YOLOv5项目实现口罩检测、目标检测(免费提供数据集2000+图片和标注以及所有代码)可以在多种平台上运行(pycharm+CUDA、colab、国内GPU云平台)图片形式、rstp形式、视频形式等 |
您所在的位置:网站首页 › 各种口罩的功能和区别图片 › YOLOv5项目实现口罩检测、目标检测(免费提供数据集2000+图片和标注以及所有代码)可以在多种平台上运行(pycharm+CUDA、colab、国内GPU云平台)图片形式、rstp形式、视频形式等 |
YOLOv5项目实现口罩检测、目标检测(免费提供数据集2000+图片和标注以及所有代码)可以在多种平台上运行(pycharm+CUDA、colab、国内GPU云平台)图片形式、rstp形式、视频形式等
|
一、目标检测概述
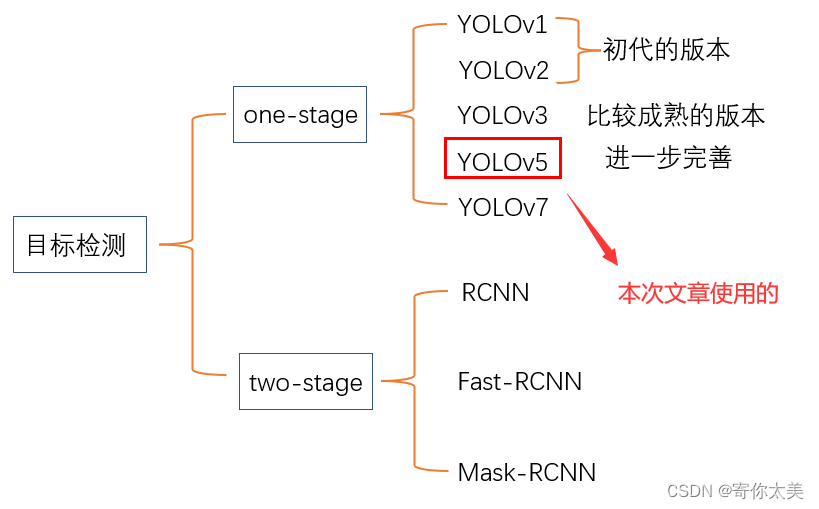
相信很多朋友最近想入门计算机视觉方面,但是对于怎么入门还不是很了解,在这个过程中会遇到很多的问题,例如:找不到学习资源、软件不会安装等等。目标检测只是计算机视觉的一个方面,但是目前仍处于热门的研究话题。而目标检测的方法分为one-stage和two-stage方法,其中两种方法包括的方法和结果如下图所示
在这篇文章中,我不会讲关于YOLOv5的一些算法细节,我会手把手教大家实现这个项目 注意: 1、本文章的内容将包含代码运行的多种平台,大家可以根据自己电脑的配置选择合适的运行平台,有: ①pycharm IDE+CUDA+anaconda 自己电脑的配置较高,显存较大的兄弟选择!!! ②colab 很方便!!不太稳定!谷歌的免费的GPU资源,需要外网和Google账户才能使用!!! ③AutoDL 很方便!!