一种基于混合三维残差门控循环单元的唇语识别方法 |
您所在的位置:网站首页 › 唇语识别模型有哪些 › 一种基于混合三维残差门控循环单元的唇语识别方法 |
一种基于混合三维残差门控循环单元的唇语识别方法
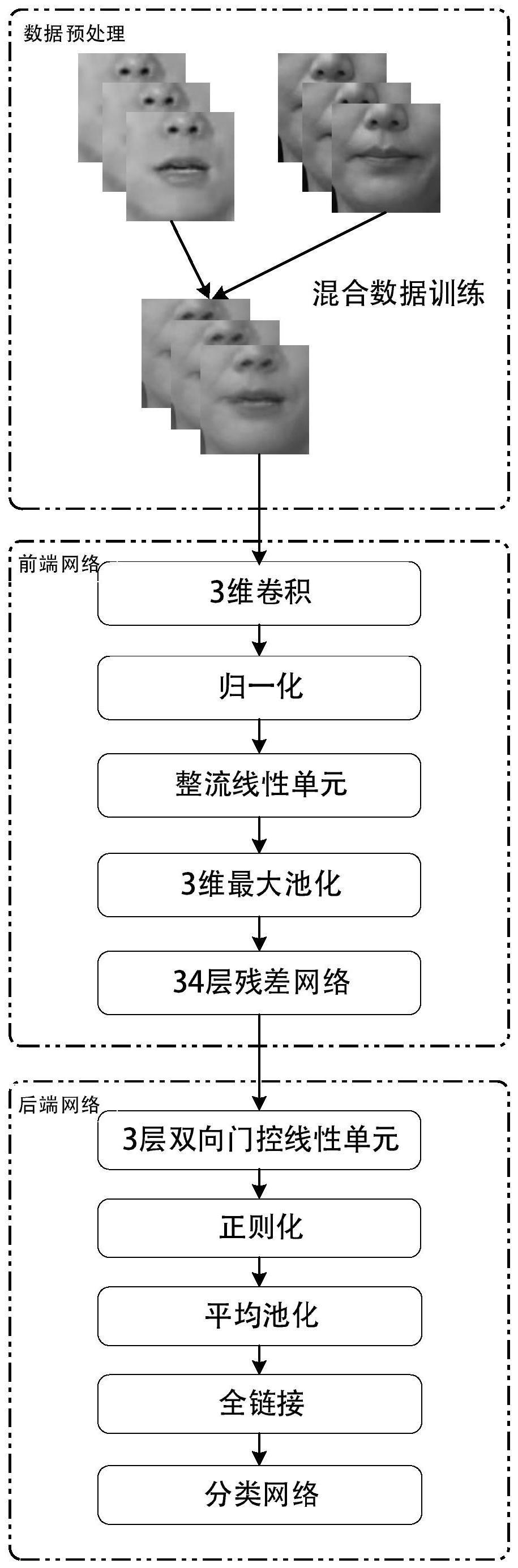 本发明属于唇语识别,涉及一种基于混合三维残差门控循环单元的唇语识别方法。 背景技术: 1、语音是如今日常生活中至关重要的一种交流方式,人们通过语音来表达他们的思想、情感和意见,以交流信息和相互理解。深度学习是一种基于神经网络的机器学习方法,随着计算机硬件技术的发展和数据量的增加,深度学习在各种应用领域中得到了广泛应用。但是,深度学习仍然面临着优化算法和模型结构的挑战。语音识别作为自然语言处理技术的一个重要分支,在实际应用中面临着一些挑战。最大的挑战之一是环境噪声和语音间混叠的影响,使得输入信号有严重的变形和干扰,导致语音识别的准确率下降。此外,声音的语速、口音、语气等不同因素也会影响语音识别的效果。同时,口齿不清、发音错误等语音缺陷也会造成巨大的影响。 2、唇语识别是一种能够解决语音识别中噪声问题的技术。唇语信号在无法获取语音信号或语音信号受到严重干扰的情况下,仍可提供有效的语音信息,其识别精度也能够与语音识别相当,并且具有较高的鲁棒性。唇语识别可以利用视频设备捕捉人类唇部运动信息,并利用模型对其进行分析,从而实现语音的识别和转写。在配合人类语音和声音的同时,唇语可以提供额外的视觉信息来减轻它们的识别难度,为语音识别技术的进一步发展提供更多的可能性。由于残疾人无法发声,他们可能无法利用传统的语音识别技术进行交流。在这种情况下,唇语识别技术可以通过分析人类唇部运动信息,并将其转换为语音信息,来帮助残疾人进行有效的交流。因此,唇语识别技术对于提高残疾人迅捷有效地沟通具有重要的帮助作用。 3、传统唇语识别模型的数据扩增方法包括旋转、缩放、水平翻转等方式,但限于因数据分布不均衡等问题,效果有限。为了提高模型的鲁棒性和泛化能力,采用混合数据训练技术进行样本扩增,并将每个样本进行线性组合生成新的混合样本,增加数据多样性和唇语视频数据集的规模,使得神经网络训练出来的特征更具代表性。采用融合残差与时空卷积网络可以很好地提取唇语视频中的静态和动态信息,使得模型能够更加准确地分辨不同的唇语动作。同时,使用时空残差块和自适应注意力机制来建模视频中短期和长期的时间依赖特征,以有效地处理非常长的时间序列。序列信息门控网络作为后端网络,在唇语视频中捕获长期依赖的时序关系上表现较好,进而提升识别精度和鲁棒性。此外,还运用了局部稀疏连接的解码器,这种解码器方法可有效地降低模型参数和算力消耗,实现了模型的轻量化、高效化和易于部署,同时在保持高精度的情况下,降低了模型的算力消耗,提高了唇语识别的实用性。 技术实现思路 1、有鉴于此,本发明的目的在于提供一种基于混合三维残差门控循环单元的唇语识别方法。 2、为达到上述目的,本发明提供如下技术方案: 3、一种基于混合三维残差门控循环单元的唇语识别方法,包括以下步骤: 4、s1:以唇部图像特征序列为对象,设计混合数据训练,对数据进行增强; 5、s2:以采用融合残差和时空卷积的网络作为前端网络,以产生序列的最终表示; 6、s3:构建基于序列信息门控网络的后端网络,对唇语进行识别。 7、进一步,所述步骤s1具体包括: 8、s11:基于多个面部标志,将数据集中的唇部图像先进行人脸对齐,裁剪图像并将它们调整为固定大小; 9、s12:使用每个地标的中值坐标,将常见的裁剪应用于给定剪辑的所有帧; 10、s13:帧被转换为灰度,并根据整体均值和方差进行归一化后得到唇部区域; 11、s14:最后使用混合数据训练进行数据增强。 