注意力机制详解(小白入门) |
您所在的位置:网站首页 › 各种智力游戏都有发展注意力的作用对不对 › 注意力机制详解(小白入门) |
注意力机制详解(小白入门)
|
文章目录
产生原因注意力机制类型最大池化与平均池化的注意力机制注意力池化层次池化- 引入时序,更新V循环池化 引入时序更新Q多头注意力池化基于多头注意力的变换器
注意力机制的研究进展(待更)注意力机制的好处注意力机制的变种硬性注意力键值对注意力多头注意力
产生原因
受到人类注意力机制的启发。人们在进行观察图像的时候,其实并不是一次就把整幅图像的每个位置像素都看过,大多是根据需求将注意力集中到图像的特定部分。而且人类会根据之前观察的图像学习到未来要观察图像注意力应该集中的位置。
注意力机制其实也是一种池化,是一种对输入分配偏好的通用池化方法,通常是含常数的,也可以带来非参数模型。注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。
最常用的形式是通过query(问询矩阵)*key(比如用rnn的隐藏层ht加入全连接生成或者用lstm的细胞状态全连接生成) 对两个矩阵点乘的结果(标准化)套入softmax进行生成概率分布,再于value 矩阵相乘的得到包含注意力机制的词/句子表示。 比如输入是the food is good but the service is bad 这个文本做情感分类,如果问的是食物的情感,则通过query embedding加大注意力在前四个词语(通过概率的数值加大前面四个词的比重)而尽可能忽略but后面的词语。如果问的是服务,则尽可能忽略but前面的词语,实现形式是通过问题生成query embedding作为Q矩阵与键K矩阵相乘经过softmax得到每个词的注意力权重(其实这是一种概率的体现), 再与V值矩阵相乘得到注意力机制的表示。该例子:对注意力可视化如下:
最大池化容易过拟合,平均池化容易欠拟合 最早的注意力机制其实是一种平均池化:
attention base RNN: seq2seq 模型:
应用:文本分类/句子情感分析 循环池化 引入时序更新Q
更细节解释: 输入X的维度 [batch_size, length, embedding_size] W [embedding_size, hidden_size] Q or V or K=WX [batch_size, length, hidden_size] 多头Q = [batch_size, length, h, embedding_size/h], 转置 [batch_size, h, length, embedding_size/h], h头,则h次缩放点积 词嵌入的维度要可以整除头的个数。 生成多个q,k,v; 并不share权重,每个头都不一样;每个头的维度: [wocab_length, embedding_dim/h]
It expands the model’s ability to focus on different positions. Yes, in the example above, z1 contains a little bit of every other encoding, but it could be dominated by the the actual word itself. It would be useful if we’re translating a sentence like “The animal didn’t cross the street because it was too tired”, we would want to know which word “it” refers to. 多头在解决指代关系更强; It gives the attention layer multiple “representation subspaces”. As we’ll see next, with multi-headed attention we have not only one, but multiple sets of Query/Key/Value weight matrices (the Transformer uses eight attention heads, so we end up with eight sets for each encoder/decoder). Each of these sets is randomly initialized. Then, after training, each set is used to project the input embeddings (or vectors from lower encoders/decoders) into a different representation subspace. 基于多头注意力的变换器
不用rnn cnn;就是基于很多线性变换,通过注意力构造很多的神经网络; 编码器:输入200个词, 最后得到200个词的表征; 解码器 生成模型;生成第一个。再生成第二个。。。在第n个词解码时对前五个词分配注意力机制;掩码变量;
Attention机制最早是在视觉图像领域提出来的,应该是在九几年思想就提出来了,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。 注意力机制的好处 提高性能,提高审计网络的可解释性克服递归神经网络RNN的一些挑战,随着输入长度增加性能下降,输入顺序不合理导致计算效率低下。最大的坏处是计算量。o(n^2d) n是文本长度 d是词的embedding 维度。 注意力机制的变种 硬性注意力之前提到的注意力是软性注意力,其选择的信息是所有输入信息在注意力 分布下的期望。还有一种注意力是只关注到某一个位置上的信息,叫做硬性注意力(hard attention)。硬性注意力有两种实现方式: (1)一种是选取最高概率的输入信息; (2)另一种硬性注意力可以通过在注意力分布式上随机采样的方式实现。硬性注意力模型的缺点: 硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息。因此最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练。为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。硬性注意力需要通过强化学习来进行训练。——《神经网络与深度学习》 键值对注意力即上图右边的键值对模式,此时Key!=Value,注意力函数变为: 多头注意力(multi-head attention)是利用多个查询Q = [q1, · · · , qM],来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接。多头的本质是多个独立的attention计算,作为一个集成的作用,防止过拟合。 对于使用自注意力机制的原因,论文中提到主要从三个方面考虑(每一层的复杂度,是否可以并行,长距离依赖学习),并给出了和RNN,CNN计算复杂度的比较。 1、可以看到,如果输入序列n小于表示维度d的话,每一层的时间复杂度self-attention是比较有优势的。当n比较大时,作者也给出了一种解决方案self-attention(restricted)即每个词不是和所有词计算attention,而是只与限制的r个词去计算attention(局部,例如Bert窗口+跳词)。 2、在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。 3、在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。能够无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构。 reference https://blog.csdn.net/yimingsilence/article/details/79208092?ops_request_misc=&request_id=&biz_id=102&utm_term=注意力机制&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-2-79208092.pc_search_result_hbase_insert&spm=1018.2226.3001.4187 https://zhuanlan.zhihu.com/p/53682800 https://www.jianshu.com/p/f3a6fd73115f |












