散列表(哈希表) |
您所在的位置:网站首页 › 埃及元素设计及分析 › 散列表(哈希表) |
散列表(哈希表)
|
目录 散列表 散列函数 散列表常用函数 1. 直接定址法 2. 除留余数法 2.1. exmple 3. 数字分析法 4. 平方取中法 5. 折叠法 处理冲突的方法 1. 开放定址法---线性探测 2. 二次探测法 3. 再Hash法 4. 拉链法(链地址法) 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。散列表对应关系f称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。Hash主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做Hash值. 也可以说,Hash就是找到一种数据内容和数据存放地址之间的映射关系。Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。 散列表散列的基本思想:在记录的存储地址和它的关键码之间建立一个确定的对应关系. 这样,不经过比较,一次读取就能够得到所查元素的查找方法
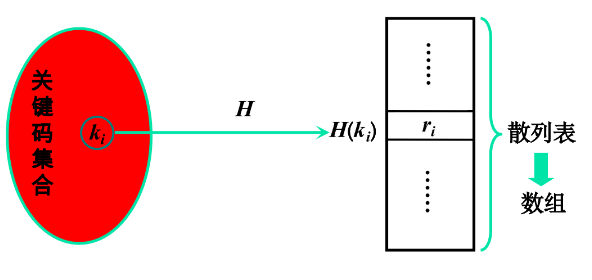
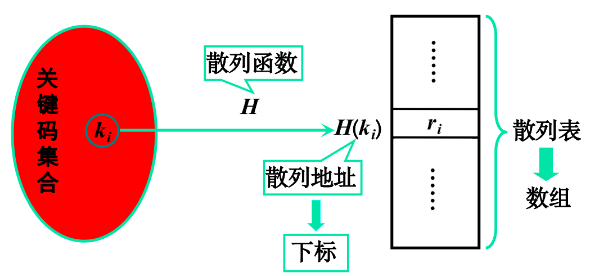
散列表:采用散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间称为散列表
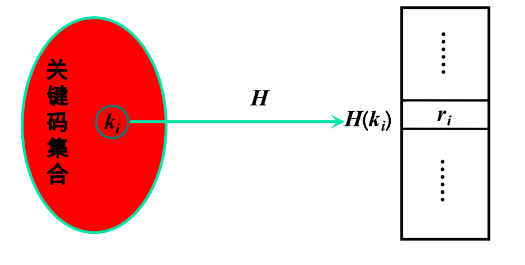
散列函数:将关键码映射伟散列表中适当存储位置的函数
散列地址:由散列函数所得的存储位置
疑问: 散列函数仅仅是一种查找技术吗? 回答:散列既是一种查找技术,也是一种存储技术 散列是一种完整的存储结构吗? 散列只是通过记录的关键码定位该记录,没有完整地表达记录之间地逻辑关系 所以,散列主要是面向查找的存储结构 关键问题: ⑴ 散列函数的设计。如何设计一个简单、均匀、存储利用率高的散列函数。 ⑵ 冲突的处理。如何采取合适的处理冲突方法来解决冲突。 散列函数设计散列函数一般应遵循以下原则: ⑴ 计算简单。散列函数不应该有很大的计算量,否则会降低查找效率。 ⑵ 函数值即散列地址分布均匀。函数值要尽量均匀散布在地址空间,这样才能保证存储空间的有效利用并减少冲突。 散列表常用函数 1. 直接定址法散列函数是关键码的线性函数,即:
例:关键码集合为{10, 30, 50, 70, 80, 90},选取的散列函数为H(key)=key/10,则散列表为:
散列函数为:
一般情况下,选p为小于或等于表长(最好接近表长)的最小素数。
以关键字的平方值的中间几位作为存储地址,求"关键字的平方值"的目的是"扩大差别",同时平方值的中间各位又能收到整个关键字中各个位数的影响
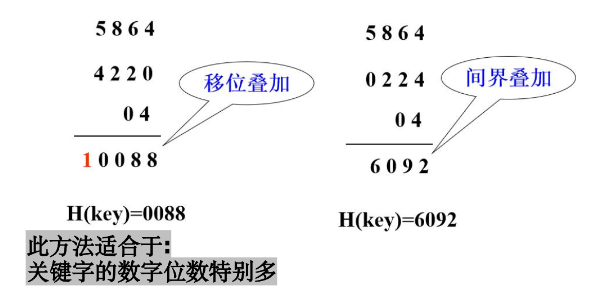
将关键字分割成若干部分,然后取他们的叠加和为哈希地址.由两种叠加处理的方法:移位叠加和间界叠加
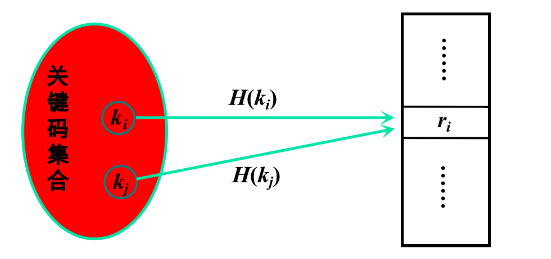
