大数据项目实战 |
您所在的位置:网站首页 › 大数据相关职位招聘 › 大数据项目实战 |
大数据项目实战
|
目录 第一章:项目概述 1.1项目需求和目标 1.2预备知识 1.3项目架构设计及技术选取 1.4开发环境和开发工具 1.5项目开发流程 第二章:搭建大数据集群环境 2.1安装准备 2.2Hadoop集群搭建 2.3Hive安装 2.4Sqoop安装 第三章:数据采集 3.1知识概要 3.2分析与准备 3.3采集网页数据 第四章:数据预处理 4.1分析预处理数据 4.2设计数据预处理方案 4.3实现数据的预处理 第五章:数据分析 5.1数据分析概述 5.2Hive数据仓库 5.3分析数据 第六章:数据可视化 6.1平台概述 6.2数据迁移 6.3平台环境搭建 6.4实现图形化展示功能 第一章:项目概述 1.1项目需求项目需求: 本项目是以国内某互联网招聘网站全国范围内的大数据相关招聘信息作为基础信息,其招聘信息能较大程度地反映出市场对大数据相关职位的需求情况及能力要求,利用这些招聘信息数据通过大数据分析平台重点分析一下几点: 分析大数据职位的区域分布情况分析大数据职位薪资区间分布情况分析大数据职位相关公司的福利情况分析大数据职位相关公司技能要求情况 1.2预备知识知识储备: JAVA面向对象编程思想Hadoop、Hive、Sqoop在Linux环境下的基本操作HDFS与MapReduce的Java API程序开发大数据相关技术,如Hadoop、HIve、Sqoop的基本理论及原理Linux操作系统Shell命令的使用关系型数据库MySQL的原理,SQL语句的编写网站前端开发相关技术,如HTML、JSP、JQuery、CSS等网站后端开发框架Spring+SpringMVC+MyBatis整合使用Eclipse开发工具的应用Maven项目管理工具的使用 1.3项目架构设计及技术选取
系统环境主要分为开发环境(Windows)和集群环境(Linux) 开发工具:Eclipse、JDK、Maven、VMware Workstation 集群环境:Hadoop、Hive、Sqoop、MySQL web环境:Tomcat、Spring、Spring MVC、MyBatis、Echarts 1.5项目开发流程1.搭建大数据实验环境 (1)Linux 系统虛拟机的安装与克隆 (2)配置虛拟机网络与 SSH 服务 (3)搭建 Hadoop 集群 (4)安装 MySQL 数据库 (5)安装 Hive (6)安装 Sqoop 2.编写网络爬虫程序进行数据采集 (1)准备爬虫环境 (2)编写爬虫程序 (3)将爬取数据存储到 HDFS 3.数据预处理 (1)分析预处理数据 (2)准备预处理环境 (3)实现 MapReduce 预处理程序进行数据集成和数据转换操作 (4)实现 MapReduce 预处理程序的两种运行模式 4.数据分析 (1)构建数据仓库 (2)通过 HSQL 进行职位区域分析 (3)通过 HSQL 进行职位薪资分析 (4)通过 HSQL 进行公司福利标签分析 (5)通过 HSQL 进行技能标签分析 5.数据可视化 (1)构建关系型数据库 (2)通过 Sqoop 实现数据迁移 (3)创建 Maven 项目配置项目依赖的信息 (4)编辑配置文件整合 SSM 框架 (5)完善项目组织框架 (6)编写程序实现职位区域分布展示 (7)编写程序实现薪资分布展示 (8)编写程序实现福利标签词云图 (9)预览平台展示内容 (10)编写程序实现技能标签词云图 第二章:搭建大数据集群环境 2.1安装准备虚拟机安装与克隆(克隆方法选择创建完整克隆) 虚拟机网络配置 #编辑网络 vi /etc/sysconfig/network-scripts/ifcfg-ens33 #重启 service network restart #配置ip和主机名映射 vi /etc/hosts
