揭秘华为数据湖:3大特点、6个标准、入湖流程 |
您所在的位置:网站首页 › 华为数据导入是什么意思啊知乎 › 揭秘华为数据湖:3大特点、6个标准、入湖流程 |
揭秘华为数据湖:3大特点、6个标准、入湖流程
|
01 华为数据湖的3个特点
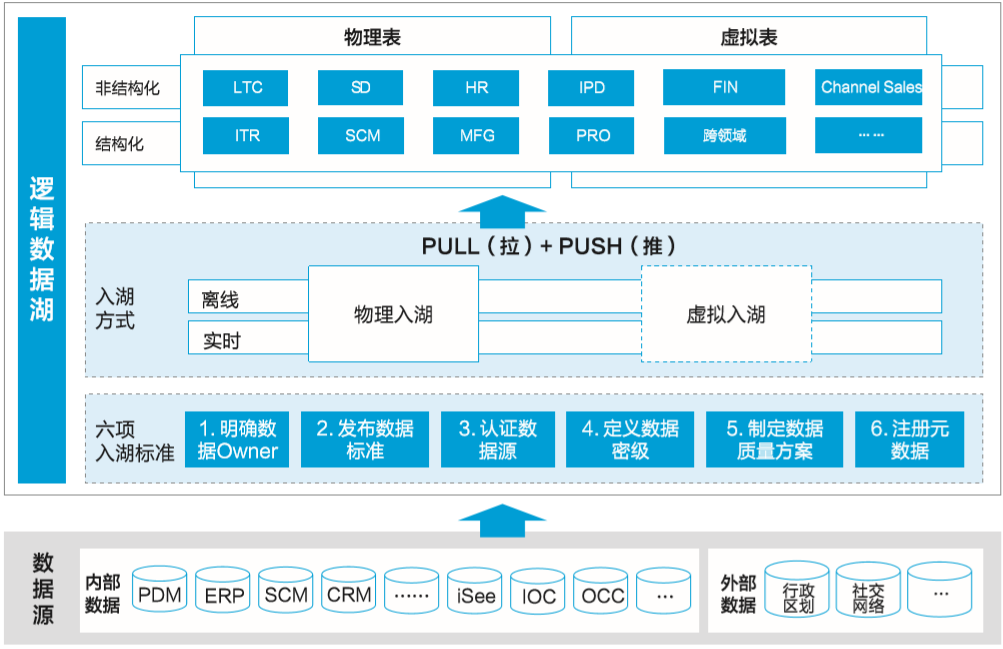
华为数据湖(如图5-2所示)是逻辑上对内外部的结构化、非结构化的原始数据的逻辑汇聚。数据入湖要遵从6项入湖标准,基于6项标准保证入湖的质量,同时面向不同的消费场景提供两种入湖方式,满足数据消费的要求。
▲图5-2 数据湖总体视图
经过近两年的数据湖建设,目前已经完成1.2万个逻辑数据实体、28万个业务属性的入湖,同时数据入湖在华为公司也形成了标准的流程规范,每个数据资产都要入湖成为数据工作的重要标准。
华为数据湖主要有以下几个特点。
1. 逻辑统一
华为数据湖不是一个单一的物理存储,而是根据数据类型、业务区域等由多个不同的物理存储构成,并通过统一的元数据语义层进行定义、拉通和管理。
2. 类型多样
数据湖存放所有不同类型的数据,包括企业内部IT系统产生的结构化数据、业务交易和内部管理的非结构化的文本数据、公司内部园区各种传感器检测到的设备运行数据,以及外部的媒体数据等。
3. 原始记录
华为数据湖是对原始数据的汇聚,不对数据做任何的转换、清洗、加工等处理,保留数据最原始特征,为数据的加工和消费提供丰富的可能。
02 数据入湖的6个标准
数据入湖是数据消费的基础,需要严格满足入湖的6项标准,包括明确数据Owner、发布数据标准、定义数据密级、明确数据源、数据质量评估、元数据注册。通过这6项标准保证入湖的数据都有明确的业务责任人,各项数据都可理解,同时都能在相应的信息安全保障下进行消费。
1. 明确数据Owner
数据Owner由数据产生对应的流程Owner担任,是所辖数据端到端管理的责任人,负责对入湖的数据定义数据标准和密级,承接数据消费中的数据质量问题,并制定数据管理工作路标,持续提升数据质量。
2. 发布数据标准
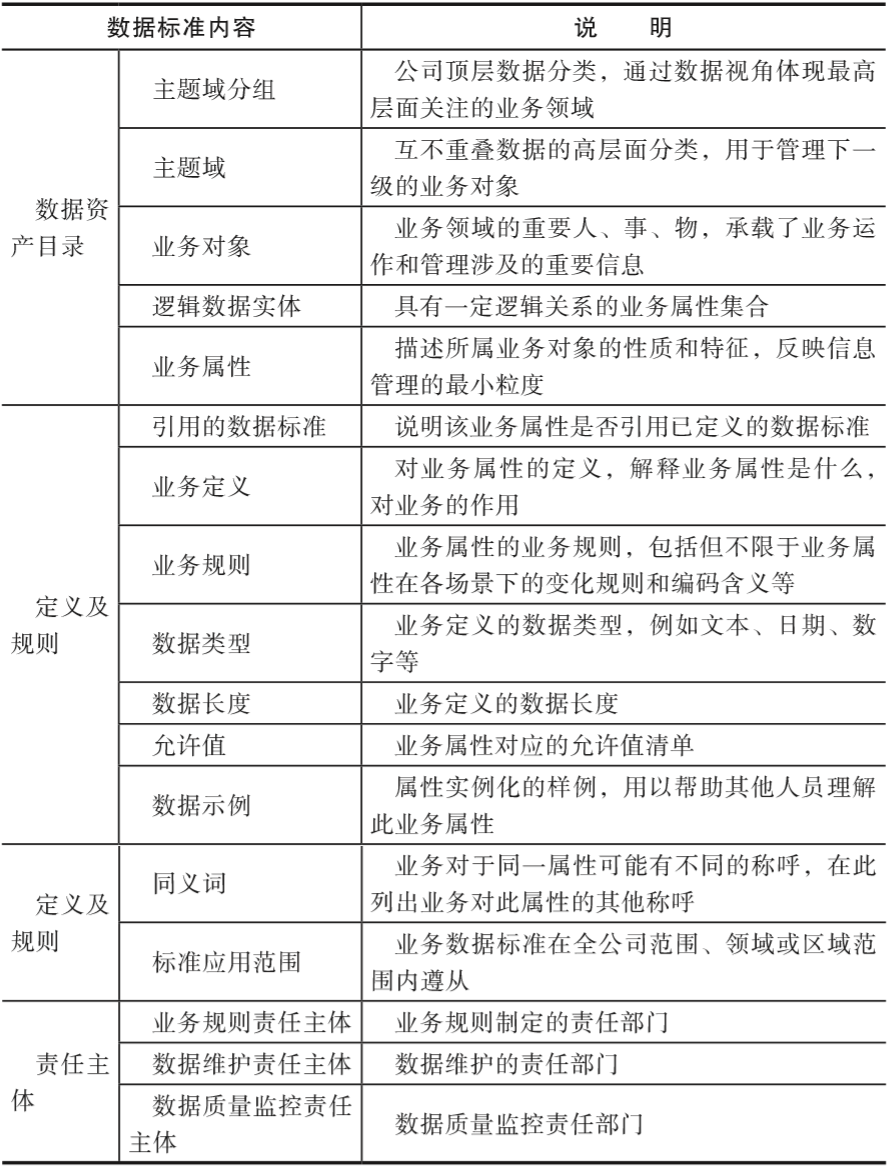