稳定!唯一的缺点是按小时收费!! 2、手把手教你怎么训练,同时也提供训练后的模型,可以直接使用(也是手把手教哦 3、利用训练后的模型: ①检测图片 ②检测视频 ③通过摄像实时检测 二、项目实战(以口罩检测为例)项目源码和数据集以及数据标注位于文章末尾!!! 2.1目标检测概述写这一部分的目的是对于深度学习中的一些监督学习方法进行概述,让大家对于目标检测有一个清楚的认识,了解进行目标检测的一系列步骤,便于大家在自己的电脑上实操。 1、我们要选择数据集(当然,在这篇博客中我演示的是口罩数据集) 这时候会有一个问题——什么是数据集?它有什么用?数据集在目标检测中就是很多很多张图片,图片中有一些人、动物、物品等等(这些叫做前景,也就是我们需要检测的目标),同时会有对于这些图片中物体的标注(标注用来确定物体的位置信息)。与此同时,还会有具体是哪一类物体(这叫做标签,例如:有狗、猫、人等等) 将以上的概念迁移到我们今天的项目中,我们的标签一共就有3种:戴口罩、未戴口罩、没有戴好口罩;我们同时用标注工具标注图片中目标的位置,用记事本保存。
如上图所示的一张图片中显然有两个人是戴好口罩的我们用0标注,没有带好口罩的我们用1标注,未戴口罩的用2标注,对于上面一张图片,我们生成的标注信息可以保存在TXT记事本中
如上图中,TXT文件中一共有两条记录,代表2个目标,每一条记录有5个参数,作用如上图红色文字所示。 2、划分训练集和验证集 在我的上一篇文章中讲了关于机器学习的本质,里面详细介绍了训练集和测试集怎么划分以及为什么要训练?在这里我就不再赘述,只是说明在目标检测中我们在划分训练集和测试集时候的注意事项 首先我们的图片以及标注放在了一个文件夹中
