GoogLeNet论文阅读 |
您所在的位置:网站首页 › 学术期刊的字母代号是 › GoogLeNet论文阅读 |
GoogLeNet论文阅读
|
GoogLeNet
文章目录
GoogLeNet单词不重要重要
摘要1*1卷积核的作用全局平均池化(Global Average Pooling,GAP)Motivation小结GoogLeNet V1
论文题目:Going deeper with convolutions
参考资料:https://blog.csdn.net/qq_39297053/article/details/130667442?spm=1001.2014.3001.5502
单词
不重要
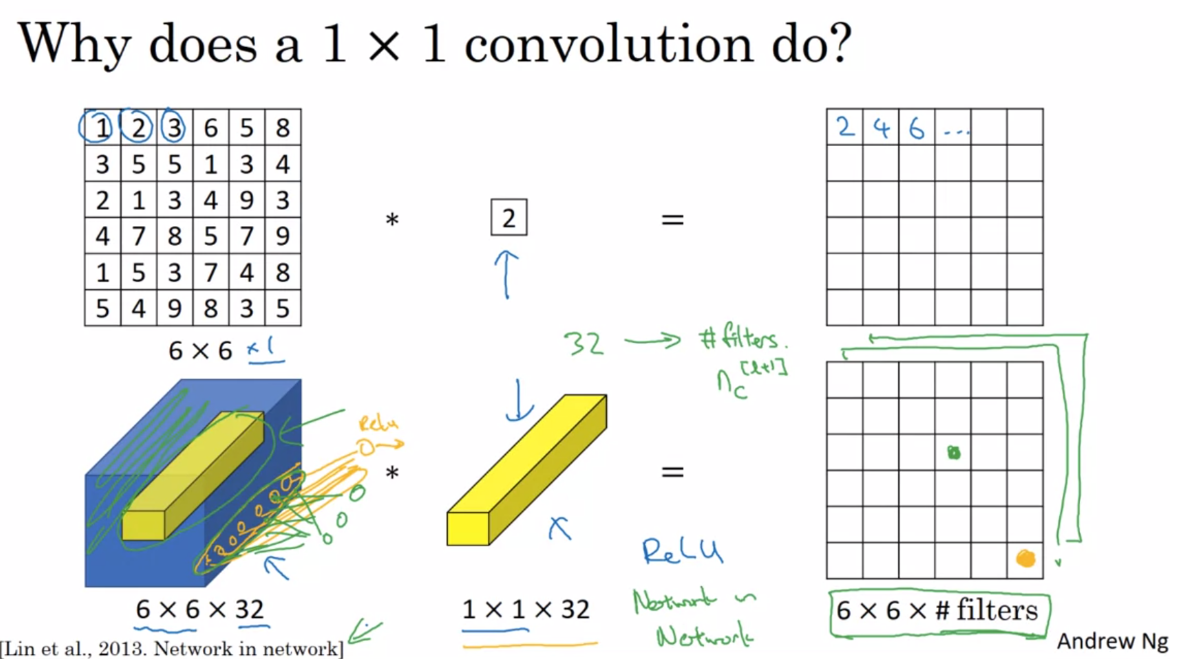
dual purpose 双重目的 object detection 对象检测 One must be cautious though 值得注意的是 straightforward 直截了当 重要sparse structure 稀疏的结构 computational budget is always finite 计算预算总是有限的 any uniform increase in the number of their filters results in a quadratic increase of computation 滤波器数量的任何均匀增加都会导致计算量呈二次方增加 摘要We propose a deep convolutional neural network architecture codenamed Inception that achieves the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14).The main hallmark of this architecture is the improved utilization of the computing resources inside the network. By a carefully crafted design, we increased the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular in- carnation used in our submission for ILSVRC14 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection. 我们提出了一个代号为 Inception 的深度卷积神经网络架构,它在 2014 年 ImageNet 大规模视觉识别挑战赛 (ILSVRC14) 中实现了分类和检测的最新技术水平。