2023 |
您所在的位置:网站首页 › 怎么p正装全身照 › 2023 |
2023
|
目录如下  2023-04-08_5分钟学会2023年最火的AI绘画(Lora模型训练入门) 2023-04-08_5分钟学会2023年最火的AI绘画(Lora模型训练入门)===============2023-04-09更新=============== 该系列目前有以下文章 2023-03-10_5分钟学会2023世界顶级AI绘画神器Stable Diffusion(入门篇) 2023-03-18_5分钟学会2023年最火的AI绘画(文生图) 2023-03-22_5分钟学会2023年最火的AI绘画(图生图) 2023-03-25_5分钟学会2023年最火的AI绘画(ControlNet详解) 2023-04-01_5分钟学会2023年最火的AI绘画(4K高清修复) 2023-04-03_5分钟学会2023年最火的AI绘画(如何互联网访问&模型共享) 2023-04-08_5分钟学会2023年最火的AI绘画(Lora模型训练入门) 交流可加扣裙:四二642八九七2 介绍模型的训练一共分为四种 EmbeddingsHypernetworksDreamboothLoRA其中Embeddings和Hypernetworks是比较早期的做法,标准的Dreambooth和最常见的LoRA,早期的做法先且不论,下面说一下Dreambooth和LoRA的区别 Dreambooth:Dreambooth直接拿样本数据对整个模型进行微调,训练的成果可以直接保存在模型中,而且在模型风格和添加的图片之间可以得到不错的平衡,但是它生成的文件很大,很次都是一个ckpt文件,上G级别,如4G,相信有过使用经验都知道,模型太大每次会加载很久,另外Dreambooth训练对硬件要求很高,一般家用显卡显存为8G,Dreambooth训练最低要求12G,标准要求为24GLoRA:全名为Low-Rank Adaptation of Large Language Models(大语言模型的低阶适配器),简单来说就是大语言模型的微调小模型,在Checkpoint的大模型的下通过这个小模型可以进行微调,LoRA模型很小,最大的100+MB,最小的2~4MB,易于使用,训练快,对显存要求低,最低要求可以在6G显存显存上训练,从学习率来看,比标准的Dreambooth提高了100倍,另外一个好处是可以针对一个模型载入多个LoRA,但是LoRA有一个缺点是对模型的调整有限,而Dreambooth对模型的调整更加全面,总是大多数场景下还是利大于弊的,因此我们一般情况下会选择使用LoRA训练LoRA建议学习率:1e-4=0.0001Dreambooth建议学习率:1e-6=0.000001LoRA的训练流程一般为:(好的LoRA训练集至关重要) 训练主题选择 > 训练集收集 > 训练集整理与清洗 > 训练集放大清晰化(可选) > 训练级分辨率预处理与打标 > 进行训练 > 对比查看训练结果 LoRA三种训练方式目前有三种训练方式 Kohya_ss,是目前比较主流产生LoRA的做法:https://github.com/bmaltais/kohya_ss教程:https://mnya.tw/cc/word/1940.html秋叶的训练脚本:https://github.com/Akegarasu/lora-scripts教程:https://www.bilibili.com/video/BV1fs4y1x7p2Dreambooth扩展:Stable Diffusion WebUI上Dreambooth扩展也可以训练LoRA后文将使用三种方式分别尝试LoRA的训练,这些训练工具的安装过程可能需要使用到科学上网,如果有类似于Connection reset、Connection refuse、timeout之类的报错多半是网络原因,请自备T子,此处不在赘述。 