0基础快速上手Python网络爬虫(纯干货) |
您所在的位置:网站首页 › 图片爬虫99 › 0基础快速上手Python网络爬虫(纯干货) |
0基础快速上手Python网络爬虫(纯干货)
本文节选自图灵2023年出品的Python“红宝书”:《从0到1:Python即学即用》,该书包含了10个热门项目,而网络爬虫只是其中一个。详情请看:https://zhuanlan.zhihu.com/p/619066219。 互联网就像一张大网,每一个页面就像是网上的一个节点。在这张大网上,存在着各种各样的数据。对于体量比较大的数据,仅仅靠人工一条一条地手动收集显然不太可能。 最好的做法是,可以开发一个自动程序,让它从这张网上不断地抓取数据,然后保存到文件或数据库中以供后面使用。在这个过程中,自动程序就像是一只蜘蛛,而互联网就像蜘蛛爬行的那张网。在实际项目开发中,这个自动抓取的程序也叫做“网络爬虫(Web Crawler)”。 本章将以本书配套网站——绿叶学习网(http://www.lvyestudy.com)作为爬取的对象,来学习如何使用Python来爬取你想要的数据。 提示 在开始网络爬虫、数据分析以及数据可视化的学习之前,请先阅读一下“附录B 数据科学简介”去了解各部分之间的关系,这可以让你学习起来更加顺畅。一、网页基础在学习网络爬虫之前,你必须要对网页有一定的了解,否则后面将无从下手。现在的网页开发也叫做“前端开发”,它最核心的3个技术是HTML、CSS和JavaScript(如图1),三者之间的区别如下。 HTML用于控制网页的结构。CSS用于控制网页的外观。JavaScript控制着网页的行为。 图1 图1做一个网页就像是盖一个房子。盖房子的时候,都是先把结构建好(HTML),然后再给房子装修(CSS),最后再给房子添加一些行为(JavaScript),比如开灯可以把屋子照亮。 学习网络爬虫,最重要是把HTML和CSS这两个学好,而JavaScript只需要简单了解即可。当然,具备一定的前端开发基础会对网络爬虫的学习带来很大的帮助。 1、HTML简介HTML的全称为“Hyper Text Markup Language(超文本标记语言)”,是网页的标准语言。HTML并不是一门编程语言,而是一门描述性的标记语言。 语法: 内容标签符一般都是成对出现的,包含一个开始符号和一个结束符号。结束符号只是在开始符号前面多加上了一个斜杠“/”。当浏览器收到HTML文本后,就会解析里面的标签符,然后把标签符对应的功能表达出来。 对于一个网页来说,它最基本的HTML结构如下。 网页的标题网页的内容 学习HTML,说白了就是学习各种标签。HTML是一门描述性的语言,它是用标签来说话的。举个例子,如果你要在浏览器显示一段文字,就应该使用“段落标签(p)”;如果要在浏览器显示一张图片,就应该使用“图片标签(img)”。针对显示东西的不同,使用的标签也会不同。在HTML中,常用的标签如下表所示。 标签说明div分区(块元素)span分区(行内元素)p段落ul无序列表li列表项h1~h61~6级标题a超链接strong强调(粗体)em强调(斜体)table表格th表头单元格td表身单元格form表单input表单元素2、CSS简介HTML只是定义一个网页的“骨架”,此时网页看起来比较“丑陋”。因此还需要使用CSS来对其进行修饰,使得网页更加美观才行。CSS指的是“Cascading Style Sheet(层叠样式表)”,它是用来控制网页外观的一门技术。 在互联网发展早期,网页都是用HTML来做的,这样的页面可想而知单调成什么样了。为了改造HTML标签的默认外观,使得页面变得更加美观,后来就引入了CSS。 学习网络爬虫,并不需要精通CSS里面的所有技术,但至少要对CSS的各种选择器足够了解才行。那什么是选择器呢?先来看一个简单的网页。 示例: 绿叶学习网 绿叶学习网 绿叶学习网浏览器效果如图2所示。  图2 图2对于上面这个网页,如果只希望将第2个div文本颜色变为红色(如图3所示),该怎么实现呢?我们肯定要通过一种方式来选中第2个div(因为其他的div不能选中),只有选中了才可以为其改变颜色。  图3 图3像上面这种选中你想要的元素的方式,我们称之为“选择器”。所谓的选择器,说白了就是用一种方式把你想要的那个元素选中。只有把它选中了,你才可以为这个元素添加CSS样式。这样去理解,够简单了吧? CSS有很多方式可以把你想要的元素选中,这些不同的方式其实就是不同的选择器。选择器的不同,在于它的选择方式不同,但它们的最终目的都是相同的,那就是把你想要的元素选中,然后才可以定义该元素的CSS样式。 当然,你也有可能用某一种选择器来代替另外一种选择器,这仅仅是选择方式不同罢了,但目的还是一样的。在CSS中,常用的选择器如下表所示。 选择器说明element元素选择器#idid选择器,id名前面必须加上“#”.classclass选择器,class名前面必须加上“.”elementA > elementB子代选择器elementA elementB后代选择器elementA + elementB相邻选择器elementA, elementB, ..., elementN群组选择器3、JavaScript简介JavaScript,也就是通常所说的“JS”。