|
文章目录
案例1——word模板为表格案例2——word模板中带有下划线形式python docx基本操作回到需求
案例1——word模板为表格
目的就是把excel中的数据,填入word模板中的对应位置
如下是我自定义的两个文档(仅作为学习),包括一个申请表.doc和申请名单.xlsx
 有需要的可以下载:https://note.youdao.com/s/JshqQRVK 有需要的可以下载:https://note.youdao.com/s/JshqQRVK
申请名单.xlsx 中数据如下 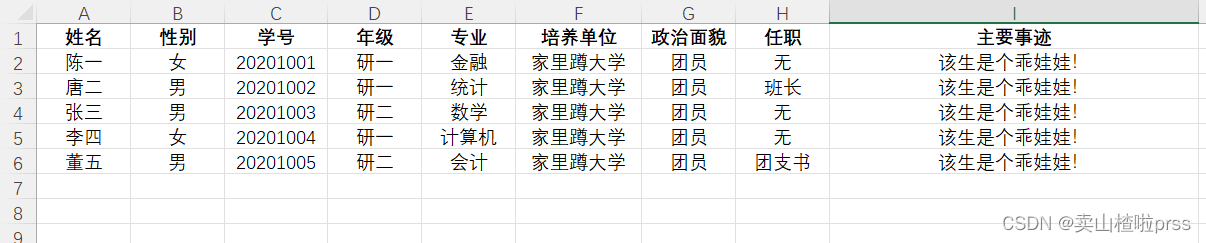 申请表.doc 内容如下(准备好需要的文档——申请表.doc ) 申请表.doc 内容如下(准备好需要的文档——申请表.doc ) 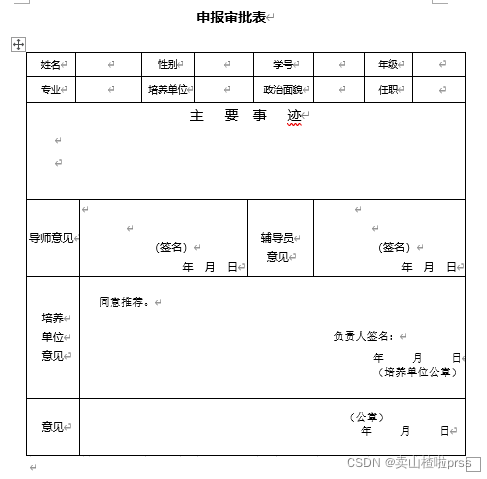
对于这种表格形式的需求,我觉得最快速的就是用word自带的邮件合并功能了,超级简单,写 chui 子个代码 。
例如:打开申请表,点击 “邮件-邮件开始合并”,就可以做相应的操作
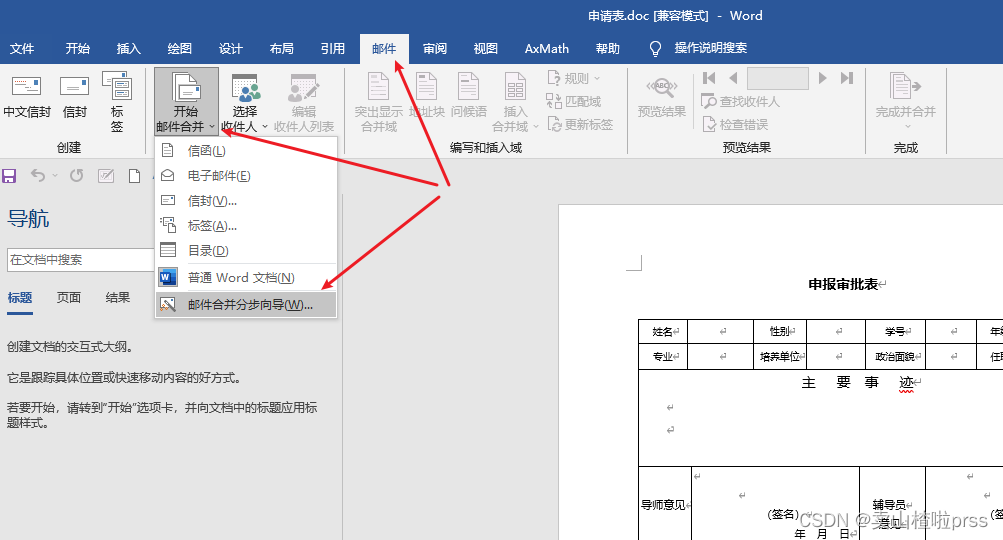 具体的操作,网上太多了,推荐几个吧 具体的操作,网上太多了,推荐几个吧
如何把excel表格中的内容批量填写到word模板中 word每页生成一个单独文件1分钟快速生成几百个文件
最终效果 
当然,这里还有一个就是怎么把word每一页变为一个单独的文档问题,额,百度应该有。
案例2——word模板中带有下划线形式
同样的,自定义如下数据  数据链接:https://note.youdao.com/s/GGOc4voN,有需要学习的伙伴可以下载试一下 数据链接:https://note.youdao.com/s/GGOc4voN,有需要学习的伙伴可以下载试一下
word模板内容如下  申请信息数据如下 申请信息数据如下  对于这种带有下划线的,考虑使用python来完成。这里主要使用了专门处理word的python扩展包python-docx 对于这种带有下划线的,考虑使用python来完成。这里主要使用了专门处理word的python扩展包python-docx
关于docx 的安装
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com docx
如果按照上面代码安装,会报如下的错误 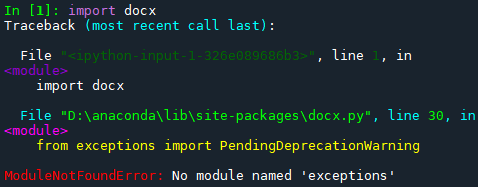 在网上找的方法,说是可以通过离线安装 在网上找的方法,说是可以通过离线安装
在这个网站https://www.lfd.uci.edu/~gohlke/pythonlibs/下载好 python_docx-0.8.10-py2.py3-none-any.whl 这个文件,然后在cmd或者Anaconda Prompt中输入pip install 再把这个whl文件按住拖动到pip install 后面,回车安装即可。 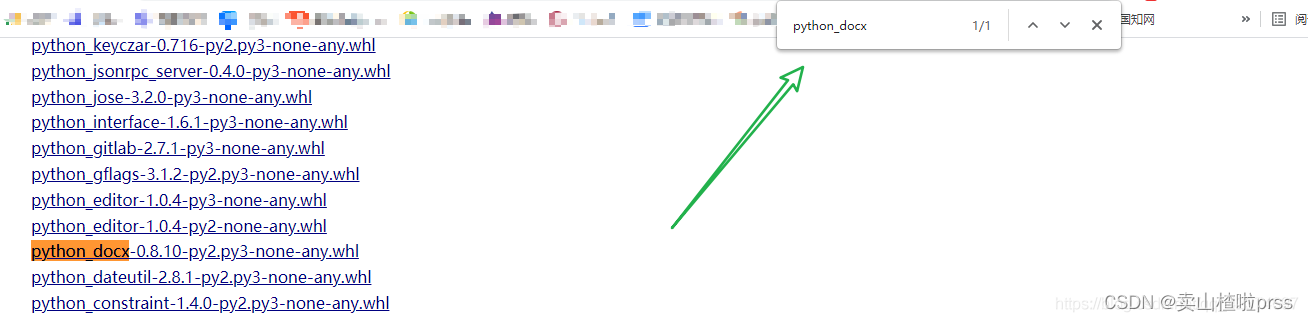
python docx基本操作
参考网上的那些教程,自己也学习学习~
1.创建word文档
# 导包
from docx import Document
# docx.shared 中包含诸如"字号","颜色","行间距"等常用模块
from docx.shared import Inches,Pt,RGBColor
from docx.oxml.ns import qn
#创建 Document 对象,相当于打开一个 word 文档
#将整个文章看做是一个Document对象
document = Document()
# 对正文的样式进行设置
# Normal指的是正文部分,还有很多其他选项如标题、表格、列表等,可遍历doc.styles进行查看
# 设置正文颜色,大小,粗体
document.styles['Normal'].font.color.rgb = RGBColor(0, 0, 255)
document.styles['Normal'].font.size = Pt(12)
document.styles['Normal'].font.bold = True
document.styles['Normal'].font.name = u'宋体'
# 对于中文字体必须加这一句
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
#向文档中添加一个标题,标题级别设置为0级,0,1,2...表示标题号大到小
document.add_heading('网红书店', level=0)
#向文档中添加一个段落,并将段落引用赋给变量 p(https://www.jianshu.com/p/7d2fcf976914)
