哈希原理与常见哈希函数 |
您所在的位置:网站首页 › 哈希表的定义和工作原理图片 › 哈希原理与常见哈希函数 |
哈希原理与常见哈希函数
|
一,什么是哈希
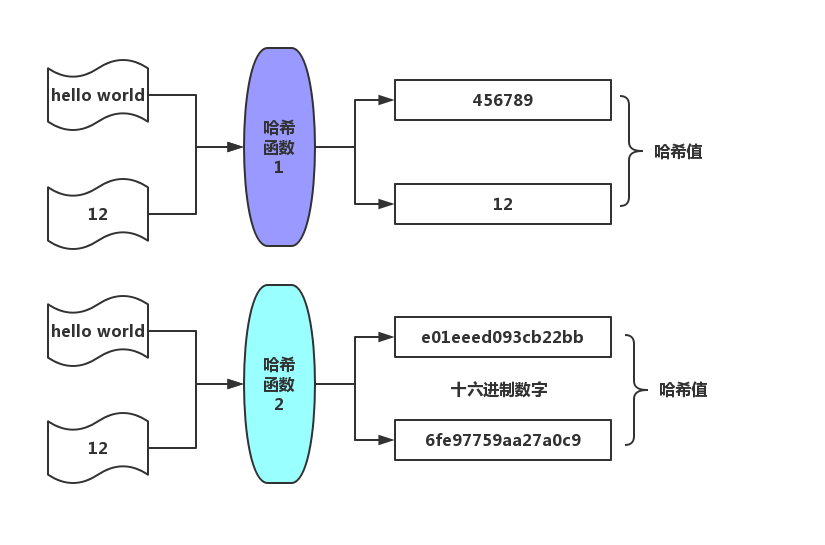
哈希是将任意长度的数据转换为一个数字的过程。这个数字是在一个固定的范围之内的。 转换的方法称为哈希函数,原值经过哈希函数计算后得到的值称为哈希值。
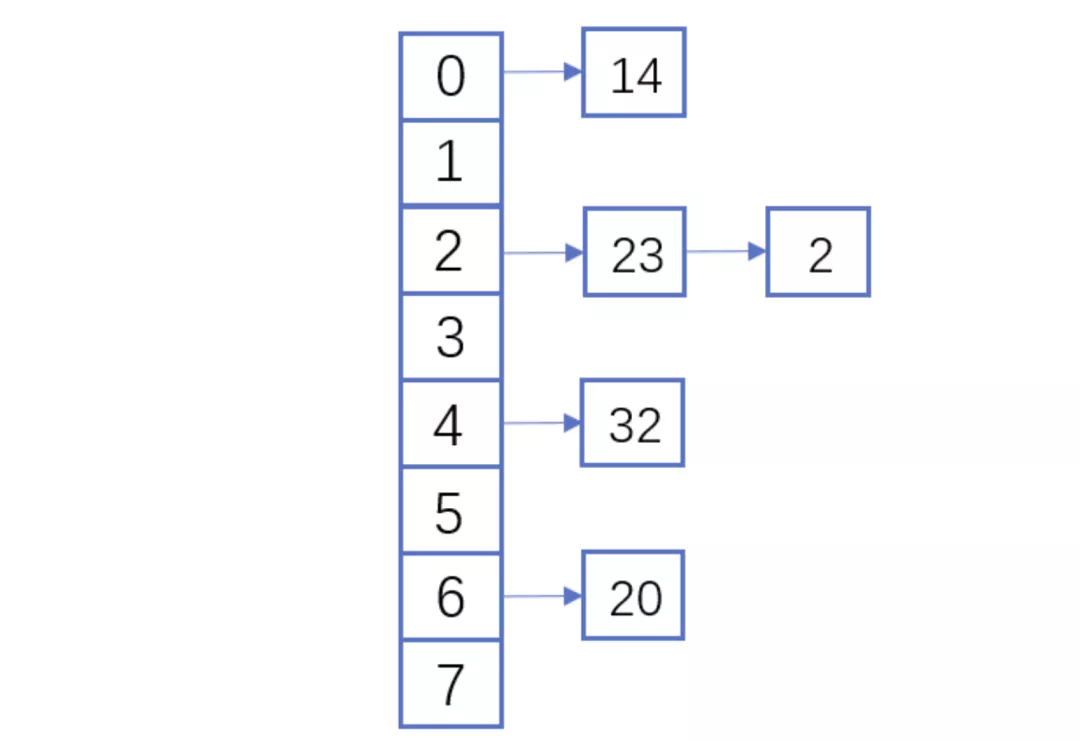
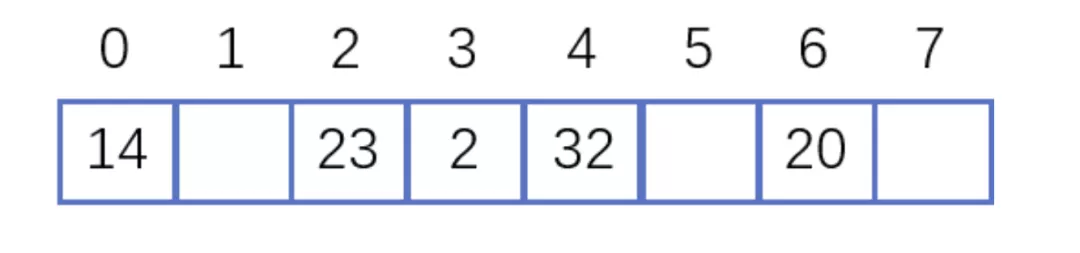
(1)一致性:同一个值每次经过同一个哈希函数计算后得到的哈希值是一致的。 F(x)=rand() :每次返回一个随机值,是不好的哈希(2)散列性:不同的值的哈希值尽量不同,理想情况下每个值对应于不同的数字。 F(x)=1 : 不管输入什么都返回1,是不好的哈希 2.冲突怎么解决把一个大的集合映射到一个固定大小的集合中,肯定是存在冲突的。这个是抽屉原理或者叫鸽巢理论。 桌上有十个苹果,要把这十个苹果放到九个抽屉里,无论怎样放,我们会发现至少会有一个抽屉里面放不少于两个苹果。这一现象就是我们所说的“抽屉原理”。 抽屉原理的一般含义为:“如果每个抽屉代表一个集合,每一个苹果就可以代表一个元素,假如有n+1个元素放到n个集合中去,其中必定有一个集合里至少有两个元素。” 