easyExcel |
您所在的位置:网站首页 › 如何用vba来控制excel合并单元格操作方法是否正确 › easyExcel |
easyExcel
|
目录
前言一、情景介绍二、问题分析三、代码实现四、测试方法五、小结
前言
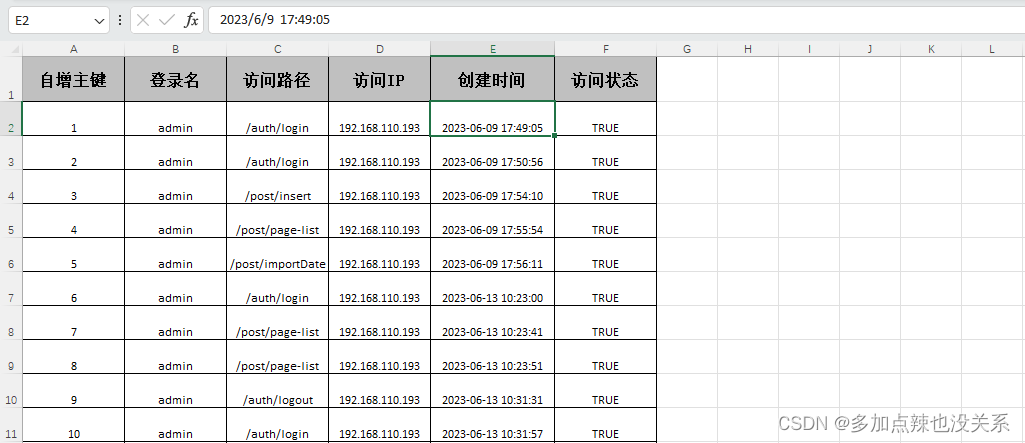
Java-easyExcel入门教程:https://blog.csdn.net/xhmico/article/details/134714025 之前有介绍过如何使用 easyExcel,以及写了两个入门的 demo ,这两个 demo 能应付在开发中大多数的导入和导出需求,不过有时候面对一些复杂的表格,就会有点不够用,该篇就是关于我如何处理表格中的合并单元格的一个开发过程记录 以下内容是结合 Java-easyExcel入门教程 中的案例代码去实现的,可能与你项目中所使用的 easyExcel 会有点不同 一、情景介绍假如说你有一个表格的数据想要导入到系统中,在通常情况下,面对标准的表格文件,比如:
表头和内容都比较工整,每个单元格对应一个数据,通过 Java-easyExcel入门教程 中的内容就能轻易实现导入 但是如果导入的文件中存在一些 合并的单元格,例如:
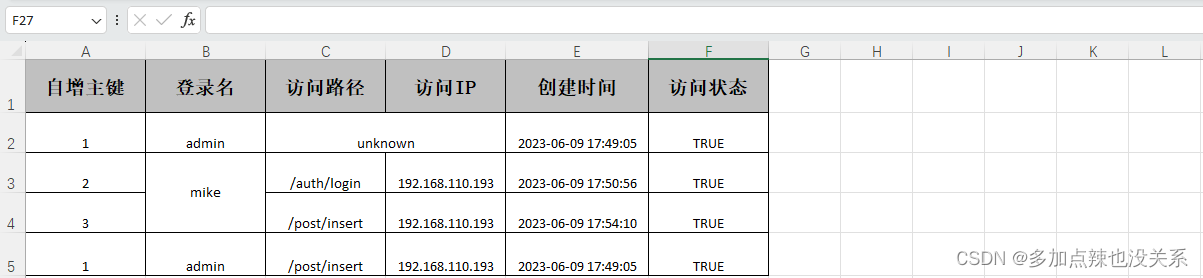
还是按照之前的方式实现导入,那么读出来的数据是:
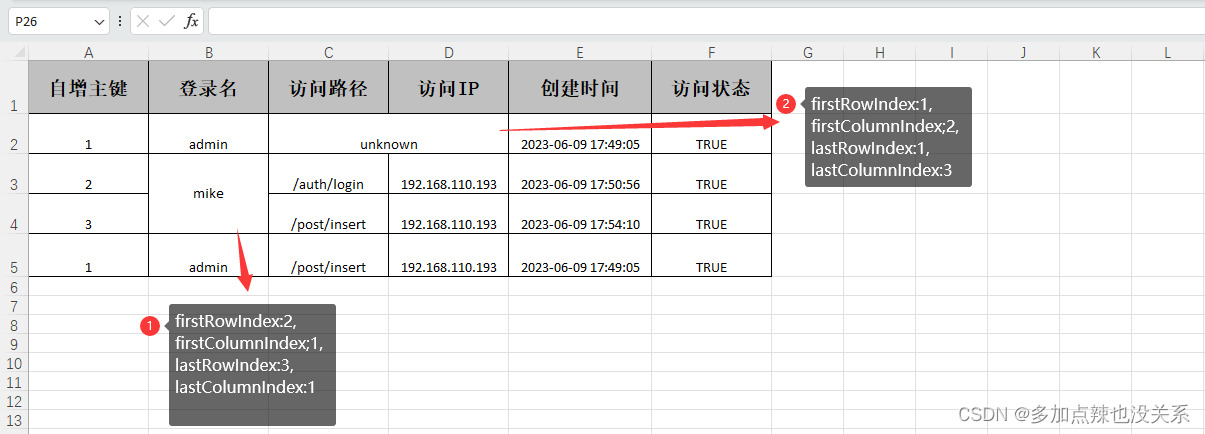
原本期望第一条数据 访问IP 读到的值为 unknown,第三条数据 登录名 读到的值为 mike,当时结果均为 null 二、问题分析首先需要知道 excel 表格合并单元格的原理:在合并单元格时,仅保留左上角的值,而放弃其他值
也就是说合并的单元格取的值都是 左上角的值 在 官方文档 中对于如何读取合并单元格信息是这样的描述的:
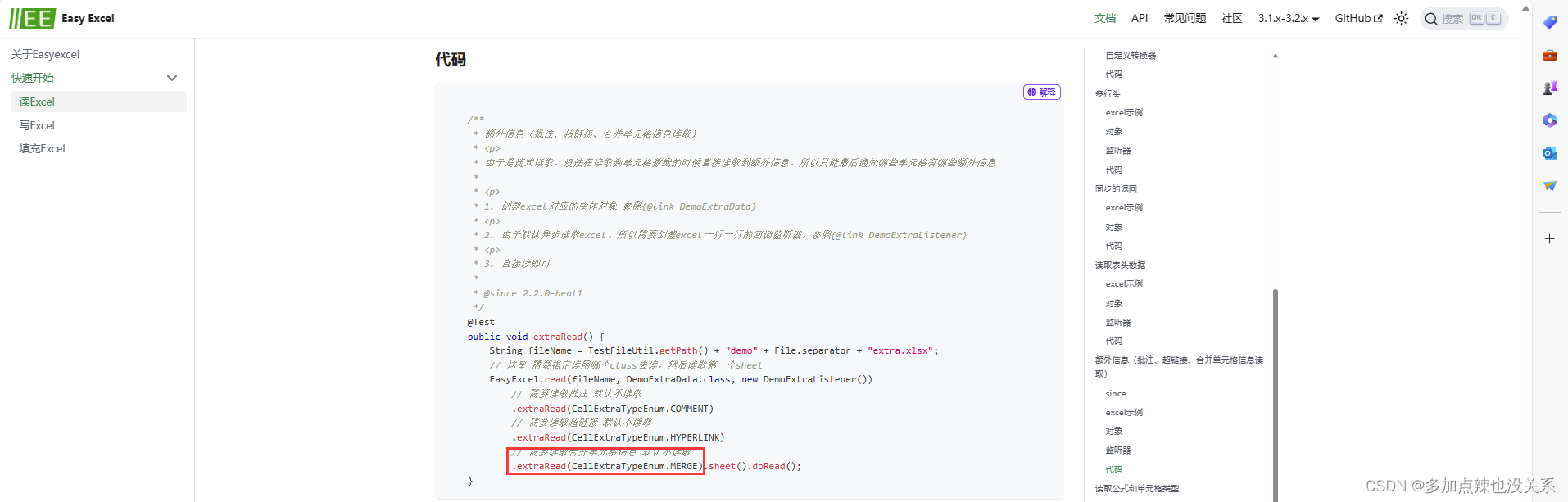
首先是需要在监听器中添加一个 extra 方法 @Override public void extra(CellExtra extra, AnalysisContext context) { log.info("读取到了一条额外信息:{}", JSON.toJSONString(extra)); switch (extra.getType()) { case COMMENT: log.info("额外信息是批注,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(), extra.getText()); break; case HYPERLINK: if ("Sheet1!A1".equals(extra.getText())) { log.info("额外信息是超链接,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(), extra.getText()); } else if ("Sheet2!A1".equals(extra.getText())) { log.info( "额外信息是超链接,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}," + "内容是:{}", extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(), extra.getLastColumnIndex(), extra.getText()); } else { Assert.fail("Unknown hyperlink!"); } break; case MERGE: log.info( "额外信息是超链接,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}", extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(), extra.getLastColumnIndex()); break; default: } }在读取文件的时候添加 .extraRead(CellExtraTypeEnum.MERGE) 就能获取到所有的合并单元格
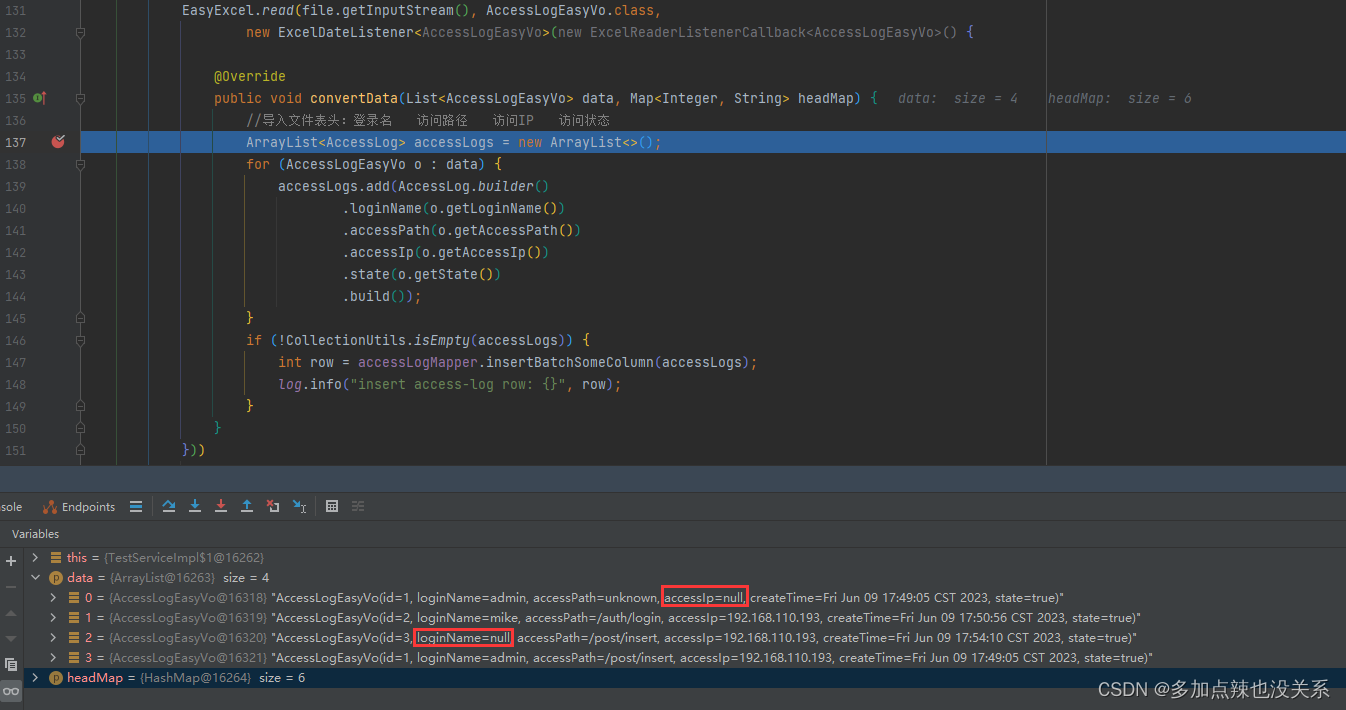
* 由于是流式读取,没法在读取到单元格数据的时候直接读取到额外信息,所以只能最后通知哪些单元格有哪些额外信息 * * * 1. 创建excel对应的实体对象 参照{@link DemoExtraData} * * 2. 由于默认异步读取excel,所以需要创建excel一行一行的回调监听器,参照{@link DemoExtraListener} * * 3. 直接读即可 * * @since 2.2.0-beat1 */ @Test public void extraRead() { String fileName = TestFileUtil.getPath() + "demo" + File.separator + "extra.xlsx"; // 这里 需要指定读用哪个class去读,然后读取第一个sheet EasyExcel.read(fileName, DemoExtraData.class, new DemoExtraListener()) // 需要读取合并单元格信息 默认不读取 .extraRead(CellExtraTypeEnum.MERGE).sheet().doRead(); } 由于是流式读取,没法在读取到单元格数据的时候直接读取到额外信息,所以只能最后通知哪些单元格有哪些额外信息 按照官方文档说的方式可以看到是有读到 合并单元格 的
也就是说只要获取到所有的数据 datas 和所有的合并单元格 mergeDatas,合并单元格中的值可以通过 firstRowIndex 和 firstColumnIndex 去 datas 中获取,firstRowIndex 可以锁定哪个 data ,firstColumnIndex 可以锁定是 data 中的哪个字段 在 easyExcel 中可以通过 @ExcelProperty 中的 index 属性来标明该字段的索引,例如: @ApiModelProperty(value = "自增主键") @ExcelProperty(value = "自增主键", index = 0) @ColumnWidth(15) private Integer id; 三、代码实现关于代码的实现我是参考了 :陈彦斌-easyexcel 读取合并单元格 类比 Java-easyExcel入门教程 中的 导入案例 主要做了以下修改: 在监听器中添加收集 合并单元格 相关的代码ExcelDateListener.java import com.alibaba.excel.context.AnalysisContext; import com.alibaba.excel.event.AnalysisEventListener; import