Python爬虫教程30:Selenium网页元素,定位的8种方法! |
您所在的位置:网站首页 › 定位杆如何使用教程 › Python爬虫教程30:Selenium网页元素,定位的8种方法! |
Python爬虫教程30:Selenium网页元素,定位的8种方法!
|
Selenium可以驱动浏览器,完成各种网页浏览器的模拟操作,比如模拟点击等。要想操作一个元素,首先应该识别这个元素。人有各种的特征(属性),我们可以通过其特征找到人,如通过身份证号、姓名、家庭住址。同理,一个元素会有各种的特征(属性),我们可以通过这个属性找到这对象。 1.什么是元素? 元素:由标签头 + 标签尾 + 标签头和标签尾包括的文本内容; 元素的信息就是指元素的标签名及元素的属性; 元素的层级结构就是指元素之间相互嵌套的层级结构; 元素定位最终就是通过元素的信息或者元素的层级结构来进行元素定位; 2.查看元素信息:在浏览器中,选中元素,右键点击“检查”,即可在Elements中查看元素信息,以检查百度首页搜索框为例,如下图所示: (一)根据id定位:如下图百度html中,具有id属性=“kw”,所以可以根据id来操作元素。下面代码实现的功能,打开百度,并向输入框中输入李白。 (二)根据name定位:在HTML当中,name属性和id属性的功能基本相同,只是name属性并不是唯一的,如果遇到没有id标签的时候,我们可以考虑通过name标签来进行定位。 百度搜索框元素html结构: 元素定位: element = driver.find_element(By.NAME, 'wd')(三)通过class name定位:我们也可以基于class属性来定位元素。通常当我们看到有多个并列的元素如list表单,class用的都是共用同一个。 百度搜索框元素html结构: 元素定位: element = driver.find_element(By.CLASS_NAME, 's_ipt')(四)tag标签定位:HTML是通过tag来定义一类功能的,比如input是输入,table是表格,tbody是表格主体等。每个元素其实就是一个tag,由于一个tag用来定义一类功能,一个网页往往有很多同类tag,所以很难通过tag去区分不同的元素。 b战搜索框元素html结构 元素定位:打开b站,在搜索框里面实现,自动输入周杰伦。 # @Author : 小红牛 # 微信公众号:WdPython import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.bilibili.com/') element = driver.find_element(By.TAG_NAME, 'input') element.send_keys('周杰伦') time.sleep(5) # 关闭网页 driver.quit()(五)link text定位,通过超链接的文本定位元素,如打开百度首页,模拟点击新闻链接后跳转新的网页。 百度搜索框,新闻元素html结构: 新闻元素定位: import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.baidu.com') # 打开百度首页,点击新闻链接 element = driver.find_element(By.LINK_TEXT, '新闻') element.click() time.sleep(5) # 关闭网页 driver.quit()(六)partial link text定位:有时候一个超链接的文本很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,进行模糊匹配。 百度搜索框,新闻元素html结构: 新闻元素定位:还是‘’新闻链接‘’的点击,这会只输入‘’闻‘’就可以定位元素了。 element = driver.find_element(By.PARTIAL_LINK_TEXT, '闻')(七)XPath定位:Xpath是一种在XML和HTML文档中查找信息的语言,通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。下面以定位百度搜索框为例子讲解。如下图开发者工具中,不需要你自己写xp语法,直接复制Xpath表示是相对路径,复制完整Xpath表示是绝对路径。 