设备树dts/dtsi格式 |
您所在的位置:网站首页 › 如何编写一个dts文件的程序 › 设备树dts/dtsi格式 |
设备树dts/dtsi格式
|
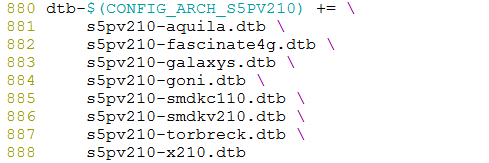
说明:后续的博文参考自韦东山老师的设备树视屏,老师用的是2440的开发板,我用的是s5pv210的开发板。原理一样 一、前言简单的说,如果要使用Device Tree,首先用户要了解自己的硬件配置和系统运行参数,并把这些信息组织成Device Tree source file。通过DTC(Device Tree Compiler),可以将这些适合人类阅读的Device Tree source file变成适合机器处理的Device Tree binary file(有一个更好听的名字,DTB,device tree blob)。在系统启动的时候,boot program(例如:firmware、bootloader)可以将保存在flash中的DTB copy到内存(当然也可以通过其他方式,例如可以通过bootloader的交互式命令加载DTB,组织成DTB保存在内存中),并把DTB的起始地址传递给client program(例如OS kernel,bootloader或者其他特殊功能的程序)。对于计算机系统(computer system),一般是firmware->bootloader->OS,对于嵌入式系统,一般是bootloader->OS。 二、设备树的组成和应用 2.1 DTS和DTSI *.dts文件是一种ASCII文本对Device Tree的描述,放置在内核的/arch/arm/boot/dts目录。一般而言,一个*.dts文件对应一个ARM的machine。 *.dtsi文件作用:由于一个SOC可能有多个不同的电路板,而每个电路板拥有一个 *.dts。这些dts势必会存在许多共同部分,为了减少代码的冗余,设备树将这些共同部分提炼保存在*.dtsi文件中,供不同的dts共同使用。*.dtsi的使用方法,类似于C语言的头文件,在dts文件中需要进行include *.dtsi文件。当然,dtsi本身也支持include 另一个dtsi文件。 2.2. DTC DTC为编译工具,它可以将.dts文件编译成.dtb文件。DTC的源码位于内核的scripts/dtc目录,内核选中CONFIG_OF,编译内核的时候,主机可执行程序DTC就会被编译出来。 即scripts/dtc/Makefile中 hostprogs-y := dtc always := $(hostprogs-y) 在内核的arch/arm/boot/dts/Makefile中,若选中某种SOC,则与其对应相关的所有dtb文件都将编译出来。在linux下,make dtbs可单独编译dtb。以下截取了S5PV210平台的一部分。
888行是我自己添加的一个设备树文件 2.3. DTB DTC编译*.dts生成的二进制文件(*.dtb),bootloader在引导内核时,会预先读取*.dtb到内存,进而由内核解析。 2.4. Bootloader Bootloader需要将设备树在内存中的地址传给内核。在ARM中通过bootm或bootz命令来进行传递。bootm [kernel_addr] [initrd_address] [dtb_address],其中kernel_addr为内核镜像的地址,initrd为initrd的地址,dtb_address为dtb所在的地址。若initrd_address为空,则用“-”来代替。 三、设备树中dts、dtsi文件的基本语法 DTS的基本语法范例,如图所示。 它包括一系列节点,以及描述节点的属性。 “/”为root节点。在一个.dts文件中,有且仅有一个root节点;在root节点下有“node1”,“node2”子节点,称root为“node1”和“node2”的parent节点,除了root节点外,每个节点有且仅有一个parent;其中子节点node1下还存在子节点“child-nodel1”和“child-node2”。 注:如果看过内核/arch/arm/boot/dts目录的读者看到这可能有一个疑问。在每个.dsti和.dts中都会存在一个“/”根节点,那么如果在一个设备树文件中include一个.dtsi文件,那么岂不是存在多个“/”根节点了么。其实不然,编译器DTC在对.dts进行编译生成dtb时,会对node进行合并操作,最终生成的dtb只有一个root node。Dtc会进行合并操作这一点从属性上也可以得到验证。这个后面分析。 在节点的{}里面是描述该节点的属性(property),即设备的特性。它的值是多样化的: 1.它可以是字符串string,如model = "YIC System SMDKV210 based on S5PV210"; 也可能是字符串数组string-list,如compatible = "yic,smdkv210", "samsung,s5pv210"; 2.它也可以是32 bit unsigned integers,整形用表示, reg = ; 3.它也可以是binary data,十六进制用[]表示,local-mac-address = [00 00 de ad be ef]; 4.它也可能是空,empty_property;