这种架构的主要特点是提高了网络内部计算资源的利用率。通过精心设计,我们增加了网络的深度和宽度,同时保持计算预算不变。为了优化质量,架构决策基于 Hebb 原理和多尺度处理的直觉。我们提交给 ILSVRC14 的一个特定化身称为 GoogLeNet,一个 22 层的深度网络,其质量在分类和检测的背景下进行评估。 赫布理论(Hebbian principle):两个神经元或者神经元系统,如果总是同时被激发,就会形成一种"组合",其中一个神经元的激发会促进另一个的激发。 In this paper, we will focus on an efficient deep neural network architecture for computer vision, codenamed Inception, which derives its name from the Network in network paper by Lin et al [12] in conjunction with the famous “we need to go deeper” internet meme 在本文中,我们将重点关注一种用于计算机视觉的高效深度神经网络架构,代号为 Inception,其名称源自 Lin 等人[12]网络论文中的 Network,并结合著名的“我们需要更深入”网络梗"。 Network in network这篇论文主要讲了1*1卷积核和GAP 1*1卷积核的作用1x1卷积一般只改变输出通道数(channels),称之为升维、降维,而不改变输出的宽度和高度
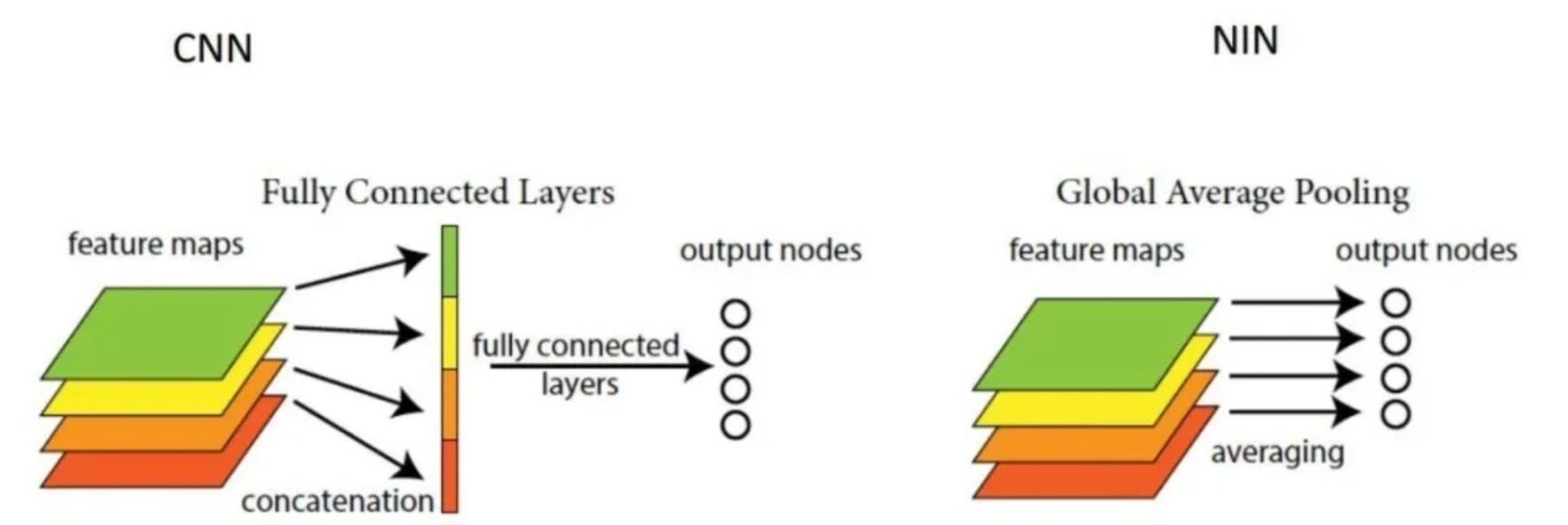
当输入的矩阵channel为1时,此时1x1卷积的channel也为1。这时候只能起到升维的作用。即再来一个卷积核,得到一个结果,得到第二个通道。 当输入为6x6x32时,1x1卷积的形式是1x1x32,当只有一个1x1卷积核的时候,此时输出为6x6x1。 因为每一个通道都要和1x1卷积做相乘求和的操作,所以有几个卷积核,输出的通道数就为几。 即若1x1卷积的形式是1x1xfilter,则输出为6x6xfliter 其实1x1卷积,可以看成一种全连接(full connection)。 However, in our setting, 1 × 1 convolutions have dual purpose: most critically, they are used mainly as dimension reduction modules to remove computational bottlenecks, that would otherwise limit the size of our networks. This allows for not just increasing the depth, but also the width of our networks without significant performance penalty. 