基于物品的协同过滤算法 |
您所在的位置:网站首页 › 基于物品的协同过滤算法例子图片大全 › 基于物品的协同过滤算法 |
基于物品的协同过滤算法
|
输入
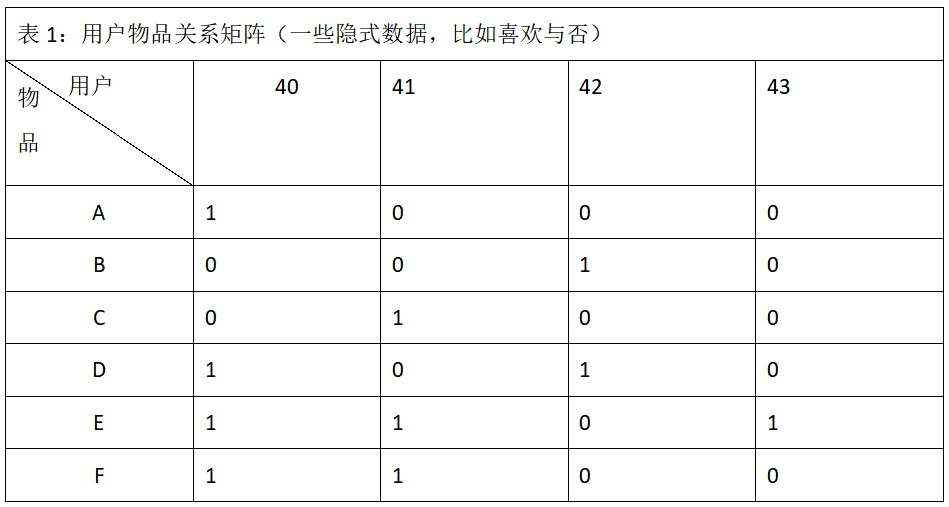
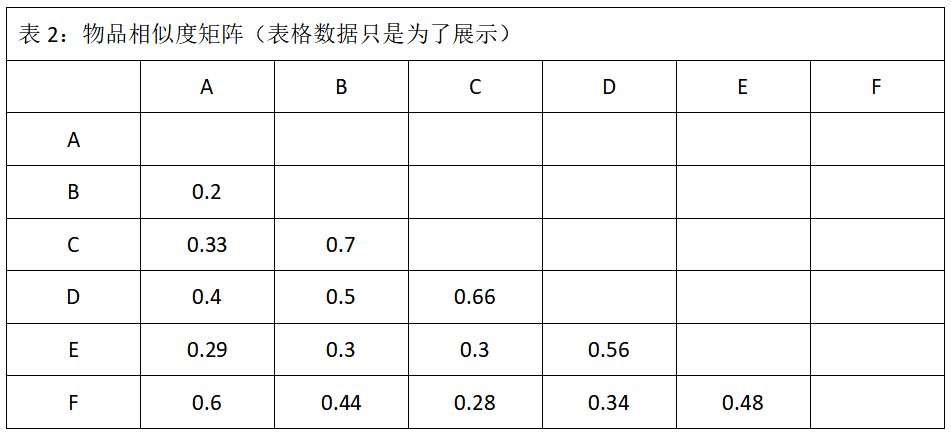
输入:物品用户行为矩阵,行为矩阵中的元素只有0和1,0代表行为的负类,1代表行为的正类。比如不喜欢与喜欢、不点赞与点赞、不收藏与收藏。 输出输出1:根据输入可计算得到物品相似度矩阵; 输出2:根据输入中物品用户行为矩阵得到用户喜欢的物品,用户喜欢的物品结合输出1得到的物品相似度矩阵,可以计算得到用户喜欢度最高的k个物品,并推荐给用户。 前言基于物品的协同过滤算法适用于物品数明显小于用户数的场景,适用于长尾物品丰富,用户个性化需求强烈的领域。但是该算法不适用于物品变化较快的场景,比如新闻类的应用,如果物品一直在变化,那么会增加物品相似度更新的频率,不够稳定,此类场景下可以考虑选择基于用户的协同过滤算法。 原理基于物品的协同过滤诞生于1998年,是由亚马逊首先提出,适用于用户明显多于物品的情况。基于物品的协同过滤算法的原始想法是:给用户推荐用户喜欢的物品相似的物品。问题在于“相似的物品”是如何度量的,基于内容的推荐系统中,物品相似是用内容的相似性计算出来的,但是实际上人的群体行为还是会有一些内容特征抓不到的相似性。 在基于物品的协同过滤之前,最常用的是基于用户的协同过滤。基于用户的协同过滤首秀按计算相似用户,然后再根据相似用户的喜好推荐物品,但是基于用户的协同过滤存在以下问题: 用户的数量往往很多,用户之间相似度计算起来工作量大; 用户的兴趣爱好变化较快,所以这个动态变化的过程很难被跟踪和记录。基于物品的协同过滤可以较好的解决上面的问题。物品的数量远远少于用户的数量,而且物品之间的相似度不易改变,物品对应的消费者数量大,所以计算出来的物品相似度比较可靠。 协同过滤算法依赖于用户物品之间的关系矩阵(如表1所示)。基于物品的协同过滤算法除了依赖用户物品之间的关系矩阵,还依赖于物品之间的相似度矩阵(如表2所示)。
计算物品的相似度有好几种方法,比如余弦相似度、杰卡德(Jaccard)相似度,余弦相似度适用于评分数据,杰卡德(Jaccard)相似度适用于隐式反馈数据,由于这里使用的用户户物品矩阵是隐式反馈数据,所以介绍下Jaccard相似度的计算公式: 式子表示的是物品M与N的相似度,其中 通过上面的公式计算得到物品相似度矩阵后,就可以结合用户已经喜欢过的物品集合给用户推荐物品了,可以通过下面的公式计算用户对待推荐物品的评分:
计算用户u对物品i的评分,需要遍历用户喜欢过的物品集合A,对于集合A中的任意物品j,求用户u对j评分 可以依次求得用户u对所有物品的评分,去掉用户已经喜欢过的物品后,保留分数最高的N个结果推荐给用户u。 python代码实现 1 #1、手动构造一个用户物品行为矩阵,行为物品,列为用户,矩阵元素值为(0,1),0代表不感兴趣,1代表感兴趣 2 #2、根据用户行为矩阵,计算出物品相似度矩阵 3 #3、根据物品相似度矩阵以及用户喜欢的物品推荐出TopN个物品 4 import numpy as np 5 # 100*200的物品用户行为矩阵 6 item_user_matrix = np.random.randint(0,2,size=(100, 200),dtype=np.int) 7 8 # 计算物品的相似度矩阵sim,形状为100*100 9 # 对于隐式反馈数据,使用杰卡德(Jaccard)相似系数计算物品的相似度,sim(i,j)表示物品i与物品j的相似度, 10 # 等于同时喜欢物品i和j的用户数除以喜欢物品i和物品j的用户总数 11 rowNum = item_user_matrix.shape[0] 12 columNum = item_user_matrix.shape[0] 13 sim_matrix = np.zeros((rowNum, columNum)).astype('float') 14 #同时喜欢下标为colum的物品和下标为row的物品的用户数 15 columAndRow_NUM = 0 16 #喜欢下标为colum的物品的用户数与喜欢下标为row的物品的用户数之和 17 columOrRow_NUM = 0 18 for row in range(0, rowNum): 19 for colum in range(0, columNum): 20 if colum < row: # 只需要对矩阵下三角更新 21 # 因为矩阵元素只有0和1,求点积即为交集 22 columAndRow_NUM = np.dot(item_user_matrix[colum], item_user_matrix[row]) 23 # 元素相加求和,就求得并集 24 columOrRow_NUM = item_user_matrix[colum].sum() + item_user_matrix[row].sum() 25 sim_matrix[row][colum] = columAndRow_NUM/columOrRow_NUM 26 print('columAndRow_NUM:{}, columOrRow_NUM:{}, sim_matrix[{}][{}]:{}'. 