抽屉原理有时也被称为鸽巢原理。它是组合数学中一个重要的原理。 (1)拉链法: 链表地址法是使用一个链表数组来存储相应数据,当hash遇到冲突的时候依次添加到链表的后面进行处理。Java里的HashMap是拉链法解决冲突的典型应用场景。
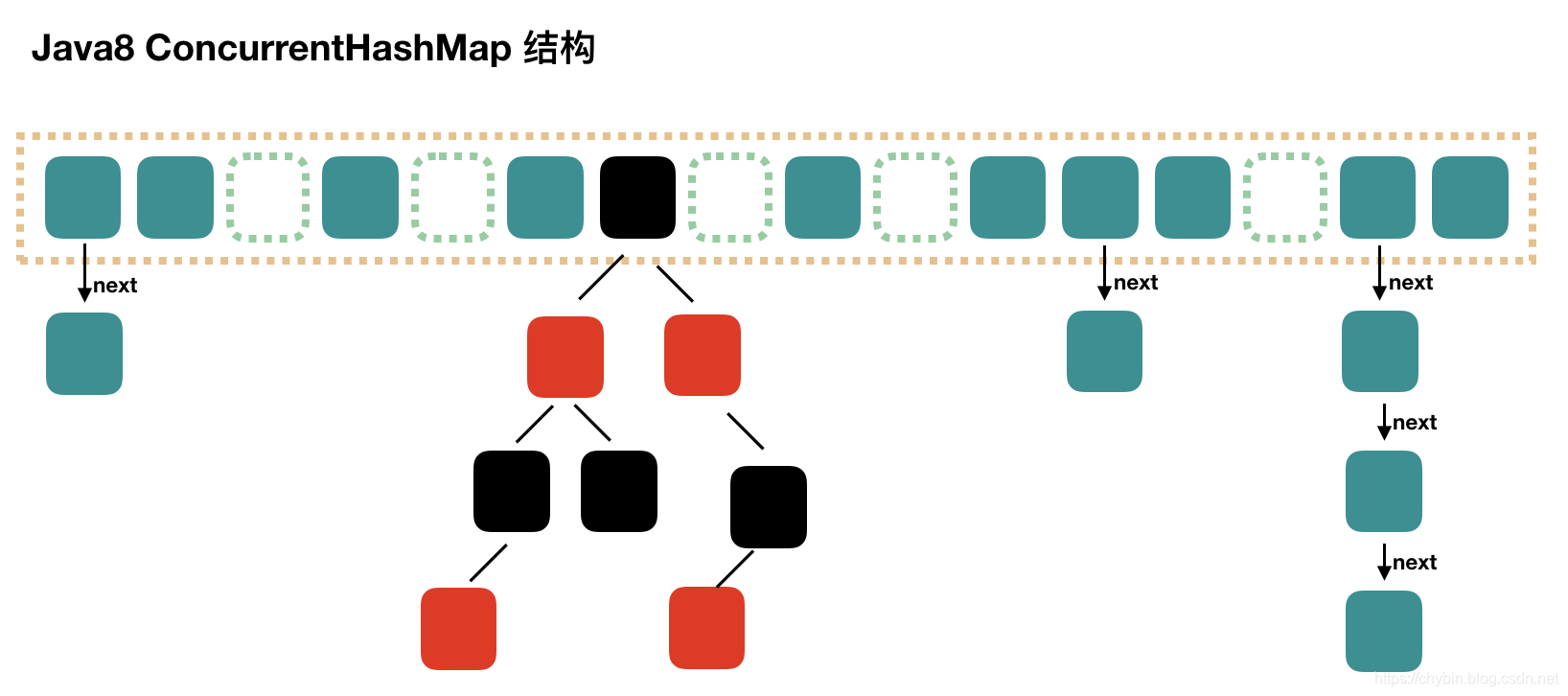
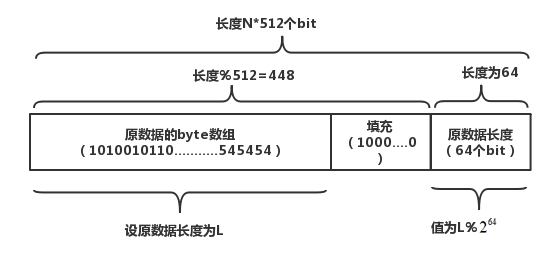
Java8的HashMap中,使用一个链表数组来存储数据,根据元素的哈希值确定存储的数组索引位置,当冲突时,就链接到元素后面形成一个链表,Java8中当链表长度超过8的时候就变成红黑树以优化性能,红黑树也可以视为拉链法的一种变形。 (2)开放地址法 开放地址法是指大小为 M 的数组保存 N 个键值对,其中 M >N。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为“开放地址”哈希表。 线性探测法,就是比较常用的一种“开放地址”哈希表的一种实现方式。线性探测法的核心思想是当冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。简单来说就是:一旦发生冲突,就去寻找下 一个空的散列表地址,只要散列表足够大,空的散列地址总能找到。 Java8中的HashTable就是用线性探测法来解决冲突的。 