com.alibaba.excel.exception.ExcelDataConvertException; import com.alibaba.excel.metadata.CellExtra; import com.alibaba.fastjson.JSON; import lombok.extern.slf4j.Slf4j; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; @Slf4j public class ExcelDateListener extends AnalysisEventListener { private final ExcelReaderListenerCallback callback; // 每隔50条存储数据库,实际使用中可以3000条,然后清理list,方便内存回收 private static final int BATCH_COUNT = 50; // 表头数据 Map headMap=new HashMap(); // 缓存数据 List cacheList = new ArrayList(); // 合并单元格 private final List extraMergeInfoList = new ArrayList(); public ExcelDateListener(ExcelReaderListenerCallback callback) { this.callback = callback; } /** * 获取合并单元格 */ public List getExtraMergeInfoList() { return this.extraMergeInfoList; } /** * 这里会一行行的返回头 */ @Override public void invokeHeadMap(Map headMap, AnalysisContext context) { this.headMap=headMap; log.info("解析到一条头数据:{}", JSON.toJSONString( headMap)); } @Override public void invoke(M data, AnalysisContext analysisContext) { cacheList.add(data); // 在这里可以做一些其他的操作,就靠自己去拓展了 // 达到BATCH_COUNT了,需要去存储一次数据库,防止数据几万条数据在内存,容易OOM if (cacheList.size() >= BATCH_COUNT) { // 这里是存数据库的操作 callback.convertData(cacheList,headMap); // 存储完成清理 list cacheList.clear(); } } /** * 所有数据解析完成了 都会来调用 */ @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { callback.convertData(cacheList,headMap); cacheList.clear(); } /** * 在转换异常 获取其他异常下会调用本接口。抛出异常则停止读取。