k最近邻算法 |
您所在的位置:网站首页 › 喜剧片的分类包括 › k最近邻算法 |
k最近邻算法
|
文章目录
一、k最近邻算法的原理二、k最近邻算法过程详解三、kNN算法的注意事项1. k值的选取2. 距离的度量(1)欧氏距离(2)曼哈顿距离(3)切比雪夫距离
3. 特征归一化
四、k最近邻算法案例分享1. 电影分类kNN算法实战
五、kNN算法优缺点
一、k最近邻算法的原理
kNN算法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN算法的核心思想 :如果一个数据在特征空间中最相邻的k个数据中的大多数属于某一个类别,则该样本也属于这个类别(类似投票),并具有这个类别上样本的特性。通俗地说,对于给定的测试样本和基于某种度量距离的方式,通过最靠近的k个训练样本来预测当前样本的分类结果。 kNN算法就是根据距离待分类样本A最近的k个样本数据的分类来预测A可能属于的类别,基本的计算步骤如下: 存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。计算待分类数据与训练集中每一个样本之间的距离。找出与待分类样本距离最近的k个样本。观测这k个样本的分类情况。把出现次数最多的类别作为待分类数据的类别 二、k最近邻算法过程详解举个简单的例子,我们可以使用k最近邻算法分类一个电影是爱情片还是动作片。我们以接吻次数和打斗次数来区分是爱情电影还是动作电影。我们已有的数据集,这个数据集有两个特征,即打斗镜头数和接吻镜头数。除此之外,我们也知道每个电影的所属类型,即分类标签,现在要预测电影5是属于哪个类型的电影(爱情片或动作片),如表3-1所示。
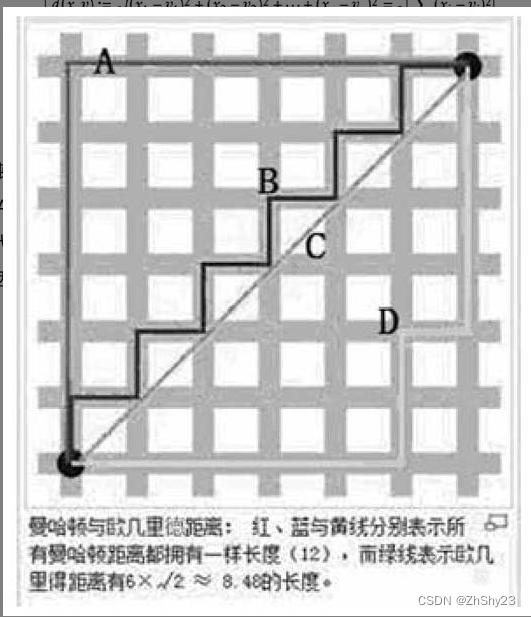
k最近邻算法的步骤描述如下: 计算已知类别数据集中的点与当前测试点之间的距离。按照距离递增次序排序。选取与当前测试点距离最小的k个点。确定前k个点所在类别的出现频率。返回前k个点所出现频率最高的类别作为当前测试点的预测分类。关于这里的距离度量,这个电影分类的例子有2个特征,也就是2维的,可以使用我们高中学过的两点距离公式(两点距离公式其实就是欧氏距离在二维空间上的公式,也就是欧氏距离n的值为2的情况,欧氏距离也称为欧几里德距离)来计算距离,如图3-3所示。 欧式距离其实就是应用勾股定理计算两个点的直线距离。二维空间的公式,如图3-4所示,P为点(x2,y2)与点(x1,y1)之间的欧氏距离,|x|为点(x2,y2)到原点的欧式距离。 曼哈顿距离就是表示两个点在标准坐标系上的绝对轴距之和。如图3-6所示,折线A代表曼哈顿距离,线段C代表欧氏距离,也就是直线距离,而折现B和折现D代表等价的曼哈顿距离。曼哈顿距离就是两个点在南北方向上的距离加上在东西方向上的距离,即 d ( i , j ) = ∣ x i − x j ∣ + ∣ y i − y j ∣ d(i,j)=|x_i-x_j|+|y_i-y_j| d(i,j)=∣xi−xj∣+∣yi−yj∣。