为了了解Device Tree的结构,我们首先给出一个Device Tree的示例: /dts-v1/; #include #include "s5pv210.dtsi" / { model = "YIC System SMDKV210 based on S5PV210"; compatible = "yic,smdkv210", "samsung,s5pv210"; chosen { bootargs = "console=ttySAC2,115200n8 root=/dev/nfs nfsroot=192.168.0.101:/home/run/work/rootfs/rootfs_3.16.57 ip=192.1 68.0.20 init=/linuxrci earlyprintk"; }; memory@30000000 { device_type = "memory"; reg = ; }; ethernet@88000000 { compatible = "davicom,dm9000"; reg = ; interrupt-parent = ; interrupts = ; local-mac-address = [00 00 de ad be ef]; davicom,no-eeprom; clocks = ; clock-names = "sromc"; }; key { empty_property; } };四、Device Tree source file语法介绍 1.dts文件的基本组成单元为: [label:] node-name[@unit-address] { [properties definitions] //就是属性定义,对当前节点描述,将硬件信息提供给内核处理 [child nodes] //子节点 }“[]”表示option,因此可以定义一个只有node name的空节点。如下: key { };label方便在dts文件中引用,具体后面会描述。
@unit-address通常用区分名字相同的外设备,比如有两块内存。 memory@30000000 { device_type = "memory"; reg = ; }; memory@50000000 { device_type = "memory"; reg = ; };这样,在同一级别,就能通过节点名字区别不同设备。(不同级别设备节点是可以相同的,如下节点是可以的) AAAAA { device_type = "AAAAA"; reg = ; AAAAA { device_type = "AAAAA"; reg = ; }; };child node的格式和node是完全一样的,因此,一个dts文件中就是若干嵌套组成的node,property以及child note、child note property描述。 /dts-v1/; #include #include "s5pv210.dtsi" / { model = "YIC System SMDKV210 based on S5PV210"; compatible = "yic,smdkv210", "samsung,s5pv210"; chosen { bootargs = "console=ttySAC2,115200n8 root=/dev/nfs nfsroot=192.168.0.101:/home/run/work/rootfs/rootfs_3.16.57 ip=192.168.0.20 init=/linuxrci earlyprintk"; }; memory@30000000 { device_type = "memory"; reg = ; }; };我们先以上面实例中的一部分为例来分析: device tree顾名思义是一个树状的结构,既然是树,必然有根。 “/”是根节点的node name。 “{”和“}”之间的内容是该节点的具体的定义,其内容包括各种属性的定义以及child node的定义。 chosen和memory都是sub node,sub node的结构和root node是完全一样的,因此,sub node也有自己的属性和它自己的sub node,最终形成了一个树状的device tree。
说到属性中的代表的值,这里引入Arrays of cells的概念:cell表示由尖括号分隔的32位无符号整数 举例 /* example 1 */ interrupt = ; /* example 2,表示一个64位数据 */ clock-frequency = ; /* example 3,A null-terminated string (有结束符的字符串) */ compatible = "simple-bus"; /* example 4,A bytestring(字节序列) */ local-mac-address = [00 00 12 34 56 78]; // 每个byte使用2个16进制数来表示 local-mac-address = [000012345678]; // 每个byte使用2个16进制数来表示chosen node主要用来描述由系统firmware指定的runtime parameter。如果存在chosen这个node,其parent node必须是名字是“/”的根节点。原来通过tag list传递的一些linux kernel的运行时参数可以通过Device Tree传递。例如command line可以通过bootargs这个property这个属性传递;initrd的开始地址也可以通过linux,initrd-start这个property这个属性传递。在本例中,chosen节点包含了bootargsbootargs的属性。 