|
作为一个深度学习的学生,实验室的GPU显卡是排不上号的,于是乎本人就找到了一个很好用的GPU平台----恒源云 远程连接ssh软件:  第一步:我们先启动服务器 第二步: 端口 ip地址填写好 第一步:我们先启动服务器 第二步: 端口 ip地址填写好  登录成功了! 登录成功了! 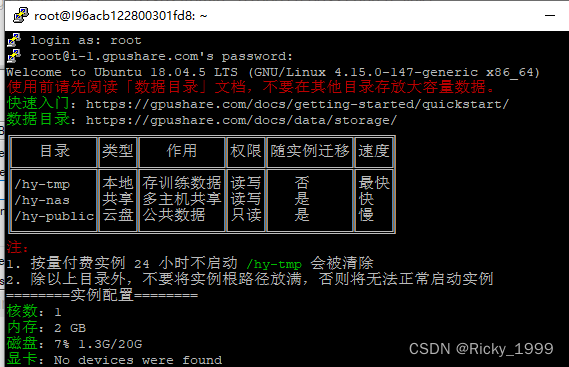 先来一个CNN minist手写字识别试试水吧! 先来一个CNN minist手写字识别试试水吧!
import torch
from torch.nn import Linear, ReLU
import torch.nn as nn
import numpy as np
from torch.autograd import Variable
from torchvision import datasets,transforms
from torch.autograd import Variable
import torch.optim as optim
transformation = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
#data/表示下载数据集到的目录,transformation表示对数据集进行的相关处理
train_dataset = datasets.MNIST('data/',train=True, transform=transformation,download=True)
test_dataset = datasets.MNIST('data/', train=False, transform=transformation,download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=True)
import torch.nn.functional as F
class Mnist_Net(nn.Module):
def __init__(self):
super(Mnist_Net,self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(10,20,kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50) #320是根据卷积计算而来4*4*20(4*4表示大小,20表示通道数)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
#x = F.dropout(x,p=0.1, training=self.training)
x = self.fc2(x)
return F.log_softmax(x,dim=1)
model = Mnist_Net()
model = model.cuda() #使用Gpu加速训练
optimizer = optim.SGD(model.parameters(), lr=0.01)#优化函数
#损失函数
criteon = nn.CrossEntropyLoss()
optimizer = optim.SGD(transfer_model.parameters(), lr=0.01)
transfer_model = transfer_model.cuda()
train_losses , train_accuracy = [],[]
val_losses , val_accuracy = [],[]
for epoch in range(10):
transfer_model.train()
running_loss =0.0
running_correct =0
for batch_idx,(x,target) in enumerate(train_loader):
#预测值logits
x,target = x.cuda(),target.cuda()
x,target = Variable(x),Variable(target)
logits = transfer_model(x)
loss = criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss +=loss.item()
preds = logits.data.max(dim=1,keepdim=True)[1]
running_correct += preds.eq(target.data.view_as(preds)).cpu().sum()
train_loss = running_loss/len(train_loader.dataset)
train_acc = 100*running_correct/len(train_loader.dataset)
train_losses.append(train_loss)
train_accuracy.append(train_acc)
print('epoch:{},train loss is{},train_acc is {}'.format(epoch,train_loss,train_acc))
test_loss =0.0
test_acc_num=0
#模型test
model.eval()
for data,target in test_loader:
data,target = data.cuda(),target.cuda()
data,target = Variable(data),Variable(target)
logits = transfer_model(data)
test_loss +=criteon(logits,target).item()
_,pred = torch.max(logits,1)
test_acc_num += pred.eq(target).float().sum().item()
test_los = test_loss/len(test_loader.dataset)
test_acc = test_acc_num/len(test_loader.dataset)
val_losses.append(test_los)
val_accuracy.append(test_acc)
print("epoch:{} total loss:{},acc:{}".format(epoch,test_los,test_acc))
新建一个python文件,直接训练! 