然而,在我们的设置中,1 × 1卷积有双重目的:最关键的是,它们主要用作降维模块,以消除计算瓶颈,否则将限制我们网络的大小。这不仅可以增加网络的深度,还可以增加网络的宽度,而不会对性能造成重大影响。 宽度:层级结构 (如果这一层是神经网络就是结点的数量,如果这一层是卷积那就是kernel的数量) 深度:特征图的数量 全局平均池化(Global Average Pooling,GAP)全局平均池化层(GAP)在2013年的《Network In Network》(NIN)中首次提出 一般情况下,卷积层用于提取二维数据如图片、视频等的特征,针对于具体任务(分类、回归、图像分割)等,卷积层后续会用到不同类型的网络,拿分类问题举例,最简单的方式就是将卷积网络提取出的特征(feature map)输入到softmax全连接层对应不同的类别。首先,这里的feature map是二维多通道的数据结构,类似于三个通道(红黄绿)的彩色图片,也就是这里的feature map具有空间上的信息;其次,在GAP被提出之前,常用的方式是将feature map直接拉平成一维向量(下图左),但是GAP不同,是将每个通道的二维图像做平均,最后也就是每个通道对应一个均值(下图右)。
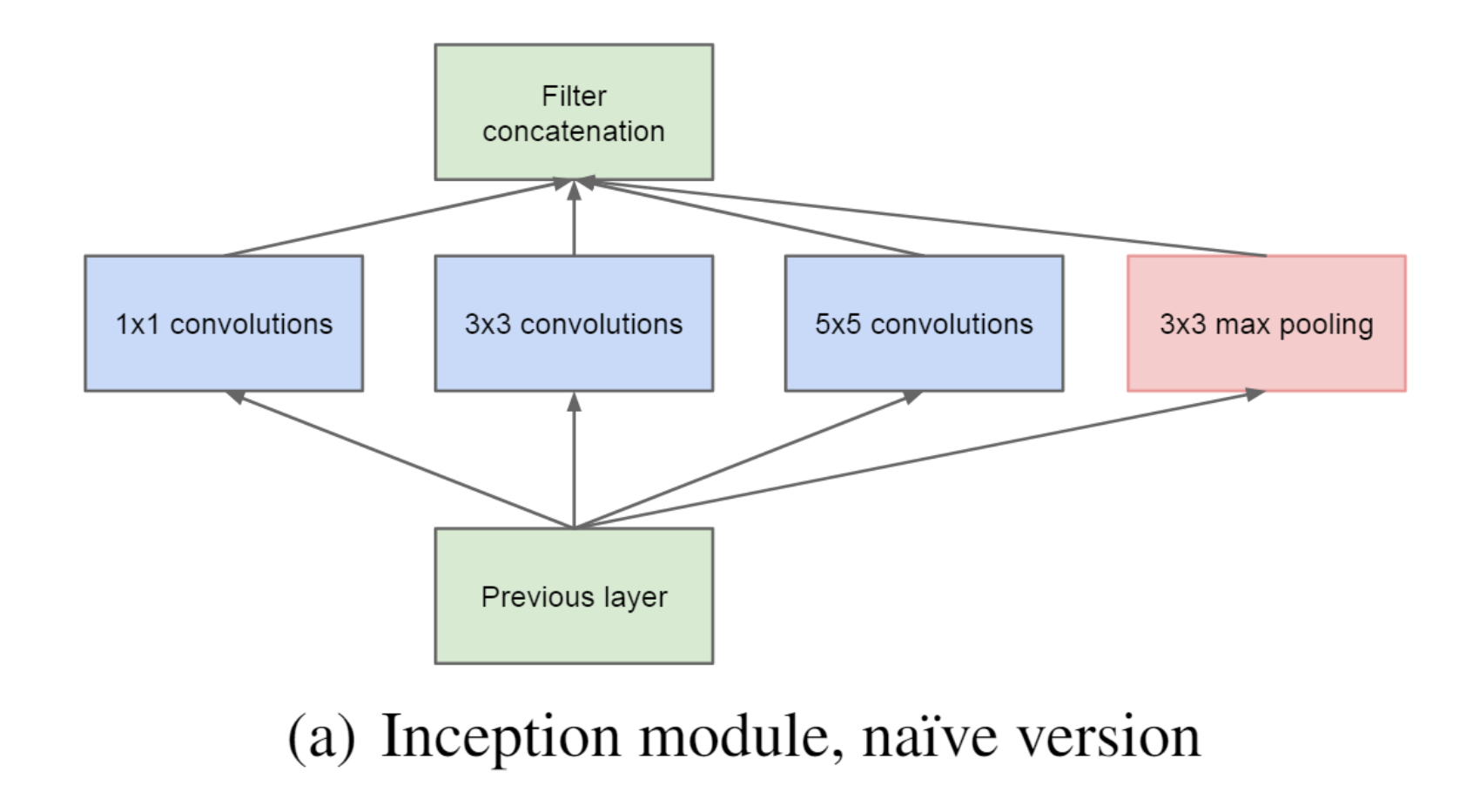
GAP的优势: 1. 抑制过拟合。直接拉平做全连接层的方式依然保留了大量的空间信息,假设feature map是32个通道的10 *10图像,那么拉平就得到了32 * 10 * 10的向量,如果是最后一层是对应两类标签,那么这一层就需要3200 * 2的权重矩阵,而GAP不同,将空间上的信息直接用均值代替,32个通道GAP之后得到的向量都是32的向量,那么最后一层只需要32 * 2的权重矩阵。相比之下GAP网络参数会更少,而全连接更容易在大量保留下来的空间信息上面过拟合。 2. 可解释的雏形。在《NIN》原文当中有这样一句话,GAP相比全连接更加自然地加强了类别和feature map之间的联系,(这个类别指的是分类的类别) 3. 输入尺寸更加灵活。在第1点的举例里面可以看到feature map经过GAP后的神经网络参数不再与输入图像尺寸的大小有关,也就是输入图像的长宽可以不固定。 MotivationThe most straightforward way of improving the performance of deep neural networks is by increasing their size. 提高深度神经网络性能的最直接方法是增加其规模。 