public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry entry = (Entry)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null; } private void addEntry(int hash, K key, V value, int index) { modCount++; Entry tab[] = table; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; hash = key.hashCode(); index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. @SuppressWarnings("unchecked") Entry e = (Entry) tab[index]; tab[index] = new Entry(hash, key, value, e); count++; }(2)冲突解决示例 举个例子,假如散列长度为8,哈希函数是:y=x%7。两种解决冲突的方式如下: 拉链法解决冲突 线性探测法解决冲突 MD5哈希算法是将任意字符散列到一个长度为128位的Bit数组中,得出的结果表示为一个32位的十六进制数字。 MD5哈希算法有以下几个特点: 正像快速:原始数据可以快速计算出哈希值逆向困难:通过哈希值基本不可能推导出原始数据输入敏感:原始数据只要有一点变动,得到的哈希值差别很大冲突避免:很难找到不同的原始数据得到相同的哈希值算法过程: 数据填充:将原数据的二进制值进行补齐。 (1)填充数据:使得长度模除512后得到448,留出64个bit来存储原信息的长度。填充规则是填充一个1,后面全部是0。 (2)填充长度数据:计算原数据的长度数据,填充到最后的64个bit上,如果消息长度数据大于64bit就使用低64位的数据。
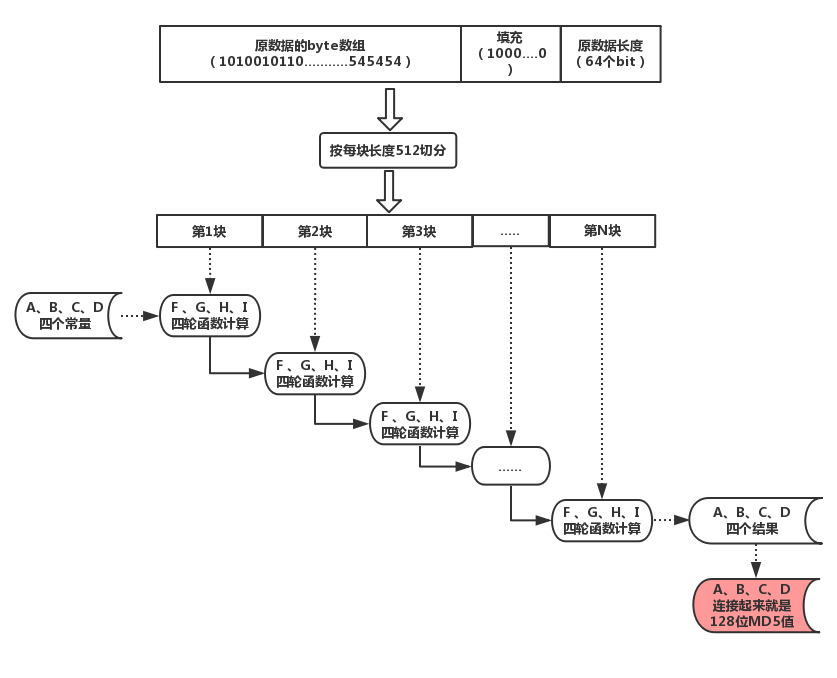
将填充好的数据按照每份512的长度进行切分,对每一份依次进行处理,每份的处理方式是使用四个函数进行依次进行计算,每个函数都有四个输入参数,输出也是四个数字,输出的数字作为下一份数据的输入,所有份数的数据处理完毕,得到的四个数字连接起来就是最终的MD5值。 以下图片是整个迭代计算的过程示意图,其中四个初始参数和四个函数定义如下: //四个初始参数值 A=0x67452301; B=0xefcdab89; C=0x98badcfe; D=0x10325476; //四个函数的定义 // a、b、c、d是每次计算时候的四个参数 F=(b&c)|((~b)&d); F=(d&b)|((~d)&c); F=b^c^d; F=c^(b|(~d));
|
【本文地址】
今日新闻 |
推荐新闻 |