冲突:对于两个不同关键码ki≠kj,有H(ki)=H(kj),即两个不同的记录需要存放在同一个存储位置,ki和kj相对于H称做同义词。
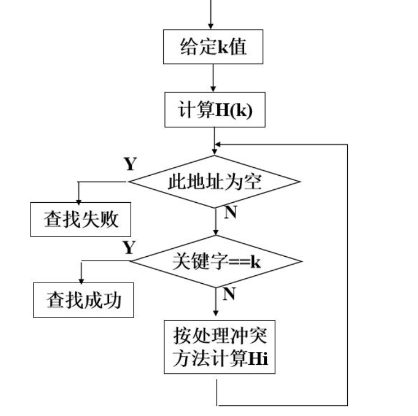
基本思想:有冲突时就去寻找下一个空的哈希地址,只要哈希表足够大,空的哈希地址总能够找到,并且将数据元素存入
一旦冲突,就找下一个空地址存入 优点:只要哈希表未被填满,保证能找到一个空地址单元存放有冲突的元素 缺点:能使第i个哈希地址的同义词存入第i+1个地址,这样本应存入第i+1个哈希地址的元素变成了第i+2个哈希地址的同义词,……,产生“聚集”现象,降低查找效率 步骤: 取数据元素的关键字key,计算其哈希函数值(地址)。若该地址对应的存储 空间还没有被占用,则将该元素存入;否则执行step2解决冲突 根据选择的冲突处理方法,计算关键字key的下一个存储地址。若下一个存储地址仍被占用,则继续执行step2,直到找 到能用的存储地址为止 2. 二次探测法
就是往前面和后面找 3. 再Hash法基本思想:H2(key)是另设定的一个哈希函数,它的函数值应该和m互质 互质是公约数只有1的两个整数,叫做互质整数。公约数只有1的两个自然数,叫做互质自然数,后者是前者的特殊情形。 互质,若N个整数的最大公因数是1,则称这N个整数互质。 例如8,10的最大公因数是2,不是1,因此不是整数互质。 7,11,13的最大公因数是1,因此这是整数互质。 哈哈哈哈哈哈哈,小学数学没学好吧,我就猜到你互质不知道是啥
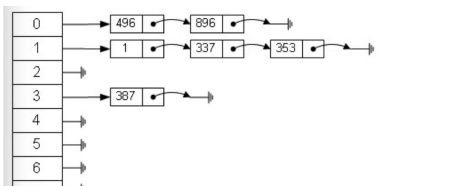
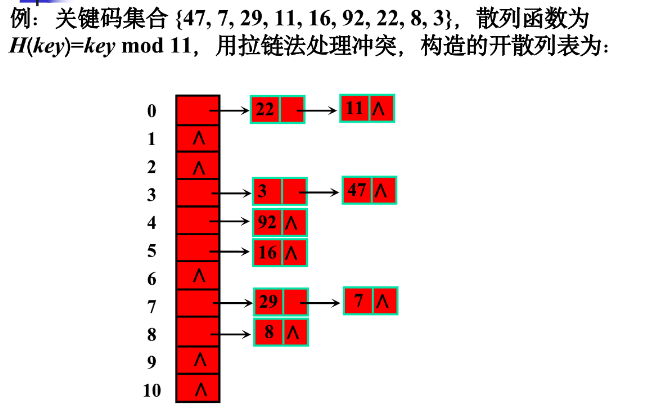
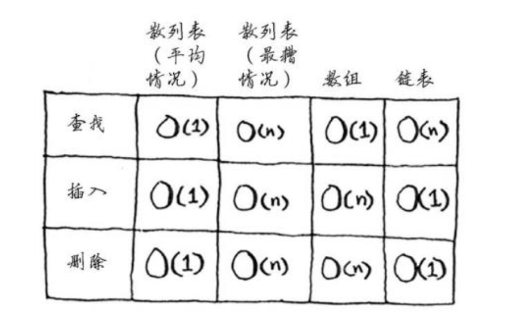
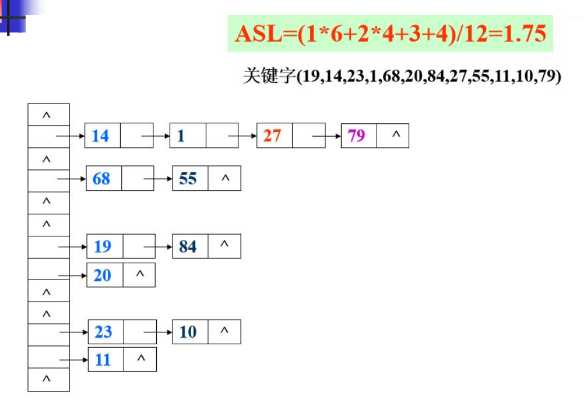
基本思想:将所有散列地址相同的记录,即所有同义词的记录存储再一个单链表中(称为同义词子表),在散列表中存储的是所有同义词子表的头指针 同拉链法处理冲突构造的散列表叫做开散列表 设n个记录存储在长度为m的散列表中,则同义词子表的平均长度为n/m 数组的特点是:寻址容易,插入和删除困难; 链表的特点是:寻址困难,插入和删除容易。 那么我们能不能综合两者的特性,做出一种寻址容 易,插入删除也容易的数据结构?答案是肯定的, 这就是我们要提起的哈希表,哈希表有多种不同的 实现方法,我接下来解释的是最常用的一种方法: 拉链法,我们可以理解为“链表的数组”
在拉链法构造的散列表查找算法——伪代码 计算散列地址j; 在第j个同义词子表中顺序查找; 若查找成功,则返回结点的地址;否则,将待查记录插在第j个同义词子表的表头。
希望能帮到你~ |

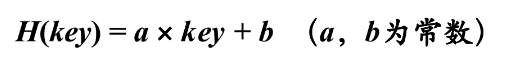


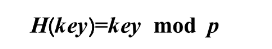
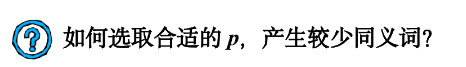









【本文地址】
今日新闻 |
推荐新闻 |