上述xpath定位表达式从html dom树的根节点(html节点)开始逐层查找,最后定位到“input”节点。特点:路径唯一,但是容易受页面改动影响,即便页面代码结构只发生了微小的变化,也可能会造成原先有效的xpath定位表达式定位失败。 相对路径:从匹配选择的当前节点开始选择文档中的节点,而不考虑它们的位置,起始于双斜杠(//)。相对路径的xpath定位表达式更加简洁,推荐使用相对路径的xpath表达式。 element = driver.find_element(By.XPATH, '//*[@id="kw"]') element.send_keys('李白')(八)css selector定位,来进行页面元素的定位的,Css定位可以通过id选择器、class选择器、标签选择器和属性选择器。 百度搜索框元素html结构: 元素定位: # @Author : 小红牛 # 微信公众号:WdPython # 1. id选择器, 用#号 来定义 element = driver.find_element(By.CSS_SELECTOR, '#kw') # 2.class选择器,用 .来定义 # element = driver.find_element(By.CSS_SELECTOR, '.s_ipt') # 3.标签属性定位,格式:[属性名=”属性值”],或标签名[属性名=属性值] # element = driver.find_element(By.CSS_SELECTOR, 'input[id="kw"]') # element = driver.find_element(By.CSS_SELECTOR, '[autocomplete="off"]') # 4.组合定位写法 # element = driver.find_element(By.CSS_SELECTOR, 'input.s_ipt') # element = driver.find_element(By.CSS_SELECTOR, 'input#kw')完毕!!感谢您的收看 ----------★★历史博文集合★★---------- 我的零基础Python教程,Python入门篇 进阶篇 视频教程 Py安装py项目 Python模块 Python爬虫 Json Xpath 正则表达式 Selenium Etree CssGui程序开发 Tkinter Pyqt5 列表元组字典数据可视化 matplotlib 词云图 Pyecharts 海龟画图 Pandas Bug处理 电脑小知识office自动化办公 编程工具 |
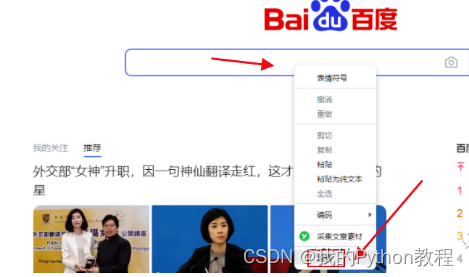 点击检查后,就可以在开发者工具中,快速定位百度输入框的元素位置,如下图。
点击检查后,就可以在开发者工具中,快速定位百度输入框的元素位置,如下图。 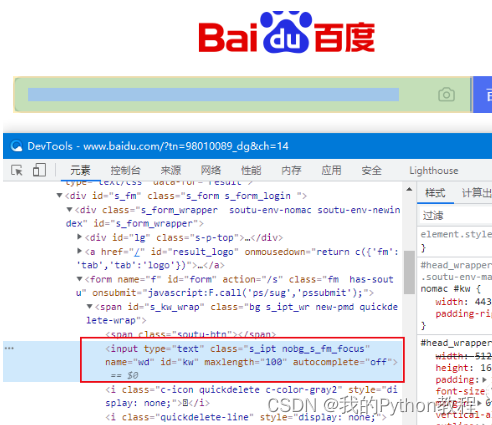 3.元素定位方法,selenium 提供了一系列的对象定位方法,常用的有以下8种:
3.元素定位方法,selenium 提供了一系列的对象定位方法,常用的有以下8种: 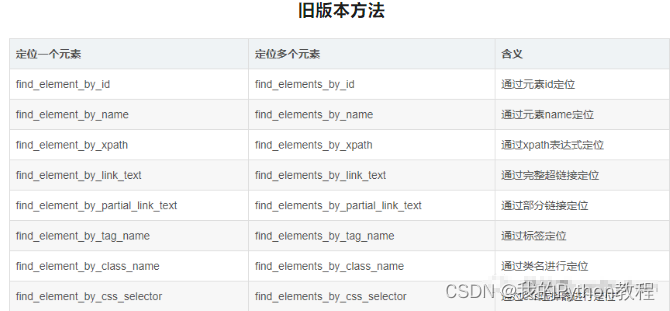
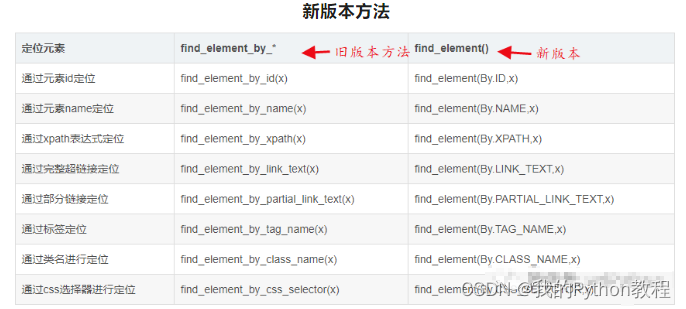 import selenium目前,由于selenium新版本的升级,使用find_element_by_*,会提示弃用警告,建议使用find_element()以适应最新的版本。以下代码中,我都用的是4.13版本。
import selenium目前,由于selenium新版本的升级,使用find_element_by_*,会提示弃用警告,建议使用find_element()以适应最新的版本。以下代码中,我都用的是4.13版本。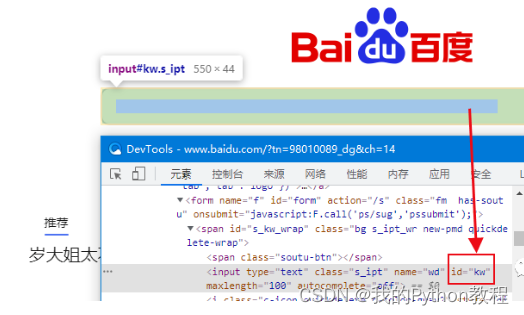
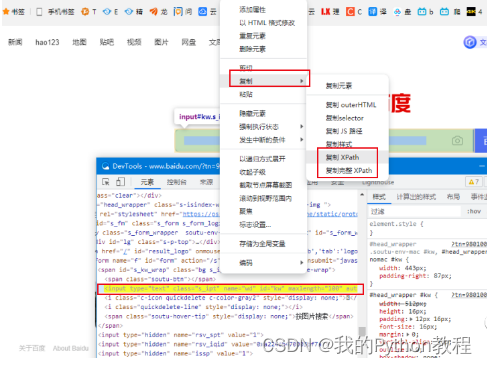 绝对路径:表示页面元素,在网页的HTML代码结构中,从根节点一层层地搜索到需要被定位的页面元素,绝对路径起始于正斜杠(/),每一步均被斜杠分割。
绝对路径:表示页面元素,在网页的HTML代码结构中,从根节点一层层地搜索到需要被定位的页面元素,绝对路径起始于正斜杠(/),每一步均被斜杠分割。
【本文地址】
今日新闻 |
推荐新闻 |