手把手教会 爬虫爬取json数据 |
您所在的位置:网站首页 › 如何查看json格式文件表示的电路图像信息 › 手把手教会 爬虫爬取json数据 |
手把手教会 爬虫爬取json数据
|
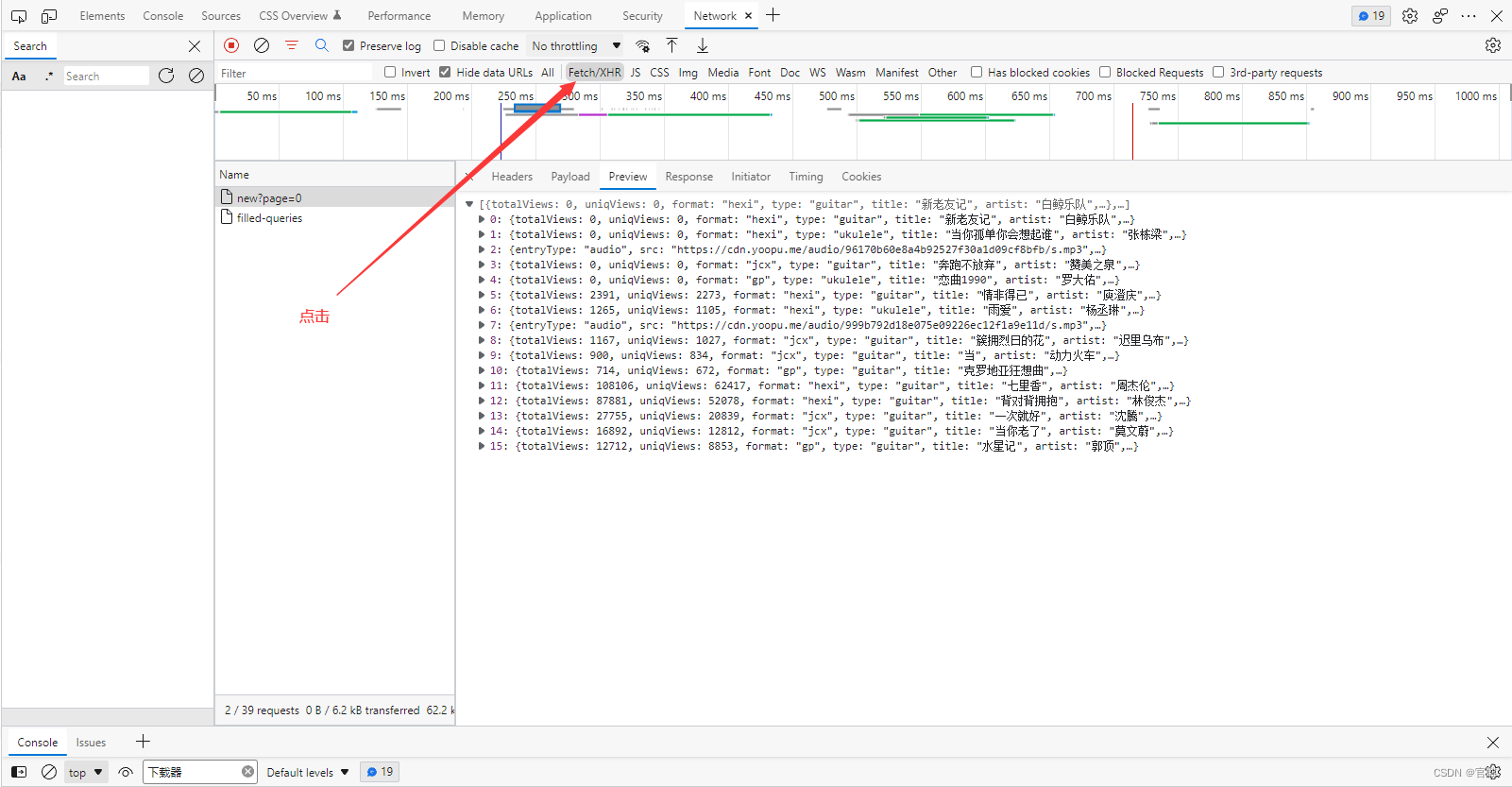
提示:本章爬取练习的url地址 = 发现曲谱 (yoopu.me) 前言我们学爬虫,有时候想要的数据并不在html文本里面,而是通过js动态渲染出来的。 如果我们需要爬取此类数据的话,我们该怎么办呢? 请读者接着往下看: 提示:以下是本篇文章正文内容,下面案例可供参考 一、首先第一步先确定数据是以什么形式加载出来的。这个很简单首先先打开页面源代码,然后ctrl + f 搜索内容的关键字。如果搜索的到那就很简单! 直接请求获取页面源代码 解析数据就可以了。 如果并发现数据并没有在html代码里面,那我们就 f12 打开 开发者工具 点击这里
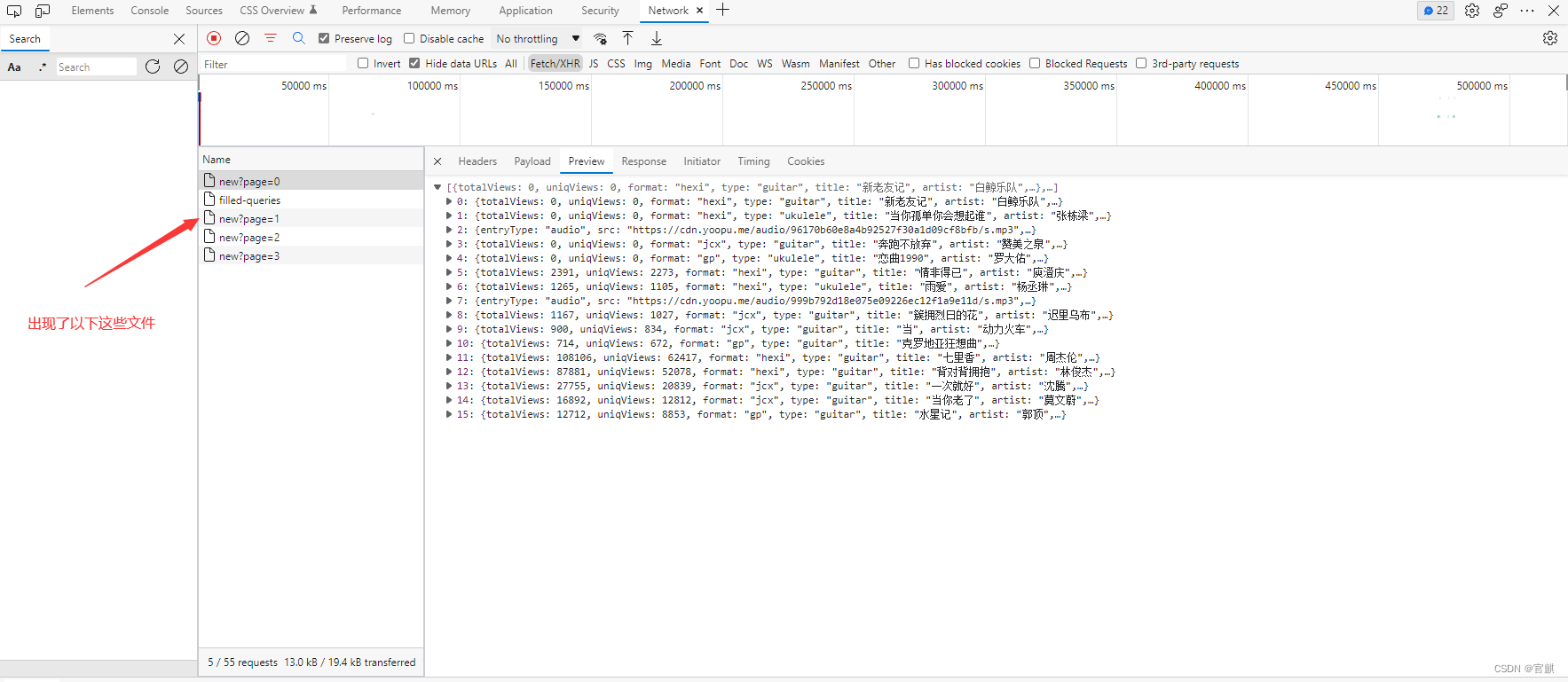
然后 滑动页面让其继续加载数据 就会这样
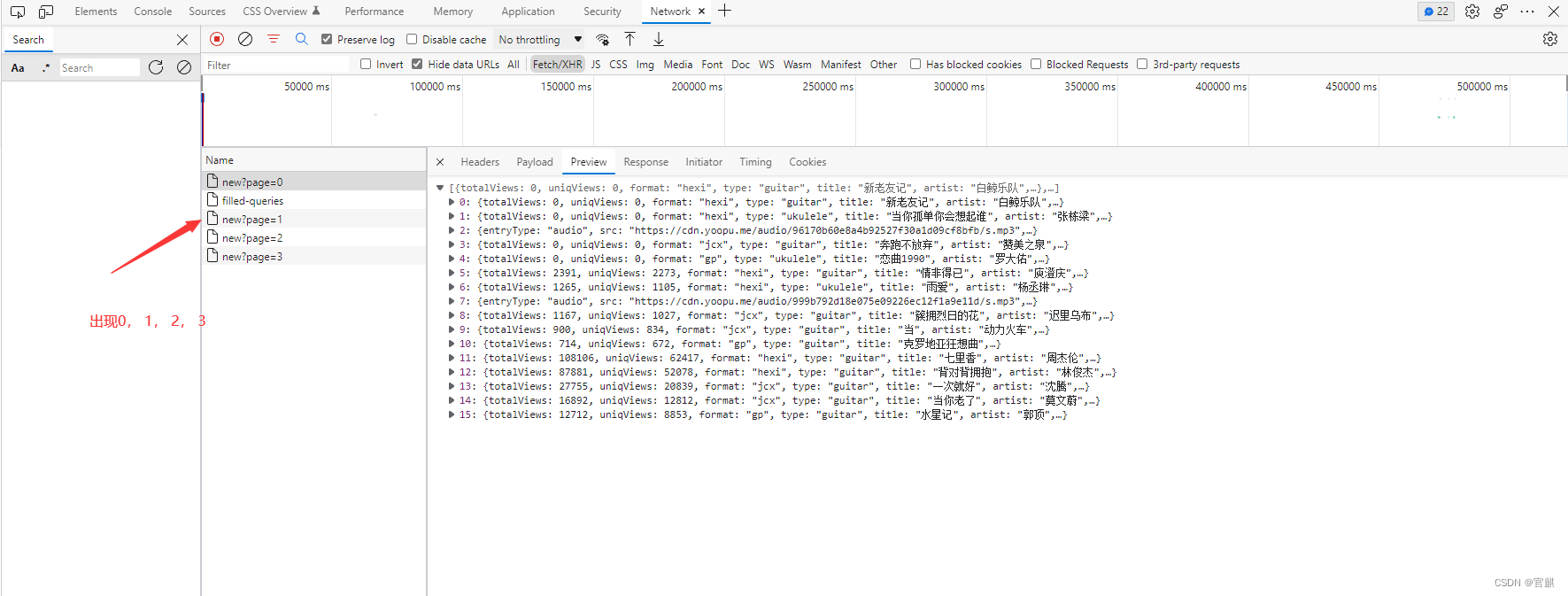
通过每次滑动发现 滑动一次就会接收到这些有规律的数据包
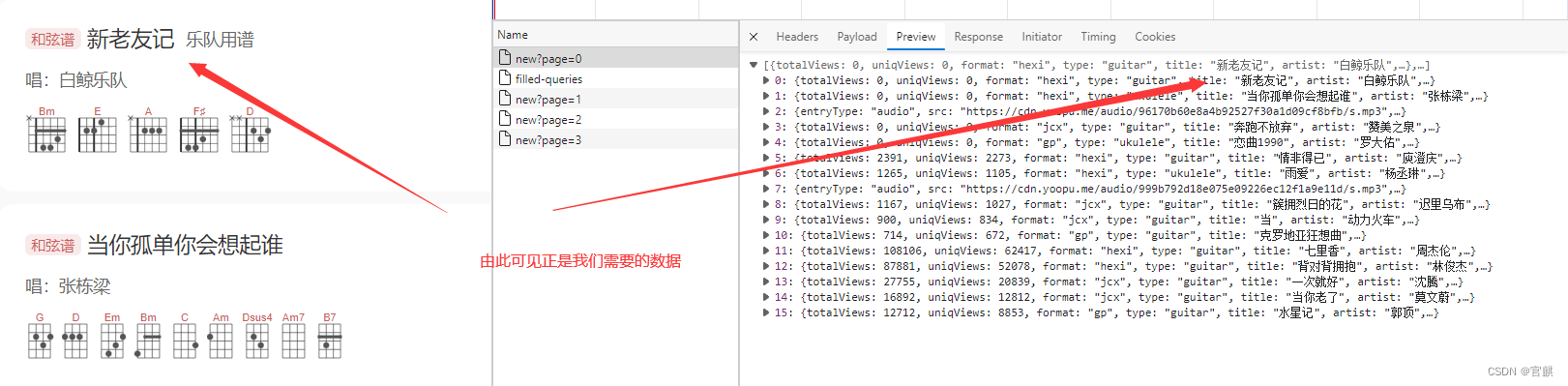
然后我们点击page=0 再点击 prevrew 会发现里面的数据正是页面加载的数据
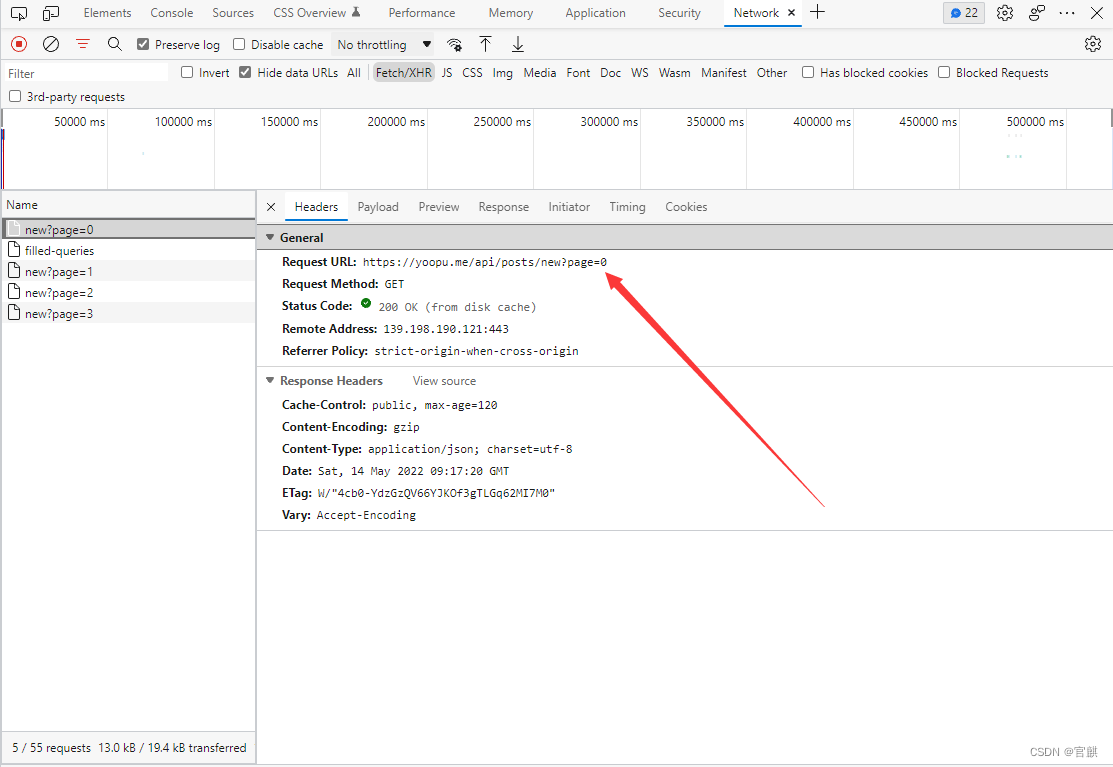
现在再点击 headers 获取需要请求的 url 二、确定需要访问的url之后就开始准备写代码 1.这次请求需要引入的库 代码如下(示例) import json import requests import random import time 2.准备请求需要的数据代码如下(示例): 本节使用较严格的反反爬措施,并使用面向对象编程所以需要的数据有点多。 # 创建一个对象 class Get_url(object): # 定义初始化属性 def __init__(self, num): # 这条是需要我们访问的 url ,实现翻页功能在主程序入口, 到时候传参给num就能实现翻页功能 self.url = f'https://yoopu.me/api/posts/new?page={num}' # 这是伪造头,待会会随机选取其中之一 self.USER_AGENTS = [ "Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11", "Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", "Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50", "Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0", "Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT)", "Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3", "Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12 " ] # 这是ip代理池,待会会随机选取其中之一 self.IP_AGENTS = [{'HTTP': '60.170.204.30:8060'}, {'HTTP': '111.3.118.247:30001'}, {'HTTP': '220.168.52.245:53548'}, {'HTTP': '202.116.32.236:80'}, {'HTTP': '14.215.212.37:9168'}, {'HTTP': '39.106.71.115:7890'}, {'HTTP': '220.168.52.245:53548'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '118.163.120.181:58837'}, {'HTTP': '121.13.252.62:41564'}, {'HTTP': '106.54.128.253:999'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '210.5.10.87:53281'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '112.6.117.135:8085'}, {'HTTP': '61.150.96.27:36880'}, {'HTTP': '106.15.197.250:8001'}, {'HTTP': '202.109.157.65:9000'}, {'HTTP': '112.74.17.146:8118'}, {'HTTP': '183.236.123.242:8060'}, {'HTTP': '220.168.52.245:53548'}, {'HTTP': '103.37.141.69:80'}, {'HTTP': '218.75.69.50:57903'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '113.88.208.112:8118'}, {'HTTP': '122.9.101.6:8888'}, {'HTTP': '47.113.90.161:83'}, {'HTTP': '106.15.197.250:8001'}, {'HTTP': '61.216.156.222:60808'}, ] # 构建headers请求头 把ua伪造头通过random随机选取一个传进去 self.headers = {'Accept': 'image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', 'Cookie': 