入湖数据要有相应的业务数据标准。业务数据标准描述公司层面需共同遵守的“属性层”数据的含义和业务规则,是公司层面对某个数据的共同理解,这些理解一旦明确并发布,就需要作为标准在企业内被共同遵守。数据标准的信息如表5-1所示。
▼表5-1 数据标准说明
3. 认证数据源
通过认证数据源,能够确保数据从正确的数据源头入湖。认证数据源应遵循公司数据源管理的要求,一般数据源是指业务上首次正式发布某项数据的应用系统,并经过数据管理专业组织认证。
认证过的数据源作为唯一数据源头被数据湖调用。当承载数据源的应用系统出现合并、分拆、下线情况时,应及时对数据源进行失效处理,并启动新数据源认证。
4. 定义数据密级
定义数据密级是数据入湖的必要条件,为了确保数据湖中的数据能充分地共享,同时又不发生信息安全问题,入湖的数据必须要定密。数据定密的责任主体是数据Owner,数据管家有责任审视入湖数据密级的完整性,并推动、协调数据定密工作。
数据定级密度在属性层级,根据资产的重要程度,定义不同等级。不同密级的数据有相应的数据消费要求,为了促进公司数据的消费,数据湖中的数据有相应的降密机制,到降密期或满足降密条件的数据应及时降密,并刷新密级信息。
5. 数据质量评估
数据质量是数据消费结果的保证,数据入湖不需要对数据进行清洗,但需要对数据质量进行评估,让数据的消费人员了解数据的质量情况,并了解消费该数据的质量风险。同时数据Owner和数据管家可以根据数据质量评估的情况,推动源头数据质量的提升,满足数据质量的消费要求。
6. 元数据注册
元数据注册是指将入湖数据的业务元数据和技术元数据进行关联,包括逻辑实体与物理表的对应关系,以及业务属性和表字段的对应关系。通过联接业务元数据和技术元数据的关系,能够支撑数据消费人员通过业务语义快速地搜索到数据湖中的数据,降低数据湖中数据消费的门槛,能让更多的业务分析人员理解和消费数据。
03 数据入湖方式
数据入湖遵循华为信息架构,以逻辑数据实体为粒度入湖,逻辑数据实体在首次入湖时应该考虑信息的完整性。原则上,一个逻辑数据实体的所有属性应该一次性进湖,避免一个逻辑实体多次入湖,增加入湖工作量。