chosen { bootargs = "console=ttySAC2,115200n8 root=/dev/nfs nfsroot=192.168.0.101:/home/run/work/rootfs/rootfs_3.16.57 ip=192.168.0.20 init=/linuxrci earlyprintk"; };通过该command line可以控制内核从net启动,当然,具体项目要相应修改command line以便适应不同的需求。我们知道,device tree用于HW platform识别,runtime parameter传递以及硬件设备描述。chosen节点并没有描述任何硬件设备节点的信息,它只是传递了runtime parameter。 memory device node是所有设备树文件的必备节点,它定义了系统物理内存的layout。device_type属性定义了该node的设备类型,例如cpu、serial等。对于memory node,其device_type必须等于memory。reg属性定义了访问该device node的地址信息。对于device node,reg描述了memory-mapped IO register的offset和length。对于memory node,定义了该memory的起始地址和长度。 当然memory也可以通过command line来传递. chosen { bootargs = "console=ttySAC2,115200n8 root=/dev/nfs nfsroot=192.168.0.101:/home/run/work/rootfs/rootfs_3.16.57 ip=192.168.0.20 init=/linuxrci earlyprintk mem=512M@30000000"; };
在dts文件中,对于properties,有一些常用的、默认的、特殊的属性,定义如下: model 设备制造商的描述,如果有2款板子配置基本一致, 它们的compatible是一样的那么就通过model来分辨这2款板子 compatible 定义一系列的字符串, 用来指定内核中哪个machine_desc可以支持本设备,即这个板子兼容哪些平台 。一般"供应商,产品"。 reg 描述设备资源在其父总线定义的地址空间中的地址。通常这意味着内存映射IO寄存器块的偏移量和长度,但在某些总线类型上可能有不同的含义。根节点定义的地址空间中的地址是CPU实际地址。 #address-cells 在它的子节点的reg属性中, 使用多少个u32整数来描述地址(address) #size-cells 在它的子节点的reg属性中, 使用多少个u32整数来描述地址长度(size) phandle 节点中的phandle属性, 它的取值必须是唯一的(不要跟其他的phandle值一样),使用phandle值来引用节点 bootargs 内核command line参数, 跟u-boot中设置的bootargs作用一样 cpus /cpus节点下面有1个或多个cpu子节点,cpu子节点用reg属性来表明自己是那个cpu。
下面对上面属性的常见用法做举例分析: model: model = "YIC System SMDKV210 based on S5PV210";compatible: 对于根节点,用来指定内核中哪个machine_desc可以支持本设备,即这个板子兼容哪些平台 。通常格式为,",",manufacturer表示供应商,model字符串代表了与该设备兼容的其他设备 compatible = "yic,smdkv210", "samsung,s5pv210";该属性的值是string list,定义了一系列的modle(每个string是一个model)。这些字符串列表被操作系统用来选择用哪一个driver来驱动该设备。假设定义该属性: compatible = "yic,smdkv210", "samsung,s5pv210";那么操作操作系统可能首先使用 "yic,smdkv210"来匹配适合的driver,如果没有匹配到,那么使用字符串"samsung,s5pv210"来继续寻找适合的driver。对于root node,compatible属性是用来匹配machine type的(在device tree代码分析文章中会给出更细致的描述)。 下面给出代码中对应的匹配值。
#address-cells #size-cells reg 注:“cells”是由尖括号分隔的32位无符号整数:cell-property = 下面表示32位系统中,1个512M内存的分布。 / { ...... #address-cells = ; #size-cells = ; memory@30000000 { device_type = "memory"; reg = ; }; };下面表示32位系统中,2个512M内存的分布。 / { ...... #address-cells = ; #size-cells = ; memory@30000000 { device_type = "memory"; reg = ; }; };
如果我们的CPU是64位的,2G的内怎么描述呢? / { ...... #address-cells = ; #size-cells = ; memory@100000000 { device_type = "memory"; reg = ; }; };如果不指定#address-cells和#size-cells 的大小,那么系统会认为只是两块32位内存还是1块64位内存呢?