12、进一步,步骤s1中,假设batchx1是一个batch样本,batchy1是该batch样本对应的标签;batchx2是另外一个batch样本,batchy2是该batch样本对应的标签,λ是由参数α,β的贝塔分布计算出来的混合系数,混合数据训练原理公式为: 13、λ=beta(α,β) 14、mixed_batchx=λ*batchx1+(1-λ)*batchx2 15、mixed_batchy=λ*batchy1+(1-λ)*batchy2 16、其中beta指的是贝塔分布,mixed_batchx是混合后的batch样本,mixed_batchy是混合后的batch样本对应的标签; 17、当batch size=1时,表示两张图片样本混合;当batch size>1时,表示两个batch图片样本两两对应混合。 18、进一步,所述前端网络具体包括: 19、第一层:用于将时空卷积应用于预处理的帧流并且捕获嘴部区域的短期动态;第一层由一个卷积层组成,具有64个3维内核,还包括批量归一化和整流线性单元;提取的特征图通过时空最大池化层; 20、第二层:3维特征图在每个时间步通过一个残差网络,使用34层身份映射版本;它的构建块由两个卷积层和bn和relu组成,而跳过连接促进信息传播;resnet使用最大池化层逐步下降空间维度,直到其输出在每个时间步成为一维张量; 21、原始的残差块中的计算为: 22、yl=h(xl)+f(xl,wl) 23、xl+1=f(yl) 24、其中xl是第1个残差单元的输入特征,wl={wl,k|1≤k≤k}是第l个残差单元相关的一组权重,k是残差单元中的层数,f表示残差函数,函数f是逐元素加法后的操作,也就是relu激活函数,函数的集合作为恒等映射: 25、h(xl)=xl xl+1=yl 26、从而得到函数: 27、xl+1=xl+f(xl,wl) 28、经过递归得到: 29、 30、任意深层单元的特征xl表示为浅层单元xl的特征加上形如的残差函数,表明任意单元l与l之间都具有残差特性,对于任意一个l层的深度网络: 31、 32、最后一层的输出特征xl是x0加上中间层残差函数的结果,将网络的损失函数表示为ε,根据链式法则有: 33、 34、进一步,所述后端网络具体包括: 35、时空卷积层的输出是由卷积神经网络和光流算法提取出的时空特征;所述时空特征中包含视频数据中的空间和时间信息;所述时空特征作为残差网络输入,传递给序列信息门控网络进行时间序列的语义建模和学习,从而完成对视频中语音信号的识别; 36、序列信息门控网络在时间t的激活是前一个激活和候选激活之间的线性插值: 37、 38、其中更新门决定单元更新其激活或内容的程度,更新门由下式计算: 39、 40、这个过程是把现有的状态和新计算的状态之间取线性总和,但没有采取任何机制去控制其状态暴露程度,而每次将所有状态都暴露,候选激活的计算方法: 41、 42、其中rt是一组重置门,并且⊙是逐元素乘法,当关闭时,重置门使单元充当读取输入序列的第一个符号,使其能够忘记先前计算的状态;重置门的计算类似于更新门: 43、 44、在后端,对序列信息门控网络在时间维度上的输出进行平均,并将结果发送到最终的全连接层进行预测,交叉熵损失用于优化。 45、本发明的有益效果在于:从模型算法角度出发,本发明的唇语识别模型完整结合了融合残差和时空卷积的网络和序列信息门控网络,前端网络能够利用三维卷积神经网络提取唇语视频中的静态和动态特征,并通过深度残差结构来解决一般二维网络中梯度消失的问题。而后端网络则是基于序列信息门控网络,能够很好地处理唇语视频中的时序信息,从而进一步提高唇语识别的准确性和鲁棒性。本前后端结合的模型成功地解决了唇语识别中常见的唇形相似性高、数据量少的难题,在实验中取得了较好的效果。该模型对唇读障碍人群的实际应用领域有着广泛而实用的意义。 46、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。 |
【本文地址】
今日新闻 |
推荐新闻 |