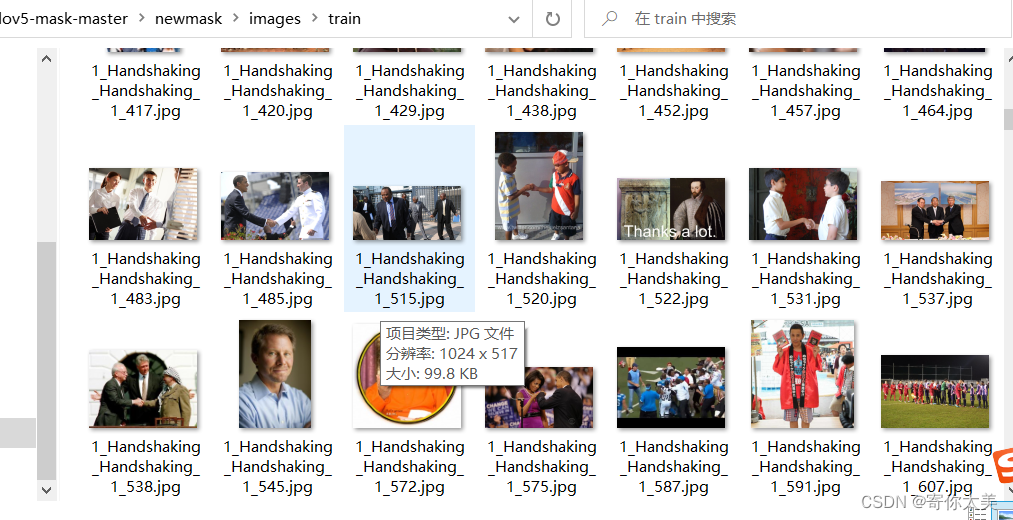
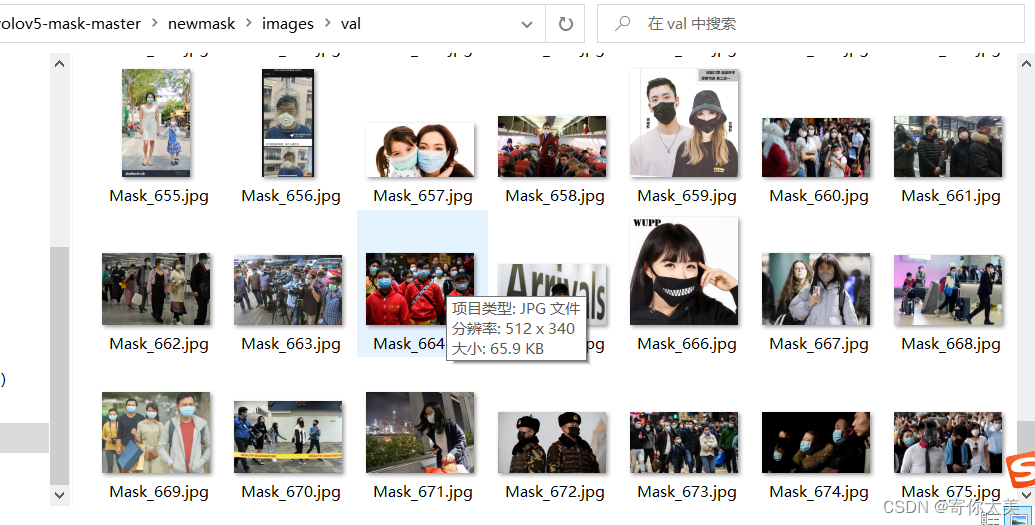
图片和标注文件夹下面都有两个子文件夹,都包含了训练集和验证集,训练集中的图片共有600张,测试集中的图片有178张。如下图所示
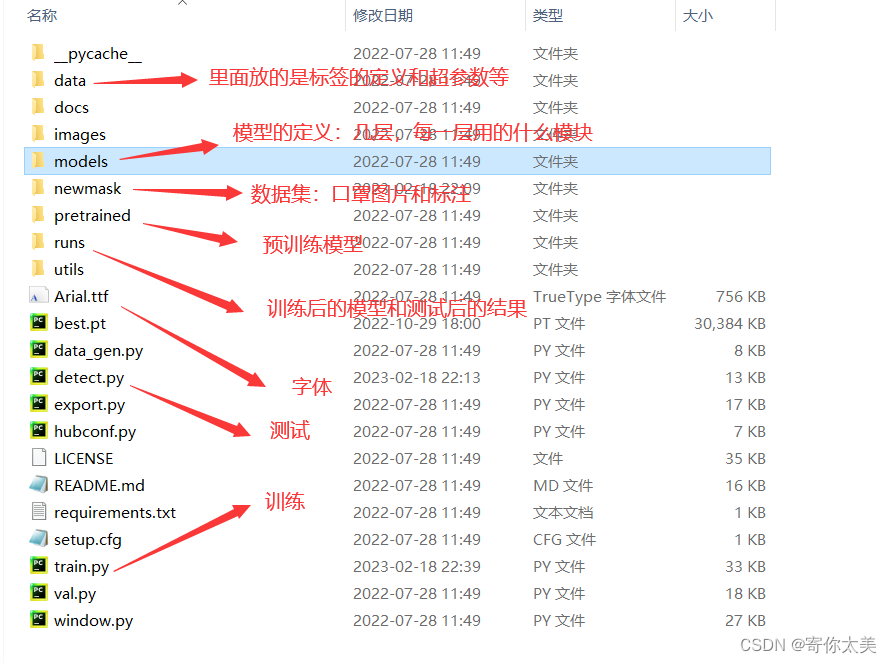
3、一些文件的作用
模型的训练我们就使用云平台,例如:Google的colab或者国内收费的云平台等GPU租用,考虑到许多兄弟无法访问外网,我这次的演示就以国内GPU平台为例。 1、百度搜索AutoDL 进入AutoDL官网,注册一个账号,选择合适的配置的GPU,点击创建实例即可
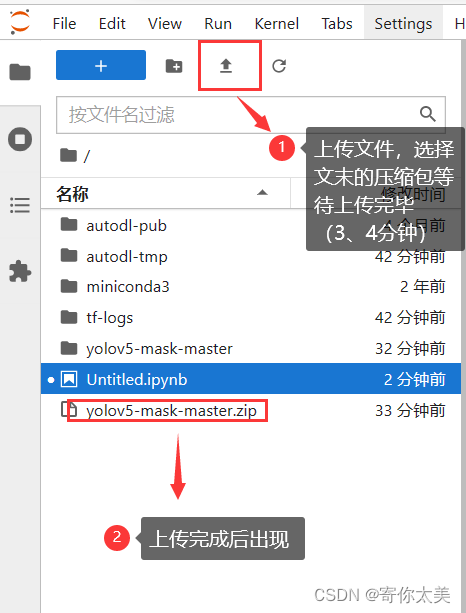
①如上图所示,这个就是你创建的实例,我们选择的显卡的显存为40G,算是比较大的显存了(也可以选择小的显存,只不过训练的时间久一点)。 ②接着我们点击图中所示的JupyterLab工具进入编辑窗口 按下图中的要求操作。
③在代码行输入以下代码,解压压缩文件(注意这一步的操作一定要在上传成功后操作!!!) import zipfile f = zipfile.ZipFile("./yolov5-mask-master.zip",'r') for file in f.namelist(): f.extract(file) f.close()④然后输入以下代码进入文件夹目录下,安装配置文件(这也是选择云GPU的一点好处,避免了自己安装的各种错) %cd yolov5-mask-master/ %pip install -qr requirements.txt2、正式开始训练!!! 