python统计英文文本词频和提取文本关键词 |
您所在的位置:网站首页 › 如何提取文章中的重要信息和内容呢英语 › python统计英文文本词频和提取文本关键词 |
python统计英文文本词频和提取文本关键词
|
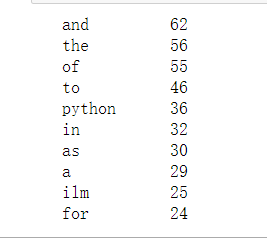
统计一段英文的词频,以下代码只将标点符号省去,没有去除英文中介词,数词,人称代词等,如需要改进在统计时候直接去除相应词汇即可。 #读取文本 txt = open("english.txt","r",errors='ignore').read() #字母变小写 txt = txt.lower() for ch in '!"#$&()*+,-./:;?@[\\]^_{|}·~‘’': #替换标点 txt = txt.replace(ch,"") #根据空格,空字符,换行符,制表符进行分词 words = txt.split() #记录词频 counts = {} for word in words: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(10): word,count = items[i] #分别左对齐占据10个单位,空格补全,右对齐五个单位,空格补全 print("{0:5}".format(word,count))
为了更好地体现文本的核心含义,下面我们采用jieba包的自然语言分析功能进行关键词的提取。 # 正则包 import re # 自然语言处理包 import string import jieba import jieba.analyse # html 包 import html from numpy import * from zhon import * with open('./english.txt', "rb") as x: content = x.read() # 正则过滤 content = re.sub("[{}]+".format(string.punctuation), " ", content.decode("utf-8")) # html 转义符实体化 content = html.unescape(content) # 切割 seg = [i for i in jieba.cut(content, cut_all=True) if i != ''] # 提取关键词 keywords = jieba.analyse.extract_tags("|".join(seg), topK=10, withWeight=True) # 分词与关键词提取 keywords0 = keywords with open('./keywords0.txt', 'w') as k0: k0.write(str(keywords0)) k0.close() print('完成文章关键字提取!')结果如下,后者为所占权重 [('Python', 0.4361421259243218), ('ILM', 0.36904333732058), ('production', 0.19011323437726846), ('was', 0.1789301029433115), ('its', 0.11183131433956968), ('used', 0.11183131433956968), ('into', 0.10064818290561271), ('process', 0.10064818290561271), ('systems', 0.08946505147165575), ('time', 0.08946505147165575)] |
【本文地址】
今日新闻 |
推荐新闻 |