使用java 来爬取网页内容 |
您所在的位置:网站首页 › 如何介绍一个网页内容的特点 › 使用java 来爬取网页内容 |
使用java 来爬取网页内容
|
使用java 来爬取网页内容
前言明确爬取对象实现需求小说名称章节内容
源代码结语
前言
在日常中,我们经常需要浏览网页,阅读一些内容。 但网页中并不是所有内容都是我们所需要的。 毕竟,谁都不想看的好好时突然出现一个“澳门棋牌”。 那么这时我们就可以爬取它的内容。 明确爬取对象这里就以大家熟知的 笔*阁为例。 打开笔*阁的首页。 不对,打开一本小说。 这里以《进化的四十六亿重奏》为例(我是挺推荐这本书的,还有,如果可以的话尽量支持正版。)
那我们需要什么呢? 那我们就需要明确我们爬取的对象。 1 小说的名称。 2 章节名称。 3 章节内容。 ok,明确了对象后,那我们就需要针对这些对象进行爬取。 实现需求 小说名称首先是小说的名称。 通过观察源代码,我们可以看到: 小说的名称和简介是储存在: 小说的目录 和 章节内容是储存在: 我们可以将网页的内容全部存入一个字符串数组中。 然后进行比较,确定位置。 然后将我们需要的内容提取出来。 在放入新的文件中。 话不多说,上实例: 源代码 public static void main(String[] args){ //确定主页链接 String link = "https://www.biquwx.la/0_376/"; //确定文件存放位置 String path = "/Users/apple/Downloads/test/"; //默认运行一次,当连接不上链接时(也就是出现SSLException异常时),runTime会+1,也就是仔运行一次 int runTimes = 1; for (int runtime=0;runtime |
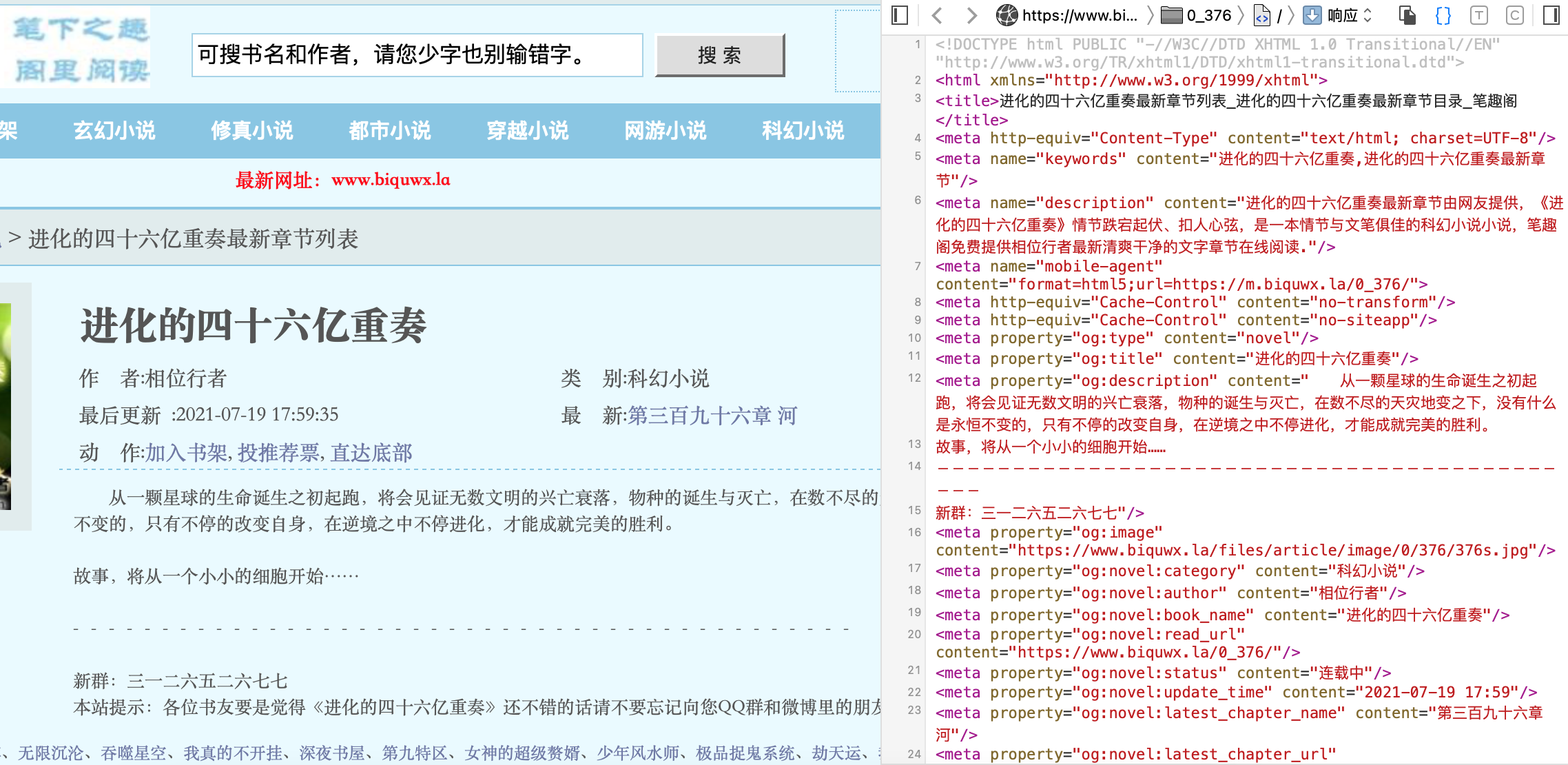 打开主页,查看源代码,我们可以从其中换取我们需要的一起。
打开主页,查看源代码,我们可以从其中换取我们需要的一起。
 11,12行的标签中的。
11,12行的标签中的。
【本文地址】
今日新闻 |
推荐新闻 |