#- 每个Document包含许多个代表“段落”的Paragraph对象,存放在document.paragraphs中
#可以使用 add_run 方法在P后面继续追加文字,并设置格式
#- 每个Paragraph都有许多个代表"行内元素"的Run对象,存放在paragraph.runs中。
p = document.add_paragraph('实体书店承载着人们的情怀与梦想')
p.add_run('城市发展').bold = True # 加粗
p.add_run('也应为实体书店')
p.add_run('留下一席之地。').italic = True # 斜体
#添加标题和段落,采用不同的形式
document.add_heading('书店可以成为城市“文化会客厅”', level=1)
document.add_paragraph('实体书店只有不断研究消费者需求',style="Intense Quote")
document.add_paragraph('不断创新', style='List Bullet')
document.add_paragraph('才是发展之道', style='List Number')
#添加图片,设置图片大小
document.add_picture(r"C:\Users\ABC\Desktop\12.png", width=Inches(2.25))
#添加表格,填入表格内容
table = document.add_table(rows=2, cols=2)
table.cell(0,0).text = "1"
table.cell(0,1).text = "2"
table.cell(1,0).text = "3"
table.cell(1,1).text = "4"
table=document.add_table(rows=2,cols=4,style='Table Grid')
for i in range(0,2):
for j in range(0,4):
table.cell(i,j).text="第{i}行{j}列".format(i=i+1,j=j+1)
# 插入一个分页符
document.add_page_break()
#保存文本
document.save('demo.docx')
效果如下 
2.编辑已存在的word文档(修改前)

# 导入
from docx import Document
from docx.shared import Inches,Pt,RGBColor
from docx.oxml.ns import qn
from docx.enum.style import WD_STYLE_TYPE #所有样式 (包括段落、文字、表格)的枚举常量集
from docx.enum.text import WD_ALIGN_PARAGRAPH #对齐方式 的枚举常量集,不过在vscode中显示有错,事实又能够执行
from docx.enum.text import WD_LINE_SPACING #行间距的单位枚举常量集(包括:单倍行距,1.5倍行距,固定 值,最小值等)
# 从文件创建文档对象
document = Document('./书店.docx')
# 显示每段的内容
for p in document.paragraphs:
print(p.text)
#设置段落间距
paragraph_format = p.paragraph_format
# p.space_before=Pt(18) #上行间距
# p.space_after=Pt(12) #下行间距
paragraph_format.line_spacing=Pt(25) #行距
paragraph_format.first_line_indent=document.styles['Normal'].font.size * 2 #段落首行缩进量
for run in p.runs:
run.font.bold = True
# run.font.italic = True
run.font.underline = True
# run.font.strike = True
# run.font.shadow = True
run.font.size = Pt(12)
# run.font.color.rgb = RGBColor(255,0,255)
run.font.name = "黑体"
# 设置像黑体这样的中文字体,必须添加下面 2 行代码
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"),"黑体")
# 修改正文样式
document.styles['Normal'].font.color.rgb = RGBColor(0, 0, 255)
document.styles['Normal'].font.size = Pt(20)