如果这里不抛出异常则 继续读取下一行 */ @Override public void onException(Exception exception, AnalysisContext context) { // 如果是某一个单元格的转换异常 能获取到具体行号 // 如果要获取头的信息 配合invokeHeadMap使用 if (exception instanceof ExcelDataConvertException) { ExcelDataConvertException excelDataConvertException = (ExcelDataConvertException)exception; log.error("第{}行,第{}列解析异常", excelDataConvertException.getRowIndex(), excelDataConvertException.getColumnIndex()); } } /** * 读取条额外信息:批注、超链接、合并单元格信息等 */ @Override public void extra(CellExtra extra, AnalysisContext context) { log.info("读取到了一条额外信息:{}", JSON.toJSONString(extra)); switch (extra.getType()) { case COMMENT: log.info("额外信息是批注,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(), extra.getText()); break; case HYPERLINK: if ("Sheet1!A1".equals(extra.getText())) { log.info("额外信息是超链接,在rowIndex:{},columnIndex;{},内容是:{}", extra.getRowIndex(), extra.getColumnIndex(), extra.getText()); } else if ("Sheet2!A1".equals(extra.getText())) { log.info( "额外信息是超链接,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}," + "内容是:{}", extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(), extra.getLastColumnIndex(), extra.getText()); } else { log.error("Unknown hyperlink!"); } break; case MERGE: log.info( "额外信息是合并单元格,而且覆盖了一个区间,在firstRowIndex:{},firstColumnIndex;{},lastRowIndex:{},lastColumnIndex:{}", extra.getFirstRowIndex(), extra.getFirstColumnIndex(), extra.getLastRowIndex(), extra.getLastColumnIndex()); extraMergeInfoList.add(extra); break; default: } } } easyExcel 工具类中添加解析合并单元格的方法 import com.alibaba.excel.annotation.ExcelProperty; import com.alibaba.excel.metadata.CellExtra; import com.mike.common.core.constant.DateFormatConstant; import