NLP |
您所在的位置:网站首页 › 常见的中文分词技术有哪几种 › NLP |
NLP
|
上一篇我们讲了N一最短路径方法、基于词的n元文法模型,本节将主要介绍由字构词方法、基于词感知机算法的汉语分词方法、基于字的生成模型和区分式模型相结合的汉语分词方法,下面我们就开始讲解由字构词的方法: 由字构词方法 由字构词方法的由来其实这个方法我们在前面讲解HMM和CRF时就一直在不停的在使用它,下面我们就详细的讲讲他的实现: 第一篇由字构词(Character一basedTaggingZ)的分词论文发表在2002年第一届SIGHAN研讨会上,当时并未引起学界的重视。一年后,xue在最大熵(ME)模型上实现的由字构词分词系统参加了BakeoffZo03的评测,在AS2003的封闭测试项目上获得第二名(见表4),然而其未登录词召回率(0.729)却位居榜首。xue还在ictyu2003的封闭测试中获得第三名,其召回率(0.670)仍然是该项比赛中最高的。尽管在Bkeoff2003中各种分词技术的优劣还难分伯仲,但既然未登录词对分词精度的影响比分词歧义大十倍以上,人们自然青 睐这种能获致最高召回率的分词方法。这一预测果然在BakeoffZO05上得到了证实。
在Bakeoff2005的各项赛事中,采用由字构词方法的参赛系统名列前茅,其中Low和Tseng的系统几乎分别囊括了开放和封闭测试的全部冠军,不同的是前者仍采用最大嫡模型,而后者选用的是条件随机场(Conditional Random Field,CRF)模型。到Bakeoff2006,由字构词的分词系统己遍地开花。其中微软亚洲研究院用CRF模型实现的由字构词分词系统在参加的六项中文分词评测中获得四个第一和两个第三。 把分词视为字的词位分类问题以往的分词方法,无论是基于规则的还是基于统计的,一般都依赖于一个事先编制的词表。自动分词过程就是通过查词表来作出词语切分的决策。与此相反,由字构词方法把分词过程视为字的分类问题。即认为每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位)。假如规定字只有四个构词位置:B(词首),M(词中),E(词尾)和S(单独成词),那么下面句子(l)的分词结果就可以直接表示成如(2)所示的字标注形式: (1)分词结果: /上海 / 计划 / 到 / 本 / 世纪 / 末 / 实现 / 人均 / 国内 / 生产 / 总值 / 五千美元 / 。/ (2)字标注: 上/B 海/E 计/B 划/E 到/S 本/S 世/B 纪/E 末/S 实/B 现/E 人/B 均/E 国/B 内/E 生/B 产/E 总/B 值/E 五/B 千/M 美/M 元/E/ 。/S 首先需要说明,“由字构词”中的“字”不只限于汉字。考虑到中文真实文本还包含一定数量的非汉字字符,本文所说的“字”,也包括标点符号、外文字母、注音符号和阿拉伯数字等。所有这些字符都是由字构词的基本单元。当然,汉字依然是这个构造单元集合中数 量最多的一类字符。以拥有411万字次的MSRA20OS语料(见表l)为例,它包含5147种不同字符。其中,不同汉字5036个,非汉字字符只有111个,汉字占97.84%。如果从字符出现频率来考察,则汉字出现次数占全部语料字符出现频率的87.69%,非汉字字符占12.3%。在非汉字字符中大部分是标点符号,标点符号的出现次数占语料的9.42%。 由字构词分词技术的一个重要优势在于,它能够平衡地看待词表词和未登录词的识别问题。在这种分词技术中,文本中的词表词和未登录词都是用统一的字标注过程来实现的。在学习架构上,既可以不必专门强调词表词信息,也不用专门设计特定的未登录词识别模块。这使得分词系统的设计大大简化。在字标注过程中,所有的字根据预定义的特征进行词位特性的学习,获得一个概率模型,然后在待分字串上,根据字与字之间的结合紧密程度,得到一个词位的分类结果,最后根据词位定义,直接获得最终的分词结果。在这个过程中,没有显式地考虑词表词和未登录词的知识,所有的中间处理都是在字一级的单元上完成的。分词成为字重组的简单过程。然而,下面会看到,这一简单处理带来的处理结果是令人满意的。 字的词位分类及其所用的基本特征现代机器学习的主要方法,包括支持向量机(Support Vector Machine,SVM)、最大熵(EM)和条件随机场(CRF),都己经被应用于由字构词的分词学习中。由于分词过程通常处于中文处理的前端,因此,很难设计出有效的特征来大幅度提高分词性能。事实上,由于分词的初等地位,可供选用的特征也非常少。迄今为止,最常用的两类特征是字本身以及词位(状态)转移概率(这里我们沿用隐马尔科夫模型H朋中的术语)。 对于SVM和ME来说,需要设计独立的状态转移特征来表达词位的转化。但是对于一阶线性链CRF学习来说,这一转移过程将被自动集成到系统中来,而无需专门指定。这样,对于基于CRF建模的分词系统而言,需要考虑的仅仅是字特征。 词位学习中确定字特征的主要参数是上下文窗口的宽度,也就是使用距当前字多远的字来作为当前字分类的依据。相关工作表明,使用前后各两个字(即5个字的窗口宽度)是比较理想的。实际上,根据历届Bakeoff提交的报告,几乎没有系统使用超过5个字的窗口宽度。这是具有统计学依据的。笔者统计了Bakeoff2003和Bakco用005的全部8个训练语料库词长的频率分布,结果见表5。从中可以看到,在所有语料库中90%的词次是!一2字词,95%的词次是三字或三字以下词,99%以上的词都是5字或五字以下词。因此,使用宽度为5个字的上下文窗口足以覆盖真实文本中绝大多数的构词情形。
