1896 |
您所在的位置:网站首页 › 厉届奥运会排行榜 › 1896 |
1896
|
阅读本文大约需要 5 分钟
通过前4篇数据分析文章的讲解,本周开始OF要为大家带来数据分析的实战。实战的选材呢,OF是随机选取的,如果大家有什么想要分析的难题,可以私信沟通。 本来想从网上直接下一份历届奥运会的奖牌数据进行动态呈现(包括1896-2021各届、年份、国家/地区、金牌、银牌、铜牌、合计、排名),说来也奇怪,在网上竟然找不到能满足这些条件的,最多能找到1896-2012的数据,但是也不全。没办法了,只能自己去爬虫采集数据啦,当然建议大家有现成数据的还是不要花费这时间去爬虫,既烧脑细胞(得自己找规律),还不安全,万一被限制自由了呢?🤭当然,本文我们要学习的内容只是为了学习,不涉及商业机密,也不违法。
主要内容:Excel 办公自动化和数据分析 适用人群:办公室职员 / Python 初学者 / 有志从事数据分析工作的人员 准备内容:Anaconda-Spyder;requests、re、Pandas、BeautifulSoup(bs4)库
我们先看看能在网上找到什么样的数据,寻找数据源的原则:尽量多的满足我们的需求。 OF找到了一个网站,这里有第一届至第三十届的数据,奖牌榜也比较齐全。但是呢,部分数据并不规则,比如: 1)大部分是下图这样的
2)一部分是这样的
3)还有个别是这样的
另外,每个页面网址的变化部分竟然没有规律可言。
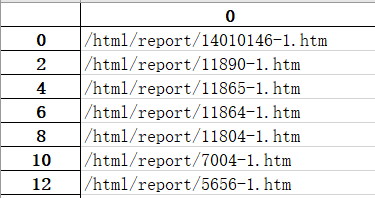
为了能向大家介绍更多的知识点,加大些数据采集的难度,就选取该网站作为数据源吧。咱先别急着写程序,先做一件重要的事,构思下怎样才能把历届奥运会的数据整理完全? a、对第1)种大部分数据的情况,先爬取下来,输出到excel(1); b、对第2)种小部分数据的情况,也先爬取下来,输出到另一个excel(2); c、对第3)种个别的,还有第31-32届的数据,算了,别折腾了,手动复制粘贴到excel(3)吧。 d、最后把这3个excel合并到一个excel,进行数据处理吧。 思路是有了,如何解决网址没有规律的问题呢?想了下,没有规律就把所有网址爬下来保存在一个excel上,然后一个个模拟访问再获取数据吧。 2、获取历届奥运会的网址首先,OF先介绍下爬虫的步骤: 1)获取url; 2)下载网页内容; 3)解析网页内容;4)寻找需要的内容并保存。 1)获取url:http://www.no1story.com/html/category/11644-1.htm 总共有两页,第一页是11644-1,第二页是11644-2,其他都是一样的,该网址可以拆分为3部分 url_begin = 'http://www.no1story.com/html/category/11644-' i = 1 url_end = '.htm' url = url_begin+str(i)+url_end2)下载网页内容:写个getHTMLText函数获取 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } def getHTMLText(url): ''' 此函数用于获取网页的html文档 ''' try: #获取服务器的响应内容,并设置最大请求时间为6秒 res = requests.get(url, headers=headers, timeout = 6) #判断返回状态码是否为200 res.raise_for_status() #设置该html文档可能的编码 res.encoding = res.apparent_encoding #返回网页HTML代码 return res.text except: return '产生异常'3)解析网页内容 for i in range(1,3): url = url_begin+str(i)+url_end demo = getHTMLText(url) #解析HTML代码 soup = BeautifulSoup(demo, 'html.parser')4)寻找需要的内容并保存:这里有个re.compile正则表达式的知识,大家可以学下 newlist=[] for i in range(1,3): url = url_begin+str(i)+url_end demo = getHTMLText(url) #解析HTML代码 soup = BeautifulSoup(demo, 'html.parser') #模糊搜索HTML代码的所有包含href属性的标签 a_labels = soup.find_all('a', attrs={'href': re.compile(r"/html/report/(\s\w+)?")}) #获取所有标签中的href对应的值,即超链接 for a in a_labels: newlist.append(a.get('href')) #删除重复的网址 newlist2 = pd.DataFrame(newlist).drop_duplicates() #将网址导出到excel newlist2.to_excel("./data/test.xlsx")完整代码如下: import requests, re from bs4 import BeautifulSoup import pandas as pd headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } def getHTMLText(url): ''' 此函数用于获取网页的html文档 ''' try: #获取服务器的响应内容,并设置最大请求时间为6秒 