This is an easy and safe way of training higher quality models, especially given the availability of a large amount of labeled training data. However, this simple solution comes with two major drawbacks. 这是训练更高质量模型的一种简单且安全的方法,特别是考虑到大量标记训练数据的可用性。然而,这个简单的解决方案有两个主要缺点。 Bigger size typically means a larger number of parameters, which makes the enlarged network more prone to over- fitting, especially if the number of labeled examples in the training set is limited. This is a major bottleneck as strongly labeled datasets are laborious and expensive to obtain, often requiring expert human raters to distinguish between various fine-grained visual categories. 更大的尺寸通常意味着更多的参数,这使得扩大的网络更容易过度拟合,特别是在训练集中标记示例的数量有限的情况下。这是一个主要瓶颈,因为强标记数据集的获取既费力又昂贵,通常需要专业的人类评估者来区分各种细粒度的视觉类别 The other drawback of uniformly increased network size is the dramatically increased use of computational resources. For example, in a deep vision network, if two convolutional layers are chained, any uniform increase in the number of their filters results in a quadratic increase of computation. If the added capacity is used inefficiently (for example, if most weights end up to be close to zero), then much of the computation is wasted. As the computational budget is always finite, an efficient distribution of computing resources is preferred to an indiscriminate increase of size, even when the main objective is to increase the quality of performance 统一增加网络规模的另一个缺点是计算资源的使用急剧增加。