SSH服务配置 #查看SSH服务 rpm -qa | grep ssh #SSH安装命令 yum -y install openssh openssh-server #查看SSH进程 ps -ef | grep ssh #生成密钥对 ssh-keygen -t rsa #复制公钥文件 ssh-copy-id 主机名 2.2Hadoop集群搭建
步骤: 下载安装配置环境变量(编辑环境变量文件——配置系统环境变量——初始化环境变量)环境验证 JDK安装 1.安装rz,通过rz命令上传安装包 yum install lrzsz 2.解压 tar -zxvf jdk-8u181-linux-x64.tar.gz -C /usr/local 3.修改名字 mv jdk1.8.0_181/ jdk 4.配置环境变量 vi /etc/profile #JAVA_HOME export JAVA_HOME=/usr/local/jdk export PATH=$PATH:$JAVA_HOME/bin 5.初始化环境变量 source /etc/profile 6.验证配置 java -version Hadoop安装 1.通过rz命令上传安装包 2.解压 tar -zxvf hadoop2.7.1.tar.gz -C /usr/local 3.修改名字 mv hadoop2.7.1/ hadoop 4.配置环境变量 vi /etc/profile #HADOOP_HOME export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 5.初始化环境变量 source /etc/profile 6.验证配置 hadoop version Hadoop集群配置
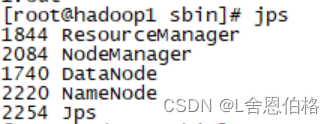
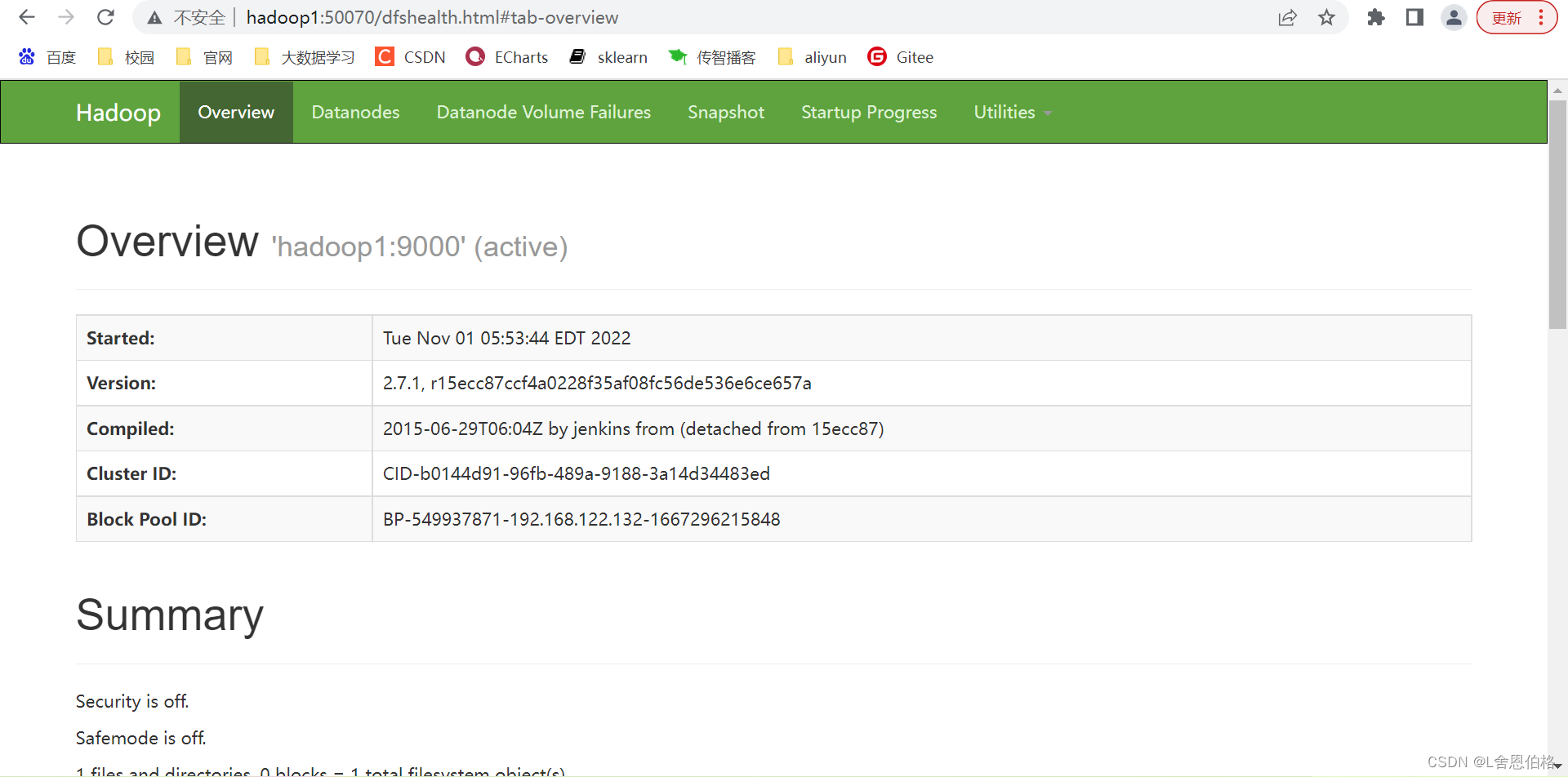
步骤: 配置文件修改文件(hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml)修改slaves文件并将集群主节点的配置文件分发到其他主节点 1.cd hadoop/etc/hadoop 2.vi hadoop-env.sh #配置JAVA_HOME export JAVA_HOME=/usr/local/jdk 3.vi yarn-env.sh #配置JAVA_HOME(记得去掉前面的#注释,注意别找错地方) 4.vi core-site.xml #配置主进程NameNode运行地址和Hadoop运行时生成数据的临时存放目录 fs.defaultFS hdfs://hadoop1:9000 hadoop.tmp.dir /usr/local/hadoop/tmp 5.vi hdfs-site.xml #配置Secondary NameNode节点运行地址和HDFS数据块的副本数量 dfs.replication 3 dfs.namenode.secondary.http-address hadoop2:50090 6.cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml #配置MapReduce程序在Yarns上运行 mapreduce.framework.name yarn 7.vi yarn-site.xml #配置Yarn的主进程ResourceManager管理者及附属服务mapreduce_shuffle yarn.resourcemanager.hostname hadoop1 yarn.nodemanager.aux-services mapreduce_shuffle 8.vi slaves hadoop1 hadoop2 hadoop3 9.scp /etc/profile root@hadoop2:/etc/profile scp /etc/profile root@hadoop3:/etc/profile scp -r /usr/local/* root@hadoop2:/usr/local/ scp -r /usr/local/* root@hadoop3:/usr/local/ 10.