document.styles['Normal'].font.bold = True
document.styles['Normal'].font.name = u'楷体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'楷体')
#document.styles['Normal'].paragraph_format.line_spacing_rule=WD_LINE_SPACING.EXACTLY #段落行距样式为固定值,必须指定行距值,否则就会变成 多倍行距 模式
#document.styles['Normal'].paragraph_format.line_spacing_rule=WD_LINE_SPACING.SINGLE #段落行距样式为单倍行距 模式
document.styles['Normal'].paragraph_format.line_spacing_rule=WD_LINE_SPACING.MULTIPLE #多倍行距,此模式的具体行间距由文字字号大小决定,如果后面指定了行距值,此多倍行距设置会被忽略,变成固定值模式
document.styles['Normal'].paragraph_format.line_spacing=Pt(22) #行距值
document.styles['Normal'].paragraph_format.space_before=Pt(10) #段前距
document.styles['Normal'].paragraph_format.space_after=Pt(20) #段后距
document.styles['Normal'].paragraph_format.first_line_indent=document.styles['Normal'].font.size * 2 #段落首行缩进量
# 添加段落
paragraph = document.add_paragraph('实体书店承载着人们的情怀与梦想,城市发展也应为实体书店留下一席之地。')
paragraph.bold = True # 加粗
# 在此段落之前插入一个段落
prior_paragraph = paragraph.insert_paragraph_before('---------------')
# 保存文档
document.save('书店.docx')
处理效果如下 
回到需求
对于这种下划线形式,如果直接填数据,会改变模板结构,比如

我想的是,把数据都填在中间位置,同时也不改变填入范围的宽度(大致不变)
额,想了一个比较笨的方法就是一个段落一个段落的处理。如下,我把不需要填入数据的内容先保留(开头),放到一个重新创建的文档中——申请书1.docx
然后在这个文档的基础上,逐行添加

比如,先处理 申请人: 申请时间: 这一个段落
先添加p = document.add_paragraph('申请人:'),没有下划线,紧接着添加申请信息数据p.add_run(c).font.underline = True,设置下划线,紧接又添加p.add_run(' 申请时间:') …
p1 = '申请人: 申请时间: '
# 获取p1中的空格
kg1 = ' '
kg2 = ' '
len_kg1 = len(kg1)
len_kg2 = len(kg2)
ccc = df.loc[i,"申请人"]
e = df.loc[i,"申请时间"]
ddd = str(e.year) + '-' + str(e.month) + '-' + str(e.day)
len_c = len(ccc)
len_d = len(ddd)
x = int(round((len_kg1-len_c)/2,0))
y = int(round((len_kg2-len_d)/2,0))
c = ' '*x + ccc + ' '*x
d = ' '*y + ddd + ' '*y
p = document.add_paragraph('申请人:')
p.add_run(c).font.underline = True
p.add_run(' 申请时间:')
p.add_run(d).font.underline = True
在处理的时候,需要注意空格  还有缩进的问题 还有缩进的问题
具体的操作可以看代码吧。
把Excel中每一个申请信息填入空白Word模板中,生成的最终结果如下
   完整代码: 完整代码:
# 导入
from docx import Document
from docx.shared import Inches,Pt,RGBColor
from docx.oxml.ns import qn
from docx.enum.style import WD_STYLE_TYPE #所有样式 (包括段落、文字、表格)的枚举常量集