例如,在深度视觉网络中,如果链接两个卷积层,则其滤波器数量的任何均匀增加都会导致计算量呈二次方增加。如果增加的容量使用效率低下(例如,如果大多数权重最终接近于零),则大部分计算都会被浪费。由于计算预算始终是有限的,因此即使主要目标是提高性能质量,计算资源的有效分配也优于不加选择地增加规模 The fundamental way of solving both issues would be by ultimately moving from fully connected to sparsely connected architectures, even inside the convolutions. 解决这两个问题的基本方法是最终从完全连接转向稀疏连接架构,甚至在卷积内部也是如此。 On the downside, todays computing infrastructures are very inefficient when it comes to numerical calculation on non-uniform sparse data structures 缺点是,当涉及到非均匀稀疏数据结构的数值计算时,当今的计算基础设施效率非常低 所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能 因此作者就提出了Inception的结构来实现。 The main idea of the Inception architecture is to consider how an optimal local sparse structure of a convolutional vision network can be approximated and covered by readily available dense components Inception架构的主要思想是考虑如何用容易获得的密集组件来近似和覆盖卷积视觉网络的最佳局部稀疏结构
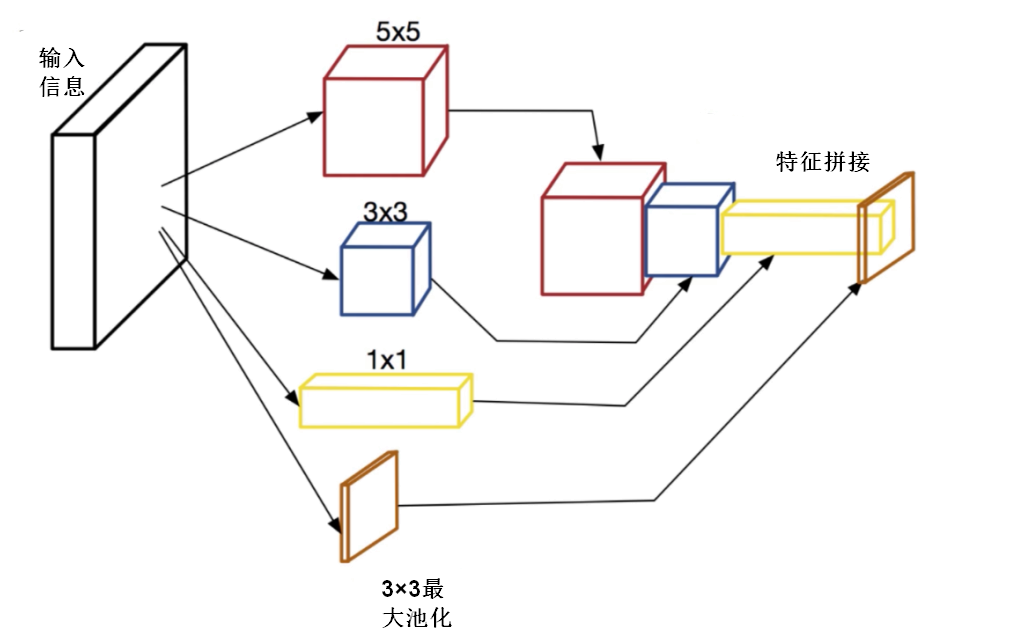
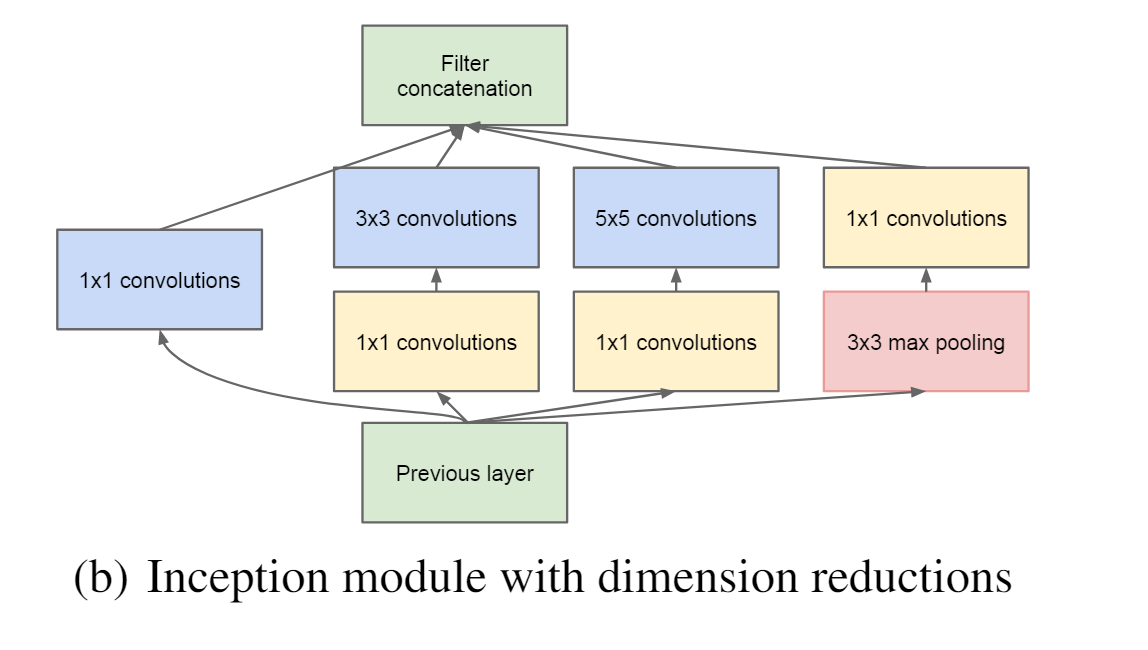
