【Stata双重差分模型】双重差分DID的具体操作步骤 |
您所在的位置:网站首页 › 平行趋势检验基期选择原则有哪些 › 【Stata双重差分模型】双重差分DID的具体操作步骤 |
【Stata双重差分模型】双重差分DID的具体操作步骤
|
目录 一、简介 二、数据准备 数据收集: 数据清洗: 变量定义: 三、模型构建 四、实证分析 描述性统计: 平行趋势检验: 双重差分估计: 安慰剂检验: 异质性分析: 五、结果解读与讨论 六、结论与展望 七、DIDI扩展内容 八、附录 一、简介双重差分法(DID)是一种经济学中常用的计量方法,用于评估某一事件或政策的影响。通过比较实验组和对照组在事件发生前后的变化,DID能够有效地分离出事件或政策的影响。本案例将详细阐述如何使用双重差分法进行实证分析,并展示具体的STATA操作代码。
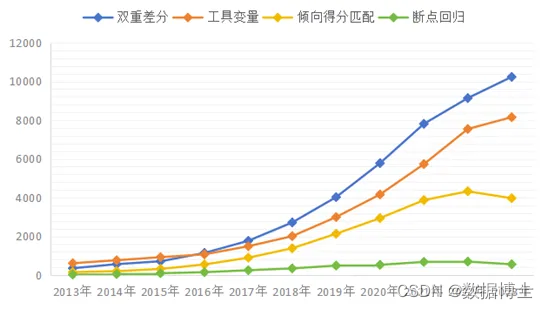
在中国知网以“双重差分”“倍差法”“DID”按篇名、主题、关键词、摘要、小标题检索,2017年后使用双重差分方法的论文数量急剧上升,超越了工具变量法(instrumental variable)、倾向得分匹配法(PSM)、断点回归设计(regression discontinuity design)等社会科学领域实证研究常用方法。据有关不完全统计,从2020年开始,国内外核心、权威期刊约有20%的实证论文采用了DID方法。
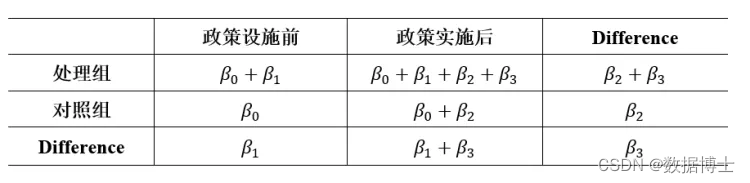
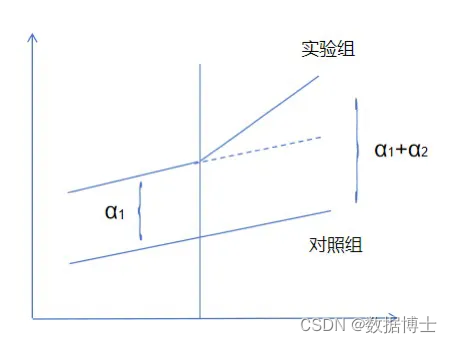
假设我们要评估一项新的就业培训政策对失业人员再就业的影响。我们收集了实施该政策的地区(实验组)和未实施该政策的地区(对照组)的相关数据。数据包括个人的年龄、性别、教育水平、失业时长以及是否再就业等信息。 数据清洗:在数据分析之前,需要对数据进行清洗,以确保数据的准确性和完整性。这包括检查数据的一致性、处理缺失值和异常值等。 * 检查数据的一致性 describe * 处理缺失值 drop if missing(age) | missing(gender) | missing(education) | missing(unemployment_duration) | missing(reemployment) * 处理异常值(例如,删除失业时长小于0的记录) drop if unemployment_duration < 0 变量定义:定义所需的变量,包括被解释变量(是否再就业)、解释变量(政策实施虚拟变量和时间虚拟变量)以及控制变量(年龄、性别、教育水平和失业时长)。 * 定义变量 gen policy = (treatment == 1 & year >= policy_year) // 政策实施虚拟变量 gen time = (year >= policy_year) // 时间虚拟变量 三、模型构建基于双重差分法,我们构建以下回归模型:
其中,Reemployment𝑖𝑡是个体 𝑖在时间 𝑡是否再就业的二进制变量;Policy𝑖𝑡是政策实施虚拟变量;Time𝑖𝑡是时间虚拟变量;Xit 是控制变量向量;ϵit 是误差项。
首先,我们对数据进行描述性统计分析,以了解各变量的分布情况。 * 描述性统计 summarize age gender education unemployment_duration reemployment policy time 平行趋势检验:在进行双重差分分析之前,需要进行平行趋势检验,以确保实验组和对照组在政策实施前具有相似的趋势。 * 平行趋势检验 xtset id year xtreg reemployment policy time age gender education unemployment_duration, fe 使用双重差分模型进行估计,以获取政策的实际效果。 * 双重差分估计 xtreg reemployment policy time policy_time age gender education unemployment_duration, fe 安慰剂检验:为了进一步验证结果的稳健性,可以进行安慰剂检验。这包括随机选择一个时间点作为政策实施年份,然后重新进行双重差分估计。 * 安慰剂检验 local random_year = runiformint(policy_year - 5, policy_year - 1) // 随机选择一个时间点 gen placebo_policy = (treatment == 1 & year >= `random_year') gen placebo_time = (year >= `random_year') gen placebo_policy_time = placebo_policy * placebo_time xtreg reemployment placebo_policy placebo_time placebo_policy_time age gender education unemployment_duration, fe 异质性分析:为了深入了解政策在不同群体中的效果,可以进行异质性分析。例如,分析政策对不同年龄段、性别和教育水平群体的影响。 * 异质性分析 xtreg reemployment policy time policy_time age gender education unemployment_duration if age < 30, fe // 分析政策对30岁以下群体的影响 xtreg reemployment policy time policy_time age gender education unemployment_duration if age >= 30, fe // 分析政策对30岁及以上群体的影响 五、结果解读与讨论根据实证分析结果,我们发现政策实施后,实验组的再就业率显著高于对照组。此外,我们还发现政策对不同年龄段、性别和教育水平群体的再就业影响存在差异。这些发现对于政策制定者具有重要的参考价值。 六、结论与展望通过双重差分法的实证分析,我们得出了关于新就业培训政策效果的结论。然而,双重差分法也存在一定的局限性,如可能存在遗漏变量偏差、样本选择偏误等问题。未来研究可以进一步完善研究方法,提高政策评估的准确性 七、DIDI扩展内容多期双重差分法(Multi-Period DID):传统的双重差分法通常只涉及两个时期(政策实施前和政策实施后)。然而,在许多情况下,政策可能会在多个时期实施。多期双重差分法允许我们分析这种多期政策的影响。在多期双重差分法中,时间虚拟变量不再仅仅是二元变量,而是根据政策实施的多个时期进行编码。 合成控制法(Synthetic Control Method, SCM):合成控制法是一种扩展的双重差分法,特别适用于评估单个或少数几个单位(如城市、国家)的政策影响。SCM通过构建一个“合成”的控制组,该控制组是多个潜在对照单位的加权组合,以最大程度地近似实验单位在政策实施前的特征。这种方法可以减少因选择对照组不当而导致的偏差。 双重差分法的内生性问题处理:双重差分法的一个关键假设是实验组和对照组的选择是外生的。然而,在现实中,这一假设往往不成立。为了处理内生性问题,研究者可以采用工具变量法、倾向得分匹配等方法。例如,工具变量法可以通过找到一个与实验组选择相关但与结果无关的工具变量来消除内生性。 双重差分法与面板数据模型的结合:双重差分法通常与面板数据模型相结合,以充分利用时间和横截面的信息。面板数据模型可以控制个体固定效应和时间固定效应,从而减少遗漏变量偏差。此外,面板数据模型还可以考虑动态效应,即政策影响的滞后效应和持续效应。 双重差分法的异质性分析:异质性分析可以帮助我们了解政策在不同群体中的效果是否存在差异。通过将样本划分为不同的子群体(如按年龄、性别、地区等划分),并对每个子群体分别进行双重差分估计,我们可以揭示政策的异质性影响。 双重差分法的稳健性检验:为了确保双重差分法结果的可靠性,研究者需要进行稳健性检验。常见的稳健性检验方法包括:安慰剂检验(随机选择一个时间点作为政策实施年份)、改变对照组(使用不同的对照组进行估计)、改变模型设定(例如,使用不同的控制变量)等。 八、附录双重差分:DID简介 (qq.com) Stata:空间双重差分模型(Spatial DID)-xsmle (qq.com) 相关视频及参考资料(提取码:2024) |

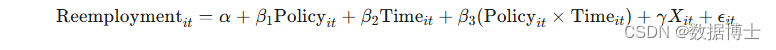
【本文地址】
今日新闻 |
推荐新闻 |