这是一种嵌入到HTML页面中的编程语言,由浏览器一边解释一边执行。单纯只有HTML和CSS的页面,一般只供用户浏览。而JavaScript的出现,使得用户可以与页面进行交互(如定义各种鼠标事件),让网页实现更多绚丽的效果。 拿绿叶学习网来说,二级导航、图片轮播、回顶部等地方都用到了JavaScript,如图4所示。HTML和CSS只是描述性的语言,单纯使用这两个没办法是做出那些特效,而必须使用编程的方式来实现,也就是使用JavaScript。  图4说明 前端开发涉及的内容非常复杂,并非一本书能介绍得完。如果你完全没有Web方面的基础或者基础比较差,请先快速学习一遍本书配套的两个在线教程:①HTML入门(www.lvyestudy.com/html);② CSS入门(www.lvyestudy.com/css)。二、请求网页:Requests库 图4说明 前端开发涉及的内容非常复杂,并非一本书能介绍得完。如果你完全没有Web方面的基础或者基础比较差,请先快速学习一遍本书配套的两个在线教程:①HTML入门(www.lvyestudy.com/html);② CSS入门(www.lvyestudy.com/css)。二、请求网页:Requests库如果想要请求一个网页,有两个经常用到的库:Urllib和Requests。Urllib是Python内置的库,而Requests是第三方库。由于Requests库不仅具备Urllib库的全部功能,而且它的语法更加简单易懂,所以在实际项目开发中,我们更多的是使用Requests库,而不是Urllib库。 Requests是一个第三方库,需要手动去安装。在VSCode终端中输入下面命令,按下Enter键即可安装。 pip install requests1、HTTP请求HTTP常用的请求方式有两种:GET和POST。其中,GET方式是从服务器请求数据,而POST是将数据提交给服务器。在实际项目开发中,对于请求一个网页,大多数情况下使用的是GET方式。 在Requests库中,我们可以使用get()函数来发起一个GET请求,从而获取一个网页的内容。 语法: requests.get(url, params)url是必选参数,它是一个网页的地址。params是可选参数,表示该请求所携带的参数。如果请求的参数放在了URL中,就没必要使用params参数了。对于GET请求来说,它的URL有两种方式:①不带参数的URL;②带参数的URL。 # 方式1:不带参数 requests.get('http://www.lvyestudy.com/search') # 方式2:带参数 requests.get('http://www.lvyestudy.com/search?wd=python')判断一个URL是否带参数,其实非常简单。如果一个URL后面没有带“?”,那么该URL是不带参数的。而如果一个ULR后面带有“?”,就说明该ULR是带参数的。比如http://www.lvyestudy.com/search?wd=python这个地址,它表示URL带的参数是“wd=python”。其中“wd”是参数的名,而“python”是参数的值。 如果一个URL带多个参数,那么参数之间要使用“&”进行连接。比如下面URL带了两个参数:wd=python和ie=utf-8。 http://www.lvyestudy.com/search?wd=python&ie=utf-8示例: import requests url = 'http://www.lvyestudy.com/search?wd=python' res = requests.get(url) print(res) print(type(res))运行结果如下: 对于带参数的URL来说,它有两种不同的方式。下面两种方式是等价的。但在实际项目开发中,更推荐使用方式1,主要是它更加方便简单。 # 方式1 url = 'http://www.lvyestudy.com/search?wd=python' res = requests.get(url) # 方式2 url = 'http://www.lvyestudy.com/search' params = {'wd': 'python'} res = requests.get(url, params=params)requests.get()函数返回的是一个Response对象。该对象有很多属性,常用的如下表所示。 属性说明text获取网页内容(HTML代码)content获取网页字节流url获取请求地址encoding获取编码方式status_code获取状态码headers获取请求头cookies获取Cookies示例:res.text import requests url = 'http://www.lvyestudy.com' res = requests.get(url) print(res.text)运行结果如下: 绿叶学习网-给你初恋般的感觉 ……此处省略大量内容res.text表示获取一个网页的HTML代码,它本质上是一个字符串。网络爬虫都是先获取一个网页的HTML代码,然后再从HTML代码中提取你想要的数据。 