通俗讲解Pytorch梯度的相关问题:计算图、no |
您所在的位置:网站首页 › 如何计算梯度计算公式图解 › 通俗讲解Pytorch梯度的相关问题:计算图、no |
通俗讲解Pytorch梯度的相关问题:计算图、no
|
文章目录
with torch.no_grad()和requires_gradbackward()Variable,Parameter和torch.tensor()zero_grad()计算图with torch.no_grad()和backward()with torch.no_grad()和detach()补充
既然涉及梯度,不得不先谈谈requires_grad。
import torch
with torch.no_grad()和requires_grad
下面先来做做题: a=torch.tensor([1.1]) print(a.requires_grad) #答案是? a=torch.tensor([1.1],requires_grad=True) b=a*2 print(b.requires_grad) #答案是? a=torch.tensor([1.1],requires_grad=True) with torch.no_grad(): b=a*2 print(a.requires_grad) print(b.requires_grad) #答案是?答案是:假真真假。 backward()一个requires_grad为真的tensor可以backward(),而backward()就是根据计算图求梯度。所以我们可以查看a的梯度。即b对a的偏导,直觉上就是2。 a=torch.tensor([1.1],requires_grad=True) b=a*2 print(b.requires_grad) print(b) b.backward() print(a.grad)
个人理解是:torch.tensor()、torch.autograd.Variable和torch.nn.Parameter 基本一样。 前两者都可以设置requires_grad参数,后者则直接默认requires_grad=True。 三者都拥有.data,.grad,.grad_fn等属性。 所以,只要requires_grad=True,都可以计算梯度以及backward()。 zero_grad() a = torch.tensor([1.1], requires_grad=True) b = a * 2 print(b) c = b + 3 print(c) b.backward(retain_graph=True)#计算图在backward一次之后默认就消失,我们下面还要backward一次,所以需要retain_graph=True保存这个图。否则下面会报错。 print(a.grad) c.backward() print(a.grad)
以上面这个代码为例,其计算图如下:
UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won’t be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more information. 这是因为在Pytorch中不会对非叶子节点保存梯度,但是根据求导的链式法则,计算梯度肯定要。我们仔细观察上面那个计算图,只有如下是叶子节点 拿神经网络举个例子给你,变量a就相当于神经网络中的参数(需要求梯度并且更新),那些常量就相当于你的输入,不要计算梯度,自然也不需要更新 知识拓展:如果非要计算c对b的梯度怎么办呢?使用retain_grad()。 a = torch.tensor([1.1], requires_grad=True) b = a * 2 b.retain_grad() c = b + 3 c.backward() print(a.grad) print(b.grad) with torch.no_grad()和backward() a = torch.tensor([1.1], requires_grad=True) b = a * 2 with torch.no_grad(): c = b + 2 print(c.requires_grad) d = torch.tensor([10.0], requires_grad=True) e = c * d print(e.requires_grad) e.backward() print(d.grad) print(a.grad)
我们根据前面所学的知识,推导出前3个结果应该已经没有问题了,但是第4个怎么解释呢?很简单一句话,在计算图中,非叶子节点c作为“中间人”,如果其requires_grad=False,那么其前面的所有变量都无法反向传播,自然也就没有梯度,相当于卡住了。 with torch.no_grad()和detach()和上一个代码作为对照,有的时候with torch.no_grad()和detach()有异曲同工之妙,看招如下: a = torch.tensor([1.1], requires_grad=True) b = a * 2 c = b + 2 print(c) print(c.requires_grad) c=c.detach() print(c) print(c.requires_grad) d = torch.tensor([10.0], requires_grad=True) e = c * d print(e.requires_grad) e.backward() print(d.grad) print(a.grad)可以看到,detach()也可以让计算图上的节点c失效。