【Paddle实战】基于PaddleSpeech搭建私人录音转文字服务 |
您所在的位置:网站首页 › 录音转文字一般多长时间啊 › 【Paddle实战】基于PaddleSpeech搭建私人录音转文字服务 |
【Paddle实战】基于PaddleSpeech搭建私人录音转文字服务
|
环境搭建 安装paddlepaddle和paddleSpeech: pip install paddlepaddlepip install paddlespeechPaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用如下: 声音分类 语音识别 语音翻译 语音合成 相关依赖如下: gcc >= 4.8.5 paddlepaddle >= 2.3.1 python >= 3.7 linux(推荐), mac, windows win必须安装Microsoft C++生成工具 命令行调用 语音分类 paddlespeech cls --input 1.mp3
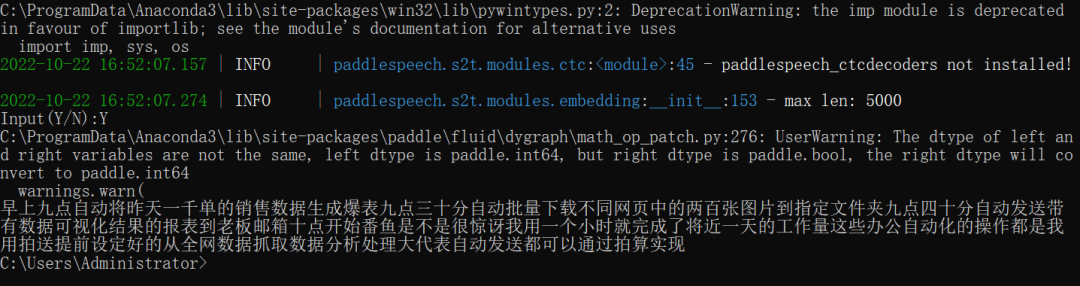
一段python办公自动化抖音广告语,因为有背景音乐,所以判断为Music。 语音识别
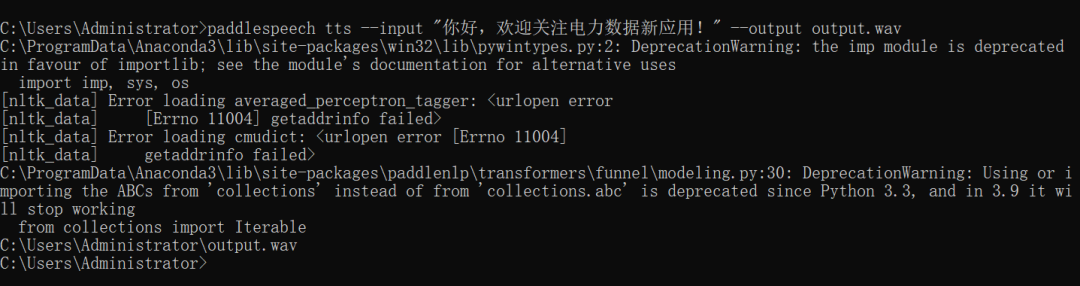
这段广告语被完整识别出来,唯一的问题是不带标点符号。 语音翻译(英翻中) paddlespeech asr --lang zh --input input_16k.wavwindows暂不支持,但是linux可以。 语音合成 paddlespeech tts --input "你好,欢迎关注电力数据新应用!" --output output.wav
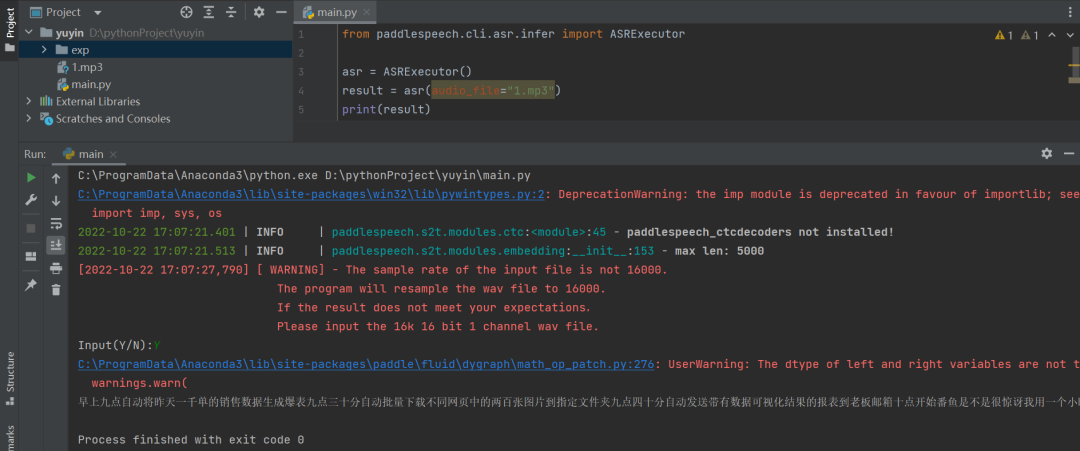
自动生成语音,大数据工匠,2秒 API调用语音识别 from paddlespeech.cli.asr.infer import ASRExecutor asr = ASRExecutor()result = asr(audio_file="1.mp3")print(result)
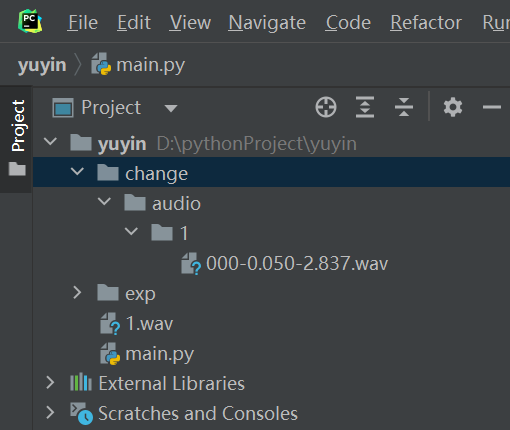
PaddleSpeech识别最长语音为50s,故需要切分。 代码实现 音频切分: 安装auditok库。 pip install auditok引入需要的库。 from paddlespeech.cli.asr.infer import ASRExecutorfrom paddlespeech.cli.text.infer import TextExecutorimport csvimport moviepy.editor as mpimport auditokimport osimport paddleimport soundfileimport librosaimport warnings warnings.filterwarnings('ignore')通过auditok.split来对音频进行切分,切分后新建目录:change/audio/文件名/,将文件存入该目录。 # 引入auditok库import auditok# 输入类别为audiodef qiefen(path, ty='audio', mmin_dur=1, mmax_dur=100000, mmax_silence=1, menergy_threshold=55): audio_file = path audio, audio_sample_rate = soundfile.read( audio_file, dtype="int16", always_2d=True) audio_regions = auditok.split( audio_file, min_dur=mmin_dur, # minimum duration of a valid audio event in seconds max_dur=mmax_dur, # maximum duration of an event # maximum duration of tolerated continuous silence within an event max_silence=mmax_silence, energy_threshold=menergy_threshold # threshold of detection ) for i, r in enumerate(audio_regions): # Regions returned by `split` have 'start' and 'end' metadata fields print( "Region {i}: {r.meta.start:.3f}s -- {r.meta.end:.3f}s".format(i=i, r=r)) epath = '' file_pre = str(epath.join(audio_file.split('.')