机器学习20:嵌入 |
您所在的位置:网站首页 › 向量空间有什么意义 › 机器学习20:嵌入 |
机器学习20:嵌入
|
协同过滤 是基于大量其他用户的兴趣来预测目标用户的兴趣的方法之一。在本节,我们以协同过滤算法为例,来看一下电影推荐的实现。假设我们有 500,000 个用户,以及这些用户观看过的电影列表(来自 1,000,000 部电影的目录)。我们的目标是向用户推荐电影。 为了解决这个问题,需要某种方法来确定哪些电影彼此相似。我们可以通过将电影嵌入到一个低维空间中来实现这一目标,如此一来,相似的电影在这个“空间”中应该是邻近的。 在描述如何学习嵌入之前,我们首先探讨我们希望嵌入具有的质量类型,以及如何表示用于学习嵌入的训练数据。 1.1 在一维数轴上排列电影为了更好地理解嵌入的含义,如下表所示,我们尝试在一张纸上将以下电影排列在一维数轴上,以便彼此最接近(最相似)的电影具有最密切的相关性: 电影评分描述布鲁R一名法国寡妇在丈夫和女儿因车祸去世后悲痛不已。黑暗骑士崛起PG-13在这部以 DC 漫画宇宙为背景的《黑暗骑士》续集中,蝙蝠侠致力于拯救哥谭市免遭核毁灭 。哈利·波特与魔法石PG一名孤儿发现自己是一名巫师,并就读于霍格沃茨魔法学校,在那里他与邪恶的伏地魔展开了第一次战斗。超人总动员PG一个超级英雄家庭被迫在郊区过着平民生活,他们从退休生活中恢复过来,以拯救超级英雄种族免受综合症和他的杀手机器人的侵害。怪物史莱克PG一个可爱的食人魔和他的驴伙伴出发执行营救被龙囚禁在城堡里的菲奥娜公主的任务。星球大战PG卢克·天行者和汉·索罗与两个机器人联手营救莱娅公主并拯救银河系。贝尔维尔的三胞胎PG-13当职业自行车手冠军在环法自行车赛期间被绑架时,他的祖母和超重的狗在三位老年爵士歌手的帮助下远赴海外营救他。