记得在hadoop2、hadoop3初始化 source /etc/profile Hadoop集群测试 格式化文件系统启动hadoop集群验证各服务器进程启动情况 #1.格式化文件系统 初次启动HDFS集群时,对主节点进行格式化处理 hdfs namenode -format 或者hadoop namenode -format #2.进入hadoop/sbin/ cd /usr/local/hadoop/sbin/ #3.主节点上启动HDFSNameNode进程 hadoop-daemon.sh start namenode #4.每个节点上启动HDFSDataNode进程 hadoop-daemon.sh start datanode #5.主节点上启动YARNResourceManager进程 yarn-daemon.sh start resourcemanager #6.每个节点上启动YARNodeManager进程 yarn-daemon.sh start nodemanager #7.规划节点上启动SecondaryNameNode进程 hadoop-daemon.sh start secondarynamenode #8.jps(5个进程) DataNode ResourceManager NameNode NodeManager jps
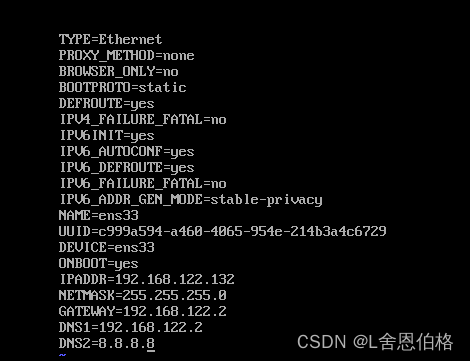
在Windows操作系统配置IP映射,文件路径C:\Windows\System32\drivers\etc,在etc文件添加如下配置内容
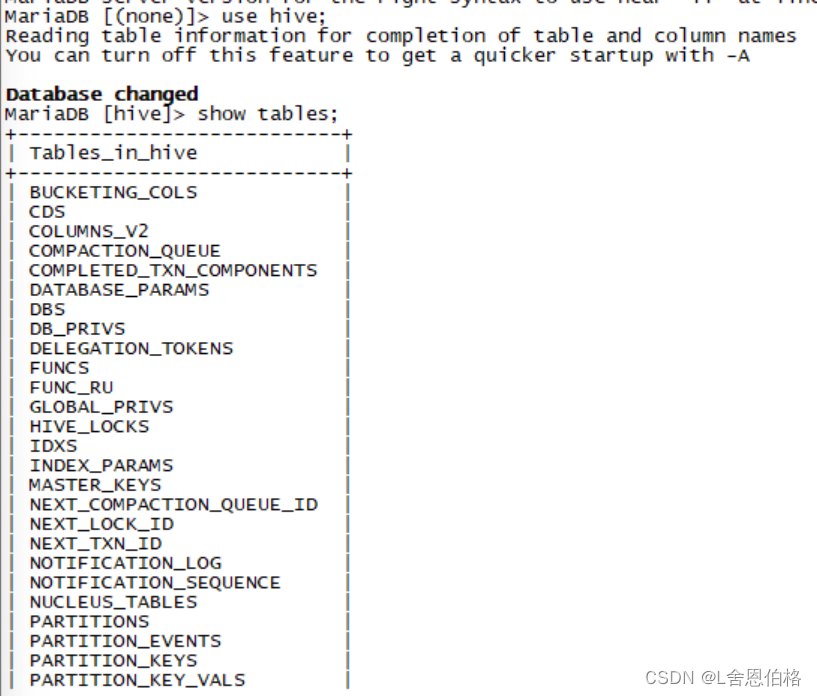
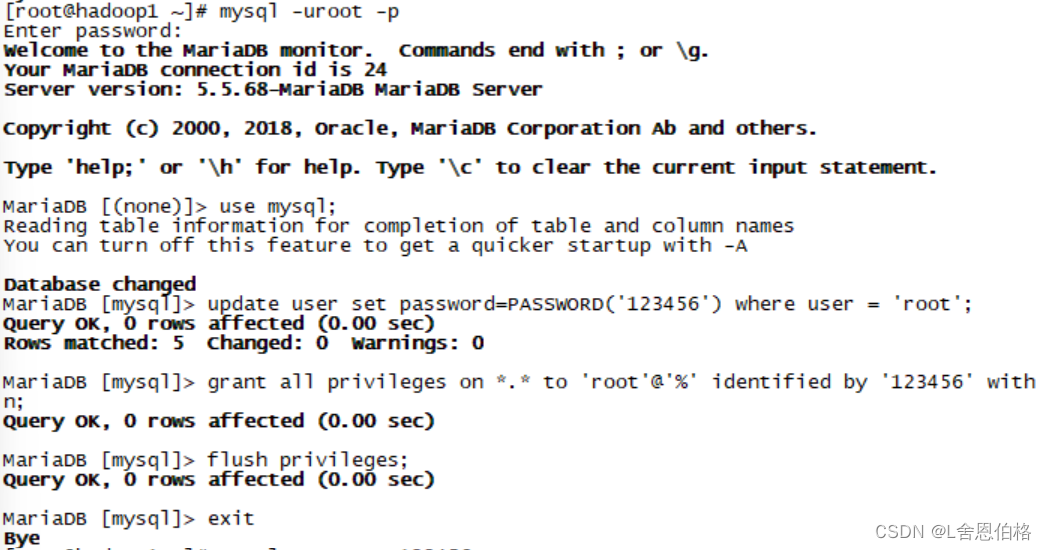 安装hive #1.解压
tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /usr/local
#2.修改名字
mv apache-hive-1.2.2-bin/ hive
#3.配置文件
cd /hive/conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh(修改 export HADOOP_HOME=/usr/local/hadoop)
#4.
vi hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database
#5.上传mysql驱动包
cd ../lib
rz(mysql-connector-java-5.1.40.jar)
#6.配置环境变量
vi /etc/profile
#添加HIVE_HOME
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
#7.启动hive
cd ../bin/
./hive
安装hive #1.解压
tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /usr/local
#2.修改名字
mv apache-hive-1.2.2-bin/ hive
#3.配置文件
cd /hive/conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh(修改 export HADOOP_HOME=/usr/local/hadoop)
#4.
vi hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database
#5.上传mysql驱动包
cd ../lib
rz(mysql-connector-java-5.1.40.jar)