示例:res.content import requests url = 'http://www.lvyestudy.com' res = requests.get(url) print(res.content)运行结果如下: b'\n\n……\n\n'res.text获取的是网页对应的字符串,而res.content获取的是网页对应的字节流。你可以使用type()函数来查看一下。 print(type(res.text)) # print(type(res.content)) #示例:将字节流转换为字符串 import requests url = 'http://www.lvyestudy.com' res = requests.get(url) result = res.content.decode('utf-8') print(result)运行结果如下: 绿叶学习网-给你初恋般的感觉 ……此处省略大量内容我们可以使用decode()方法来将字节流转换为字符串。最后,对于res.text和res.content,你需要清楚以下3点。 res.text返回的是“字符串数据”,而res.content返回的是“二进制数据”。获取一个网页的文本数据,有两种方式:①res.text;②res.content.decode('utf-8')。如果使用res.text获取的网页文本数据存在乱码,则应该使用res.content.decode('utf-8')来代替。示例:其他属性 import requests url = 'http://www.lvyestudy.com' res = requests.get(url) print('请求地址:', res.url) print('编码方式:', res.encoding) print('状态码:', res.status_code) print('请求头:', res.headers) print('Cookies:', res.cookies)运行结果如下: 请求地址:http://www.lvyestudy.com/ 编码方式:utf-8 状态码:200 请求头:{'ETag': ''8572-YzjQvDbqL/4amRd8jRcTMLpnfSA'', 'Content-Type': 'text/html; charset=utf-8', 'Accept-Ranges': 'none', 'Vary': 'Accept-Encoding', 'Content-Encoding': 'gzip', 'Date': 'Sat, 17 Jul 2021 09:42:00 GMT', 'Connection': 'keep-alive', 'Transfer-Encoding': 'chunked'} Cookies:get()函数会返回一个Response对象,通过该对象可以获取某个网页非常多的有用信息,包括请求地址、编码方式、状态码、请求头、Cookies等。 2、添加请求头对于很多网站来说,必须在发起请求的时候添加一个请求头,否则网站会限制你的访问。在Requests库中,我们可以在get()函数中使用headers参数来添加一个请求头。 语法: requests.get(url, headers=请求头)示例: import requests url = 'http://www.lvyestudy.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36 Edg/91.0.864.71' } res = requests.get(url, headers=headers) print(res.url)输出结果如下: http://www.lvyestudy.com/请求头代码一般都是又长又臭,那平常是不是每次都要手动输入这么一大段代码呢?肯定没有必要。实际上还有一种快速获取这段代码的方式,只需要以下两步即可。 ① 打开控制台:首先使用Edge浏览器打开网页,这里打开绿叶学习网首页(www.lvyestudy.com)。然后在页面任意地方单击鼠标右键,在弹出菜单中选择【检查】。此时浏览器就会弹出一个控制台,如图5所示。  图5 图5② 获取请求头:在浏览器控制台中单击【网络】选项,接着刷新一下浏览器(记得一定要刷新)。刷新后会显示一个资源列表,单击列表中的“www.lvyestudy.com”,然后在右侧【标头】这一栏可以找到请求头代码,如图6所示。  注意,仅仅把这段代码复制下来是没有用的。由于headers本身是一个字典,所以还需要将英文冒号前后的字符串分别加上引号才行。最终的headers代码如下: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36 Edg/91.0.864.71' }提示 虽然Chrome是最适合开发人员使用的浏览器,但由于网络问题经常无法正常下载或更新版本。因此对于国内开发者来说,更推荐使用Edge浏览器。Edge是微软主推的一款浏览器,主要用于替代IE。它拥有和Chrome一样的标准,功能强大而使用简单。三、提取数据:BeautifulSoup库Requests库获取的是整个网页的数据,本质上是该网页的HTML代码。一般情况下还需要对网页进一步提取数据,此时我们可以使用BeautifulSoup库来实现。 