纪念R一名失忆症患者迫切希望通过在身上纹上线索来侦破妻子的谋杀案。 如图 1 所示,虽然这种嵌入确实有助于了解电影针对儿童和成人的程度,但人们在提出推荐时还需要了解电影的更多方面。让我们更进一步地了解这个示例,添加第二个嵌入维度。 图 1. 可能的一维排列
1.2 在二维空间中排列电影 图 1. 可能的一维排列
1.2 在二维空间中排列电影
如图 2 所示,我们尝试将相同的电影排列在二维空间中。
通过这种二维嵌入,我们定义了电影之间的距离,如果电影在面向儿童与成人的程度以及面向成人的程度方面相似,那么电影就在附近(因此推断为相似)。它们是大片与艺术电影。当然,这些只是电影的众多重要特征中的两个。 更一般地说,我们所做的是将这些电影映射到 嵌入空间 中,其中每部电影都由一组二维坐标来描述。例如,在此空间中,“Shrek” 映射到 (-1.0, 0.95),“Bleu” 映射到 (0.65, -0.2)。一般来说,在学习 d 维嵌入时,每部电影都由 d 个实数值表示,每个实数值给出一维的坐标。 在此示例中,我们为每个维度指定了名称。学习嵌入时,各个维度不是通过名称来学习的。有时,我们可以查看嵌入并为维度分配语义,但有时则不能。通常,每个这样的维度称为 潜在维度,因为它代表数据中不明确的特征,而是从中推断出来的特征。 最终,有意义的是 嵌入空间 中电影之间的距离,而不是单个电影沿任何给定维度的值。 2.嵌入:分类输入数据分类数据是指代表有限选择集中的一个或多个离散项目的输入特征。例如,它可以是用户观看过的一组电影、文档中的一组单词或一个人的职业。 分类数据通过稀疏张量来有效地表示,稀疏张量是具有很少非零元素的张量。例如,如果我们正在构建电影推荐模型,我们可以为每个可能的电影分配一个唯一的 ID,然后用每个用户观看过的电影的稀疏张量来表示,如图 3 所示。