 上图为双向rnn作为encoder, 经过编码后再塞进去基于RNN的decoder。 需要初始化的值: s0, y0,h0(正向,反向两个)。st是新的decoder中的隐状态。 seq2seq的理解:主要是生成模型的一种。比如“知识就是力量”这个句子经过decode后,是c,c生成s0,s1=f(y0,s0,c), y1=f(s1,c,y0). 注意力机制让其先集中翻译知识,输出knowledge,作为y0,进一步再翻译下面的。
上图为双向rnn作为encoder, 经过编码后再塞进去基于RNN的decoder。 需要初始化的值: s0, y0,h0(正向,反向两个)。st是新的decoder中的隐状态。 seq2seq的理解:主要是生成模型的一种。比如“知识就是力量”这个句子经过decode后,是c,c生成s0,s1=f(y0,s0,c), y1=f(s1,c,y0). 注意力机制让其先集中翻译知识,输出knowledge,作为y0,进一步再翻译下面的。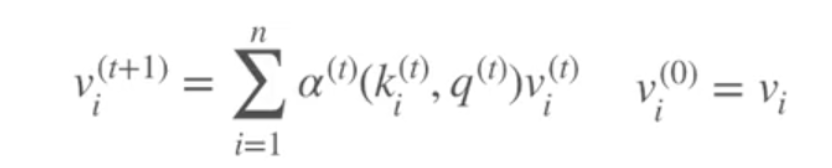



 深度学习主要是对端对端对训练。但该论文需要提供中间步骤的标签;先根据query获得最接近的句子1,再根据句子1找句子2,句子2中的实体得到答案。
深度学习主要是对端对端对训练。但该论文需要提供中间步骤的标签;先根据query获得最接近的句子1,再根据句子1找句子2,句子2中的实体得到答案。






 逻辑:通过全连接层做不同的子空间变换,再连接起来。允许模型在不同子空间学习信息,另外一点是这个过程是可以并行计算的。Q每一行都是一个词的表征; dk: the square root of the dimension of the key vectors.
逻辑:通过全连接层做不同的子空间变换,再连接起来。允许模型在不同子空间学习信息,另外一点是这个过程是可以并行计算的。Q每一行都是一个词的表征; dk: the square root of the dimension of the key vectors.






【本文地址】
今日新闻 |
推荐新闻 |