com.mike.common.core.utils.StringUtils; import lombok.extern.slf4j.Slf4j; import javax.servlet.http.HttpServletResponse; import java.io.UnsupportedEncodingException; import java.lang.reflect.Field; import java.net.URLEncoder; import java.util.List; @Slf4j public class EasyExcelUtil { /** * 初始化响应体 * @param response 请求头 * @param fileName 导出名称 */ public static void initResponse(HttpServletResponse response, String fileName) { String finalFileName = fileName + "_(截止"+ StringUtils.getNowTimeStr(DateFormatConstant.Y0M0D)+")"; // 设置content—type 响应类型 // response.setContentType("application/vnd.ms-excel"); response.setCharacterEncoding("utf-8"); try { // 这里URLEncoder.encode可以防止中文乱码 finalFileName = URLEncoder.encode(finalFileName, "UTF-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } response.setHeader("Content-disposition", "attachment;filename=" + finalFileName + ".xlsx"); } /** * 处理合并单元格 * @param data 解析数据 * @param extraMergeInfoList 合并单元格信息 * @param headRowNumber 起始行 * @return 填充好的解析数据 */ public static List explainMergeData(List data, List extraMergeInfoList, Integer headRowNumber) { // 循环所有合并单元格信息 extraMergeInfoList.forEach(cellExtra -> { int firstRowIndex = cellExtra.getFirstRowIndex() - headRowNumber; int lastRowIndex = cellExtra.getLastRowIndex() - headRowNumber; int firstColumnIndex = cellExtra.getFirstColumnIndex(); int lastColumnIndex = cellExtra.getLastColumnIndex(); // 获取初始值 Object initValue = getInitValueFromList(firstRowIndex, firstColumnIndex, data); // 设置值 for (int i = firstRowIndex; i |



【本文地址】