k均值聚类 |
您所在的位置:网站首页 › 大班横纵坐标 › k均值聚类 |
k均值聚类
|
机器学习之k均值聚类
什么是聚类K均值聚类过程怎么样设置 合理的K 值计算距离的几种方式欧式距离:曼哈顿距离:切比雪夫距离余弦距离(Cosine Distance)
python 实现参考文献
什么是聚类
所谓聚类算法是指将一堆没有标签的数据自动划分成几类的方法,属于无监督学习方法 。 监督学习 有特征 有标签 。 无监督学习 只要特征没有标签 。 查看两者的区别在这里。 如下图: 将所有的数据 展示如下, 只有变量 x 没有 y . 但是我们用肉眼可以很明显的分 成 三类。那么机器怎么样区分呢? 聪明的同学就知道了 ,通过算距离。 算法流程: 1、首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。 2、从数据集中随机选择k个数据点作为质心。 3、对数据集中每一个点,计算其与每一个质心的距离(如欧式距离),离哪个质心近,就划分到那个质心所属的集合。 4、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。 5、如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止。 6、如果新质心和原质心距离变化很大,需要迭代3~5步骤。 比如: 我们先 随机 找 A ,B两个点 作为质心。
重新计算 质心, 将质心 更换成红色的字体 的。
重新计算每个点 到 A,B 质心的分类,得到如下分类:
1、按需选择 简单地说就是按照建模的需求和目的来选择聚类的个数。比如说,一个游戏公司想把所有玩家做聚类分析,分成顶级、高级、中级、菜鸟四类,那么K=4;如果房地产公司想把当地的商品房分成高中低三档,那么K=3。按需选择虽然合理,但是未必能保证在做K-Means时能够得到清晰的分界线。 2、观察法 就是用肉眼看,看这些点大概聚成几堆。这个方法虽然简单,但是同时也模棱两可。
左上角是原始点。右上角分成了两类。左下角是三类,左下角是四类。至于K到底是选3还是选4,可能每个人都有不同的选择。 观察法的另一个缺陷就是:原始数据维数要低,一般是两维(平面散点)或者三维(立体散点),否则人类肉眼则无法观察。对于高维数据,我们通常利用PCA降维,然后再进行肉眼观察。 3、手肘法 将所有的的点 按照K 个分类 计算距离总和 。 总和越大 分类越不合理。 手肘法本质上也是一种间接的观察法。我们将得到K个聚类的中心点Mi, i=1,2,⋯,K。以及每个原始点所对应的聚类Ci,i=1,2,⋯,K。我们通常采用所有样本点到它所在的聚类的中心点的距离的和作为模型的度量,记为DK。
这里距离可以采用欧式距离。 对于不同的K,最后我们会得到不同的中心点和聚类,所有会有不同的度量。 我们把上面的例子用不同的K去计算,会得到不同的结果。把K作为横坐标,DK作为纵坐标,我们可以得到下面的折线。 K 为 分类的个数 DK 为 每一分类 到质心的距离之和 再相加。
很显然K越大,距离和越小。但是我们注意到K=3是一个拐点,就像是我们的肘部一样,K=1到3下降很快,K=3之后趋于平稳。手肘法认为这个拐点就是最佳的K。 手肘法是一个经验方法,而且肉眼观察也因人而异,特别是遇到模棱两可的时候。相比于直接观察法,手肘法的一个优点是,适用于高维的样本数据。有时候人们也会把手肘法用于不同的度量上,如组内方差组间方差比。 4、Gap Statistic方法 这里我们要继续使用上面的DK。Gap Statistic的定义为:
这里E(logDk)指的是logDk的期望。这个数值通常通过蒙特卡洛模拟产生,我们在样本里所在的矩形区域中(高维的话就是立方体区域)按照均匀分布随机地产生和原始样本数一样多的随机样本,并对这个随机样本做聚类,从而得到一个DK。如此往复多次,通常20次,我们可以得到20个logDK。对这20个数值求平均值,就得到了E(logDK)的近似值。最终可以计算Gap Statisitc。而Gap statistic取得最大值所对应的K就是最佳的K。 用上图的例子,我们计算了K=1,2,…9对应的Gap Statisitc.
蒙特卡洛 这个我后面会讲 。 计算距离的几种方式 欧式距离:
二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离:
n维空间点a(x11,x12,…,x1n)与b(x21,x22,…,x2n)的曼哈顿距离:
二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离:
二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦为: 将以下数据存入 myData.txt 以下代码放入 KMeans.py 中。 0.697 0.46 0.774 0.376 0.634 0.264 0.608 0.318 0.556 0.215 0.403 0.237 0.481 0.149 0.437 0.211 0.666 0.091 0.243 0.267 0.245 0.057 0.343 0.099 0.639 0.161 0.657 0.198 0.36 0.37 0.593 0.042 0.719 0.103 0.359 0.188 0.339 0.241 0.282 0.257 0.748 0.232 0.714 0.346 0.483 0.312 0.478 0.437 0.525 0.369 0.751 0.489 0.532 0.472 0.473 0.376 0.725 0.445 0.446 0.459 import matplotlib.pyplot as plt from numpy import * import random def loadDataSet(filename): fr = open(filename) numberOfLines = len(fr.readlines()) returnMat = zeros((numberOfLines, 2)) classLabelVector = ['密度','含糖率'] fr = open(filename) index = 0 for line in fr.readlines(): print(line) #line = line.split(' ') line = line.split(' ') #line = line.strip().split('\t').split(' ') print(line[0:2]) returnMat[index, :] = [float(line[0]), float(line[len(line)-1])] index += 1 return