27 format(columAndRow_NUM,columOrRow_NUM, row, colum, sim_matrix[row][colum])) 28 29 # 根据物品相似度矩阵以及用户喜欢的物品推荐出TopN个物品 30 # 欲求用户user对物品i的喜欢度,首先求出用户user喜欢的物品集合,根据物品相似度矩阵,求出物品i与用户user喜欢的物品对应的相似度 31 # 相似度与喜欢度相乘求和,除以相似度之和,得到的商为用户user对物品i的相似度 32 # 求得喜欢度之后,选择topN个做推荐 33 def topNrecom(user, N): 34 # 字典的键为物品下标编号,值为喜欢度 35 result = {} 36 # user对应的物品向量 37 itemVec = item_user_matrix[:,user] 38 for item in range(0,rowNum): 39 # 直接做点积即可,因为用户还没有发生行为的物品喜欢度为0,与相似度相乘还是0,无影响 40 user_item_sim_sum = np.dot(itemVec, sim_matrix[item]) 41 result[item] = user_item_sim_sum; 42 # 从result中去掉用户已经发生过行为的物品,然后再推荐出预测喜欢度较高的top N个物品 43 for index in range(0, len(itemVec)): 44 if(1 == itemVec[index]): 45 result.pop(index) 46 return sorted(result.items() , key=lambda x: x[1], reverse=True)[:N] 47 48 user = 122 49 N = 10 50 itemList = topNrecom(user, N) 51 print('user[{}] top [{}] recom result:{}'.format(user, N, itemList))代码运行结果 本文代码手动构造了一个100*200的物品用户行为矩阵,实际工业环境中肯定不止这点数据量,本中重点在于讲解原理和一种实现方法,对于某个用户而言,推荐喜欢度最高的10个物品,代码运行结果如下: 1 user[122] top [10] recom result:[(98, 13.734837466951667), (97, 13.534563830373337), (90, 12.351537112348055), (94, 12.194631579469013), (82, 11.25929195188074), (84, 10.662303442296619), (80, 10.60327372276929), (79, 10.570187047487309), (77, 9.94780886977415), (69, 8.431845325504977)]按照喜欢度从高到底排序,推荐的物品id为98、97、90、94、82、84、80、79、77、69。 |
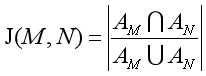
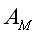 表示喜欢物品M的用户的集合,
表示喜欢物品M的用户的集合,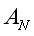 表示喜欢物品N的用户的集合,分子为同时喜欢物品M,N的用户集合,分母为喜欢物品M,N的用户集合的并集。
表示喜欢物品N的用户的集合,分子为同时喜欢物品M,N的用户集合,分母为喜欢物品M,N的用户集合的并集。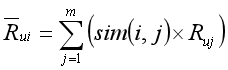
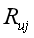 与物品i、j的相似度sim(i,j)之积,然后累加得到用户u对物品i的评分。
与物品i、j的相似度sim(i,j)之积,然后累加得到用户u对物品i的评分。【本文地址】
今日新闻 |
推荐新闻 |