#6.配置环境变量
vi /etc/profile
#添加HIVE_HOME
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
#7.启动hive
cd ../bin/
./hive
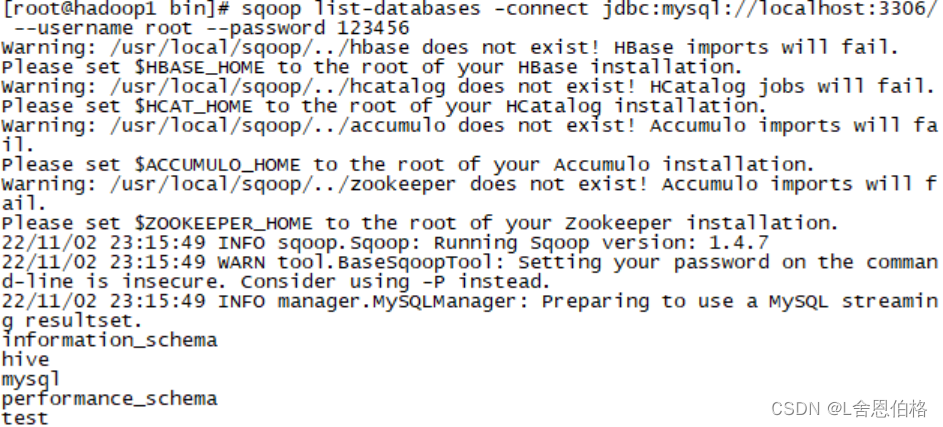
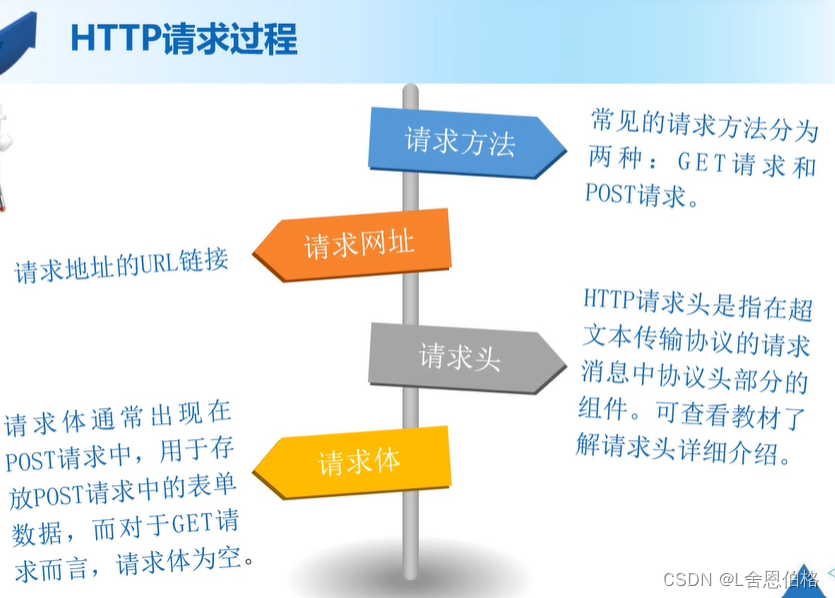
1.数据源分类(系统日志采集、网络数据采集、数据库采集) 2.HTTP请求过程
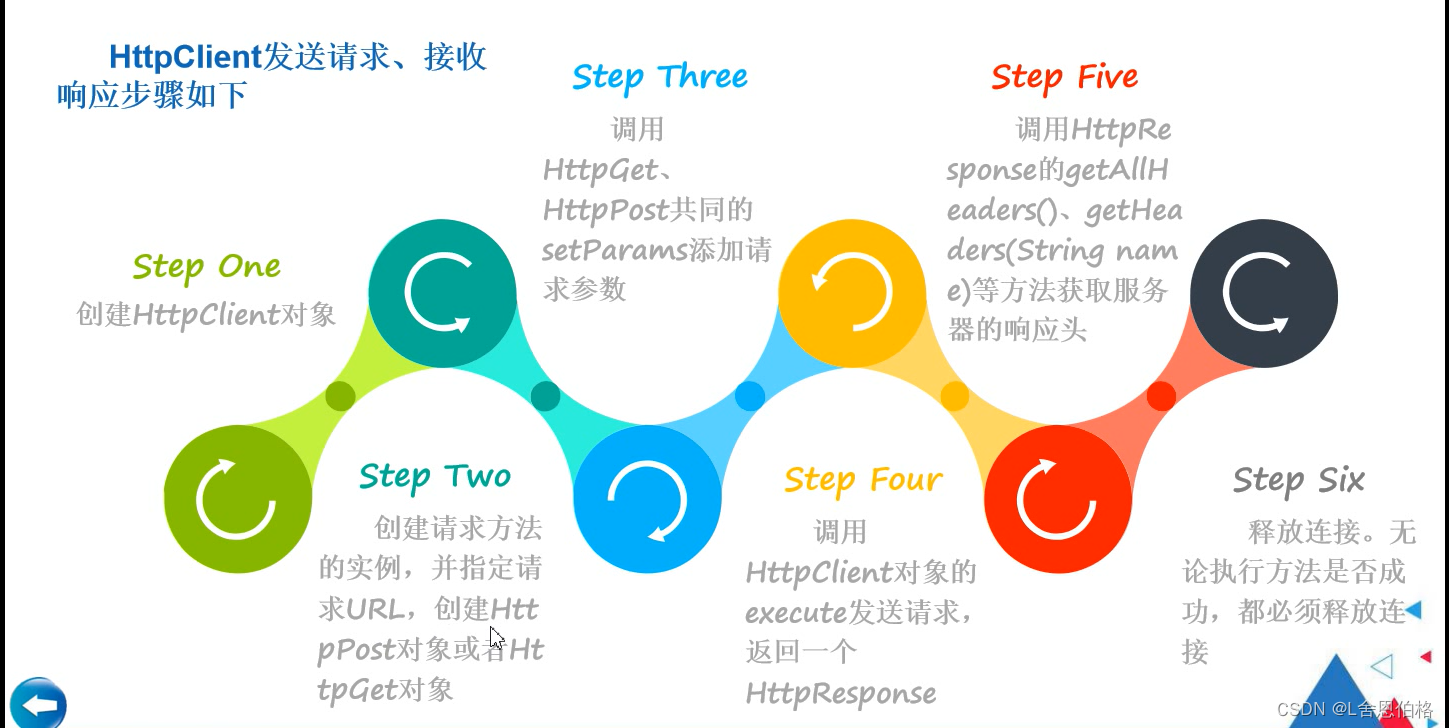
3.HttpClient
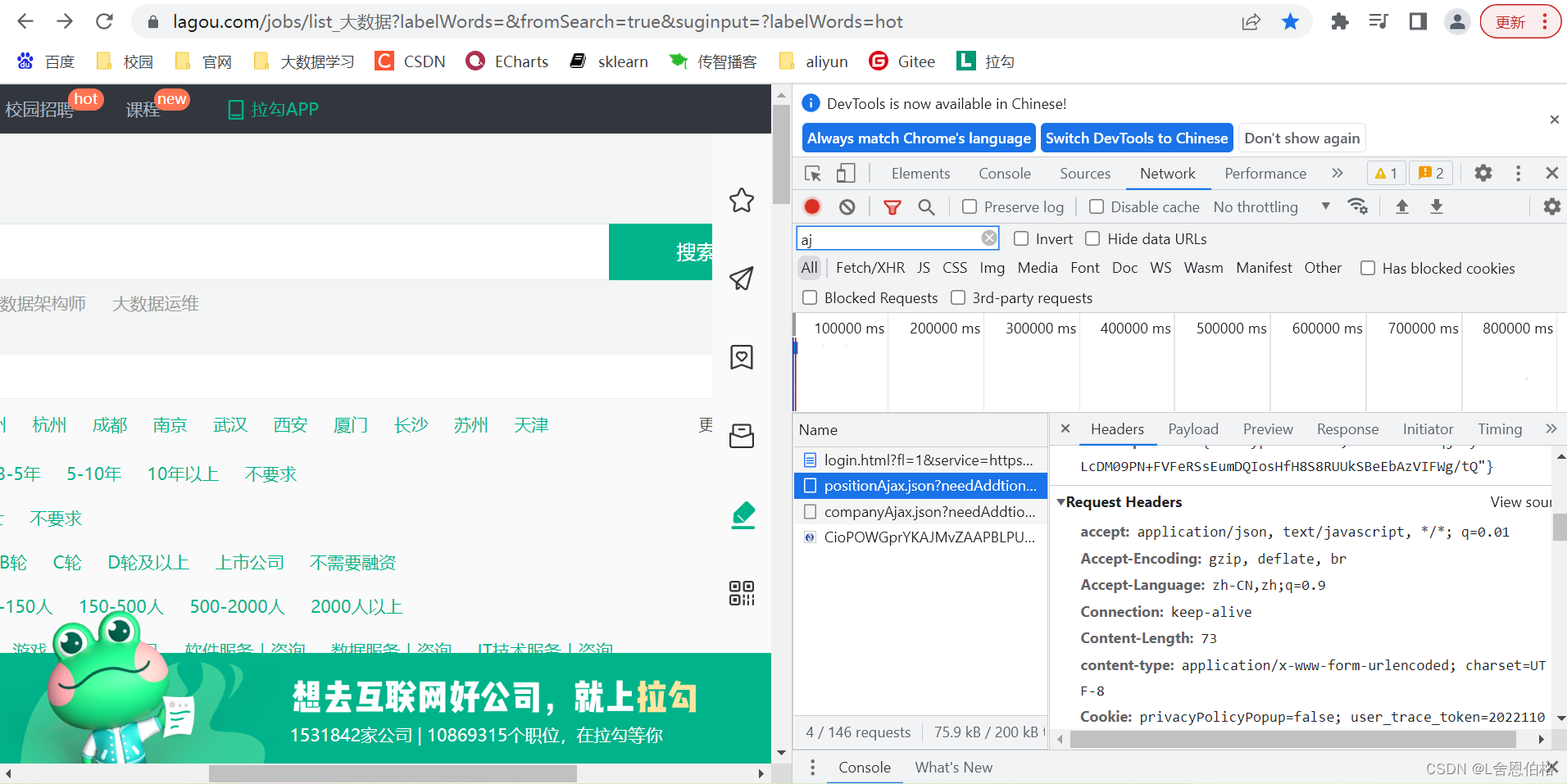
1.分析网页数据结构 使用Google浏览器进入到开发者模式,切换到Network这项,设置过滤规则,查看Ajax请求中的JSON文件;在JSON文件的“content-positionResult-result”下查看大数据职位相关的信息 2.数据采集环境准备
在pom文件中添加编写爬虫程序所需要的HttpClient和JDK1.8依赖 org.apache.httpcomponents httpclient 4.5.4 jdk.tools jdk.tools 1.8 system ${JAVA_HOME}/lib/tools.jar 3.3采集网页数据1.创建相应结果JavaBean类 通过创建的HttpClient响应结果对象作为数据存储的载体,对响应结果中的状态码和数据内容进行封装 //HttpClientResp.java package com.position.reptile; import java.io.Serializable; public class HttpClientResp implements Serializable { private static final long serialVersionUID = 2963835334380947712L; //响应状态码 private int code; //响应内容 private String content; //空参构造 public HttpClientResp() { } public HttpClientResp(int code) { super(); this.code = code; } public HttpClientResp(String content) { super(); this.content = content; } public HttpClientResp(int code, String content) { super(); this.code = code; this.content = content; } //getter和setter方法 public int getCode() { return code; } public void setCode(int code) { this.code = code; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } //重写toString方法 @Override public String toString() { return "HttpClientResp [code=" + code + ", content=" + content + "]"; } }2.