'BDUSS_BFESS=VhlWExJYUxHLUd-VDQ3VHl4WktUb2dYSXZmWEdId3ViSG41Z2tHT3FhcnBpVlppRVFBQUFBJCQAAAAAAAAAAAEAAACFlYZcyqfIpb7N1tjNt9TZwLQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOn8LmLp~C5iY; BAIDUID_BFESS=42114CA345FFDDD003FDB91BC19F4B5D:FG=1; HMACCOUNT_BFESS=76DA5CF409547AE8', 'Host': 'hm.baidu.com', 'Referer': 'https://yoopu.me/', 'Sec-Fetch-Dest': 'image', 'Sec-Fetch-Mode': 'no-cors', 'Sec-Fetch-Site': 'cross-site', 'User-Agent': random.choice(self.USER_AGENTS), 'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="101", "Microsoft Edge";v="101"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"'} # 构建ip, 也通过随机模块传入 self.proxies = random.choice(self.IP_AGENTS) 3.访问url并返回 json数据 # 获取网页的json数据方法 def get_url(self): # 让程序延迟 0.5 到 1.5秒之间的时间随机访问 time.sleep(random.uniform(0.5, 1.5)) # 用get请求发送, 传入url,请求头, ip代理 然后用json数据保存 response = requests.get(self.url, headers=self.headers, proxies=self.proxies).json() # 退出函数返回 response return response 4.处理json数据并解析数据 # 提取json 关键数据方法 def url_date(self): # 用res变量接收 get_url返回的数据 res = self.get_url() # 然后解析 我们请求下来的数据,发现我们获取的数据是一个列表, # 然后里面数据是字典形式存在 , 这样的话我们就可以通过遍历列表然后通过 key查找获取到值了 for i in res: # 因为发现有一些数据 里面不包含我们所需要的信息, 然后找不到就会异常 # 所以我们就用异常处理, 如果异常就执行 except的代码 try: singer = i['artist'] print(singer) except Exception as a: print('抱歉,没有获取到乐队信息!') try: singer = i['title'] print(singer) except Exception as a: print('抱歉没有获取到歌名!') try: singer = 'https://yoopu.me/view/' + i['id'] print(singer) except Exception as a: print('抱歉没有获取到歌名网址!') try: singer = i['key'] print(singer + '调') except Exception as a: print('抱歉没有获取到歌曲音调!') print('\n') 5.