res = requests.get(url, headers=headers, timeout = 6) #判断返回状态码是否为200 res.raise_for_status() #设置该html文档可能的编码 res.encoding = res.apparent_encoding #返回网页HTML代码 return res.text except: return '产生异常' def main(): #目标网页,这个可以换成一个你喜欢的网站 url_begin = 'http://www.no1story.com/html/category/11644-' url_end = '.htm' newlist=[] for i in range(1,3): url = url_begin+str(i)+url_end demo = getHTMLText(url) #解析HTML代码 soup = BeautifulSoup(demo, 'html.parser') #模糊搜索HTML代码的所有包含href属性的标签 a_labels = soup.find_all('a', attrs={'href': re.compile(r"/html/report/(\s\w+)?")}) #获取所有标签中的href对应的值,即超链接 for a in a_labels: newlist.append(a.get('href')) #删除重复的网址 newlist2 = pd.DataFrame(newlist).drop_duplicates() #将网址导出到excel newlist2.to_excel("./data/test.xlsx") main()生成的excel内容,截取了部分如下:
因为篇幅的原因,OF以获取第1)种大部分情况的数据为例
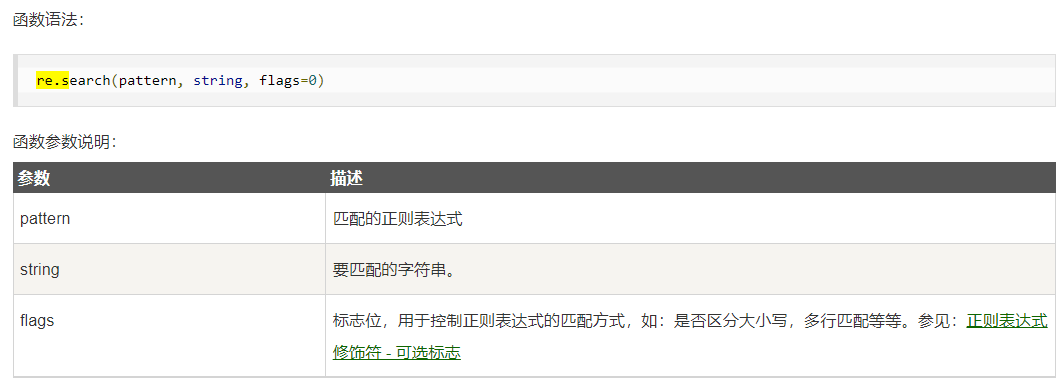
获取网页的表格数据,可以理解为获取标签内的内容,一般我们用find_all()来获取符合条件的解析内容,在循环获取历届数据前,我们先用一个网址进行调试。 import requests,re from bs4 import BeautifulSoup import pandas as pd #请求headers 模拟谷歌浏览器访问 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } def getHTMLText(url): try: #获取服务器的响应内容,并设置最大请求时间为6秒 res = requests.get(url, headers=headers, timeout = 6) #判断返回状态码是否为200 res.raise_for_status() #设置该html文档可能的编码 res.encoding = res.apparent_encoding #返回网页HTML代码 return res.text except: return '产生异常' #读取新建的excel来存放获取的数据 olympic = pd.ExcelWriter("./data/Olympic2.xlsx") #用其中一个网址进行测试 url = "http://www.no1story.com/html/report/5437-1.htm" demo = getHTMLText(url) #解析HTML代码 bs = BeautifulSoup(demo, 'html.parser') # 获取表格内容并按['名次','国家','金牌','银牌','铜牌']导出到excel content = bs.find_all('td',attrs={'style':True}) data_list_content = [] #定义一个空列表 for data in content: data_list_content.append(data.text.strip()) #获取标签的内容去掉两边空格并添加到列表里 #语句new_list = [example[i] for example in dataSet]作用为: 将dataSet中的数据按行依次放入example中,然后取得example中的example[i]元素,放入列表new_list中 new_list = [data_list_content[i:i + 5] for i in range(0, len(data_list_content), 5)] df1 = pd.DataFrame(new_list) #设置列顺序 df1.columns=['名次','国家','金牌','银牌','铜牌'] df1.to_excel(olympic,sheet_name='initial') olympic.close()截至目前,少了一个最重要的年份,我们看一下这个网页,其中有一行标明了年份:“1960年第十七届罗马奥运会上,各国排名情况如下”,还有标题中标明了第几届奥运会“第十七届罗马奥运会各国奖牌榜”。我们用正则表达式先获得这两行数据: title_rule = re.compile("第+\w+奥运会各国奖牌榜\B") year_rule = re.compile("(.*)年") title = bs.find(text=title_rule) year = bs.find(text=year_rule)OF将常用的正则表达式列下:
但我们想要的年份(如1996),标题(如第二十六届亚特兰大奥运会),一般在re.compile()后,我们在使用re.search(匹配成功返回一个匹配的对象,否则返回None)或re.match()来获取想要的内容。