图 3.我们的电影推荐问题的数据 图 3 中矩阵的每一行都是捕获用户观看电影历史记录的示例,并表示为稀疏张量,因为每个用户仅观看所有可能电影的一小部分。最后一行对应于稀疏张量 [1, 3, 999999],使用电影图标上方显示的词汇索引。 同样,我们可以将单词、句子和文档表示为稀疏向量,其中词汇表中的每个单词扮演的角色类似于我们推荐示例中的电影。 为了在机器学习系统中使用这种 表示,我们需要一种方法将每个稀疏向量表示为数字向量,以便语义相似的项目(电影或单词)在向量空间中具有相似的距离。但是如何将单词表示为数字向量呢? 最简单的方法是定义一个巨大的输入层,其中包含词汇表中每个单词的节点,或者至少为数据中出现的每个单词一个节点。如果数据中出现 500,000 个唯一单词,您可以表示一个长度为 500,000 向量的单词,并将每个单词分配给向量中的一个槽。 如果将 “horse” 分配给索引 1247,那么要将 “horse” 输入到网络中,就可以将 1 复制到第 1247 个输入节点,将 0 复制到所有其余输入节点。这种表示形式称为 one-hot 编码(在【机器学习8:特征组合-Feature Crosses】中有介绍),因为只有一个索引具有非零值。 更常见的是,您的向量可能包含较大文本块中的单词计数。这被称为 “词袋” 表示。在词袋向量中,500,000 个节点中的几个节点将具有非零值。 但是,无论我们如何确定非零值,每个单词一个节点都会提供非常 稀疏的 输入向量——即具有相对较少非零值的非常大的向量。稀疏表示存在一些问题,这些问题可能导致模型难以有效学习。 2.1 网络规模巨大的输入向量意味着神经网络的权重数量巨大。如果您的词汇表中有 M 个单词,并且输入上方网络的第一层中有 N 个节点,则您有 MxN 权重来训练该层。