后续将在三种工具中修改必要参数,其他参数保持默认的情况下按照同样的训练集、同样的底模进行训练,然后在做横向和纵向的对比。 训练集准备(主题选择&清理&打标)介绍首先确认训练主题,一般入门就训练AI认识脸,当然主题还有许多,比如某种姿势动作、某种画风、某种服饰等等,这里就以入门的训练脸为主题。 巧妇难为无米之炊,首先当然准备好训练集,训练集很重要,这直接影响到最后训练的效果,因此需要进行挑选,训练集看质不看量,一般准备15张以上照片,找一个你喜欢的明星或者动漫人物,大多数教程并没有说明如何寻找训练集,可以从以下网站寻找训练集,照片质量还是不错,毕竟经过人工(用户)筛选 堆糖:https://www.duitang.com花瓣:https://huaban.compinterest:https://www.pinterest.com优质训练集定义如下 至少15张图片,每张图片的训练步数不少于100照片人像要求多角度,特别是脸部特写(尽量高分辨率),多角度,多表情,不同灯光效果,不同姿势等图片构图尽量简单,避免复杂的其他因素干扰可以单张脸部特写+单张服装按比例组成的一组照片减少重复或高度相似的图片,避免造成过拟合建议多个角度、表情,以脸为主,全身的图几张就好,这样训练效果最好训练集照片准备好后需要经过如下处理 对训练集继续修复,修复一些低像素照片和去除不必要的杂质,修复有两种方式推荐:一是可以在Stable Diffusion的Extra页面进行批量简单高清放大二是可以在Stable Diffusion的图生图+Tiled VAE插件进行批量修复(高级用法)裁剪你的照片成512×512(显存比较高768×768也可以)的比例,批量裁剪有几种方法birme站点批量裁剪后批量下载,优势是可以自定义选取利用picpick软件自己裁剪后用python脚本批量改名和批量二次裁剪,上手难度略高推荐:使用Stable Diffusion自带的训练预处理工具进行裁剪,优点是简单方便,缺点是不能自定义选取准备图片解析词,新建一个和图片名称一样的txt文件,里面输入对应照片的描述,可以使用自然语言,也可以使用关键词堆砌,注意是英文的(如a woman with a red lip and a blue background with a white background and a red lip and a blue background with a white background, 1girl, close-up, halftone, halftone_background, mole, polka_dot, polka_dot_background, solo),也有下面几种方式手动打标,不推荐,相当于给AI打工,不利于打工人的身心健康推荐:推荐用Stable Diffusion 