【爬虫学习】实战篇1:猫眼电影票房爬虫 |
您所在的位置:网站首页 › 实时票房哪里查看比较准确一点 › 【爬虫学习】实战篇1:猫眼电影票房爬虫 |
【爬虫学习】实战篇1:猫眼电影票房爬虫
|
今天咱们来学习一个爬虫的具体实战:爬取猫眼电影票房的数据。 目标:使用python自带的urllib库编写一个小程序,我们只需启动小程序,就可以实时爬取猫眼的电影票房数据,并自动将数据生成一个excel保存至本地文件夹。 接下来,我将尽可能详细地介绍爬虫编写的步骤,希望大家可以跟着我一步步操作,全部编写完成之后,我们可以展开想象的翅膀,触类旁通,使用相同的技巧去获取自己需要的公开数据吧! 步骤1:打开猫眼的官网,查看首页的内容,并获取对应的url。
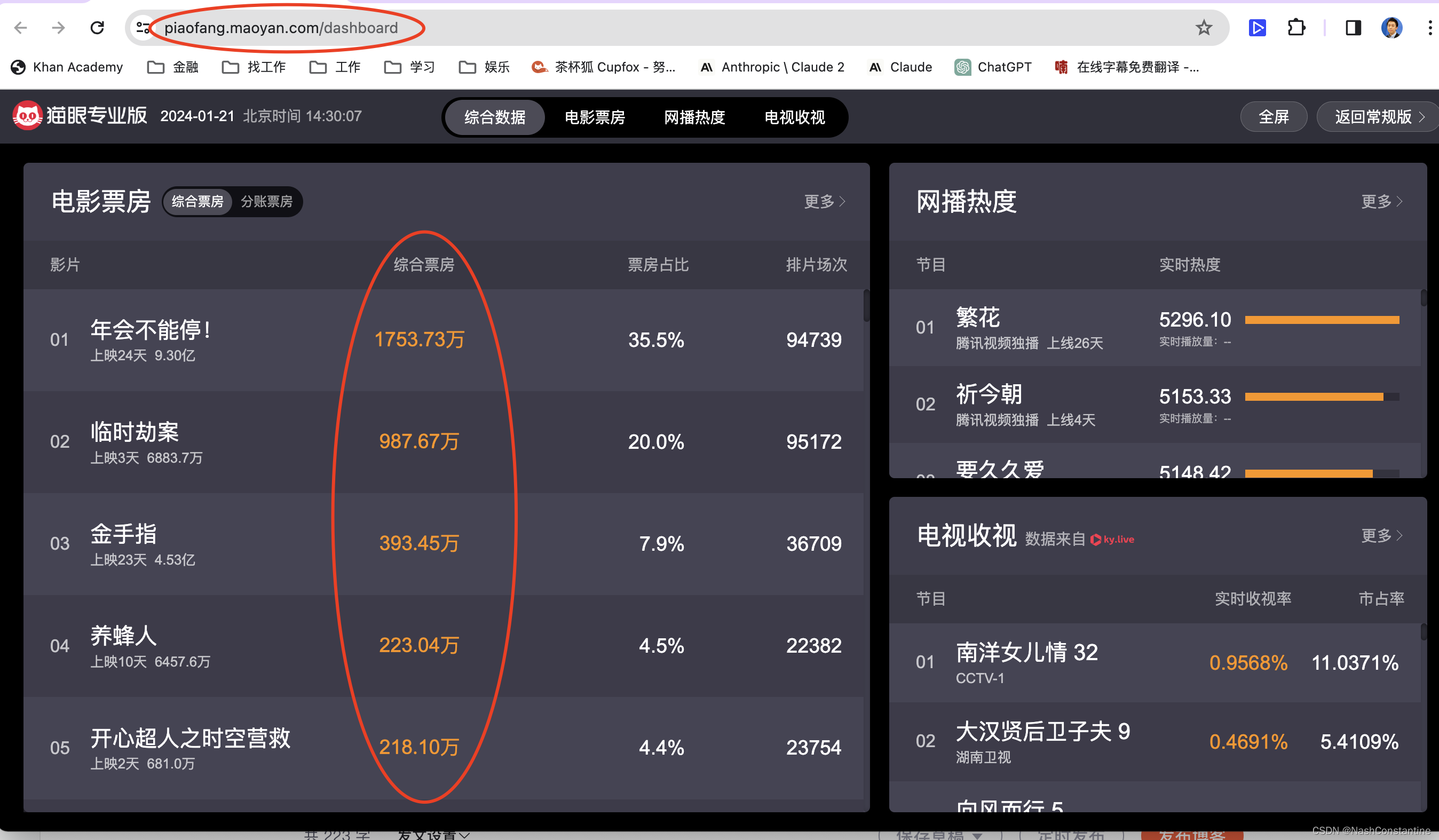
上图就是打开猫眼票房之后的页面,大约公布了80+部目前在放映的电影名称和综合票房的数据,这个数据就是我们希望爬取的数据。同时,url我们也已经知道了: https://piaofang.maoyan.com/dashboard 步骤2:打开python终端,导入urllib库和request模块,编写请求头,获取完整HTML代码。这个步骤是单纯地写代码,代码我就不详细解释了,如下: from urllib import request # 填写猫眼url: url = 'https://piaofang.maoyan.com/dashboard ' # 填写user-agent: header = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' } # 使用request模块中的Request类,创建一个猫眼url对应的类: resp = request.Request(url,headers=header) # 使用request模块中的urlopen函数,打开上面的resp: resp_html = request.urlopen(resp) # 打印猫眼的html代码: print(resp_html.read())运行代码,发生报错:
说实话,不太懂SSL证书的含义,但是通过CSDN查询,只要在代码开头引入ssl并取消ssl认证就不会再报错了。 from urllib import request # 引入ssl,取消全局ssl认证: import ssl ssl._create_default_https_context = ssl._create_unverified_context # 填写猫眼url: url = 'https://piaofang.maoyan.com/dashboard ' # 填写user-agent: header = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' } # 使用request模块中的Request类,创建一个猫眼url对应的类: resp = request.Request(url,headers=header) # 使用request模块中的urlopen函数,打开上面的resp: resp_html = request.urlopen(resp) # 打印猫眼的html代码: print(resp_html.read()) 上图即为猫眼HTML源代码了,内容是比较多的。 步骤3:对HTML源代码进行解码,把ASCII代码转换为中文字符。非常简单,在read方法后跟上使用decode方法,解码为utf-8,代码如下: from urllib import request # 引入ssl,取消全局ssl认证: import ssl ssl._create_default_https_context = ssl._create_unverified_context # 填写猫眼url: url = 'https://piaofang.maoyan.com/dashboard ' # 填写user-agent: header = { 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' } # 使用request模块中的Request类,创建一个猫眼url对应的类: resp = request.Request(url,headers=header) # 使用request模块中的urlopen函数,打开上面的resp: resp_html = request.urlopen(resp) # 打印猫眼的html代码: print(resp_html.read().decode('utf-8'))再运行代码一次,发现HTML代码中出现中文汉字,解码成功:  步骤4:发现需要的票房数据并不在HTML源代码中
步骤4:发现需要的票房数据并不在HTML源代码中
回到猫眼票房首页,随便选一个票房的数字,在python的代码输出端检索,发现没找到,表明票房的数据并未放在HTML源代码中,那么,票房数据是放在哪里呢? 我们在猫眼票房页面,右键-检查-network,我们发现电影名称或者票房数据似乎藏在以下文件中:
我们更新下代码:
|
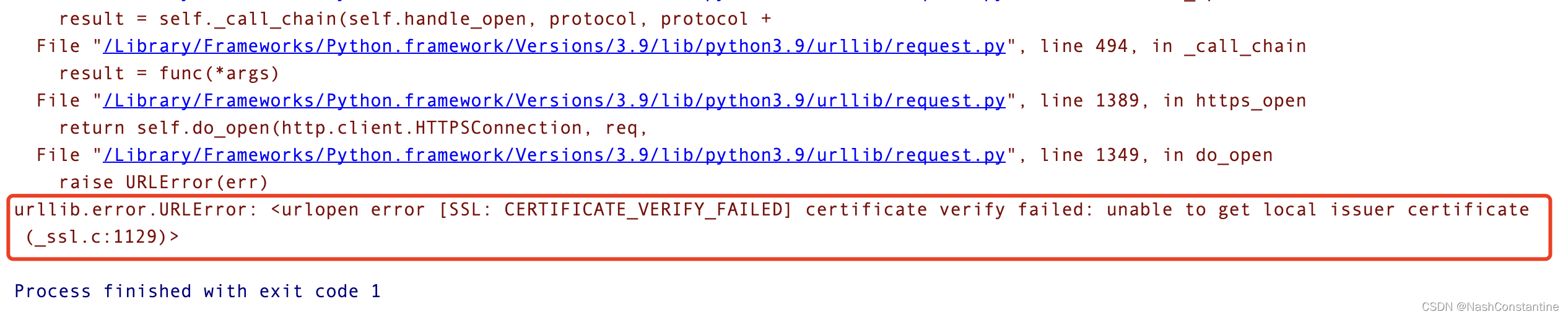 错误原因中文翻译:证书验证失败:无法获取本地颁发者证书。
错误原因中文翻译:证书验证失败:无法获取本地颁发者证书。
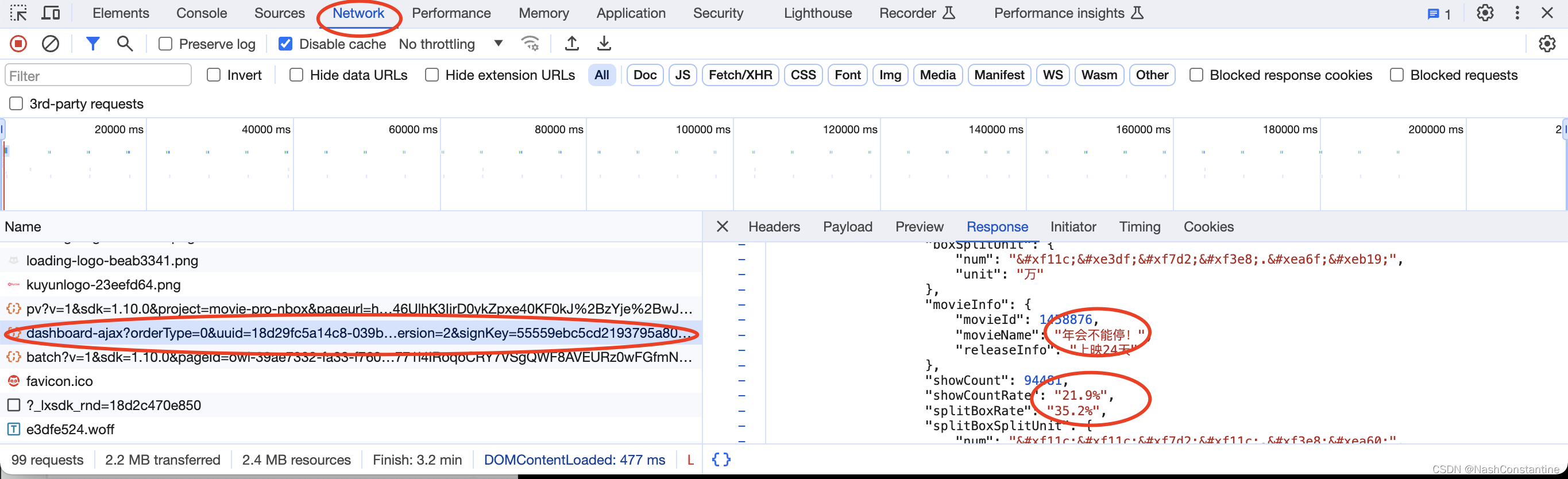

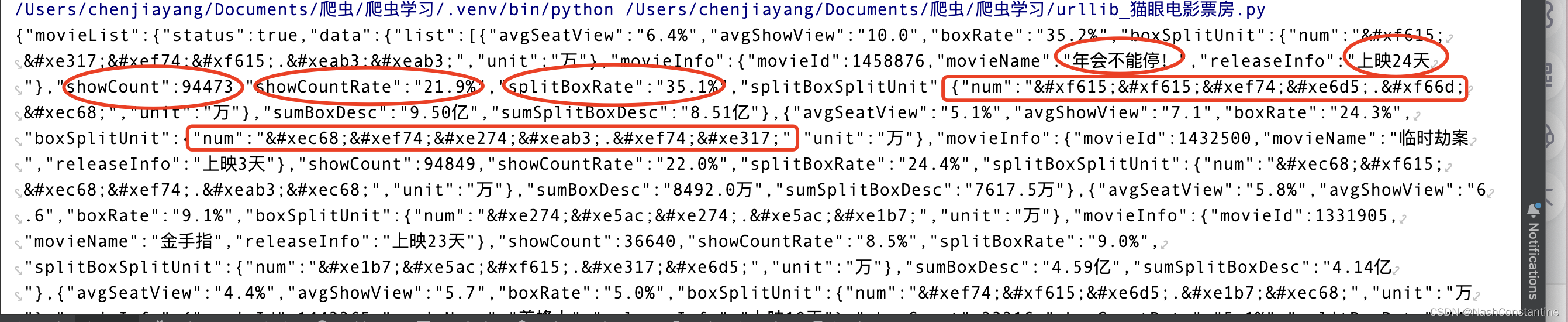 很多数据浮现出来,但是最重要的一些数据(红色方框),我们发现并不是阿拉伯数字,而是一串很奇怪的代码。这表明,猫眼知道了很多爬虫想要爬取票房数据,他们设置了加密,我们还需要解密这一串乱七八糟的代码!
很多数据浮现出来,但是最重要的一些数据(红色方框),我们发现并不是阿拉伯数字,而是一串很奇怪的代码。这表明,猫眼知道了很多爬虫想要爬取票房数据,他们设置了加密,我们还需要解密这一串乱七八糟的代码!【本文地址】
今日新闻 |
推荐新闻 |