这里需要补充一下detach()的原理:让其grad_fn没有了,也让其requires_grad=False。这个时候,其是一个常量!!!!!!。 补充上面的计算图的例子其实是算简单的,虽然对于90%的操作都已经够用了。但是如果设计到对requires_grad=true的节点进行更改的时候,极难,超级难理解,也极易出错。也就是传说中的inplace操作。 下面做一个小测试: b=nn.Parameter(torch.rand(3,2)) c=torch.tensor([1.,2.]) a=nn.Parameter(torch.rand(2,3)) a[0]=torch.matmul(b,c)#是否报错,若报错,则删除此句。 a.data[0]=torch.matmul(b,c)#是否报错,若报错,则删除此句。 e=a[0]*2 e.sum().backward()#b是否有梯度?答案是:报错,不报错,没有梯度。 embedding=nn.Parameter(torch.rand(2,3)) d=nn.Parameter(torch.rand(3,3)) user_embeddings=embedding.clone() user_embedding_input = user_embeddings[0] a=user_embedding_input*3#option1 print(a) a=torch.matmul(d,user_embedding_input)#option2 print(a) user_embeddings[0]=a loss=a.sum() loss.backward()#是否报错?报错。 embedding=nn.Parameter(torch.rand(2,3)) d=nn.Parameter(torch.rand(3,3)) user_embeddings=embedding.clone() user_embedding_input = user_embeddings[[0],:] # a=user_embedding_input*3#option1 # print(a) a=torch.matmul(user_embedding_input,d)#option2 print(a) user_embeddings[[0],:]=a loss=a.sum() loss.backward()#是否报错?不报错 embedding=nn.Parameter(torch.rand(2,3)) d=nn.Parameter(torch.rand(3,3)) user_embeddings=embedding.clone() user_embedding_input = user_embeddings[[0],:] a=torch.matmul(user_embedding_input,d) print(a) user_embeddings[[0],:]=a user_embedding_input=3#question line loss=a.sum() loss.backward()#是否报错?不报错。 如果你上面都能清楚画出计算图并且说出原因,那么你大概率是掌握了。但是如果还有疑问,请看。 |

 我们发现,b对a的梯度是2没有错,但是c对a的梯度是4,有错。这是因为没有对梯度进行清0,不清零的话,默认进行梯度叠加,Pytorch不设置自动清零,是因为叠加梯度有一些应用场景(例如一个数据x1前向传播,然后计算loss1,反向传播,又来一个数据x2前向传播,然后计算loss2,反向传播,这个时候,我们得到的梯度是叠加的,其现实意义是根据loss1+loss2求梯度(求导法则,loss相加,梯度也是相加),这其实就是batch实现需要的,甚至你可以变相实现更大的batch,例如硬件有限,只能32,你各一次zero_grad,那么久实现了64的batch_size)其实。所以我们需要手动清零。
我们发现,b对a的梯度是2没有错,但是c对a的梯度是4,有错。这是因为没有对梯度进行清0,不清零的话,默认进行梯度叠加,Pytorch不设置自动清零,是因为叠加梯度有一些应用场景(例如一个数据x1前向传播,然后计算loss1,反向传播,又来一个数据x2前向传播,然后计算loss2,反向传播,这个时候,我们得到的梯度是叠加的,其现实意义是根据loss1+loss2求梯度(求导法则,loss相加,梯度也是相加),这其实就是batch实现需要的,甚至你可以变相实现更大的batch,例如硬件有限,只能32,你各一次zero_grad,那么久实现了64的batch_size)其实。所以我们需要手动清零。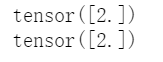
 我们再来做一个实验,c对b的梯度是多少?很多人直接说1,但是在Pytorch中这个不允许计算。
我们再来做一个实验,c对b的梯度是多少?很多人直接说1,但是在Pytorch中这个不允许计算。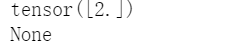 而且还发出了警告提示信息:
而且还发出了警告提示信息: 进一步,在Pytorch中只会对变量a求梯度,而2,3是常量。所以我们只得到了变量a的梯度。
进一步,在Pytorch中只会对变量a求梯度,而2,3是常量。所以我们只得到了变量a的梯度。

【本文地址】
今日新闻 |
推荐新闻 |