基于深度学习的图像去模糊(两篇经典的文献阅读笔记) |
您所在的位置:网站首页 › 图像恢复的范畴包括 › 基于深度学习的图像去模糊(两篇经典的文献阅读笔记) |
基于深度学习的图像去模糊(两篇经典的文献阅读笔记)
|
基于神经网络的动态场景图像去模糊
参考文献:2017 CVPR Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring 原文链接:https://arxiv.org/pdf/1612.02177.pdf 基于深度学习的方法和传统的优化的方法都提出了对于图像的非均匀模糊问题进行了解决,但对于动态场景的模糊问题,也就是图像中只有局部区域存在模糊的问题难以解决。2017年,Seungjun等人总结现有的图像去模糊算法中存在的问题为: 1) 难以获得实测清晰图像和模糊图像对用于训练图像去模糊网络; 2) 对于动态场景的图像去模糊问题,难以获得局部图像的模糊核; 3) 去模糊问题需要较大的感受野。 针对上述提出的问题,作者提出了一种实测动态场景图像合成的方式,并公开了用于动态场景的图像去模糊数据集gopro_large, gopro数据集已经成为目前基于深度学习的去模糊算法最常用的数据集之一 。而针对难以获得动态场景的局部区域的模糊核问题,作者选择一种基于深度学习的端到端的图像去模糊的算法,抛弃了传统的方法先估计模糊核在估计清晰图像的策略,使用卷积神经网络从退化图像中直接复原清晰图像。并且仿照 传统的图像去模糊问题中多尺度的复原策略融入到网络中,网络设计如图1所示。 参考文献:2018CVPR DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks 原文链接:https://arxiv.org/pdf/1711.07064.pdf Gan为对抗生成网络,首次在文献Generative Adversarial Nets中被提出,应用于图像生成。随着Gan的发展逐步应用于图像复原领域。该文献提出将Gan应用于图像去模糊问题上。实现了一种基于深度学习的端到端的图像去模糊。提出的Gan的生成器网络模型如图3所示。生成器由两个步长为1/2的卷积网络、9个ResBlock和两个反卷积网络组成。每个ResBlock包括卷积层、instance normalization层和ReLU激活层。 Gan网络结构设计部分与cGan类似,如图4所示。在训练阶段,损失函数包括两个部分 L = L G A N ⎵ a d v l o s s + λ ⋅ L X ⎵ c o n t e n t l o s s ⎵ t o t a l l o s s \mathcal { L } = \underbrace { \underbrace { \mathcal { L } _ { G A N } } _ { adv loss } + \underbrace { \lambda \cdot \mathcal { L } _ { X } } _ { content loss } } _ {total loss } L=totalloss advloss LGAN+contentloss λ⋅LX 其中 L G A N \mathcal { L } _ { G A N } LGAN为对抗损失,采用WGAN-GP中提出的所示函数 L G A N = ∑ n = 1 N − D θ D ( G θ G ( I B ) ) \mathcal { L } _ { G A N } = \sum _ { n = 1 } ^ { N } - D _ { \theta _ { D } } \left( G _ { \theta _ { G } } \left( I ^ { B } \right) \right) LGAN=∑n=1N−DθD(GθG(IB)) 内容损失采用perceptual loss L X = 1 W i , j H i , j ∑ x = 1 W i , j ∑ y = 1 H i , j ( ϕ i , j ( I S ) x , y − ϕ i , j ( G θ G ( I B ) ) x , y ) 2 \mathcal { L } _ { X } = \frac { 1 } { W _ { i , j } H _ { i , j } } \sum _ { x = 1 } ^ { W _ { i , j } } \sum _ { y = 1 } ^ { H _ { i , j } } \left( \phi _ { i , j } \left( I ^ { S } \right) _ { x , y } - \phi _ { i , j } \left( G _ { \theta _ { G } } \left( I ^ { B } \right) \right) _ { x , y } \right) ^ { 2 } LX=Wi,jHi,j1∑x=1Wi,j∑y=1Hi,j(ϕi,j(IS)x,y−ϕi,j(GθG(IB))x,y)2. Perceptual loss采用在ImageNet上训练好的VGG19的VGG3,3的激活层。 此外,DelurGan使用一种新的评价指标,采用YOLO检测结果的来评估图像复原的好坏。 |
 图1 网络结构图 作者通过三个多尺度的卷积神经网络,其中B1为待复原图像,分别降采样两次为B2 B3,将降采样的结果分别输入到网络中得到相应分辨率尺寸下复原结果,并将复原结果作为下一阶段的输入,从而知道后续的复原。这种多尺度的策略,类似于传统的模糊核估计中的由粗到细的策略,将复杂的问题进行分解,逐步复原,先在低分辨率下复原大尺度的信息,然后再高分辨率下复原细节信息。简化问题的同时增大了图像的感受野。 与文献Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal对比的实验结果如图2所示。在视觉上提出的方法取得更好的视觉效果。在数据集GOPRO上的测试指标如表1所示,并对比了方法间,在不同的网络尺度数下的实验结果。
图1 网络结构图 作者通过三个多尺度的卷积神经网络,其中B1为待复原图像,分别降采样两次为B2 B3,将降采样的结果分别输入到网络中得到相应分辨率尺寸下复原结果,并将复原结果作为下一阶段的输入,从而知道后续的复原。这种多尺度的策略,类似于传统的模糊核估计中的由粗到细的策略,将复杂的问题进行分解,逐步复原,先在低分辨率下复原大尺度的信息,然后再高分辨率下复原细节信息。简化问题的同时增大了图像的感受野。 与文献Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal对比的实验结果如图2所示。在视觉上提出的方法取得更好的视觉效果。在数据集GOPRO上的测试指标如表1所示,并对比了方法间,在不同的网络尺度数下的实验结果。  图2 视觉上对比实验结果 表1 在GOPRO测试集上的实验结果对比(方法间与文献[10]进行对比,方法内对比不同尺度数K对比)
图2 视觉上对比实验结果 表1 在GOPRO测试集上的实验结果对比(方法间与文献[10]进行对比,方法内对比不同尺度数K对比) 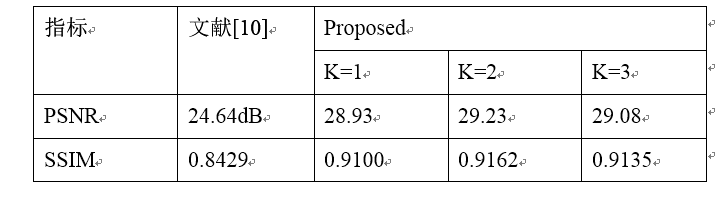 指标 文献Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal Proposed K=1 K=2 K=3 PSNR 24.64dB 28.93 29.23 29.08 SSIM 0.8429 0.9100 0.9162 0.9135
指标 文献Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal Proposed K=1 K=2 K=3 PSNR 24.64dB 28.93 29.23 29.08 SSIM 0.8429 0.9100 0.9162 0.9135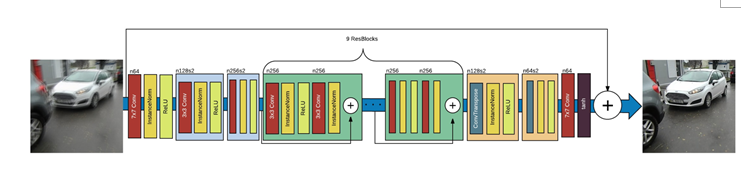 图3 生成器网络结构图
图3 生成器网络结构图 图4 DeblurGan网络结构示意图
图4 DeblurGan网络结构示意图【本文地址】
今日新闻 |
推荐新闻 |