封装HTTP请求的工具类 在com.position.reptile包下,创建一个命名为HttpClientUtils.java文件的工具类,用于实现HTTP请求方法 (1)定义三个全局变量 //编码格式 private static final String ENCODING = "UTF-8"; //设置连接超时时间,单位毫秒 private static final int CONNECT_TIMEOUT = 6000; //设置响应时间 private static final int SOCKET_TIMEOUT = 6000;(2)编写packageHeader()方法,用于封装HTTP请求头 // 封装请求头 public static void packageHeader(Map params, HttpRequestBase httpMethod){ if (params != null) { // set集合中得到的就是params里面封装的所有请求头的信息,保存在entrySet里面 Set entrySet = params.entrySet(); // 遍历集合 for (Entry entry : entrySet) { // 封装到httprequestbase对象里面 httpMethod.setHeader(entry.getKey(),entry.getValue()); } } }(3)编写packageParam()方法,用于封装HTTP请求参数 // 封装请求参数 public static void packageParam(Map params,HttpEntityEnclosingRequestBase httpMethod) throws UnsupportedEncodingException { if (params != null) { List nvps = new ArrayList(); Set entrySet = params.entrySet(); for (Entry entry : entrySet) { // 分别提取entry中的key和value放入nvps数组中 nvps.add(new BasicNameValuePair(entry.getKey(), entry.getValue())); } httpMethod.setEntity(new UrlEncodedFormEntity(nvps, ENCODING)); } }(4)编写HttpClientResp()方法,用于获取HTTP响应内容 public static HttpClientResp getHttpClientResult(CloseableHttpResponse httpResponse,CloseableHttpClient httpClient,HttpRequestBase httpMethod) throws Exception{ httpResponse=httpClient.execute(httpMethod); //获取HTTP的响应结果 if(httpResponse != null && httpResponse.getStatusLine() != null) { String content = ""; if(httpResponse.getEntity() != null) { content = EntityUtils.toString(httpResponse.getEntity(),ENCODING); } return new HttpClientResp(httpResponse.getStatusLine().getStatusCode(),content); } return new HttpClientResp(HttpStatus.SC_INTERNAL_SERVER_ERROR); }(5)编写doPost()方法,提交请求头和请求参数 public static HttpClientResp doPost(String url,Mapheaders,Mapparams) throws Exception{ CloseableHttpClient httpclient = HttpClients.createDefault(); HttpPost httppost = new HttpPost(url); //封装请求配置 