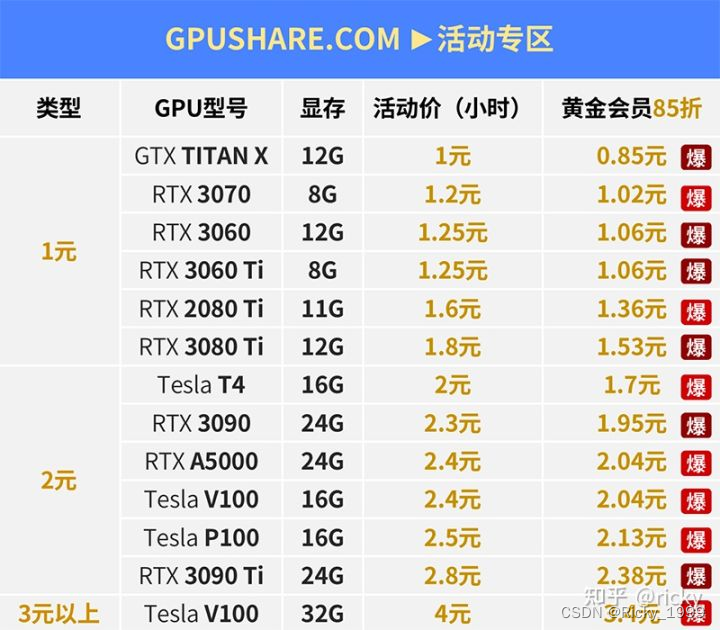
平台里预装好了一些主流的深度学习框架,即开即用,对于不想配环境的我来说非常便利。 另外还赠有100G,免费数据存储,实例关机状态下也可以上传数据。Nice!!! 还有无卡启动,便宜,方便调试。 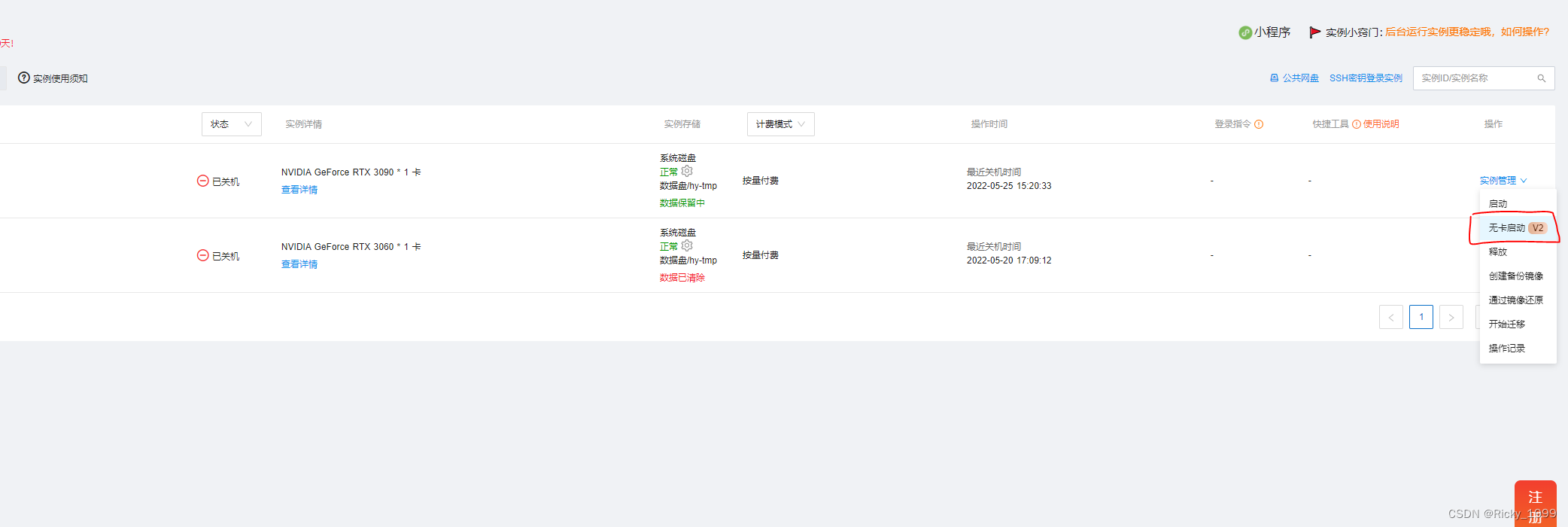
一些个性化功能如(无卡启动模式、实例可视化监控、支持公共网盘传输、共享数据集、镜像市场、备份镜像、团队共享、定时关机、实例升降配、小程序管理等) 
另外在手机上也可以控制实例进行开关机操作。 活动丰富(新人100元礼券、会员专属折扣、学生100元礼包、邀请有礼、每日签到、每月限定活动) 使用文档详实、技术团队支持、客服响应快速 平台强大的社区和社群,聚集了上万炼丹师交流分享
|