切比雪夫距离得名自俄罗斯数学家切比雪夫。如图3-7所示,若将国际象棋棋盘放在二维直角坐标系中,格子的边长定义为1,坐标的x轴及y轴和棋盘方格平行,原点恰落在某一格的中心点,则王从一个位置走到其他位置需要的步数恰为二个位置的切比雪夫距离,因此切比雪夫距离也称为棋盘距离。例如位置f6和位置e2的切比雪夫距离为4。任何一个不在棋盘边缘的位置,和周围八个位置的切比雪夫距离都是1。 k最近邻算法(kNN),这个最近邻的定义是通过距离函数来定义的,我们最常用的是欧式距离。为了保证每个特征同等重要性,我们这里对每个特征进行归一化。对数据进行归一化,避免量纲对计算距离的影响。 举例如下,我们用一个人身高(cm)与脚码(尺码)大小来作为特征值,类别为男性或者女性。如果现在有5个训练样本,分布如下: A [(179,42),男] B [(178,43),男] C [(165,36)女] D [(177,42),男] E [(160,35),女]很容易看到第一维身高特征是第二维脚码特征的4倍左右,那么在进行距离度量的时候,我们就会偏向于第一维特征。这样会造成两个特征并不是等价重要的,最终可能会导致距离计算错误,从而导致预测错误。举例如下: 现在给出一个测试样本F(167,43),让我们来预测一下他是男性还是女性,我们采取k=3来预测。
这样问题就来了,一个女性的脚43码的可能性,远远小于男性脚43码的可能性,那么为什么算法还是会预测F为女性呢?那是因为由于各个特征量纲的不同,在这里导致了身高的重要性已经远远大于脚码了,这是不客观的。所以我们应该让每个特征都具有同等的重要性!这也是我们要归一化的原因! 四、k最近邻算法案例分享 1. 电影分类kNN算法实战一个电影分类演示例子(电影名称与分类来自于优酷网;镜头数量则纯属虚构),为已知的电影分类,分为喜剧片、动作片、爱情片三个种类,使用的特征值分别为搞笑镜头、打斗镜头、拥抱镜头的数量。那么来了一部新电影《唐人街探案》,用kNN算法猜测它属于上述3个电影分类中的哪个类型? kNN算法分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(Label),也就是该数据所属的分类。首先我们构建一个已分好类的数据集,如图3-9所示,这里的新样本就是:“唐人街探案”: [23,3,17, “?片”]。
** python 代码 如下:** import math # 数据集 movie_data = {"宝贝当家": [45, 2, 9, "喜剧片"], "美人鱼": [21, 17, 5, "喜剧片"], "澳门风云3": [54, 9, 11, "喜剧片"], "功夫熊猫3": [39, 0, 31, "喜剧片"], "谍影重重": [5, 2, 57, "动作片"], "叶问3": [3, 2, 65, "动作片"], "伦敦陷落": [2, 3, 55, "动作片"], "我的特工爷爷": [6, 4, 21, "动作片"], "奔爱": [7, 46, 4, "爱情片"], "夜孔雀": [9, 39, 8, "爱情片"], "代理情人": [9, 38, 2, "爱情片"], "新步步惊心": [8, 34, 17, "爱情片"]} # 测试样本 x = [23, 3, 17] KNN = [] for key, v in movie_data.items(): d = math.sqrt((x[0]-v[0])**2 + (x[1]-v[1])**2 + (x[2]-v[2])**2) KNN.append([key, round(d, 2)]) print("=======================所有电影到测试样本的距离=========================") print(KNN) # 距离递增排序 KNN.sort(key=lambda dis: dis[1]) # 选取距离最小的5个样本 KNN = KNN[:5] print("========================距离最小的5个样本========================") print(KNN) # 确定前k个样本所在类别出现的频率,并输出出现频率最高的类别 labels = {"喜剧片": 0, "动作片": 0, "爱情片": 0} for s in KNN: label = movie_data[s[0]] labels[label[3]] += 1 labels = sorted(labels.items(), key=lambda l: l[1], reverse=True) print(labels, labels[0][0], sep='\n')结果
|
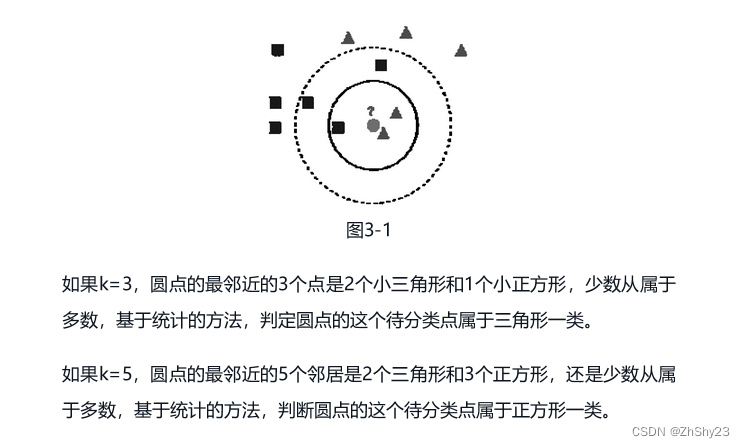 简单来说,kNN可以看成: 有那么一堆你已经知道分类的数据,当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的k个点看看这几个点属于什么类型,最后用少数服从多数的原则,给新数据归类。
简单来说,kNN可以看成: 有那么一堆你已经知道分类的数据,当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的k个点看看这几个点属于什么类型,最后用少数服从多数的原则,给新数据归类。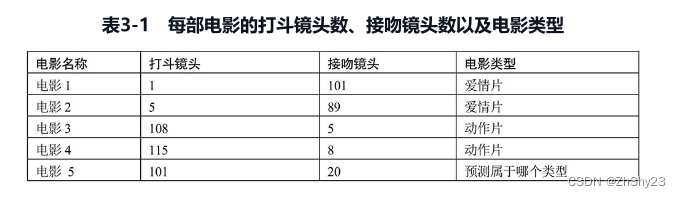 用经验法则粗略地观察:接吻镜头多的是爱情片;而打斗镜头多的是动作片。如果现在给我一部电影,你告诉我这个电影打斗镜头数和接吻镜头数,不告诉我这个电影类型,我可以根据你给我的信息,按经验法则来判断这个电影是属于爱情片还是动作片。而k最近邻算法也可以像我们人一样做到这一点,但k最邻近算法是靠已有的数据来预测的。比如,你告诉我这个电影打斗镜头数为101,接吻镜头数为20,k最近邻算法会提取样本集中特征最相似数据(最邻近)的分类标签,得到的结果取决于数据集的大小以及最近邻的判断标准因素。
用经验法则粗略地观察:接吻镜头多的是爱情片;而打斗镜头多的是动作片。如果现在给我一部电影,你告诉我这个电影打斗镜头数和接吻镜头数,不告诉我这个电影类型,我可以根据你给我的信息,按经验法则来判断这个电影是属于爱情片还是动作片。而k最近邻算法也可以像我们人一样做到这一点,但k最邻近算法是靠已有的数据来预测的。比如,你告诉我这个电影打斗镜头数为101,接吻镜头数为20,k最近邻算法会提取样本集中特征最相似数据(最邻近)的分类标签,得到的结果取决于数据集的大小以及最近邻的判断标准因素。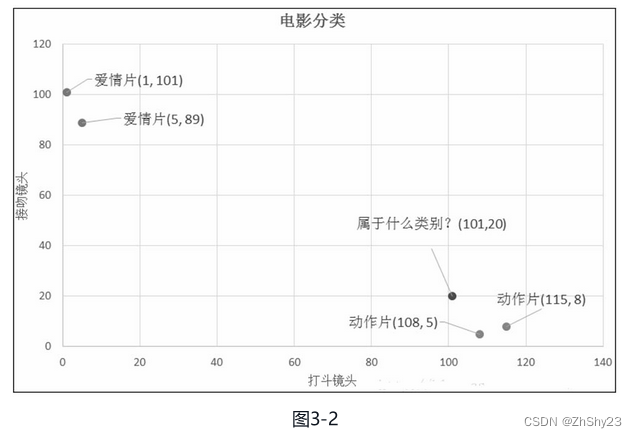 我们可以从散点图大致推断,这个坐标为(101, 20)的圆点标记的电影可能属于动作片,因为距离已知的那两个动作片的圆点更近。
