反向传播算法(BP算法),计算图与自动微分,通用近似定理 |
您所在的位置:网站首页 › 反向传播步骤图 › 反向传播算法(BP算法),计算图与自动微分,通用近似定理 |
反向传播算法(BP算法),计算图与自动微分,通用近似定理
|
通用近似定理
关于通用近似定理的详细说明如下: (2条消息) 通用近似定理(学习笔记)_呆呆象呆呆的博客-CSDN博客_通用近似定理 根据通用近似定理,可得对于具有线性输出层和至少使用一个“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元数量足够,它可以以任意精度来近似任何一个定义在实数空间中的有界闭集函数。可以认为神经网络有一种通用万能的能力,可以近似任意函数。 神经网络可以作为一个万能的函数使用,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。可以用如下公式表示。 其中 反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。 该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。 矩阵微积分向量对于向量的偏导:
向量对标量的偏导:
同时还有标量对向量求导。考虑到我需要解决的实际问题,向量对向量求导更加适用。 链式法则求复合函数导数的常用方法,大一高数学过,现在再复习一遍。
在深度学习中,神经网络在反向传播训练参数的时候要用到链式法则,反向传播的目的是更新参数w和b,试想一下,如何利用预测值反向修正第一个隐藏层的参数呢?那么就需要利用链式法则一层一层的求偏导,这就是为什么神经网络用到链式法则的原因。 计算梯度梯度的含义和用法在day1时学过,并且已用代码实现。这里把梯度计算运用到神经网络中。
第一项是损失项,第二项是正则化项,一般损失项最小时W,b最佳,但为了避免过拟合,又加入了正则化项。之后的求偏导就是数学问题了,公式推导比较复杂,但是比较好理解,可以查阅相关资料得到公式。 算法的大致过程就是:“正向传播”求损失,“反向传播”回传误差。同时,神经网络每层的每个神经元都可以根据误差信号修正每层的权重。 计算图与自动微分自动微分是利用链式法则来自动计算一个复合函数的梯度,不用手动计算,因为求微分是很固定的,用链式法则套用就行了,很适合程序来跑。 举一个例子,下面给出了一个函数
这个函数可以看成许多算子的组合,例如wx,b,+等,函数可以看成这些算子的计算图,如下
每个节点我们都能求出关于前一个输入的偏导数,并且关于前一个输入的偏导数都非常简单,可以用表记录下来,之后求偏导就比较简单了。根据链式法则,只需把前面的偏导数连乘即可。 计算图分类静态计算图(Theano,Tensorflow)和动态计算图(PyTorch,DyNet)。静态是编译时构建计算图,在程序运行时不能改变。动态计算是在程序运行时动态构建,适用与动态变化的数据。我的项目用静态计算图即可求解。 静态计算图并行能力强,好优化。 前向模式和反向模式反向模式和反向传播的计算梯度的方式相同。 关于前向模式和反向模式的区别及实现可以参考这篇文章。 (2条消息) back propagation (BP)算法拓展——自动微分简介:前向模式、反向模式及python代码实现..._weixin_30847865的博客-CSDN博客 反向传播算法就是自动微分的反向模式,前馈神经网络的训练过程可以分为三步: 1.前向计算每一层的状态和激活值,直到最后一层 2.反向计算每一层的参数的偏导数 3.更新参数 有了自动微分后,实现神经网络模型,就变得非常简单,引入一些主流框架就行了,比如PyTorch,Keras等自动搭建神经网络。 当我们要实现一个深度学习方法,就变得很容易,首先定义网络,再定义损失函数,再定义优化方法就行了,不需要手动实现梯度,不需要手动手写优化。 今天学到了好多干货!满足了。 |


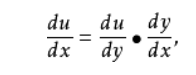



【本文地址】