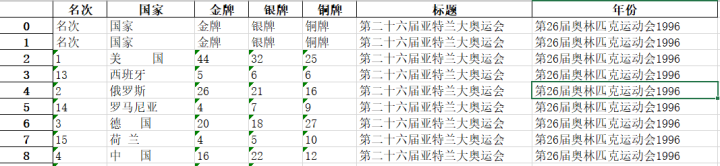
然后,我们需要把title1,year1赋给df1,新增两个列名['标题'],['年份'] df1['标题'] = '' df1['年份'] = '' df1.loc[:, '标题'] = title1 df1.loc[:, '年份'] = year1 4、获取历届奥运会的数据获取某届可以的话,我们就可以写循环语句,来获取历届奥运会的数据。不过,写循环的时候要注意: 1)因为有部分网页re.compile(标题title和年份year)时,可能获取到的是None,所以在获取title1,year1前要做个判断; 2)循环的目的是将历届奥运会的数据合并到一个DataFrame中,所以需要用到concat函数,df1作为被合并的DataFrame,d2作为每次循环获取的新DataFrame,通过循环将df2合并至df1。 完整代码如下: import requests,re from bs4 import BeautifulSoup import pandas as pd #请求headers 模拟谷歌浏览器访问 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } def getHTMLText(url): ''' 此函数用于获取网页的html文档 ''' try: #获取服务器的响应内容,并设置最大请求时间为6秒 res = requests.get(url, headers=headers, timeout = 6) #判断返回状态码是否为200 res.raise_for_status() #设置该html文档可能的编码 res.encoding = res.apparent_encoding #返回网页HTML代码 return res.text except: return '产生异常' def main(): df = pd.read_excel("./data/test.xlsx") url_begin = 'http://www.no1story.com' olympic = pd.ExcelWriter("./data/Olympic2.xlsx") df1 = pd.DataFrame() for a in df[0]: url = url_begin+str(a) demo = getHTMLText(url) #解析HTML代码 bs = BeautifulSoup(demo, 'html.parser') #获取数据 title_rule = re.compile("第+\w+奥运会各国") year_rule = re.compile("(.*)年(.*?)奥运会") title = bs.find(text=title_rule) year = bs.find(text=year_rule) if(str(title)!="None" and str(year)!="None"): title1 = re.search('(.*?)各国', str(title), re.X).group(1).strip() year1 = re.search('(.*?)年(.*?)奥运会', str(year), re.X).group(1).strip() # 表格内容处理 content = bs.find_all('td',attrs={'style':True}) data_list_content = [] #定义一个空列表 for data in content: data_list_content.append(data.text.strip()) #获取标签的内容去掉两边空格并添加到列表里 #语句new_list = [example[i] for example in dataSet]作用为: 将dataSet中的数据按行依次放入example中,然后取得example中的example[i]元素,放入列表new_list中 new_list = [data_list_content[i:i + 5] for i in range(0, len(data_list_content), 5)] df2 = pd.DataFrame(new_list) df2['标题'] = '' df2['年份'] = '' df2.loc[:, '标题'] = title1 df2.loc[:, '年份'] = year1 df1 = pd.concat([df1,df2]) print(df1) df1.columns=['名次','国家','金牌','银牌','铜牌','标题','年份'] df1.to_excel(olympic,sheet_name='Second') olympic.close() main()输出结果
结 语 今天,OF为大家介绍了如何进行爬虫获取网页数据。因为本篇文章的知识点还挺多的,今天就写到这里,希望初学者们好好体会下思路,将复杂的事项拆分成一个个步骤,这样一点点的积累起来就能把项目做成功。在写python程序前,先构思下步骤,再根据步骤一个个完成。接下来的2篇文章,将会有更多的知识点,先把数据采集这部分的内容好好消化下吧。 1、数据采集-爬虫;(本篇文章) 2、数据处理-数据清洗; 3、数据动态排序。 若有读者对选材和内容有任何建议,请随时评论或私信我,只要是好的建议,OF一定不会辜负大家,会有惊喜🎁送上。 若学员对知识点有疑问或想学习更有用的知识,也请随时评论或私信我,请相信OF的诚意,一定会努力帮助大家发现-解决问题,提高自身的核心竞争力。
|







【本文地址】