elasticsearch(ES)全局文本搜索器 |
您所在的位置:网站首页 › 微商必备的作图软件有哪些好用 › elasticsearch(ES)全局文本搜索器 |
elasticsearch(ES)全局文本搜索器
|
1.elasticsearch索引就相当于一个数据库,在索引里可以直观的看到数据,去引用或者写入。
2.elasticsearch的数据来源可以是自己的爬取的数据也可以来自本地或服务端导入。
一、基本介绍
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。 Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。 二、基本概念 2.1 Node 与 ClusterElastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。 2.2 IndexElastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。 下面的命令可以查看当前节点的所有 Index。 (由于我使用的是Kibana,所以代码可以有所不同) 1 $ GET /_cat/indices?v 2.3 DocumentIndex 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。 Document 使用 JSON 格式表示,下面是一个例子。 1 { 2 "user": "张三", 3 "title": "工程师", 4 "desc": "数据库管理" 5 }
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。 2.4 TypeDocument 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。 不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。 下面的命令可以列出每个 Index 所包含的 Type。 GET /_mapping?pretty=true
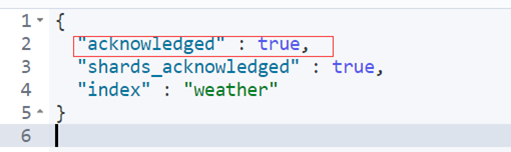
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。 三、新建和删除 Index1.新建 Index,可以直接向 Elastic 服务器发出 PUT 请求。下面的例子是新建一个名叫weather的 Index。 $ PUT /weather
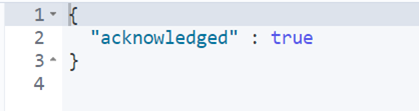
2.然后,我们发出 DELETE 请求,删除这个 Index。 $ DELETE /weather
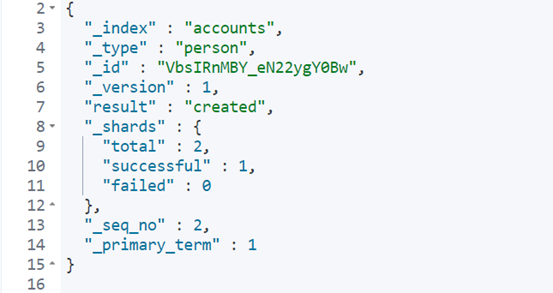
四、中文分词设置 新建一个 Index,指定需要分词的字段。这一步根据数据结构而异,下面的命令只针对本文。基本上,凡是需要搜索的中文字段,都要单独设置一下。 user title desc这三个字段都是中文,而且类型都是文本(text),所以需要指定中文分词器,不能使用默认的英文分词器。Elastic 的分词器称为 analyzer。我们对每个字段指定分词器。 "user": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }上面代码中,analyzer是字段文本的分词器,search_analyzer是搜索词的分词器。ik_max_word分词器是插件ik提供的,可以对文本进行最大数量的分词。 五、数据操作 5.1 新增记录向指定的 /Index/Type 发送 PUT 请求,就可以在 Index 里面新增一条记录。比如,向/accounts/person发送请求,就可以新增一条人员记录。 PUT /accounts/person/1 { "user": "张三", "title": "工程师", "desc": "数据库管理" }服务器返回的 JSON 对象,会给出 Index、Type、Id、Version 等信息。
如果你仔细看,会发现请求路径是/accounts/person/1,最后的1是该条记录的 Id。它不一定是数字,任意字符串(比如abc)都可以。新增记录的时候,也可以不指定 Id,这时要改成 POST 请求。 POST /accounts/person { "user": "李四", "title": "工程师", "desc": "系统管理" }上面代码中,向/accounts/person发出一个 POST 请求,添加一个记录。这时,服务器返回的 JSON 对象里面,_id字段就是一个随机字符串。
注意,如果没有先创建 Index(这个例子是accounts),直接执行上面的命令,Elastic 也不会报错,而是直接生成指定的 Index。所以,打字的时候要小心,不要写错 Index 的名称。 5.2 查看记录向/Index/Type/Id发出 GET 请求,就可以查看这条记录。 $ GET /accounts/person/1?pretty=true上面代码请求查看/accounts/person/1这条记录,URL 的参数pretty=true表示以易读的格式返回。返回的数据中,found字段表示查询成功,_source字段返回原始记录。
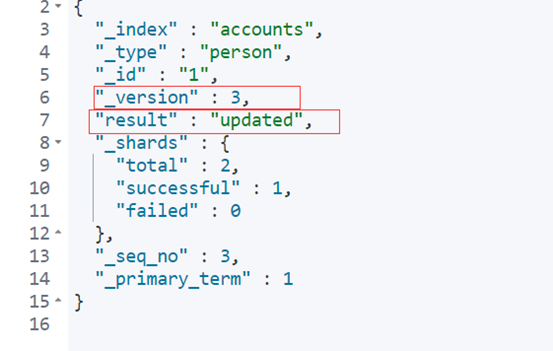
如果 Id 不正确,就查不到数据,found字段就是false。 $ GET /weather/beijing/abc?pretty=true'{ "_index" : "accounts", "_type" : "person", "_id" : "abc", "found" : false } 5.3 删除记录 删除记录就是发出 DELETE 请求。 $ DELETE /accounts/person/1 5.4 更新记录更新记录就是使用 PUT 请求,重新发送一次数据。 PUT /accounts/person/1 { "user" : "张三", "title" : "工程师", "desc" : "数据库管理,软件开发" }上面代码中,我们将原始数据从"数据库管理"改成"数据库管理,软件开发"。 返回结果里面,有几个字段发生了变化。
可以看到,记录的 Id 没变,但是版本(version)从1变成2,操作类型(result)从created变成updated。 六、数据查询 6.1 返回所有记录使用 GET 方法,直接请求/Index/Type/_search,就会返回所有记录。 $ GET /accounts/person/_search上面代码中,返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录,里面子字段的含义如下。
total:返回记录数,本例是2条。 max_score:最高的匹配程度,本例是1.0。 hits:返回的记录组成的数组。 返回的记录中,每条记录都有一个_score字段,表示匹配的程序,默认是按照这个字段降序排列。 6.2 全文搜索 Elastic 的查询非常特别,使用自己的查询语法,要求 GET 请求带有数据体。 $ GET /accounts/person/_search { "query" : { "match" : { "desc" : "软件" } } }上面代码使用 Match 查询,指定的匹配条件是desc字段里面包含"软件"这个词。返回结果如下。
Elastic 默认一次返回10条结果,可以通过size字段改变这个设置。 $ GET /accounts/person/_search { "query" : { "match" : { "desc" : "管理" }}, "size": 1 }上面代码指定,每次只返回一条结果。 还可以通过from字段,指定位移。 $ GET /accounts/person/_search { "query" : { "match" : { "desc" : "管理" }}, "from": 1, "size": 1 }上面代码指定,从位置1开始(默认是从位置0开始),只返回一条结果。 6.3 逻辑运算如果有多个搜索关键字, Elastic 认为它们是or关系。 $GET /accounts/person/_search { "query" : { "match" : { "desc" : "软件 系统" }} }上面代码搜索的是软件 or 系统。 如果要执行多个关键词的and搜索,必须使用布尔查询。 $ GET /accounts/person/_search { "query": { "bool": { "must": [ { "match": { "desc": "软件" } }, { "match": { "desc": "系统" } } ] } } |




【本文地址】
今日新闻 |
推荐新闻 |