BeautifulSoup是Python的一个HTML(或XML)解析库,使用它可以很方便地从网页中提取想要的内容。由于BeautifulSoup是第三方库,因此需要手动去安装。在VSCode的控制台中输入下面命令,按下Enter键即可安装。 pip install beautifulsoup4语法: from bs4 import BeautifulSoup soup = BeautifulSoup(res.text, 'lxml')BeautifulSoup()函数接收两个参数。第1个参数是使用Requests库获取到的数据,第2个参数表示使用哪一种HTML解析器。 注意 使用pip命令安装的是beautifulsoup4,而不是beautifulsoup。此外考虑到beautifulsoup4库的名字太长,该库的开发者已将库名字简写为bs4。因此在导入时,应该写成from bs4 import BeautifulSoup,而不是from beautifulsoup4 import BeautifulSoup。常用的HTML解析器如下表所示。BeautifulSoup官方推荐使用“lxml”作为HTML解析器,因为它的速度更快、容错能力更强。由于lxml也是第三方库,需要手动安装才能使用。在VSCode中执行这条命令即可:pip install lxml。 解析器说明html.parser标准库,不过只支持Python2lxml第三方库xml第三方库html5lib最好的容错性,以浏览器的方式解析文档,生成HTML5格式的文档此外需要清楚的是,BeautifulSoup库是配合Requests库来实现的:Requests库用于获取完整数据,BeautifulSoup库用于进一步提取数据。 BeautifulSoup()函数会返回一个BeautifulSoup对象,该对象有3组常用的方法:①prettify();②select();③find_all()和find()。下面来详细介绍。 1、 prettify()方法在BeautifulSoup库中,我们可以使用BeautifulSoup对象的prettify()方法来按标准的缩进格式输出内容。 语法: soup.prettify()示例: import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } res = requests.get('http://www.lvyestudy.com', headers=headers) soup = BeautifulSoup(res.text,'lxml') print(soup.prettify())运行结果如下: 绿叶学习网-给你初恋般的感觉 ……此处省略大量内容你可能会感到困惑:“这里的输出结果怎么和res.text是一样呢?使用prettify()方法不是多此一举吗?”其实不然。如果网页源代码本身格式是乱的,那么使用prettify()方法可以使其代码美化(包括缩进、对齐等),从而变成阅读体验更好的格式。 2、select()方法在BeautifulSoup库中,我们可以使用BeautifulSoup对象的select()方法来选择HTML元素。 语法: soup.select('选择器')select()方法接收一个CSS选择器作为参数。如果想要快速获取网页中某一个元素对应的CSS选择器,只需要以下简单的3步即可。 ① 打开网页:首先使用Edge浏览器打开网页,这里打开绿叶学习网首页(www.lvyestudy.com),如图7所示。  图7 图7② 打开控制台:将鼠标移到你想要获取数据的元素上方,接着单击鼠标右键,在弹出的菜单中选择【检查】,就会打开浏览器控制台,如图8所示。  图8 图8③ 复制selector:在浏览器控制台中,找到对应的HTML元素并选中它,然后单击鼠标右键,依次选择【复制】→【复制selector】,如图9所示。 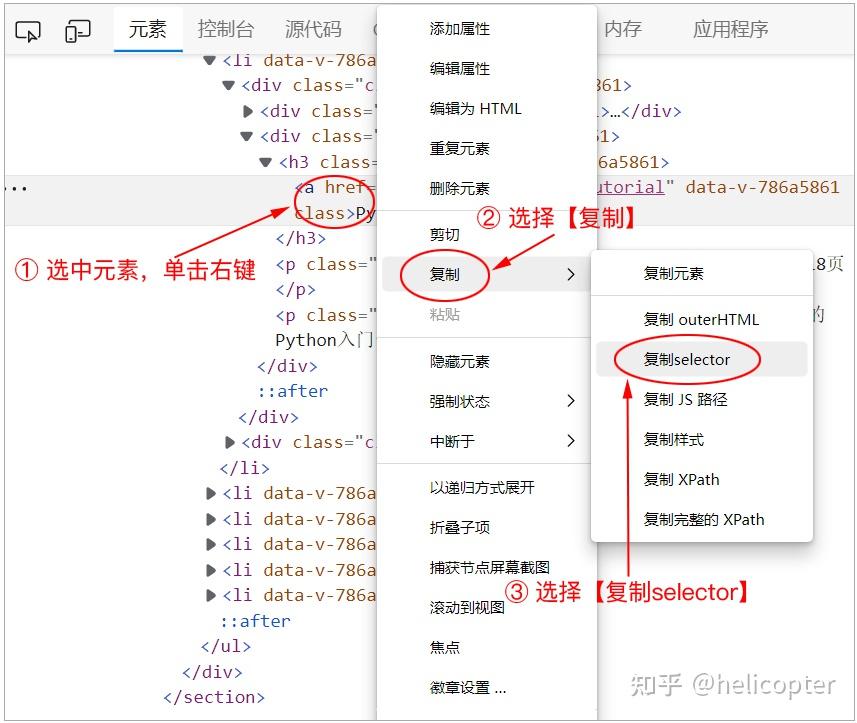 图9 图9最后把复制到粘贴板的内容粘贴出来,就可以得到该元素对应的CSS选择器了,如下所示。 #book > div > ul > li:nth-child(1) > div:nth-child(1) > div.right > h3 > a需要特别说明的是,你应该使用上面步骤来获取CSS选择器,而不是直接照抄书中代码。这是因为大多数网站都会改版升级,所使用的CSS选择器或文本内容可能会改变。 示例:获取第一本书的名字 import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } res = requests.get('http://www.lvyestudy.com', headers=headers) soup = BeautifulSoup(res.text, 'lxml') name = soup.select('#book>div>ul>li:nth-child(1)>div:nth-child(1)>div.right>h3>a') print(name) print(type(name))运行结果如下: [Python快速上手]soup.select()返回的并不是一个列表,而是一个bs4.element.ResultSet类型的数据。