[0].split('/')[-1])) mk = 'change' if (os.path.exists(mk) == False): os.mkdir(mk) if (os.path.exists(mk + '/' + ty) == False): os.mkdir(mk + '/' + ty) if (os.path.exists(mk + '/' + ty + '/' + file_pre) == False): os.mkdir(mk + '/' + ty + '/' + file_pre) num = i # 为了取前三位数字排序 s = '000000' + str(num) file_save = mk + '/' + ty + '/' + file_pre + '/' + \ s[-3:] + '-' + '{meta.start:.3f}-{meta.end:.3f}' + '.wav' filename = r.save(file_save) print("region saved as: {}".format(filename)) return mk + '/' + ty + '/' + file_pre qiefen("1.wav")执行后qiefen("1.wav")后,可以把1.wav进行切分。
语音转文本: 遍历每一个文件,将它们分别送入ASRExecutor进行识别,所有识别文本集中保存到列表words里,最终写入result.csv文件。 # 语音转文本asr_executor = ASRExecutor() def audio2txt(path): # 返回path下所有文件构成的一个list列表 print(f"path: {path}") filelist = os.listdir(path) # 保证读取按照文件的顺序 filelist.sort(key=lambda x: int(os.path.splitext(x)[0][:3])) # 遍历输出每一个文件的名字和类型 words = [] for file in filelist: print(path + '/' + file) text = asr_executor( audio_file=path + '/' + file, device=paddle.get_device(), force_yes=True) # force_yes参数需要注意 words.append(text) return words # 保存import csv def txt2csv(txt_all): with open('result.csv', 'w', encoding='utf-8') as f: f_csv = csv.writer(f) for row in txt_all: f_csv.writerow([row]) # 可替换成自身的录音文件source_path = '录音.wav'# 划分音频path = qiefen(path=source_path, ty='audio', mmin_dur=0.5, mmax_dur=100000, mmax_silence=0.5, menergy_threshold=55)# 音频转文本 需要GPUtxt_all = audio2txt(path)# 存入csvtxt2csv(txt_all)标点符号修正: 将result.csv文件读入,拼成完整的段落,利用TextExecutor进行标点符号修正,最终将修正结果存入final_result.txt文件。 # 拿到新生成的音频的路径texts = ''source_path = 'result.csv'with open(source_path, 'r') as f: text = f.readlines()for i in range(len(text)): text[i] = text[i].replace('\n', '') texts = texts + text[i]print(texts)text_executor = TextExecutor()if text: result = text_executor( text=texts, task='punc', model='ernie_linear_p3_wudao', device=paddle.get_device(), # force_yes=True )print(result) with open("final_result.txt", 'w') as f: f.writelines(result)将会议录音文件录音.wav放入工程目录下,执行程序,结果如下。
可以看到只有“一键三连”翻译成了“一见三连”,其他内容准确无误进行了识别。 |


【本文地址】