大量的权重会导致进一步的问题: 数据量。模型中的权重越多,有效训练所需的数据就越多。 计算量。权重越多,训练和使用模型所需的计算量就越多。很容易超出硬件的能力。 2.2 向量之间缺乏有意义的关系如果将 RGB 通道的像素值输入图像分类器,那么讨论 “接近” 值就有意义了。无论是在语义上还是在向量之间的几何距离方面,红蓝色都接近纯蓝色。但是,索引 1247 处为 1 的 “马” 向量与索引 50,430 处为 1 的 “羚羊” 向量并不比索引 238 处为 1 的 “电视” 向量更接近。 2.3 解决方案:嵌入这些问题的解决方案是使用嵌入,它将大型稀疏向量转换为保留语义关系的低维空间。我们将在本模块的以下部分中直观地、概念性地和编程地探索嵌入。 3.嵌入:转换到低维空间在实践中,我们可以通过将高维数据映射到低维空间来解决稀疏输入数据的核心问题。即使是一个小的多维空间也可以自由地将语义相似的项目组合在一起,并将不相似的项目分开。向量空间中的位置(距离和方向)可以在良好的嵌入中编码语义。例如,以下真实嵌入的可视化显示了捕获语义关系(例如国家与其首都之间的关系)的几何关系:
这种有意义的空间使您的机器学习系统有机会检测可能有助于学习任务的模式。 3.1 缩小网络规模虽然我们需要足够的维度来编码丰富的语义关系,但我们还需要一个足够小的嵌入空间,以便我们能够更快地训练我们的系统。有用的嵌入可能是数百个维度的量级,不过,相较于自然语言处理,这里的词汇量小几个数量级。 4.嵌入:获取嵌入获得嵌入的方法有很多种,包括 Google 创建的最先进的算法。 4.1 标准降维技术有许多现有的数学技术可以在低维空间中捕获高维空间的重要结构。理论上,任何这些技术都可以用来创建机器学习系统的嵌入。