自带的训练预处理工具进行识别打标打标优化,编辑我们生成好的解析词文件,加入我们的关键人物tag,如果是服饰图片,可以给服饰加上我们自定义的tag用于区分服饰,相同的发型也可以打上发型的自定义tag,后面使用该LoRA模型可以加上服饰或发型部分的tag用于生成对应要求的图像,人物我们可以增量加入常用的tag如face,nose,lips,hairstyle,eyes,ears,forehead,breast等,批量添加关键词有几种方式批量添加相同关键词可以直接在git bash,下面的命令可以给每个txt文件末尾增加字符串,white shirt,,添加其他的内容照这个改就行了ls | grep txt | xargs -i echo "echo -n ',white shirt,' >> {}" | bash推荐:也可以使用BooruDatasetTagManager进行批量打标,其内置了一个文本的tag库,可以针对每张照片针对性打标,如下所示 此处我们以绅士们都喜欢的一哭二闹三上不优雅为例,通过各种渠道找到对应的训练集后(为了避免不必要的麻烦训练集就不展示了,按照我们上文定义的优质训练集去寻找即可) 高清修复在打标之前先对图像进行修复,在Stable Diffusion的Extra页面进行修复,可以先在Single中进行单张参数调整,如下所示  单张参数调整不错之后可以使用批量处理  这边找一张其他照片对比下高清修复的效果,使用Extra放大后效果如下,可以看到放大之没有了像素点,这种方式是尊重原图的,因为它没有重绘,但是细节只是涂抹了,几乎没有增加细节,但肯定比没处理要好  另外注意在处理后会产生一张原图和一张压缩的图片,需要手动删除一下原图,原图一般比较大,在进行打标预处理时可能会报错,或者在设置里面找到最大限制,如下为4MB,那么超过4MB的都是需要删除的。  高级高清修复(可选) 高级高清修复(可选)注意这是可选的,它的优点是放大之后能增加细节(因为做了重绘),缺点是耗时特别长,并且参数不正确的情况下和原图差别比较大,不尊重原图,也就起不到训练的效果 这种方法在之前的文章中其实有介绍,可以回顾下之前的文章:2023-04-01_5分钟学会2023年最火的AI绘画(4K高清修复),在使用之前需要安装multidiffusion-upscaler-for-automatic1111插件 https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111在Stable Diffusion选择图生图,如下所示,首先模型选择很重要,这直接关系到修复后的效果,建议按照后续将要训练的底模一致,就是在使用底模训练之前先使用底模增加一些图片细节。 正负向tag只保留和图片质量相关的,正向可参考:masterpiece,best quality, realistic, highres,photorealistic,8k wallpaper 负向可参考:low quality,normal quality, worst quality, bad anatomy, extra breasts,extra nipples,extra hands,bad legs, bad feet,extra feet, bad fingers,confused fingers, extra fingers  脸部修复和重绘幅度很重要,可能直接影响到修复结果  其余参数按照下面选择即可  思路也是先修复一张看看效果,效果OK了再去批量处理中进行批处理,下图所示为批处理界面  下面对比一下不同参数的修复效果 重绘幅度0.3、无脸部修复,结果还是比较尊重原图的,重绘幅度不宜过小或者过大,过小不能增加细节,过大不像原图,要在修复和尊重原图之间找一个平衡点 重绘幅度0.3、有脸部修复,脸部修复效果不好这里就不展示了换一个国风模型、重绘幅度0.3、无脸部修复,虽然不太尊重原图(有转手绘效果,这是模型选择的原因),但是细节还是不错,如果本来就是要国风模型作为底模那也可以这样修复。 