RequestConfig requestConfig = RequestConfig.custom() .setConnectTimeout(CONNECT_TIMEOUT) .setSocketTimeout(SOCKET_TIMEOUT) .build(); //设置post请求配置项 httppost.setConfig(requestConfig); //设置请求头 packageHeader(headers,httppost); //设置请求参数 packageParam(params,httppost); //创建httpResponse对象获取响应内容 CloseableHttpResponse httpResponse = null; try { return getHttpClientResult(httpResponse,httpclient,httppost); }finally { //释放资源 release(httpResponse,httpclient); } }(6)编写release()方法,用于释放HTTP请求和HTTP响应对象资源 private static void release(CloseableHttpResponse httpResponse,CloseableHttpClient httpClient) throws IOException{ if(httpResponse != null) { httpResponse.close(); } if(httpClient != null) { httpClient.close(); } }3.封装存储在HDFS工具类 (1)在pom.xml文件中添加hadoop的依赖,用于调用HDFS API org.apache.hadoop hadoop-common 2.7.1 org.apache.hadoop hadoop-client 2.7.1(2)在com.position.reptile包下,创建名为HttpClientHdfsUtils.java文件的工具类,实现将数据写入HDFS的方法createFileBySysTime() public class HttpClientHdfsUtils { public static void createFileBySysTime(String url,String fileName,String data) { System.setProperty("HADOOP_USER_NAME", "root"); Path path = null; //读取系统时间 Calendar calendar = Calendar.getInstance(); Date time = calendar.getTime(); //格式化系统时间 SimpleDateFormat format = new SimpleDateFormat("yyyMMdd"); //获取系统当前时间,将其转换为String类型 String filepath = format.format(time); //构造Configuration对象,配置hadoop参数 Configuration conf = new Configuration(); URI uri= URI.create(url); FileSystem fileSystem; try { //获取文件系统对象 fileSystem = FileSystem.get(uri,conf); //定义文件路径 path = new Path("/JobData/"+filepath); if(!fileSystem.exists(path)) { fileSystem.mkdirs(path); } //在指定目录下创建文件 FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path(path.toString()+"/"+fileName)); //向文件中写入数据 IOUtils.copyBytes(new ByteArrayInputStream(data.getBytes()),fsDataOutputStream,conf,true); fileSystem.close(); }catch(IOException e) { e.printStackTrace(); } } }4.实现网页数据采集 (1)通过Chrome浏览器查看请求头