继续输入下面的代码,开始训练 !python train.py --batch-size 16注意后面的训练参数可以自己设置,如果你用的GPU显存足够大,可以定义64(我用的是40G显存),如果你的显存10G左右,参数改为8就可以。 接下来会出现整个YOLOv5模型的结构框架,每一层的定义,以及参数量的多少,见下图。
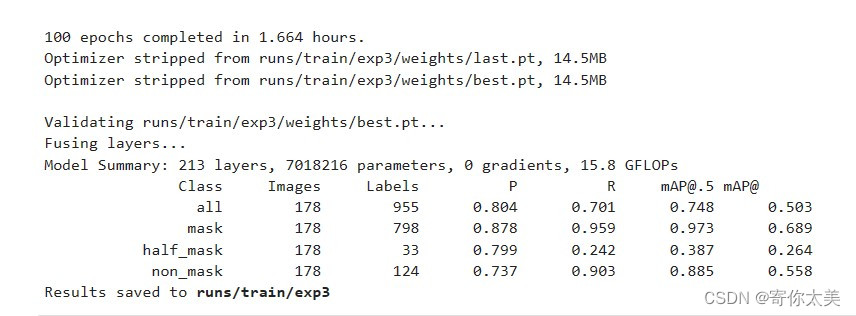
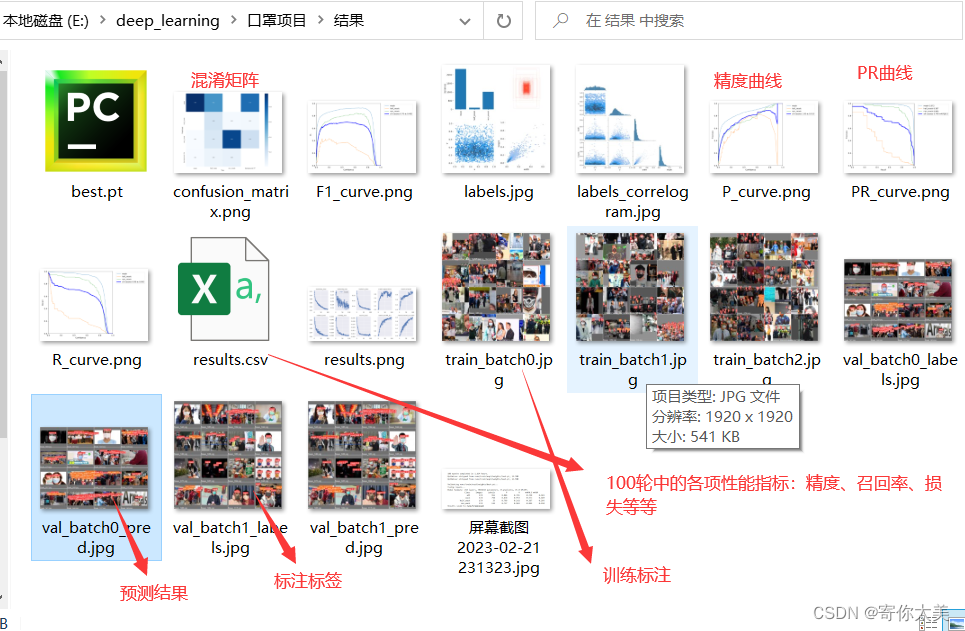
稍等一段时间,模型就开始训练了,我设置默认训练100轮,如果大家想修改训练轮数的话,可以在上面添加参数,代码如下: !python train.py --batch-size 16 --epoch 200上面的代码就是训练200轮,大家根据需要自己修改。 最后就是漫长的等待了,大家如果不想等太久,可以适当将训练轮数设置的小一点;或者选择GPU的时候选择显存大的,然后batchsize可以设置的大一点这样也可以提高训练速度;再者就是数据集图片数量少一点。当然最终的训练结果也会根据你的选择有所不同。 3、训练结果展示 训练后的结果保存在run路径下,我们可以将所有的结果都下载到本地的电脑上,方便后面在自己的机子上测试(当然也可以线上测试)。 ①best.pt该文件是训练之后的在验证集上达到最好效果的模型文件,用于实际的检测。 ②训练100轮之后的结果——精度,召回率,mAP等等
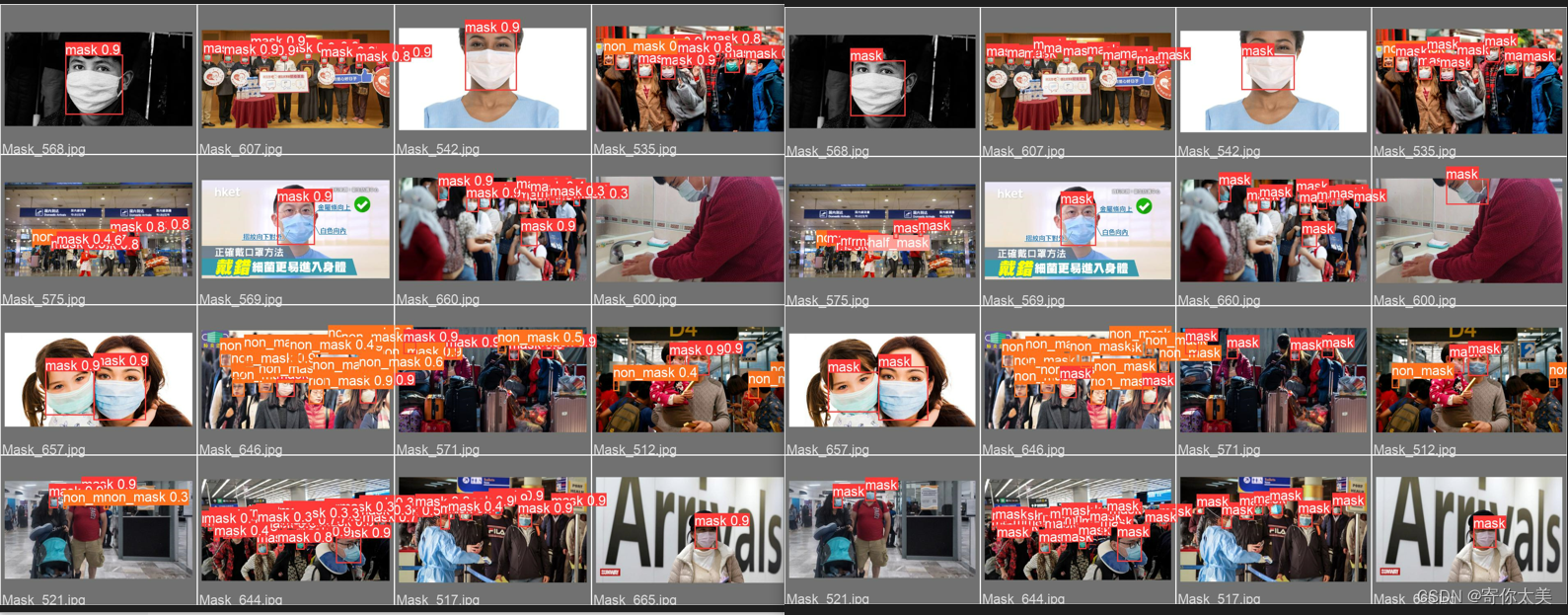