重绘幅度0.3、有脸部修复,脸部修复效果不好这里就不展示了换一个国风模型、重绘幅度0.3、无脸部修复,虽然不太尊重原图(有转手绘效果,这是模型选择的原因),但是细节还是不错,如果本来就是要国风模型作为底模那也可以这样修复。 打标 打标直接在Stable Diffusion的训练预处理中裁剪和打标,方便快捷,推荐使用,如下图所示 Source directory:选择收集的训练集目录Destination directory:选择处理后的目录,目录不存在将会新创建Auto focal point crop:一般勾选上,在裁剪的时候将会以人物的脸部为中心进行裁剪Width & Height:宽和高设置为512即可Split oversized images:如果图像太大,将会分割成多张,而不是选择丢弃剩下的,可以勾选Create flipped copies:图片少于15张建议勾选,会创建一张左右镜像的训图片Use BLIP for caption:使用自然语言解释图片,建议勾选Use deepbooru for caption:使用关键词堆砌解释图片,建议勾选 点击Preprocess进行预处理,预处理完成后如下所示,它将会自动重命名,会给每一图片加上一个同名的文本文件存放tag,在对生成的tag进行核对,批量增加或者使用上文提到的BooruDatasetTagManager进行批量处理  到此为止训练集就准备好了,下面分别介绍一下三种训练方式 模型不符合预期的可能原因图片分辨率低:可能导致人物面部的崩坏,有全身照但生成人物依然崩坏原因也可能是训练时人物照片分辨率低裁剪问题 :如果裁剪的只有脸部图片,那么你只能得到脸图,或者扭曲的半身照,可以按照比例进行图片组合。构图复杂:多个人或者构图复制,尽量让你的人物单独出镜,裁剪或者抹掉其他人或复杂的东西。图片相似成都高:重复或高度相似,这会造成过拟合底模:训练选择的基底模型问题参数:训练时参数设置不合理方式一:Kohya's GUIKohya's GUI基于Windows系统提供了可以用于Stable Diffusion模型训练的GUI界面,GUI 允许您设置训练参数并生成和运行所需的 CLI 命令来训练模型,它是一个All in One的程序包(傻瓜包)整合了训练用的所有软件,还有图形用户界面。所有软件都是在它自己的运行环境里运行,不会干扰其他的程序软件,安装kohya_ss非常简单,唯一要求是需要科学上网。 Kohya's GUI 的好处就是让训练模型的工作交给独立软体去运作,不再跟Stable Diffusion web UI一同运行,毕竟Stable Diffusion web UI 常常更新容易造成相关扩展错误等问题,非常麻烦。 