无损压缩编码(上):LZ编码 |
您所在的位置:网站首页 › 在jpeg中用到了哪些压缩编码技术方法 › 无损压缩编码(上):LZ编码 |
无损压缩编码(上):LZ编码
|
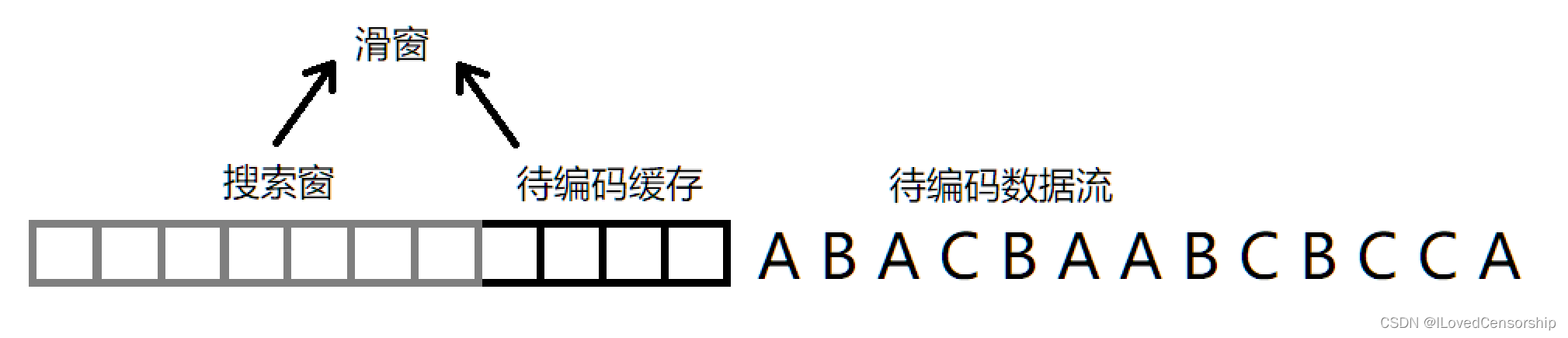
LZ77和LZ78由Abraham Lempel和Jacob Ziv分别于1977年和1978年发表,LZ即为Lempel和Ziv的首字母拼在一起。1984年Terry Welch在LZ78的基础上进行改进,发表了LZW(即Lempel–Ziv–Welch)编码。三种编码均为无损压缩编码,旨在不产生信息失真的同时降低信息冗余度。 三种编码的核心在于,按顺序读取待编码数据流,如果后面的数据流出现了前面出现过的内容,就用某种方式把这些相同的部分用某种记号来替代掉,如果记号占用的空间比原数据流更小,就能实现无损压缩。例如,如果有一字符串ABCABC,只需要记成2ABC即可,这样就可以在不失真的情况下记录更少的字符,降低信息冗余度。这种用记号替代的方式,不需要事先检索一遍整个数据流,而是相当于拿着本字典一边读取数据流一边翻译,因此也被称为字典编码;而霍夫曼编码、算术编码等则是基于概率统计的编码。 LZ77 (LZSS) 编码对于LZ77编码而言,它使用一个滑窗(sliding window)来读取待编码数据流,比如一个字符串。滑窗由两部分组成——一部分用于缓存特定大小的待编码的数据,称为待编码缓存(lookahead buffer);一部分用于缓存特定大小的已编码的数据,称为搜索窗(search window),当我们用代码实现LZ77编码时首先需要指定这两个区域的大小,整个滑窗的大小通常记为W。 (有些人以为sliding window指的就是search window,这实际上是错误的)
原始码为ABACBAABCBCCA 窗口向右滑动,依次读取数据,下图是编码的起始状态
LZ77编码的输出为长度-距离对(length-distance pairs),记为(D,L)c;D代表偏移量或距离,L代表匹配字符串长度,c代表字符串(char),接下来我将详细解释这三个值是怎么来的。 每完成一次编码,滑窗都向右移动距离L(除了一种情况,下面会解释),从待编码缓存左侧输出的值进入到搜索窗,有时候也把搜索窗称为字典,因为搜索窗的内容起到字典的作用;为了方便,以下简称待编码缓存为LAB(lookahead buffer)。 要产生编码输出,就要在搜索窗内找到与lab内容匹配的字符串。首先从lab中的左起第一个字符开始找,本例中为A;如果搜索窗中有匹配的字符串,则从左起前两个字符串开始找,本例中为AB,依此类推...直到在搜索窗中能找到整个lab内容(本例中为ABAC)为止。一旦搜索窗中找不到更长的匹配字符串了,则输出"DLC",而现在我们的搜索窗为空,当然找不到任何匹配字符串了。在这种初始状态下,D=0,L=0,c=lab中的第一个字符,本例中为A;即输出为(0,0)A。 完成一次输出后,窗口向右滑动,如下图所示