一个确定有效词位标注集的定量标准—平均加权词长。其定义为:
上式中, 在最大熵或随机条件场学习中,用于语言特征表达的特征函数起到了核心作用。一般来说,特征函数定义在一个加式集HxT上,其中H是可能的上下文或者任意的预定义条件的集合,T是一组可选的标注集。特征函数通常可以表示如下:
上式中
由于分词本质上是对一个字串中的每一个字作切分与否的二值决策过程,因此大多数由字构词的分词方法使用2词位的词位标注集。在最大熵模型中,广泛使用的是4词位的词位标注集。微软亚洲研究院在Bakeoff2006的参赛系统中,使用了6词位的词位标注集。这二类标注集的定义如下表所示。
和大多数基于2词位标注集的系统不同,使用6词位标注集,在适当的特征模板配合下,能够更有效地标注每个字的词位信息,从而在总体上获得更好的分词结果.据了解几乎所有的基于CRF的分词系统都使用了2词位标注集,因此他们大多需要使用复杂的特征来弥补标注集在表达能力上的不足。与此相反,微软研究院使用6词位标注集,因而即使使用相对简单的TMP-T6特征模板集,依然取得了领先的分词结果。这一事实表明,尽管分词过程本质上是一个二值决策过程,然而,统筹选择词位标注集和特征模板集通常能获 得更好的分词性能。 请注意,TMP-T6采用了个三字宽窗口的n一gram模板集.如前所述,上下文窗口的理想选择应该是5字宽。那么三字宽窗口是否能够提供足够的词位信息呢?答案是肯定的,条件是有6词位标注集的配合。由于6词位标注集能够不重复地给一个五字或五字以下词作词位标注,由公式(3)定义的实际激活特征中,所有5字窗口中的字信息同样都得到了引用,从而能获得特征模板集TMP-T10类似的效果。 词位模板集的语言学意义:能产度 令
对于任意一个字,如果它在某个词位上的能产度高于.05,我们就称这个词位是它的主词位。请注意,不是每个字都有主词位的。我们把那些没有主词位的字叫做白由字。下表是MSRA2005训练语料库(见表l)中具有主词位的字量分布。
从上表可以看到,除去约3/4拥有主词位的字,仅有大约1/4的字是白由的。这是基于词位分类的分词操作得以有效进行的基础之一。 为了直观的说明不同词位的字量分布,MSRA按照1/25的能产度步长分别统计了每个词位上的字量分布,得到图l的6个子图。可以看到,在所有的词位上字量的分布趋势都是类似的,即大部分字集中在每个词位的低能产度区间。这是一个有趣的结果。 以上就是由字构词的方法,参考的论文是《由字构词—中文分词新方法》黄昌宁,赵海 基于词感知机算法的汉语分词方法在2007年的ACL国际大会上Y.Zhang和S.Clark提出了一种基于词的判别式模型,该模型采用平均感知机(averaged perceptron) CCollins,2002a]作为学习算法,直接使用词相关的特征,而不是基于字的判别式模型中经常使用的字相关特征[Zhangand Clark,2007,2011]。 以下简要介绍平均感知机算法。假设
平均感知机用来训练参数向量
基于感知机算法的汉语自动分词方法的基本思路是,对于任意给定的一个输人句子,解码器每次读一个字,生成所有的候选词。生成候选词的方式有两种: (1)作为上一个候选词的末尾,与上一个候选词组合成一个新的候选词 (2)作为下一个候选词的开始。这种方式可以保证在解码过程中穷尽所有的分词候选。在解码的过程中,解码器维持两个列表:源列表和目标列表。开始时,两个列表都为空。解码器每读人一个字,就与源列表中的每个候选组合生成两个新的候选(合并为一个新的词或者作为下一个词的开始),并将新的候选词放人目标列表。当源列表中的候选都处理完成之后,将目标列表中的所有候选复 制到源列表中,并清空目标列表。然后,读人下一个字,如此循环往复直到句子结束。最后,从源列表中可以获取最终的切分结果。 感知器算法是一种典型的在线算法。感知器算法每次使用一个训练实例对模型参数进行更新,在更新参数时每次将需要更新的参数权重加1或者减1。为了防止模型对数据的过拟合,常对参数进行平均化操作,即Average Perceptron算法。Average Perceptron 算法伪代码如图1一2所示:
Average Perceptron算法不仅具有简单、速度快的特点,而且具有在线算法的优点,更新参数不需要一次使用所有训练语料,而只需要每次使用一个训练实例。 基于字的生成式模型和区分式模型相结合的汉语分词方法大家看看宗成庆的书吧,不写了,,,, |


