CNN中卷积层和池化的作用和理解 |
您所在的位置:网站首页 › 历届奥运排行榜前十名 › CNN中卷积层和池化的作用和理解 |
CNN中卷积层和池化的作用和理解
|
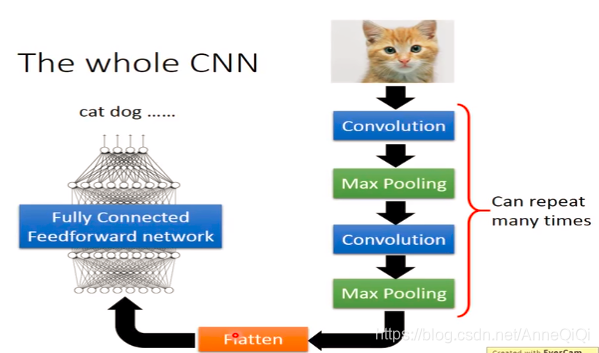
承接上文对CNN的介绍[学习笔记P20-CNN],下面来看看一些细节梳理: CNN框架:
池化层(pooling layer)也叫做子采样层(subsampling layer),其作用是进行特征选择,降低特征数量,并从而减少参数数量。
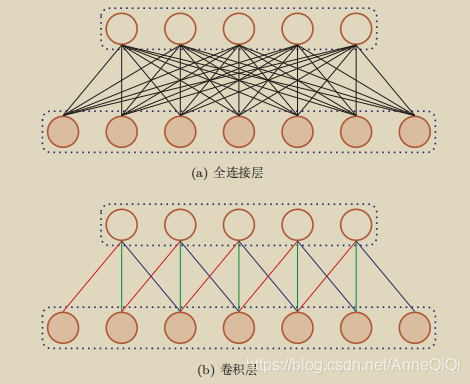
为什么conv-layer之后需要加pooling_layer? 卷积层【局部连接和权重共享】虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少。如果后面接一个分类器,分类器的输入维数依然很高,很容易过拟合。为了解决这个问题,可以再卷积层之后加上一个pooling layer,从而降低特征维数,避免过拟合。
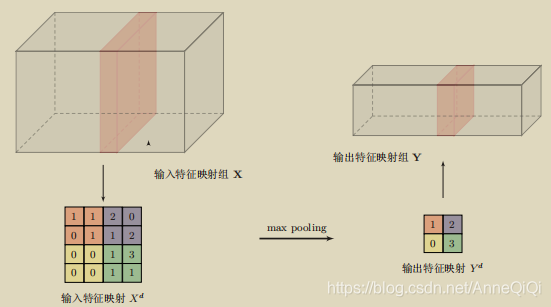
Pooling是指对每个区域进行下采样(Down Sampling)得到一个之,作为这个区域的概括。常用的pooling 函数有两种: 1)最大池化(Max Pooling):一般是取一个区域内所有神经元的最大值。 2)平均池化(Mean Pooling):一般是取区域内所有神经元的平均值。 上图给出了采样max pooling进行子采样操作的示例。可以看出,汇聚层不但 可以有效地减少神经元的数量,还可以使得网络对 一些小的局部形态改变保持 不变性,并拥有更大的感受野。 注意:过大的采样区域会急剧减少神经元的数量,会造成过多的信息损失。如果只有conv-layer会怎么样? 1)过于执着局部特征学习,忽视全局 经过3层conv-layer 3X3filter后,相当于只用了1层conv-layer7X7filter来扫描原图(28-7+1=22);对原图整体状态信息学习很少;从底层细小局部简单的特征到高层复杂全局性更高的特征,推进速度太慢。 2)计算量仍然很大 为什么使用pooling layer? 1)大幅降低parameters,降低计算量 2)通过多层conv-layer间接用更大的filter扫描原图 为什么Max pooling要优于strided convolution和average pooling? 1)strided convolution的弊端 跳格平移,容易overlook,忽视或者丢失细节数据。 2)average pooling的弊端 取均值,容易造成稀释特征程度的效果问题。 最佳downsampling的方法组合: 1)unstrided convolution 2)max pooling |
【本文地址】
今日新闻 |
推荐新闻 |