(2)在com.position.reptile包下,创建名为HttpClientData.java文件的主类,用于数据采集功能 public class HttpClientData { public static void main(String[] args) throws Exception { //设置请求头 Mapheaders = new HashMap(); headers.put("Cookie","privacyPolicyPopup=false; user_trace_token=20221103113731-d2950fcd-eb36-486c-9032-feab09943d4d; LGUID=20221103113731-ef107f32-06e0-4453-a89c-683f5a558e86; _ga=GA1.2.11435994.1667446652; RECOMMEND_TIP=true; index_location_city=%E5%85%A8%E5%9B%BD; __lg_stoken__=a5abb0b1f9cda5e7a6da82dd7a4397075c675acce324397a86b9cbbd4fc31a58d921346f317ba5c8c92b5c4a9ebb0650576575b67ebae44f422aeb4b1a950643cd2854eece70; JSESSIONID=ABAAAECABIEACCAC2031D7A104C1E74CDC3FABFA00BCC7F; WEBTJ-ID=20221105161123-18446d82e00bcd-0f0b3aafbd8e8e-26021a51-921600-18446d82e018bf; _gid=GA1.2.1865104541.1667635884; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1667446652,1667456559,1667635885; PRE_UTM=; PRE_HOST=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist%5F%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D%3FlabelWords%3Dhot; LGSID=20221105161124-df5ffe02-aefa-434b-b378-2d64367fddde; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2Fcommon-sec%2Fsecurity-check.html%3Fseed%3D5E87A87B3DA4AFE2BC190FBB560FB9266A5615D5937A536A0FA5205B13CAC74F0D0C1CC5AF1D2DD0C0060C9AF3B36CA5%26ts%3D16676358793441%26name%3Da5abb0b1f9cd%26callbackUrl%3Dhttps%253A%252F%252Fwww.lagou.com%252Fjobs%252Flist%5F%2525E5%2525A4%2525A7%2525E6%252595%2525B0%2525E6%25258D%2525AE%253FlabelWords%253