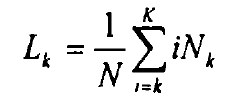
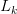 是
是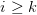 时的平均加权词长,从是语料中词长为k的词次数,
时的平均加权词长,从是语料中词长为k的词次数,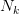 是语料中出现过的最大词长,N是语料库的总词次数。如果k=l,那么Ll,代表整个语料的平均词长。 BakeoffZoo3和Bakeoff2005各训练语料库的平均加权词长分布数据见表6。从统计中可以看到,所有语料库的平均加权词长在1.51一1.71之间。因此,5字长的上下文窗口恰好大致表达了前后各一个词的上下文(确切范围是4,53一5.13)。从这个意义上来说,5字宽的上下文窗口具备了字和词的双重含义。
是语料中出现过的最大词长,N是语料库的总词次数。如果k=l,那么Ll,代表整个语料的平均词长。 BakeoffZoo3和Bakeoff2005各训练语料库的平均加权词长分布数据见表6。从统计中可以看到,所有语料库的平均加权词长在1.51一1.71之间。因此,5字长的上下文窗口恰好大致表达了前后各一个词的上下文(确切范围是4,53一5.13)。从这个意义上来说,5字宽的上下文窗口具备了字和词的双重含义。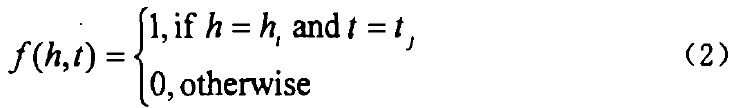
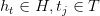 ,习惯上,我们把一组上下文特征按照共同的属性分为若干组,称之为特征模板。比如,
,习惯上,我们把一组上下文特征按照共同的属性分为若干组,称之为特征模板。比如,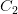 代表所有当前字后面的第二个字,就是一个unigram(一元)特征模板。 通常使用的两种n一gram(n元)特征模板集如表7所示。表中的
代表所有当前字后面的第二个字,就是一个unigram(一元)特征模板。 通常使用的两种n一gram(n元)特征模板集如表7所示。表中的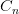 代表当前字或者和当前字相距若干位的字。例如,
代表当前字或者和当前字相距若干位的字。例如,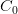 代表当前字,
代表当前字,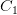 代表当前字的后一个字,
代表当前字的后一个字,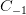 代表当前字的前一个字,依此类推。 在相关工作中,TMPT一10是最常用的一组特征模板,TMPT一6则是笔者在Bakeoff2006使用的基本特征模板。
代表当前字的前一个字,依此类推。 在相关工作中,TMPT一10是最常用的一组特征模板,TMPT一6则是笔者在Bakeoff2006使用的基本特征模板。

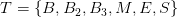 ,任意字
,任意字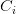 在词位
在词位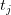 下的能产度(porductivity)可定义如下:
下的能产度(porductivity)可定义如下:

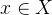 是输人句子,
是输人句子,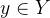 是切分结果,其中X是训练语料集合,Y是X中句子标注结果集合。我们用GEN(x)表示输人句子的切分候选集,用
是切分结果,其中X是训练语料集合,Y是X中句子标注结果集合。我们用GEN(x)表示输人句子的切分候选集,用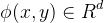 表示训练实例(x,y)对应的特征向量表示参数向量,其中
表示训练实例(x,y)对应的特征向量表示参数向量,其中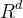 是模型的特征空间。那么,给定一个输人句子x,其最优切分结果满足如下条件:
是模型的特征空间。那么,给定一个输人句子x,其最优切分结果满足如下条件: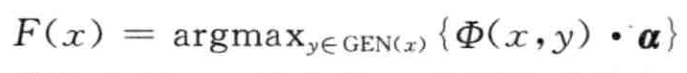
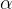 ,首先将
,首先将

【本文地址】
今日新闻 |
推荐新闻 |