该类型数据与列表类似,因此可以使用下标的方式来获取元素。比如这里可以使用name[0]来获取第1个元素。 如果你足够细心,可能也已经发现了,这里提取的结果其实是把标签名也包含进去了。实际上,预期想要获取的是不包含标签的书名,也就是“Python快速上手”这个文本。我们可以使用get_text()方法来获取标签内的文本内容,将print(name)改为print(name[0].get_text()),再次运行后结果如下: Python快速上手上面示例获取的是第一本书的名字,如果想要获取所有图书的名字,又应该怎么做呢?只需要稍微修改一下CSS选择器就可以了,也就是将li:nth-child(1)改为li。修改后的CSS选择器如下: #book > div > ul > li > div:nth-child(1) > div.right > h3 > a为什么将li:nth-child(1)改为li,这样就可以获取所有图书的名字了呢?这就涉及到CSS选择器的使用了。上面的选择器又长又臭,如果你对CSS语法比较熟悉,完全可以自己编写更简洁的选择器。比如要获取所有图书的名字,CSS选择器可以使用更简单的表示方式:.book-name>a。 之前也反复强调,学习网络爬虫必须要有一定的前端开发基础。所以请尽量先把HTML和CSS学会再来学习网络爬虫,否则在学习过程中会比较吃力。 示例:获取所有图书的名字 import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } res = requests.get('http://www.lvyestudy.com', headers=headers) soup = BeautifulSoup(res.text, 'lxml') # 获取图书名字 names = soup.select('#book>div>ul>li>div:nth-child(1)>div.right>h3>a') for name in names: print(name.get_text())运行结果如下: Python快速上手 Python数据分析 Python数据可视化 ES6快速上手 HTML+CSS+JavaScript快速上手(视频版) HTML+CSS快速上手(视频版)soup.select()返回的结果是一个可迭代对象,因此可以使用for循环来输出所有的内容。如果想要将所有图书名字保存到一个列表中去,可以使用列表推导式来实现。将“获取图书名字”这部分的代码修改如下: names = soup.select('#book>div>ul>li>div:nth-child(1)>div.right>h3>a') names = [name.get_text() for name in names] print(names)再次运行后,其结果如下: ['Python快速上手', 'Python数据分析', 'Python数据可视化', 'ES6快速上手', 'HTML+CSS+JavaScript快速上手(视频版)', 'HTML+CSS快速上手(视频版)']四、提取数据:Lxml库想要进一步提取数据,除了使用Beautiful Soup库,还可以使用Lxml库来实现。Lxml是第三方库,前面我们已经安装过了。Lxml本身是一个用于解析XML的库,不过它同样也可以很好地解析HTML,因此可以使用它来提取数据。 语法: from lxml import etree html = etree.HTML(res.text) elements = html.xpath('元素的XPath')首先使用from lxml import etree导入Lxml库中的etree模块,然后使用etree模块的HTML()函数将Requests库获取到的数据(即res.text)转换为HTML节点树,最后再使用HTML节点树的xpath()方法来获取你想要的HTML元素。 xpath()方法接收一个XPath作为参数。如何才能快速地获取到某一个元素对应的XPath呢?其实这个跟获取元素的CSS选择器差不多,只需要以下简单的3步即可。 ① 打开网页:首先使用Edge浏览器打开网页,这里打开绿叶学习网首页(http://www.lvyestudy.com),如图10所示。 图10② 打开控制台:将鼠标移到你想要获取数据的元素上面,接着单击鼠标右键,在弹出的菜单中选择【检查】,就会打开浏览器控制台,如图11所示。 图11③ 复制XPath:在浏览器控制台中,找到对应的HTML元素并选中它,然后单击鼠标右键,依次选择【复制】→【复制XPath】,如图12所示。  图12 图12最后把复制到粘贴板的内容粘贴出来,就可以得到该元素对应的XPath了,如下所示。 //*[@id='content']/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]Lxml库的XPath跟BeautifulSoup库的selector的用法十分相似,你可以多多对比一下,这样更能加深理解和记忆。 