总结:可编址的设备使用下列属性来将地址信息编码进设备树: reg #address-cells #size-cells 每个可寻址的设备有一个reg属性,即以下面形式表示的元组列表: reg = 每个元组,。每个地址值由一个或多个32位整数列表组成,被称做cells。同样地,长度值可以是cells列表,也可以为空。 既然address和length字段是大小可变的变量,父节点的#address-cells和#size-cells属性用来说明各个子节点有多少个cells。换句话说,正确解释一个子节点的reg属性需要父节点的#address-cells和#size-cells值。 每个地址值是1 cell (32位) ,并且每个的长度值也为1 cell,这在32位系统中是非常典型的。64位计算机可以在设备树中使用2作为#address-cells和#size-cells的值来实现64位寻址。
当然,在特殊情况下,是不需要长度的,即为0。如下,CPU个数是一个整数,没有宽度的。 cpus { #address-cells = ; #size-cells = ; cpu@0 { device_type = "cpu"; compatible = "arm,cortex-a8"; reg = ; }; };bootargs: 内核command line参数, 跟u-boot中设置的bootargs作用一样。
cpus: cpus节点下面有1个或多个cpu子节点,cpu子节点用reg属性来表明自己是那个cpu。所以cpus中有两个属性。 cpus { #address-cells = ; #size-cells = ; cpu@0 { device_type = "cpu"; compatible = "arm,cortex-a8"; reg = ; }; };cpu的格式基本都是固定格式。缺一不可。
多核的通常会设置cpu的频率, cpus { #address-cells = ; #size-cells = ; cpu0: cpu@0 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = ; clock-frequency = ; }; cpu1: cpu@1 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = ; clock-frequency = ; }; cpu2: cpu@2 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = ; clock-frequency = ; }; cpu3: cpu@3 { device_type = "cpu"; compatible = "arm,cortex-a15"; reg = ; clock-frequency = ; }; };
device_type: 搜索了arch/arm/boot/dts下面的所有device_type,发现只有这几种选项。
在dts文件中,引用其他节点: 1)phandle方式引用: pic@10000000 { phandle = ; interrupt-controller; }; another-device-node { interrupt-parent = ; // 使用phandle值为1来引用上述节点 };这种方式要自己确认,在设备树文件中phandle = 这个常量只能取值一次。 2)label 方式引用 节点格式 [label:] node-name[@unit-address] { [properties definitions] //就是属性定义,对当前节点描述,将硬件信息提供给内核处理 [child nodes] //子节点 } PIC: pic@10000000 { interrupt-controller; }; another-device-node { interrupt-parent = ; // 使用label来引用上述节点, // 使用lable时实际上也是使用phandle来引用, // 在编译dts文件为dtb文件时, 编译器dtc会在dtb中插入phandle属性 };这里的label方式其实原理和phandle方式是一样的,只不过lable对于我们使用来说更好辨认。dtc在编译的时候会在使用label的节点中增加一个phandle的属性,增加一个唯一的value,并把使用它的位置替换为该value。
覆盖规则: 同一层次的节点,后面的会覆盖前面的节点。 memory@30000000 { device_type = "memory"; reg = ; }; memory@30000000 { reg = ; };上面这种情况和dtsi里一个dts文件里一个是相同的效果。 编译 make dtbs CROSS_COMPILE=arm-none-linux-gnueabi-反编译 dtc -I dtb -O dts -o tmp.dts s5pv210-x210.dtb查看tmp.dts文件 memory@30000000 { device_type = "memory"; reg = ; };确认已经替换。
直接引用方式覆盖(增加)节点属性: 假设下面节点定义在dtsi文件中 xusbxti: oscillator@1 { compatible = "fixed-clock"; reg = ; clock-frequency = ; clock-output-names = "xusbxti"; #clock-cells = ; };某个dis文件包含了该dtsi文件,并定义了如下内容 &xusbxti { clock-frequency = ; };反编译后的clock-frequency值为0x16e33600也即为替换后的新值24000000
这里要特别注意一点: 直接覆盖方式引用时,新的覆盖要放在根节点外面即,刚才的例子要按照这种方式替换clock-frequency属性。 / { }; &xusbxti { clock-frequency = ; };
|


【本文地址】
今日新闻 |
推荐新闻 |