from docx.enum.text import WD_ALIGN_PARAGRAPH #对齐方式 的枚举常量集,不过在vscode中显示有错,事实又能够执行
from docx.enum.text import WD_LINE_SPACING #行间距的单位枚举常量集(包括:单倍行距,1.5倍行距,固定 值,最小值等)
import pandas as pd
import os
def GetDesktopPath():
"""
获取桌面
-------
TYPE
DESCRIPTION.
"""
return os.path.join(os.path.expanduser("~"), 'Desktop')
DesktopPath = GetDesktopPath()+'\\'
def isexists_dir_Create(path):
if not os.path.exists(path):
os.makedirs(path)
isexists_dir_Create(DesktopPath+'批量处理结果')
# 读取数据
df = pd.read_excel('申请信息.xlsx')
#读取excel数据
for i in df.index:
print(i)
# 一行一行的处理
# 从文件创建文档对象
document = Document('./申请书1.docx')
document.styles['Normal'].font.size = Pt(14)
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
p1 = '申请人: 申请时间: '
# 获取p1中的空格
kg1 = ' '
kg2 = ' '
len_kg1 = len(kg1)
len_kg2 = len(kg2)
ccc = df.loc[i,"申请人"]
e = df.loc[i,"申请时间"]
ddd = str(e.year) + '-' + str(e.month) + '-' + str(e.day)
len_c = len(ccc)
len_d = len(ddd)
x = int(round((len_kg1-len_c)/2,0))
y = int(round((len_kg2-len_d)/2,0))
c = ' '*x + ccc + ' '*x
d = ' '*y + ddd + ' '*y
p = document.add_paragraph('申请人:')
p.add_run(c).font.underline = True
p.add_run(' 申请时间:')
p.add_run(d).font.underline = True
# -----------------------------------------
p1 = '申请地点: '
kg1 = ' '
len_kg1 = len(kg1)
ccc = df.loc[i,'申请地点']
len_c = len(ccc)
x = int(round((len_kg1-len_c)/2,0))
c = ' '*x + ccc + ' '*x
p = document.add_paragraph('申请地点:')
p.add_run(c).font.underline = True
# -----------------------------------------
p1 = '审批人: 证件号: '
kg1 = ' '
kg2 = ' '
len_kg1 = len(kg1)
len_kg2 = len(kg2)
ccc = df.loc[i,'审批人1']
ddd = str(df.loc[i,'证件号1'])
len_c = len(ccc)
len_d = len(ddd)
x = int(round((len_kg1-len_c)/2,0))
y = int(round((len_kg2-len_d)/2,0))
c = ' '*x + ccc + ' '*x
d = ' '*y + ddd + ' '*y
p = document.add_paragraph('审批人:')
p.add_run(c).font.underline = True
p.add_run(' 证件号:')
p.add_run(d).font.underline = True
# -----------------------------------------
p1 = ' 证件号: '
kg1 = ' '
kg2 = ' '
len_kg1 = len(kg1)
len_kg2 = len(kg2)
ccc = df.loc[i,'审批人2']
ddd = str(df.loc[i,'证件号2'])
len_c = len(ccc)
len_d = len(ddd)
x = int(round((len_kg1-len_c)/2,0))