从上面的结果中我们可以看出,经过100轮的训练,对戴了口罩的mAP达到了97.3%,对不戴口罩的mAP为88.5%,但是好像对没有戴好口罩的检测精度不是很高,这可能是由于样本数据中的没有戴好口罩的样本数量较少。 ③验证过程中的检测结果 左边的图是利用我们训练的模型检测得到的结果 右边的图是我们标注的标签 可以看出,检测的总体结果还是比较OK的!! ④更多的结果见下表
在上面的一小节中,讲了模型的训练过程以及训练的结果,在这一小节中,我们根据上一小节中训练得到的模型进行现实中的测试,主要涵盖一下方面: 1、正常的图片检测 !python detect.py --sourse 'data/images'2、视频检测 !python detect.py --sourse 'video.mp4'3、rstp流(IP摄像头软件需要在手机上下载) !python detect.py --source 'rtsp://192.168.43.1:8554/live' 结果
实际中的检测结果如上图所示,成功的检测出了未佩戴口罩、没有戴好口罩、和戴口罩三种类型,虽然在某些方面模型还不够完善,证明有可能是训练轮数不够,训练集和验证集图片设置不合理,还有可能是选择的训练集中的特征信息不突出等等。 结果和源码以及数据集链接提取!!! 链接:https://pan.baidu.com/s/1Ba82PlF1BTFkzwTEdJ5W_g 提取码:krjc 大家需要把图片的两个文件夹复制到newmask目录下(具体操作看下图)
|



 以及下面图中的参数信息等等
以及下面图中的参数信息等等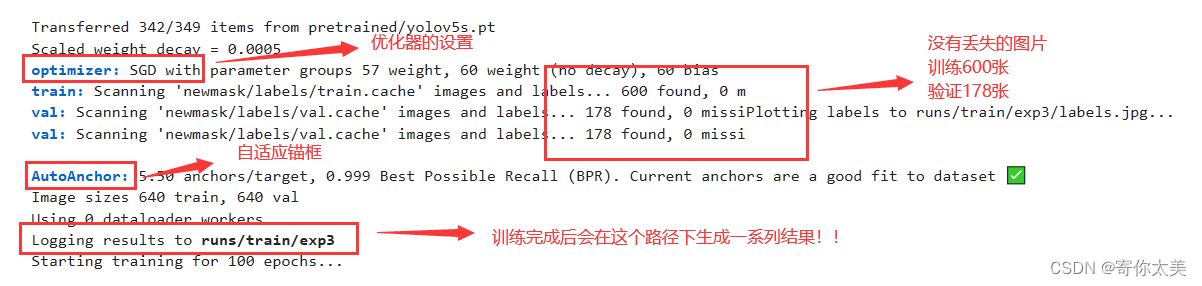

【本文地址】