例如,主成分分析(PCA)已被用来创建词嵌入。给定一组实例(例如词袋向量),PCA 尝试找到可以折叠为单个维度的高度相关的维度。 4.2 Word2vecWord2vec 是 Google 发明的一种用于训练词嵌入的算法。Word2vec 依赖分布假设将语义相似的单词映射到几何上接近的嵌入向量。 分布假设指出,经常具有相同相邻单词的单词往往在语义上相似。“狗”和“猫”经常与“兽医”一词接近,这一事实反映了它们的语义相似性。正如语言学家约翰·弗斯 (John Firth) 在 1957 年所说的那样,“你应该通过它所拥有的同伴来认识一个单词”。 Word2Vec 通过训练神经网络来利用此类上下文信息,以区分实际同时出现的单词组和随机分组的单词。输入层采用目标单词以及一个或多个上下文单词的稀疏表示。该输入连接到单个较小的隐藏层。 在该算法的一种版本中,系统通过用随机噪声词替换目标词来形成反例。给定正例“飞机飞翔”,系统可能会替换“慢跑”以创建对比负例“慢跑飞翔”。 该算法的另一个版本通过将真实目标单词与随机选择的上下文单词配对来创建反例。因此,它可能会采用正面示例(the,plane),(flies,plane)和反面示例(compiled,plane),(who,plane)并学习识别哪些对实际上在文本中一起出现。 然而,分类器并不是这两个系统版本的真正目标。模型训练完成后,就得到了嵌入。我们可以使用连接输入层和隐藏层的权重将单词的稀疏表示映射到更小的向量。这种嵌入可以在其他分类器中重用。 有关 word2vec 的更多信息,请参阅 tensorflow.org 上的教程 4.3 将嵌入训练为更大模型的一部分我们可以将学习嵌入作为目标任务神经网络的一部分。这种方法可以为特定系统提供良好定制的嵌入,但可能比单独训练嵌入需要更长的时间。 