returnMat, classLabelVector # 欧几里得距离 def edistance(v1, v2): result=0.0 for i in range(len(v1)): result +=(v1[i]-v2[i])**2 return sqrt(result) # 特征值归一化 def autoNorm(dataSet): minVals = dataSet.min(0) # 获取特征值最小值 maxVals = dataSet.max(0) # 获取特征值最大值 ranges = maxVals - minVals m = dataSet.shape[0] normDataSet = dataSet - tile(minVals, (m,1)) normDataSet = normDataSet/tile(ranges, (m,1)) #归一化 return normDataSet, ranges, minVals def kcluster(rows, distance=edistance, k=3): normDataSet, ranges, minVals = autoNorm(rows) # 归一化数据到0-1之间 count = normDataSet.shape[0] # 数据总数 randinfo = random.sample(range(0, count), k) clusters = [normDataSet[randinfo[i]] for i in range(len(randinfo))] # 随机选取k个值作为聚类中心 lastmatches = None for t in range(100): bestmatches = [[] for i in range(k)] # 寻找最近中心 for j in range(count): row = normDataSet[j] bestmatch = 0 for i in range(k): d = distance(row,clusters[i]) if d 0: for rowid in bestmatches[i]: for m in range(len(normDataSet[rowid])): avgs[m] += normDataSet[rowid][m] for j in range(len(avgs)): avgs[j] /= len(bestmatches[i]) clusters[i] = avgs return bestmatches def plot(dataMat, labelMat,bestmatches): xcord = [];ycord = [] sumx1=0.0;sumy1=0.0;sumx2=0.0;sumy2=0.0;sumx3=0.0;sumy3=0.0 midx = [];midy=[] for i in range(len(dataMat)): xcord.append(float(dataMat[i][0]));ycord.append(float(dataMat[i][1])) for i in range(len(bestmatches)): for j in bestmatches[i]: if(i==0): plt.scatter(xcord[j], ycord[j], color='red') sumx1+=xcord[j] sumy1+=ycord[j] if(i == 1): plt.scatter(xcord[j], ycord[j], color='green') sumx2 += xcord[j] sumy2 += ycord[j] if (i == 2): plt.scatter(xcord[j], ycord[j], color='black') sumx3 += xcord[j] sumy3 += ycord[j] midx.append(sumx1/len(bestmatches[0])) midx.append(sumx2 / len(bestmatches[1])) midx.append(sumx3 / len(bestmatches[2])) midy.append(sumy1 / len(bestmatches[0])) midy.append(sumy2 / len(bestmatches[1])) midy.append(sumy3 / len(bestmatches[2])) plt.scatter(midx,midy, marker = '+',color='blue') plt.xlabel(labelMat[0]);plt.ylabel(labelMat[1]) plt.xlim((0, 1)) plt.ylim((0, 1)) plt.show() if __name__=='__main__': dataMat, labelMat = loadDataSet('myData.txt') bestmatches = kcluster(dataMat) plot(dataMat, labelMat,bestmatches) 参考文献https://blog.csdn.net/lyn5284767/article/details/81332178 https://www.jianshu.com/p/4f032dccdcef |

 对所有点分类:
对所有点分类: 


 如图 我们 可以发现 质心已经不会在发生变化 所以就不变了 。 结束算法。
如图 我们 可以发现 质心已经不会在发生变化 所以就不变了 。 结束算法。
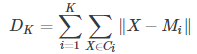

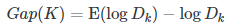

 勾股定理求出距离。
勾股定理求出距离。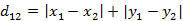
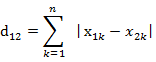
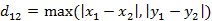 n维空间点a(x11,x12,…,x1n)与b(x21,x22,…,x2n)的切比雪夫距离:
n维空间点a(x11,x12,…,x1n)与b(x21,x22,…,x2n)的切比雪夫距离: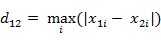
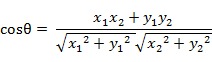
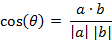 即:
即: 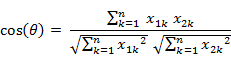
【本文地址】
今日新闻 |
推荐新闻 |