示例:获取第一本书的名字 import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } res = requests.get('http://www.lvyestudy.com', headers=headers) html = etree.HTML(res.text) name = html.xpath('//*[@id='book']/div/ul/li[1]/div[1]/div[2]/h3/a') print(name)运行结果如下: []html.xpath()返回的也是一个列表,如果想要获取节点内的文本,我们可以在XPath字符串最后加上“/text()”,修改后的代码如下: name = html.xpath('//*[@id='book']/div/ul/li[1]/div[1]/div[2]/h3/a/text()')再次运行程序,其结果如下: ['Python快速上手']上面示例获取的只是第一本书的名字,如果想要获取所有图书的名字,只需要把“li[1]”改为“li”就可以了,修改后的代码如下: name = html.xpath('//*[@id='book']/div/ul/li/div[1]/div[2]/h3/a/text()')再次运行程序,其结果如下: ['Python快速上手', 'Python数据分析', 'Python数据可视化', 'ES6快速上手', 'HTML+CSS+JavaScript快速上手(视频版)', 'HTML+CSS快速上手(视频版)']最后来总结一下,使用网络爬虫来爬取想要的数据,步骤其实非常简单。首先使用Requests库来请求网页,然后使用BeautifulSoup或Lxml库来提取数据,最后再将数据保存到文件或数据库中即可,如图13所示。  图13注意:不要用正则表达式来解析HTML。在一个字符串中定位特定的一段HTML,这似乎很适合使用正则表达式。但是,我建议你不要这样做。因为HTML的格式有很多不同的方式,并且仍然被认为是有效的HTML,比如和都是可行的。尝试使用正则表达式来捕捉所有这些可能的变化将变得非常繁琐,并且容易出错。而使用专门用于解析HTML的模块(如BeautifulSoup),则不容易导致bug。五、项目:爬取豆瓣top 250电影 图13注意:不要用正则表达式来解析HTML。在一个字符串中定位特定的一段HTML,这似乎很适合使用正则表达式。但是,我建议你不要这样做。因为HTML的格式有很多不同的方式,并且仍然被认为是有效的HTML,比如和都是可行的。尝试使用正则表达式来捕捉所有这些可能的变化将变得非常繁琐,并且容易出错。而使用专门用于解析HTML的模块(如BeautifulSoup),则不容易导致bug。五、项目:爬取豆瓣top 250电影到此为止,你已经具备了一定的爬虫基础。接下来将使用本章的技术来爬取豆瓣top 250的电影信息(如图14所示),包括名字、评分、图片地址,其地址为:https://movie.douban.com/top250。  图14 图14在开发之前先整理一下项目目录,当前项目目录包含一个空的文件夹result,用于保存结果。整个项目结构如图15所示。  图15 图15接下来我们通过之前介绍的方法来获取电影名称、评分及图片地址这3部分对应的CSS选择器,分别如下所示。 # 名称 #content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1) # 评分 #content > div > div.article > ol > li:nth-child(1) > div > div.info > div.bd > div > span.rating_num # 图片地址 #content > div > div.article > ol > li:nth-child(1) > div > div.pic > a > img上面获取的是第一个电影的名称、评分及图片地址,如果想要获取当前页面所有电影的名称、评分及图片地址,需要将所有CSS选择器中的li:nth-child(1)改为li,修改后的CSS选择器如下。 # 名称 #content > div > div.article > ol > li > div > div.info > div.hd > a > span:nth-child(1) # 评分 #content > div > div.article > ol > li > div > div.info > div.bd > div > span.rating_num # 图片地址 #content > div > div.article > ol > li > div > div.pic > a > img示例:爬取第一页 import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } res = requests.get('https://movie.douban.com/top250', headers=headers) soup = BeautifulSoup(res.text, 'lxml') # 获取名称 names = soup.select('#content>div>div.article>ol>li>div>div.info>div.hd>a>span:nth-child(1)') names = [name.get_text() for name in names] # 获取评分 scores = soup.select('#content>div>div.article>ol>li>div>div.info>div.bd>div>span.rating_num') scores = [score.get_text() for score in scores] # 获取图片地址 pics = soup.select('#content>div>div.article>ol>li>div>div.pic>a>img') pics = [pic.get('src') for pic in pics] # 创建一个空列表,用于保存结果 result = [] for i in range(len(names)): movie = {} movie['name'] = names[i] movie['score'] = scores[i] movie['pic'] = pics[i] result.append(movie) print(result)运行结果如下(由于内容过多,只展示开头和结尾): [{'name': '肖申克的救赎', 'score': '9.7', 'pic': 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg'}, ……, {'name': '怦然心动', 'score': '9.1', 'pic': 'https://img1.doubanio.com/view/photo/s_ratio_poster/public/p501177648.jpg'}]特别注意,获取图片的地址,应该获取它的src属性值。所以这里不能使用get_text()方法,而应该使用get()方法。其中get('src')表示获取当前元素src属性的值。 实际上,上面示例只是获取了第1页电影的信息,只有前25个电影。如果想要获取所有页的电影信息,此时应该怎么做呢?先来分析一下页面的URL,豆瓣电影Top250共10个页面,每个页面的URL如下: 第1页:https://movie.douban.com/top250。第2页:https://movie.douban.com/top250?start=25&filter=。第3页:https://movie.douban.com/top250?start=50&filter=。第4页:https://movie.douban.com/top250?start=75&filter=。……第10页:https://movie.douban.com/top250?start=225&filter=。从上面可以看出,除了第1页的URL比较特殊之外,其他所有页面的URL都是有规律的。第n页的URL可以表示如下: https://movie.douban.com/top250?start={25 *(n-1)}&filter=示例:爬取所有页 import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } # 定义函数,获取某一个URL中所有的电影信息 def crawler(url): res = requests.get(url, headers=headers) soup = BeautifulSoup(res.text, 'lxml') # 获取名称 names = soup.select('#content>div>div.article>ol>li>div>div.info>div.hd>a>span:nth-child(1)') names = [name.get_text() for name in names] # 获取评分 scores = soup.select('#content>div>div.article>ol>li>div>div.info>div.bd>div>span.rating_num') scores = [score.get_text() for score in scores] # 获取图片地址 pics = soup.select('#content>div>div.article>ol>li>div>div.pic>a>img') pics = [pic.get('src') for pic in pics] # 创建一个空列表,用于保存结果 result = [] for i in range(len(names)): movie = {} movie['name'] = names[i] movie['score'] = scores[i] movie['pic'] = pics[i] movies.append(movie) return result if __name__ == '__main__': # 构建所有页面的URL,保存到列表urls中去 urls = ['https://movie.douban.com/top250'] for n in range(2, 11): url = f'https://movie.douban.com/top250?start={25*(n-1)}&filter=' urls.append(url) # 