机器学习 |
您所在的位置:网站首页 › 大学体测最终成绩计算方法 › 机器学习 |
机器学习
|
一、问题描述
某学校为提高教学和思想工作水平,希望能够对学生的学习成绩进行预测,从而提前发现学生的学业问题。为了实现这一目标,该学校整理了 20 年的成绩数据的五门课程的成绩,其中第一学期课程两门,分别为 A 和 B ;第二学期两门课程,分别为 C 和 D ;第三学期一门课程 E。数据存放于 scores.xlsx 文件中(数据集链接放在了文末),各字段的含义如下: 要求分别利用 sklearn 提供的线性回归( Linear Regression )、岭回归( Ridge Regression )、鲁棒回归(使用 Huber Regression )、支持向量回归( SVR )、最近邻回归( Nearest Neighbors Regression )、决策树回归( Decision Trees )、神经网络回归( Neural Network Regression )共七种回归算法实现对成绩的预测。 并对训练出的七种回归器进行性能评估,利用测试集计算七种回归器的四项性能指标:解释方差( Explained Variance )、平均绝对误差( MAE,Mean Absolute Error )、平均平方误差( MSE,Mean Squared Error )和中位绝对误差( MedAE,Median Absolute Error )。 三、代码实现1、线性回归 import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error import sklearn.metrics as metrics from sklearn.model_selection import train_test_split import time # 读表 dataset = pd.read_excel('F:\Desktop\智能物联网课程\scores.xlsx') x1 = dataset.iloc[:, [2, 3]].values # 提取所有的行,索引为2,3的列 x2 = dataset.iloc[:, [2, 3, 4, 5]].values # 提取所有的行,索引为2,3的列 y1 = dataset.iloc[:, 4].values y2 = dataset.iloc[:, 5].values y3 = dataset.iloc[:, 6].values dataset.head() # 数据预处理 X_train_C, X_test_C, y_train_C, y_test_C = train_test_split(x1, y1, test_size=0.3, random_state=0) X_train_D, X_test_D, y_train_D, y_test_D = train_test_split(x1, y2, test_size=0.3, random_state=0) X_train_E, X_test_E, y_train_E, y_test_E = train_test_split(x2, y3, test_size=0.3, random_state=0) # 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导 sc = StandardScaler() # 将标准化的数据进行重定义 X_train_C = sc.fit_transform(X_train_C) X_test_C = sc.transform(X_test_C) y_train_C = sc.fit_transform(y_train_C.reshape(-1, 1)) y_test_C = sc.transform(y_test_C.reshape(-1, 1)) X_train_D = sc.fit_transform(X_train_D) X_test_D = sc.transform(X_test_D) y_train_D = sc.fit_transform(y_train_D.reshape(-1, 1)) y_test_D = sc.transform(y_test_D.reshape(-1, 1)) X_train_E = sc.fit_transform(X_train_E) X_test_E = sc.transform(X_test_E) y_train_E = sc.fit_transform(y_train_E.reshape(-1, 1)) y_test_E = sc.transform(y_test_E.reshape(-1, 1)) start = time.perf_counter() # 线性回归 lr = LinearRegression() lr.fit(X_train_C, y_train_C) # 使用训练好的模型对X_test进行预测,结果存储在变量y_pred中 print("score_C的预测结果:") y_pred = lr.predict(X_test_C) print('平均平方误差Mean squared error: %.2f' % mean_squared_error(y_test_C, y_pred)) # 平均平方误差 print('解释方差Explained variance: %.2f' % metrics.explained_variance_score(y_test_C, y_pred)) # 解释方差 print('平均绝对误差Mean Absolute Error: %.2f' % metrics.mean_absolute_error(y_test_C, y_pred)) # 平均绝对误差 print('中位绝对误差edian Absolute Error: %.2f\n' % metrics.median_absolute_error(y_test_C, y_pred)) # 中位绝对误差 lr.fit(X_train_D, y_train_D) print("score_D的预测结果:") y_pred = lr.predict(X_test_D) print('平均平方误差Mean squared error: %.2f' % mean_squared_error(y_test_D, y_pred)) # 平均平方误差 print('解释方差Explained variance: %.2f' % metrics.explained_variance_score(y_test_D, y_pred)) # 解释方差 print('平均绝对误差Mean Absolute Error: %.2f' % metrics.mean_absolute_error(y_test_D, y_pred)) # 平均绝对误差 print('中位绝对误差edian Absolute Error: %.2f\n' % metrics.median_absolute_error(y_test_D, y_pred)) # 中位绝对误差 lr.fit(X_train_E, y_train_E) print("score_E的预测结果:") y_pred = lr.predict(X_test_E) print('平均平方误差Mean squared error: %.2f' % mean_squared_error(y_test_E, y_pred)) # 平均平方误差 print('解释方差Explained variance: %.2f' % metrics.explained_variance_score(y_test_E, y_pred)) # 解释方差 print('平均绝对误差Mean Absolute Error: %.2f' % metrics.mean_absolute_error(y_test_E, y_pred)) # 平均绝对误差 print('中位绝对误差edian Absolute Error: %.2f\n' % metrics.median_absolute_error(y_test_E, y_pred)) # 中位绝对误差 end = time.perf_counter() print('总预测时间: %.8s Seconds' % (end - start))2、岭回归 import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error import sklearn.metrics as metrics from sklearn.model_selection import train_test_split import time # 读表 dataset = pd.read_excel('F:\Desktop\智能物联网课程\scores.xlsx') x1 = dataset.iloc[:, [2, 3]].values # 提取所有的行,索引为2,3的列 x2 = dataset.iloc[:, [2, 3, 4, 5]].values # 提取所有的行,索引为2,3的列 y1 = dataset.iloc[:, 4].values y2 = dataset.iloc[:, 5].values y3 = dataset.iloc[:, 6].values dataset.head() # 数据预处理 X_train_C, X_test_C, y_train_C, y_test_C = train_test_split(x1, y1, test_size=0.3, random_state=0) X_train_D, X_test_D, y_train_D, y_test_D = train_test_split(x1, y2, test_size=0.3, random_state=0) X_train_E, X_test_E, y_train_E, y_test_E = train_test_split(x2, y3, test_size=0.3, random_state=0) # 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导 sc = StandardScaler() # 将标准化的数据进行重定义 X_train_C = sc.fit_transform(X_train_C) X_test_C = sc.transform(X_test_C) y_train_C = sc.fit_transform(y_train_C.reshape(-1, 1)) y_test_C = sc.transform(y_test_C.reshape(-1, 1)) X_train_D = sc.fit_transform(X_train_D) X_test_D = sc.transform(X_test_D) y_train_D = sc.fit_transform(y_train_D.reshape(-1, 1)) y_test_D = sc.transform(y_test_D.reshape(-1, 1)) X_train_E = sc.fit_transform(X_train_E) X_test_E = sc.transform(X_test_E) y_train_E = sc.fit_transform(y_train_E.reshape(-1, 1)) y_test_E = sc.transform(y_test_E.reshape(-1, 1)) start = time.perf_counter() # 岭回归 ridge = Ridge() ridge.fit(X_train_C, y_train_C) # 使用训练好的模型对X_test进行预测,结果存储在变量y_pred中 print("score_C的预测结果:") y_pred = ridge.predict(X_test_C) print('平均平方误差Mean squared error: %.2f' % mean_squared_error(y_test_C, y_pred)) # 平均平方误差 print('解释方差Explained variance: %.2f' % metrics.explained_variance_score(y_test_C, y_pred)) # 解释方差 print('平均绝对误差Mean Absolute Error: %.2f' % metrics.mean_absolute_error(y_test_C, y_pred)) # 平均绝对误差 print('中位绝对误差edian Absolute Error: %.2f\n' % metrics.median_absolute_error(y_test_C, y_pred)) # 中位绝对误差 ridge.fit(X_train_D, y_train_D) print("score_D的预测结果:") y_pred = ridge.predict(X_test_D) print('平均平方误差Mean squared error: %.2f' % mean_squared_error(y_test_D, y_pred)) # 平均平方误差 print('解释方差Explained variance: %.2f' % metrics.explained_variance_score(y_test_D, y_pred)) # 解释方差 print('平均绝对误差Mean Absolute Error: %.2f' % metrics.mean_absolute_error(y_test_D, y_pred)) # 平均绝对误差 print('中位绝对误差edian Absolute Error: %.2f\n' % metrics.median_absolute_error(y_test_D, y_pred)) # 中位绝对误差 ridge.fit(X_train_E, y_train_E) print("score_E的预测结果:") y_pred = ridge.predict(X_test_E) print('平均平方误差Mean squared error: %.2f' % mean_squared_error(y_test_E, y_pred)) # 平均平方误差 print('解释方差Explained variance: %.2f' % metrics.explained_variance_score(y_test_E, y_pred)) # 解释方差 print('平均绝对误差Mean Absolute Error: %.2f' % metrics.mean_absolute_error(y_test_E, y_pred)) # 平均绝对误差 print('中位绝对误差edian Absolute Error: %.2f\n' % metrics.median_absolute_error(y_test_E, y_pred)) # 中位绝对误差 end = time.perf_counter() print('总预测时间: %.8s Seconds' % (end - start))3、其他的回归自己写吧 四、注意点1、代码中的归一化处理是不关注年份,全部数据进行归一化。严谨的归一化处理应该是根据年份来进行,模型score可以达到90%。 2、代码中的回归模型使用的是默认参数,想得到更精确的结果可以自行调整模型参数。 3、上面的代码不能完全复制,有的回归可能对y_train_C的格式有要求,这个根据给出的error来自行调整。比如在决策树回归中,这一句应该这么写 tree_clf.fit(X_train_C, y_train_C.astype('int')) 五、数据集链接:https://pan.baidu.com/s/1fr8_1kvYGwm174RbtUd8YA?pwd=kp2t 提取码:kp2t |
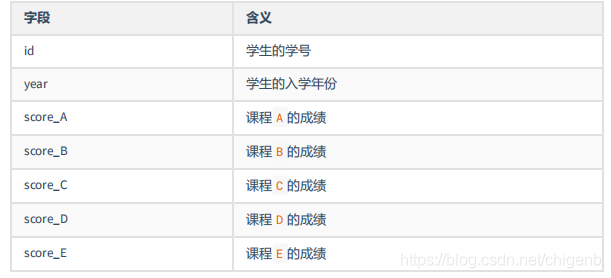 现在,你需要根据该学校提供的数据,对数据进行分析,并尝试找到预测课程 C 、 D 、 E 的模型,并对预测模型的性能进行分析。
现在,你需要根据该学校提供的数据,对数据进行分析,并尝试找到预测课程 C 、 D 、 E 的模型,并对预测模型的性能进行分析。【本文地址】
今日新闻 |
推荐新闻 |