项目地址:https://github.com/bmaltais/kohya_ss 安装打开gitbash,输入如下命令,其中目录的名称(dir变量)需要自行定义,不要使用中文和空格,此处以/e/AI/train为例 dir=/e/AI/train mkdir -p $dir && cd $dir git clone https://github.com/bmaltais/kohya_ss cd kohya_ss ./setup.bat然后接下来会装一堆依赖,其中比较大的是pytorch包(2.4G)、tensorflow包(455MB)、xformers包(184MB),此处如果很慢可尝试科学后进行下载,否则够得等 Looking in indexes: https://pypi.org/simple, https://download.pytorch.org/whl/cu116 Collecting torch==1.12.1+cu116 Downloading https://download.pytorch.org/whl/cu116/torch-1.12.1%2Bcu116-cp310-cp310-win_amd64.whl (2388.4 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/2.4 GB 764.8 kB/s eta 0:51:41注意安装到一半会进行如下选择,参考如下,注意在Windows下安装DeepSpeed一定要选择NO,DeepSpeed是一个加速训练的库,选择NO是因为DeepSpeed模块不支持Winodws,比较搞笑的是这个库是微软开发的,所以这里不要踩坑了,详情见issue [REQUEST] Hey, Microsoft...Could you PLEASE Support Your Own OS? #2427 https://github.com/microsoft/DeepSpeed/issues/2427如果选错了,重新执行setup.bat可重新选择 In which compute environment are you running? Please select a choice using the arrow or number keys, and selecting with enter * This machine AWS (Amazon SageMaker) Which type of machine are you using? Please select a choice using the arrow or number keys, and selecting with enter * No distributed training multi-CPU multi-GPU TPU MPS Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:NO # Nightly版本的PyTorch才支持dynamo,这里选择NO Do you wish to optimize your script with torch dynamo?[yes/NO]:NO # 注意在Windows环境下要选NO Do you want to use DeepSpeed? [yes/NO]:No What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all Do you wish to use FP16 or BF16 (mixed precision)? NOCUDNN 8.6,如果是30系或者40系显卡可开启该特性,它可以提供更高的批处理大小和更快的训练速度,在4090上几乎可以提速50%,需要可以在如下链接下载,大概600+MB,这也是作者提供的链接 