一般来说,当有稀疏数据(或您想要嵌入的密集数据)时,我们可以创建一个嵌入单元,它只是大小为 d 的特殊类型的隐藏单元。该嵌入层可以与任何其他特征和隐藏层组合。与任何 DNN 一样,最后一层将是正在优化的损失。例如,假设我们正在执行协作过滤,其目标是根据其他用户的兴趣来预测用户的兴趣。我们可以通过随机留出(或保留)用户观看过的少量电影作为正标签,将其建模为监督学习问题,然后优化 softmax 损失。
图 5. 用于从协作过滤数据学习电影嵌入的示例 DNN 架构 另一个例子,如果你想为房地产广告中的单词创建一个嵌入层作为 DNN 的一部分来预测房价,那么可以使用训练数据中已知的房屋售价来优化 L2 损失:标签。 当学习 d 维嵌入时,每个项目都会映射到 d 维空间中的一个点,以便相似的项目位于该空间中的附近。图 6 有助于说明嵌入层中学习到的权重与几何视图之间的关系。输入节点和 d 维嵌入层中的节点之间的边权重对应于每个 d 轴的坐标值。
链接-https://developers.google.cn/machine-learning/crash-course/embeddings/video-lecture |
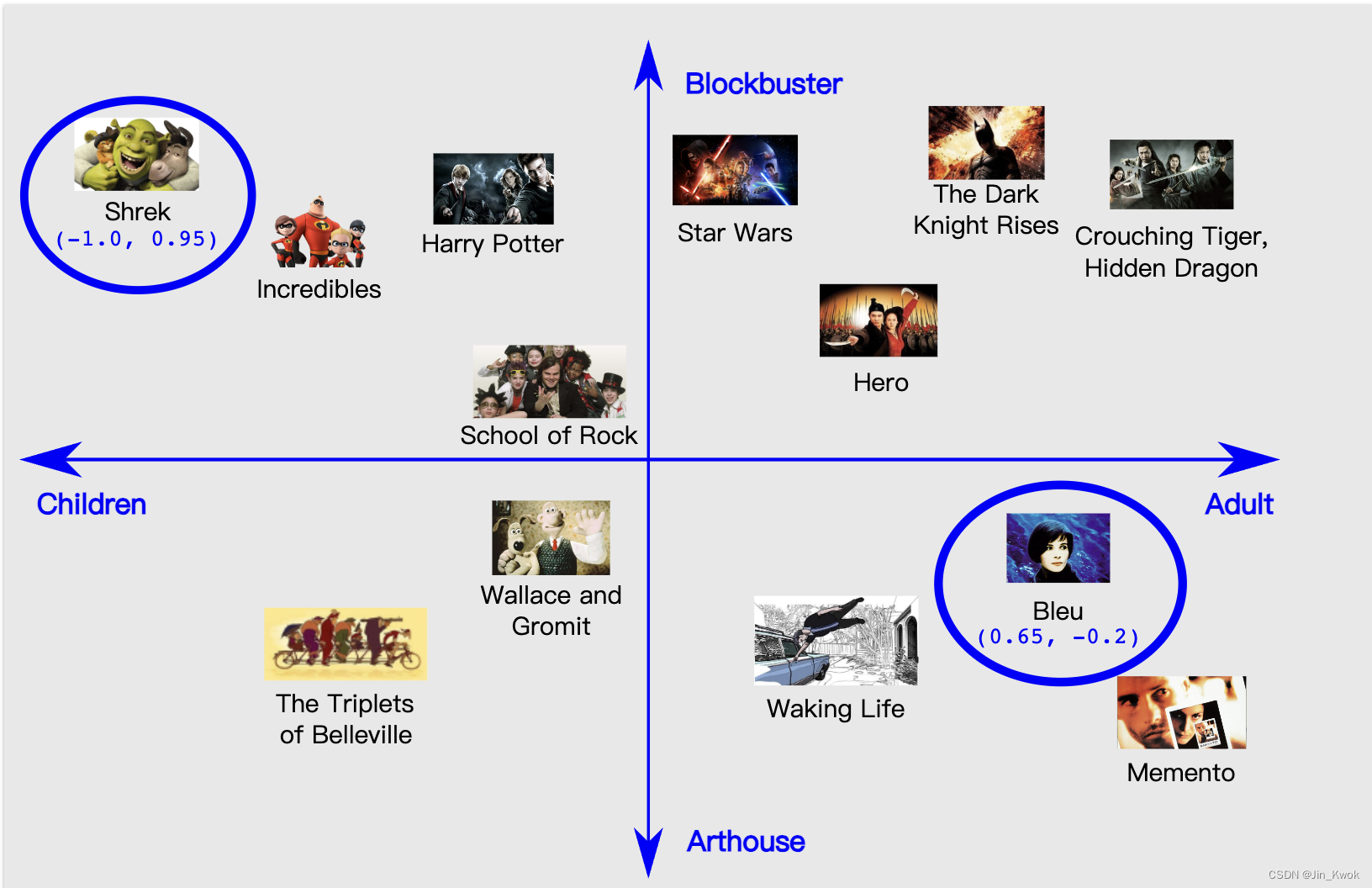 图 2. 可能的二维排列
图 2. 可能的二维排列
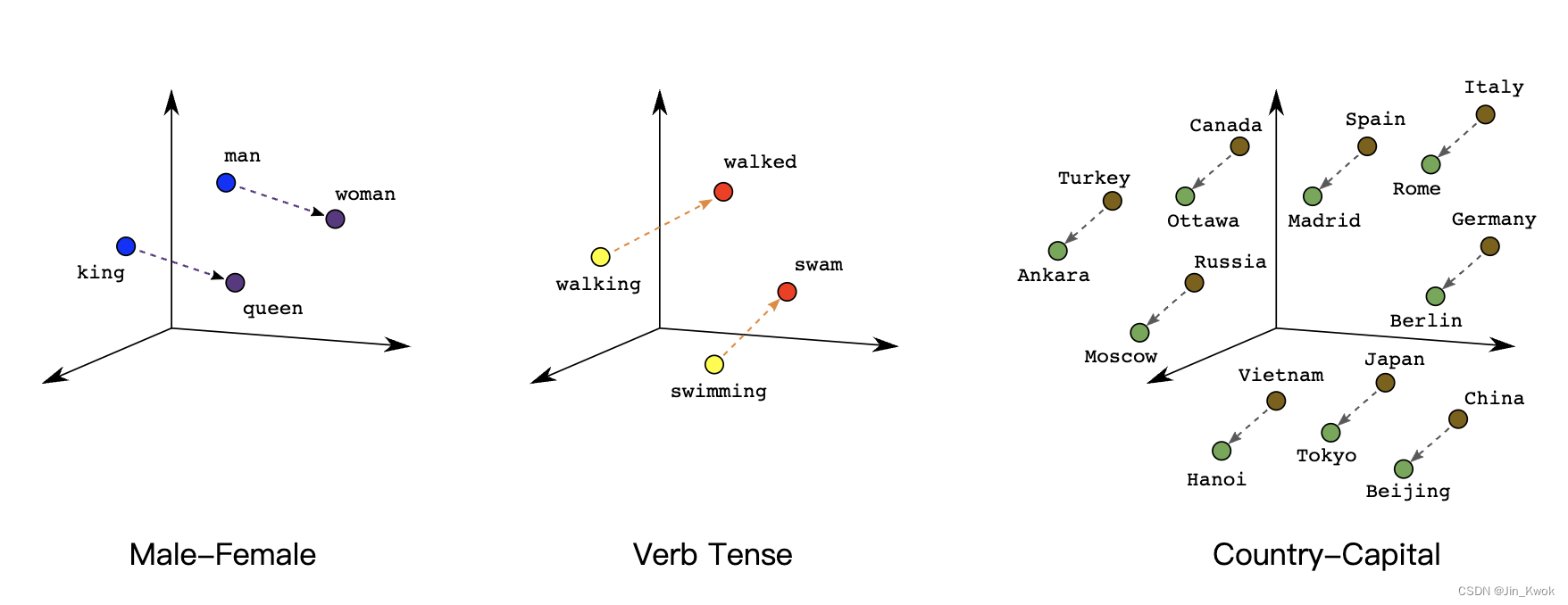 图 4 嵌入可以产生显着的类比
图 4 嵌入可以产生显着的类比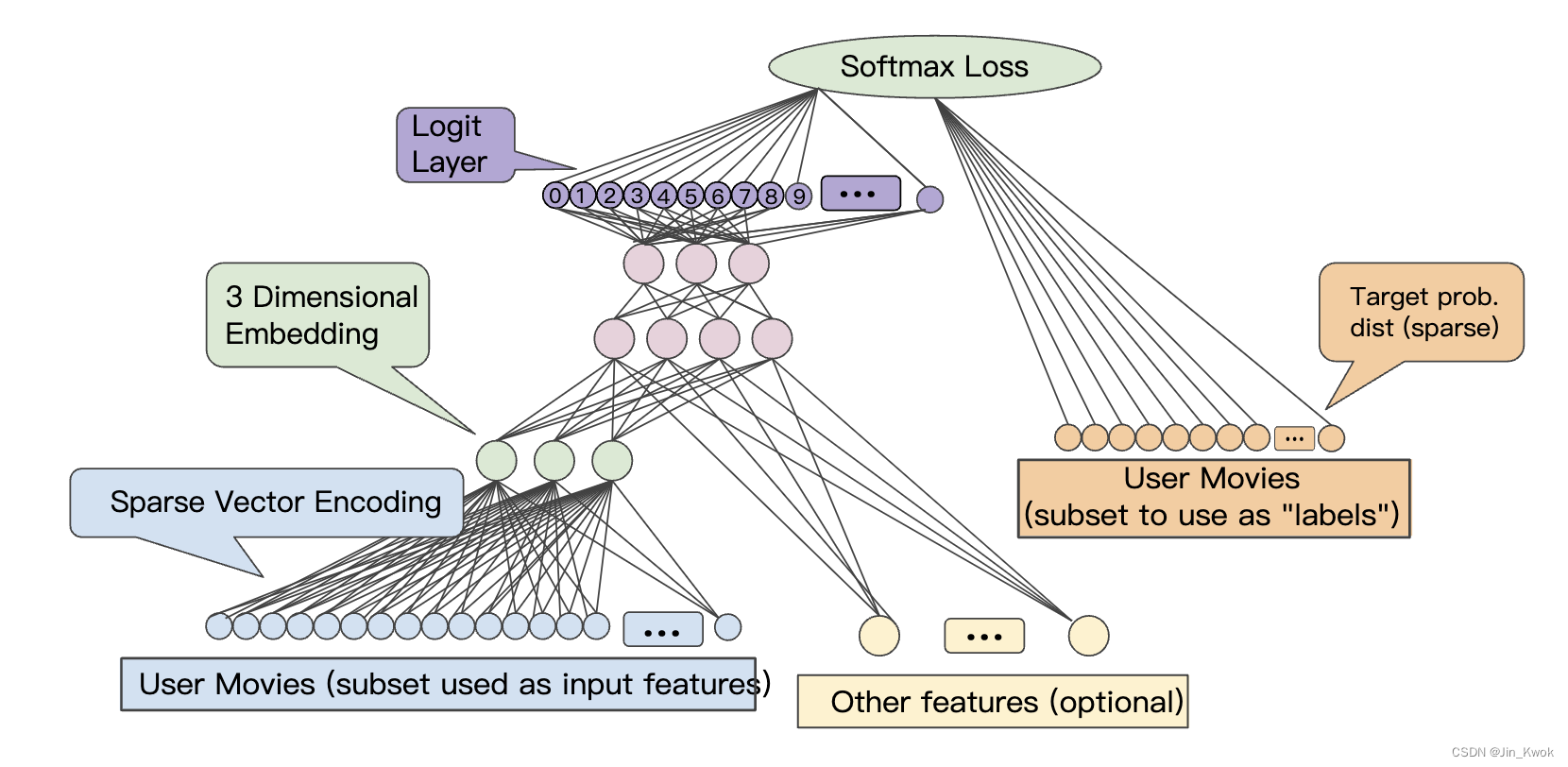
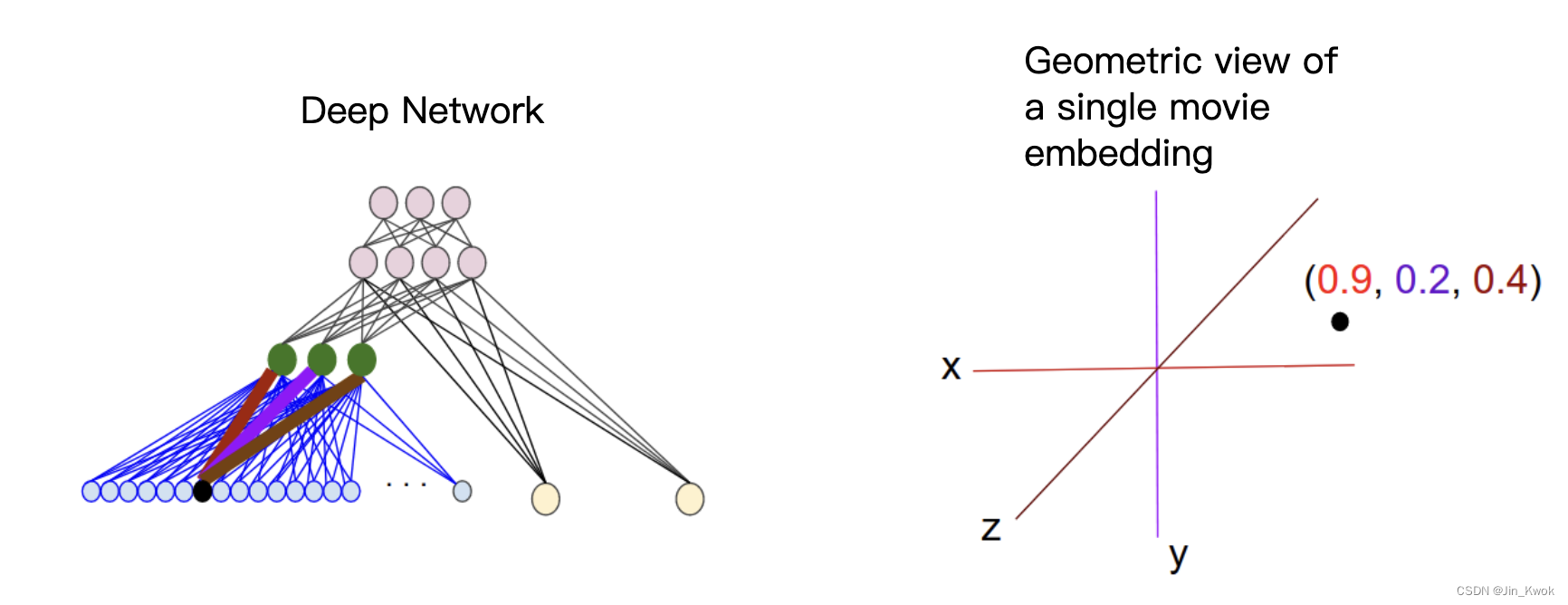 图 6. 嵌入层权重的几何视图
图 6. 嵌入层权重的几何视图【本文地址】