定义一个空列表,用于保存结果 movies = [] # 获取所有页的电影信息 for url in urls: # 获取当前URL的电影信息 info = crawler(url) # 拼接所有列表 movies.extend(info) # 输出结果 print(movies)运行结果如下(由于内容过多,只展示开头和结尾): [{'name': '肖申克的救赎', 'score': '9.7', 'pic': 'https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg'}, ……, {'name': '完 美陌生人', 'score': '8.5', 'pic': 'https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2522331945.jpg'}]上面示例其实是将爬虫功能封装成了一个模块,该模块包含了一个名为crawler()的函数,该函数的功能是用于获取某一个URL的电影信息。在模块的if __name__=='__main__':部分,我们尝试获取所有URL的电影信息。 网络爬虫爬取的数据量往往比较大,使用print()函数打印并不利于查看,最好的办法是将其保存到一个文件中去。接下来尝试将爬取的数据保存成一个CSV文件,修改后的if __name__=='__main__':代码如下。注意别忘了使用 # 导入模块(别忘了这一步) import csv if __name__ == '__main__': # 构建所有页面的URL,保存到列表urls中去 urls = ['https://movie.douban.com/top250'] for n in range(2, 11): url = f'https://movie.douban.com/top250?start={25*(n-1)}&filter=' urls.append(url) # 定义一个空列表,用于保存结果 movies = [] # 获取所有页的电影信息 for url in urls: # 获取当前URL的电影信息 info = crawler(url) # 拼接所有列表 movies.extend(info) # 处理成二维列表 result = [['name', 'score', 'pic']] for item in movies: temp = [] temp.append(item['name']) temp.append(item['score']) temp.append(item['pic']) result.append(temp) # 写入CSV文件 file = open(r'result\movies.csv', 'a', encoding='utf-8', newline='') writer = csv.writer(file) for item in result: writer.writerow(item) file.close()再次运行之后,会发现了当前目录中增加了一个movies.csv文件,如图16所示。该文件保存的就是所有电影对应的CSV数据。  图16 图16可能你以为到现在就结束了,但想要成为一名真正的爬虫工程师,又怎能满足于此呢?我们再来思考一个问题:“上面爬取的是图片地址,既然图片地址都获取到了,是否可以把这些图片下载到本地呢?”答案是肯定的。 实现思路很简单,只需要对上面爬取的结果进行遍历,从而获取每一张图片的地址。通过requests.get()函数结合content属性可以获取图片的字节流(二进制数据),然后使用文件对象的write()方法写入到本地即可。这里在上面if __name__ == '__main__':代码的后面继续编写代码,其实现代码如下。 if __name__ == '__main__': # ……此处省略前面的代码 # 下载图片 for index, item in enumerate(result): # 排除第一行,因为第一行是列名 if index != 0: # 请求图片 res_img = requests.get(item[2]) # 打开文件 file = open(f'result\\{index}.{item[0]}.jpg', 'wb') # 写入图片 file.write(res_img.content) file.close()考虑到图片比较多,下载速度比较慢,这里可以将if index!=0:修改为if index!=0 and index图17思考 对于本章项目,如果使用XPath来代替CSS选择器,又该如何实现呢? 相信小伙伴们看完本文已经大呼过瘾了,实际上本文节选自图灵2023年出品的Python“红宝书”:《从0到1:Python即学即用》。该书包含了10个热门项目,而网络爬虫只是其中一个。“红宝书”的详细内容介绍可以查看:https://zhuanlan.zhihu.com/p/619066219。 该书绝对够“渣”,实际上我就是这本“渣书”的作者。。开个玩笑,小伙伴们有什么多多批评就是,后面我争取完善到最好哈。
|
【本文地址】
今日新闻 |
推荐新闻 |