创建方法运行上面的代码 # 创建一个方法来运行上面的代码 def run(self): self.url_date() 6.创建主程序入口并实现翻页功能 # 创建主程序入口 if __name__ == '__main__': # 实现翻页功能 循环0-50 然后传参进Get_url对象然后实现翻页功能 for i in range(0, 50): run_1 = Get_url(i) run_1.run() # 实现爬取第几页 print(f'已经爬取第{i + 1}页') print('爬取完毕!') 总结上面已经实现了 数据爬取, 数据保存就不实现了,给读者操作一下。 以下是全部代码: 代码基本全部注释 import json import requests import random import time # 创建一个对象 class Get_url(object): # 定义初始化属性 def __init__(self, num): # 这条是需要我们访问的 url ,实现翻页功能在主程序入口, 到时候传参给num就能实现翻页功能 self.url = f'https://yoopu.me/api/posts/new?page={num}' # 这是伪造头,待会会随机选取其中之一 self.USER_AGENTS = [ "Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11", "Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", "Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50", "Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0", "Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT)", "Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3", "Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12 " ] # 这是ip代理池,待会会随机选取其中之一 self.IP_AGENTS = [{'HTTP': '60.170.204.30:8060'}, {'HTTP': '111.3.118.247:30001'}, {'HTTP': '220.168.52.245:53548'}, {'HTTP': '202.116.32.236:80'}, {'HTTP': '14.215.212.37:9168'}, {'HTTP': '39.106.71.115:7890'}, {'HTTP': '220.168.52.245:53548'