L实际上是搜索窗与lab的最长匹配字符串的长度,如果没有匹配字符串,L=0,但窗口仍然向右滑动,滑动的距离为1;这就是当没有匹配字符串时,滑动距离的特殊情况。滑动窗口是为了让已经编码过的部分数据进入搜索窗内,而给lab填充还没编码的数据,即”腾出lab的空间“。 现在搜索窗中已经有了一个字符A,但显然在lab中,B、BA、BAC、BACB都与A不匹配;不匹配时的输出和初始状态一样,都是(0,0)c=lab中的第一个字符,这里的输出为(0,0)B。不匹配时,窗口右滑一格,如下图:
现在,搜索窗内的字符串为AB,lab中组合为A、AC、ACB、ACBA,显然lab中的A是可以与搜索窗中左起第一个A匹配的;搜索窗中这个与之匹配的A,距离lab两格;或者说,搜索窗中这个与之匹配的A,是从lab中向左偏移2格得到的;因此D指的是搜索窗中最长匹配字符串左起第一个字符与lab的距离,所以管D叫距离或者偏移量。这里D=2,而最长匹配字符串为A,最长匹配字符串长度L=1,输出为(2,1),窗口右滑L=1格。注意,如果有匹配字符串,则不需要输出c;实际上,有些地方把c称为explicit bytes。现在,你已经掌握了LZ77的编码了,让我们继续:
输出(0,0)C,窗口右滑一格
此时,搜索窗中的BA与lab中的BA匹配,L=2;D是搜索窗中BA的B到lab的距离,D=3,输出(3,2),窗口右滑2格
输出(6,2),右滑2格 输出(5,2),右滑2格 现在新的问题出现了,lab中的C在搜索窗中有两个位置可以匹配,我们取搜索窗最左边的匹配字符串,因此输出(7,1),右滑1格。在有多个等长的最长匹配字符串时,选最左边的匹配字符串,即取更大的D值,是因为在实际代码中,靠左侧的匹配字符串是遍历过程中后找到的,此时直接输出效率更高。
输出(3,1),右滑1格
输出(7,1),右滑1格
lab中已经空了,编码结束 最终的输出为(0,0)A(0,0)B(2,1)(0,0)C(3,2)(6,2)(5,2)(7,1)(3,1)(7,1) 怎么样,是不是很简单?显然,对同一个字符串而言,选取的搜索窗和待编码缓存的大小不同,编码结果也不同 这里有一个小规律,D和L只要有一个为0,另一个必为0。因此,对于没有匹配字符串的情况,实际存储时还可以更简化,用0A就可以代替(0,0)A。但相信大家马上就发现一个问题了,比如本例的第一个编码(0,0)A,即使简化了,使用LZ77还是需要两个字符0A来表示,而这两个字符表示的实际上就是一个字符A,编码反而让需要存储的内容变得更多了!这还不如不编码。而如果(D,L)pairs表示的匹配字符串为单个字符,也就是L=1,也存在同样的问题;比如本例中最后一个字符A使用编码(7,1)表示反而更复杂。因此在更真实的应用场景中,对于L |











【本文地址】
今日新闻 |
推荐新闻 |