D%2526fromSearch%253Dtrue%2526suginput%253D%253FlabelWords%253Dhot%26srcReferer%3D; _gat=1; X_MIDDLE_TOKEN=668d4b4d5ba925cb7156e2d72086c745; privacyPolicyPopup=false; sensorsdata2015session=%7B%7D; TG-TRACK-CODE=index_search; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221843b917f5d1b4-025994c92cf438-26021a51-921600-1843b917f5e3e5%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%22103.0.0.0%22%2C%22%24latest_referrer_host%22%3A%22%22%7D%2C%22%24device_id%22%3A%221843b917f5d1b4-025994c92cf438-26021a51-921600-1843b917f5e3e5%22%7D; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1667636243; LGRID=20221105161724-fad126be-48da-4684-aa52-1ff6cfb2dffd; SEARCH_ID=535076fc2a094fa2913263e0079a9038; X_HTTP_TOKEN=a18b9f65c1cbf1490626367661a3afc88e7340da5d"); headers.put("Connection","keep-alive"); headers.put("Accept","application/json, text/javascript, */*; q=0.01"); headers.put("Accept-Language","zh-CN,zh;q=0.9"); headers.put("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64)"+"AppleWebKit/537.36 (KHTML, like Gecko)"+"Chrome/103.0.0.0 Safari/537.36"); headers.put("content-type","application/x-www-form-urlencoded; charset=UTF-8"); headers.put("Referer", "https://www.lagou.com/jobs/list_%E5%A4%A7%E6%95%B0%E6%8D%AE?labelWords=&fromSearch=true&suginput=?labelWords=hot"); headers.put("Origin", "https://www.lagou.com"); headers.put("x-requested-with","XMLHttpRequest"); headers.put("x-anit-forge-token","None"); headers.put("x-anit-forge-code","0"); headers.put("Host","www.lagou.com"); headers.put("Cache-Control","no-cache"); Mapparams = new HashMap(); params.put("kd","大数据"); params.put("city","全国"); for (int i=1;i |
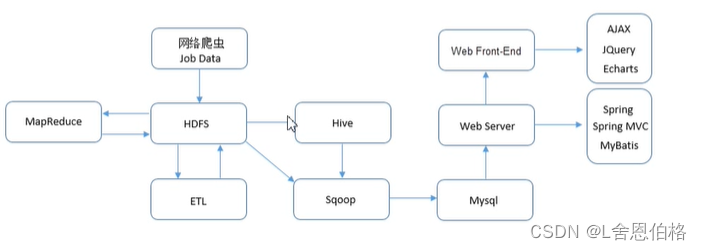



【本文地址】