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '118.163.120.181:58837'}, {'HTTP': '121.13.252.62:41564'}, {'HTTP': '106.54.128.253:999'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '210.5.10.87:53281'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '112.6.117.135:8085'}, {'HTTP': '61.150.96.27:36880'}, {'HTTP': '106.15.197.250:8001'}, {'HTTP': '202.109.157.65:9000'}, {'HTTP': '112.74.17.146:8118'}, {'HTTP': '183.236.123.242:8060'}, {'HTTP': '220.168.52.245:53548'}, {'HTTP': '103.37.141.69:80'}, {'HTTP': '218.75.69.50:57903'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '202.55.5.209:8090'}, {'HTTP': '113.88.208.112:8118'}, {'HTTP': '122.9.101.6:8888'}, {'HTTP': '47.113.90.161:83'}, {'HTTP': '106.15.197.250:8001'}, {'HTTP': '61.216.156.222:60808'}, ] # 构建headers请求头 把ua伪造头通过random随机选取一个传进去 self.headers = {'Accept': 'image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection': 'keep-alive', 'Cookie': 'BDUSS_BFESS=VhlWExJYUxHLUd-VDQ3VHl4WktUb2dYSXZmWEdId3ViSG41Z2tHT3FhcnBpVlppRVFBQUFBJCQAAAAAAAAAAAEAAACFlYZcyqfIpb7N1tjNt9TZwLQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAOn8LmLp~C5iY; BAIDUID_BFESS=42114CA345FFDDD003FDB91BC19F4B5D:FG=1; HMACCOUNT_BFESS=76DA5CF409547AE8', 'Host': 'hm.baidu.com', 'Referer': 'https://yoopu.me/', 'Sec-Fetch-Dest': 'image', 'Sec-Fetch-Mode': 'no-cors', 'Sec-Fetch-Site': 'cross-site', 