y = int(round((len_kg2-len_d)/2,0))
c = ' '*x + ccc + ' '*x
d = ' '*y + ddd + ' '*y
p = document.add_paragraph()
p.add_run(c).font.underline = True
paragraph_format = p.paragraph_format
paragraph_format.left_indent=Inches(0.5826772)
paragraph_format.first_line_indent=document.styles['Normal'].font.size * 1
p.add_run(' 证件号:')
p.add_run(d).font.underline = True
# -----------------------------------------
p1 = ' 证件号: '
kg1 = ' '
kg2 = ' '
len_kg1 = len(kg1)
len_kg2 = len(kg2)
ccc = df.loc[i,'审批人3']
ddd = str(df.loc[i,'证件号3'])
len_c = len(ccc)
len_d = len(ddd)
x = int(round((len_kg1-len_c)/2,0))
y = int(round((len_kg2-len_d)/2,0))
c = ' '*x + ccc + ' '*x
d = ' '*y + ddd + ' '*y
p = document.add_paragraph()
p.add_run(c).font.underline = True
paragraph_format = p.paragraph_format
paragraph_format.left_indent=Inches(0.5826772)
paragraph_format.first_line_indent=document.styles['Normal'].font.size * 1
p.add_run(' 证件号:')
p.add_run(d).font.underline = True
# # -----------------------------------------
p1 = '记录人: 联系电话: '
kg1 = ' '
kg2 = ' '
len_kg1 = len(kg1)
len_kg2 = len(kg2)
ccc = df.loc[i,'记录人']
ddd = str(df.loc[i,'联系电话'])
len_c = len(ccc)
len_d = len(ddd)
x = int(round((len_kg1-len_c)/2,0))
y = int(round((len_kg2-len_d)/2,0))
c = ' '*x + ccc + ' '*x
d = ' '*y + ddd + ' '*y
p = document.add_paragraph('记录人:')
p.add_run(c).font.underline = True
p.add_run(' 联系电话:')
p.add_run(d).font.underline = True
# # -----------------------------------------
document.add_paragraph()
document.add_paragraph('这是申请书的主要部分,通常要先介绍一下个人的现实情况、个人简历、家庭成员及社会关系情况。')
# # -----------------------------------------
p1 = ' 日期: '
kg1 = ' '
len_kg1 = len(kg1)
e = df.loc[i,"日期"]
ccc = str(e.year) + '-' + str(e.month) + '-' + str(e.day)
len_c = len(ccc)
x = int(round((len_kg1-len_c)/2,0))
c = ' '*x + ccc + ' '*x
p = document.add_paragraph(' ')
p.add_run(' 日期:')
p.add_run(c).font.underline = True
# # -----------------------------------------
# 保存
path = DesktopPath + '批量处理结果'+ '\\'
document.save(f"{path}{df.loc[i,'申请人']}.docx")
最后,还要推荐几篇文章,实现的方式也非常值得学习,冲!
Python+Excel+Word一秒制作百份合同 【Python实战案例】读取Excel批量替换Word局部信息 Python办公自动化|从Excel到Word
|