https://b1.thefileditch.ch/mwxKTEtelILoIbMbruuM.zip下载完成后解压到项目根目录,执行如下命令安装 # 激活venv ./venv/Scripts/activate.bat # 安装 python ./Tools/cudann_1.8_install.py # 回显如下 [ ] xformers version 0.0.14.dev0 installed. [!] bitsandbytes NOT installed. [!] diffusers NOT installed. [!] transformers NOT installed. [!] torch version 2.0.0+cu118 installed. [!] torchvision version 0.15.1+cu118 installed. Checking for CUDNN files in C:\Users\xx\AppData\Local\Programs\Python\Python310\Lib\site-packages\torch\lib Copied CUDNN 8.6 files to destination启动启动就很简单了,直接使用如下命令即可,和Stable Diffusion类似 ./gui-user.bat能看到如下界面说明安装成功  训练 训练首选准备三个目录 image log model在image目录中新建一个目录100表示每张照片训练100步,然后将上面准备好的训练集放到该目录中,即image/100,假设准备了20张照片,此处需要训练100 * 20 = 2000步 目录准备好后找到打开Dreambooth LoRA选项,选择底模,因为我们是真人训练,所以底模选择喜闻乐见的chilloutmix_NiPrunedFp16Fix.safetensors  几个目录对应选择好,注意要选择目录100的上一层目录,即image,最终模型的名字设定好,此处就以三上不优雅的假名mikami命名。 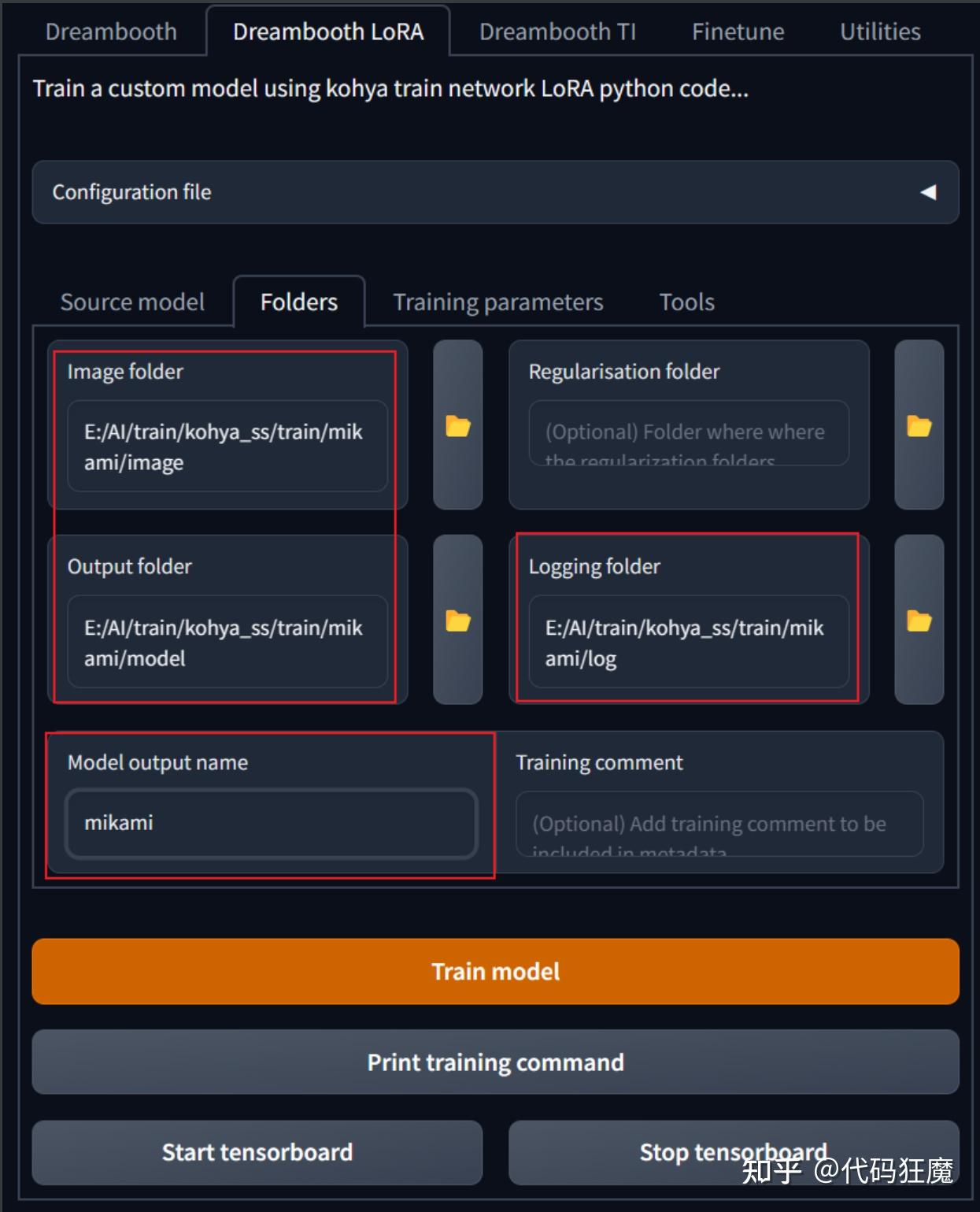 batch size,笔者显存12G可设置为4,根据实际情况先择,如果显存比较小建议保持为1就行,batch size为4表示一次处理4张图片,因此需要的步数为2000/4=500步,batch size越大训练时间越短 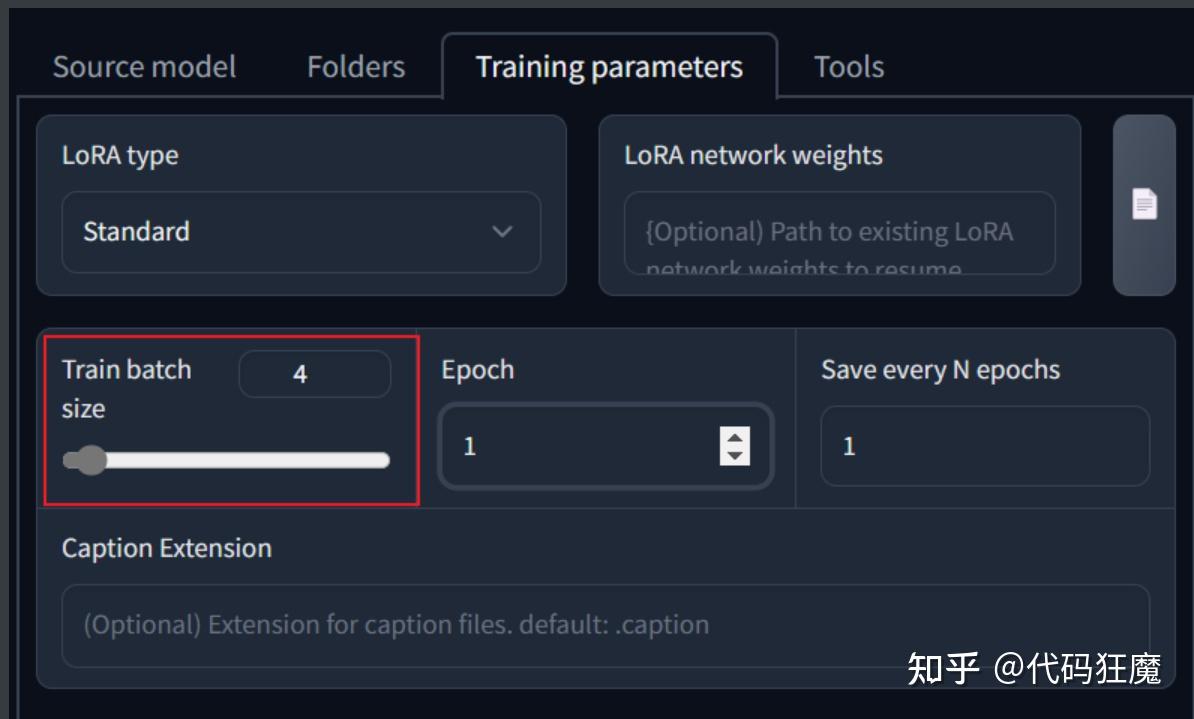 最后点击页面末尾的Train model即可,此时页面上并没有任何反应,要观察控制台,如下输出表示正在训练中 ... use 8-bit AdamW optimizer | {} running training / 学習開始 num train images * repeats / 学習画像の数×繰り返し回数: 2700 num reg images / 正則化画像の数: 0 num batches per epoch / 1epochのバッチ数: 675 num epochs / epoch数: 1 batch size per device / バッチサイズ: 4 gradient accumulation steps / 勾配を合計するステップ数 = 1 total optimization steps / 学習ステップ数: 675 steps: 3%|█████▍ 20/675 [00:25 |
【本文地址】