我们可以从散点图大致推断,这个坐标为(101, 20)的圆点标记的电影可能属于动作片,因为距离已知的那两个动作片的圆点更近。 这样我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到k个距离最近的电影。假定k=3,则三个最靠近的电影分别是动作片电影3(108,5)、动作片电影4(115,8)、爱情片电影2(5,89)。在这三个点中,动作片出现的频率为三分之二,爱情片出现的频率为三分之一,所以坐标为(101, 20)的圆点标记的电影类型为动作片。这个判别过程就是k最近邻算法。
这样我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到k个距离最近的电影。假定k=3,则三个最靠近的电影分别是动作片电影3(108,5)、动作片电影4(115,8)、爱情片电影2(5,89)。在这三个点中,动作片出现的频率为三分之二,爱情片出现的频率为三分之一,所以坐标为(101, 20)的圆点标记的电影类型为动作片。这个判别过程就是k最近邻算法。 同理,N维空间的公式,如图3-5所示。
同理,N维空间的公式,如图3-5所示。 
 对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离,因此,曼哈顿距离又称为出租车距离。
对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离,因此,曼哈顿距离又称为出租车距离。 国际象棋棋盘上2个位置间的切比雪夫距离是指王要从一个位置移至另一个位置需要走的步数。由于王可以往斜前或斜后方向移动一格,因此可以较有效率地到达目的格子。
国际象棋棋盘上2个位置间的切比雪夫距离是指王要从一个位置移至另一个位置需要走的步数。由于王可以往斜前或斜后方向移动一格,因此可以较有效率地到达目的格子。 由计算可以得到,最近的前三个分别是C、D、E三个样本,那么由C、E为女性,D为男性,女性多于男性得到我们要预测的结果为女性。
由计算可以得到,最近的前三个分别是C、D、E三个样本,那么由C、E为女性,D为男性,女性多于男性得到我们要预测的结果为女性。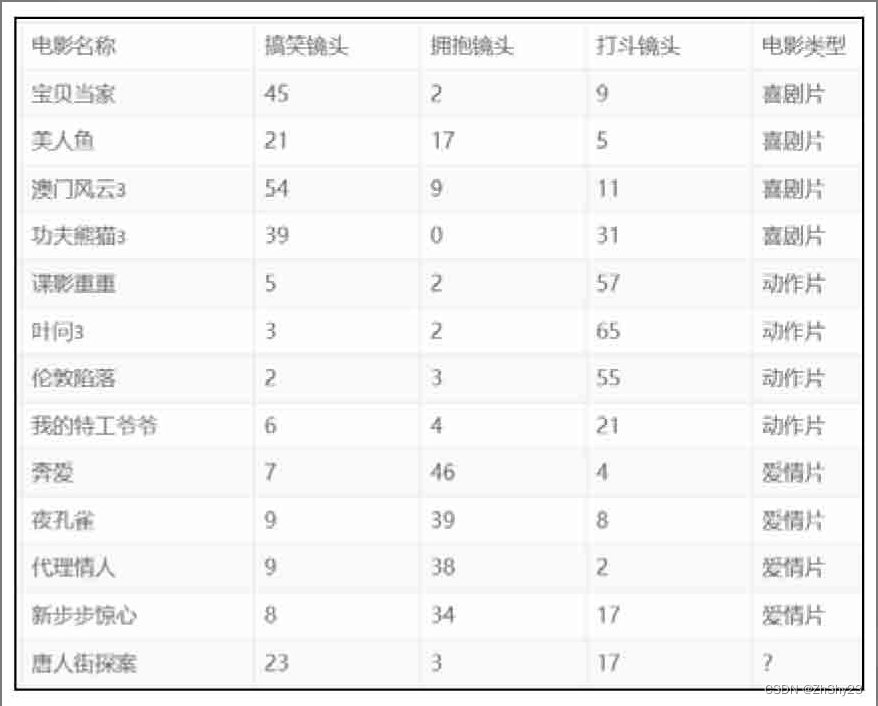
 这里采用了欧式距离的计算方式, 如测试样本为[23,3,17],我的特工爷爷为[6,4,21],则距离为
(
23
−
6
)
2
+
(
3
−
4
)
2
+
(
17
−
21
)
2
=
17.49
\sqrt{(23-6)^2+(3-4)^2+(17-21)^2}=17.49
(23−6)2+(3−4)2+(17−21)2
=17.49
这里采用了欧式距离的计算方式, 如测试样本为[23,3,17],我的特工爷爷为[6,4,21],则距离为
(
23
−
6
)
2
+
(
3
−
4
)
2
+
(
17
−
21
)
2
=
17.49
\sqrt{(23-6)^2+(3-4)^2+(17-21)^2}=17.49
(23−6)2+(3−4)2+(17−21)2
=17.49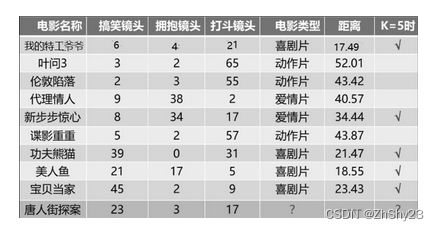
【本文地址】
今日新闻 |
推荐新闻 |