'User-Agent': random.choice(self.USER_AGENTS), 'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="101", "Microsoft Edge";v="101"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"'} # 构建ip, 也通过随机模块传入 self.proxies = random.choice(self.IP_AGENTS) # 获取网页的json数据方法 def get_url(self): # 让程序延迟 0.5 到 1.5秒之间的时间随机访问 time.sleep(random.uniform(0.5, 1.5)) # 用get请求发送, 传入url,请求头, ip代理 然后用json数据保存 response = requests.get(self.url, headers=self.headers, proxies=self.proxies).json() # 退出函数返回 response return response # 提取json 关键数据方法 def url_date(self): # 用res变量接收 get_url返回的数据 res = self.get_url() # 然后解析 我们请求下来的数据,发现我们获取的数据是一个列表, # 然后里面数据是字典形式存在 , 这样的话我们就可以通过遍历列表然后通过 key查找获取到值了 for i in res: # 因为发现有一些数据 里面不包含我们所需要的信息, 然后找不到就会异常 # 所以我们就用异常处理, 如果异常就执行 except的代码 try: singer = i['artist'] print(singer) except Exception as a: print('抱歉,没有获取到乐队信息!') try: singer = i['title'] print(singer) except Exception as a: print('抱歉没有获取到歌名!') try: singer = 'https://yoopu.me/view/' + i['id'] print(singer) except Exception as a: print('抱歉没有获取到歌名网址!') try: singer = i['key'] print(singer + '调') except Exception as a: print('抱歉没有获取到歌曲音调!') print('\n') # 创建一个方法来运行上面的代码 def run(self): self.url_date() # 创建主程序入口 if __name__ == '__main__': # 实现翻页功能 循环0-50 然后传参进Get_url对象然后实现翻页功能 for i in range(0, 50): run_1 = Get_url(i) run_1.run() # 实现爬取第几页 print(f'已经爬取第{i + 1}页') print('爬取完毕!') |
【本文地址】
今日新闻 |
推荐新闻 |