具体来说,就是将输入信息复制四份,分别送入四个不同的分支,分支中是卷积核尺寸不同的卷积操作,四个分支卷积计算后的feature maps在channel维度上合并,得到一组feature map送入后续操作,如下图所示 对上图做以下说明: 卷积核的大小在神经网络里是一种超参数,没有一种严格的数学理论证明那种尺寸的卷积核更适合提取特征,因此GoogLeNet选择了成年人的方式:我全都要。 采用不同大小的卷积核意味着不同大小的计算感受野,最后拼接操作意味着不同尺度特征的融合; 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接在channel维度拼接在一起了; 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling操作。 since pooling operations have been essential for the success in current state of the art convolutional networks 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。 但是,使用5x5的卷积核仍然会带来相对较大的计算量。 为此,作者先采用1x1卷积核来进行降维。 例如:上一层的输出数据形状为(100x100x128),经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据形状为(100x100x256)。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据的形状仍为(100x100x256),但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。 改进后的网络模型子结构如下:
GoogLeNetV1模型的最大特点在于使用了Inception模块,该模块可以同时使用多种不同尺寸的卷积核和池化层来提取特征,从而增加网络的表达能力和准确性,同时减少了模型的参数数量。Inception模块包含了多个不同的卷积和池化分支,每个分支都有不同的卷积核尺寸和步长。在训练过程中,网络会自动学习如何选择最优的分支以及如何将它们组合起来。 另外,GoogLeNetV1还采用了全局平均池化来替代打平操作,减少模型的参数数量,并防止过拟合。全局平均池化可以将整个特征图进行平均化操作,得到一个特征向量作为最终的输出。 GoogLeNetV1还引入了一种叫做“辅助分类器”的技术,用于帮助网络更快地收敛。该技术在网络中添加了两个辅助的分类器,分别在中间层和末尾层进行分类,可以在训练过程中提供额外的监督信号,从而促进网络的训练。 GoogLeNetV1在ImageNet图像分类竞赛中取得了优异的成绩,准确率达到了74.8%,并且模型参数数量仅为AlexNet的1/12。这表明了GoogLeNetV1在参数数量和分类准确率之间取得了很好的平衡。 |
【本文地址】
今日新闻 |
推荐新闻 |