数据入湖的方式主要有物理入湖和虚拟入湖两种,根据数据消费的场景和需求,一个逻辑实体可以有不同的入湖方式。两种入湖方式相互协同,共同满足数据联接和用户数据消费的需求,数据管家有责任根据消费场景的不同,提供相应方式的入湖数据。
物理入湖是指将原始数据复制到数据湖中,包括批量处理、数据复制同步、消息和流集成等方式。 虚拟入湖是指原始数据不在数据湖中进行物理存储,而是通过建立对应虚拟表的集成方式实现入湖,实时性强,一般面向小数据量应用,大批量的数据操作可能会影响源系统。
数据入湖有以下5种主要技术手段。
1. 批量集成(Bulk/Batch Data Movement)
对于需要进行复杂数据清理和转换且数据量较大的场景,批量集成是首选。通常,调度作业每小时或每天执行,主要包含ETL、ELT和FTP等工具。批量集成不适合低数据延迟和高灵活性的场景。
2. 数据复制同步(Data Replication/Data Synchronization)
适用于需要高可用性和对数据源影响小的场景。使用基于日志的CDC捕获数据变更,实时获取数据。数据复制同步不适合处理各种数据结构以及需要清理和转换复杂数据的场景。
3. 消息集成(Message-Oriented Movement of Data)
通常通过API捕获或提取数据,适用于处理不同数据结构以及需要高可靠性和复杂转换的场景。尤其对于许多遗留系统、ERP和SaaS来说,消息集成是唯一的选择。消息集成不适合处理大量数据的场景。
4. 流集成(Stream Data Integration)
主要关注流数据的采集和处理,满足数据实时集成需求,处理每秒数万甚至数十万个事件流,有时甚至数以百万计的事件流。流集成不适合需要复杂数据清理和转换的场景。
5. 数据虚拟化(Data Virtualization)
对于需要低数据延迟、高灵活性和临时模式(不断变化下的模式)的消费场景,数据虚拟化是一个很好的选择。在数据虚拟化的基础上,通过共享数据访问层,分离数据源和数据湖,减少数据源变更带来的影响,同时支持数据实时消费。数据虚拟化不适合需要处理大量数据的场景。
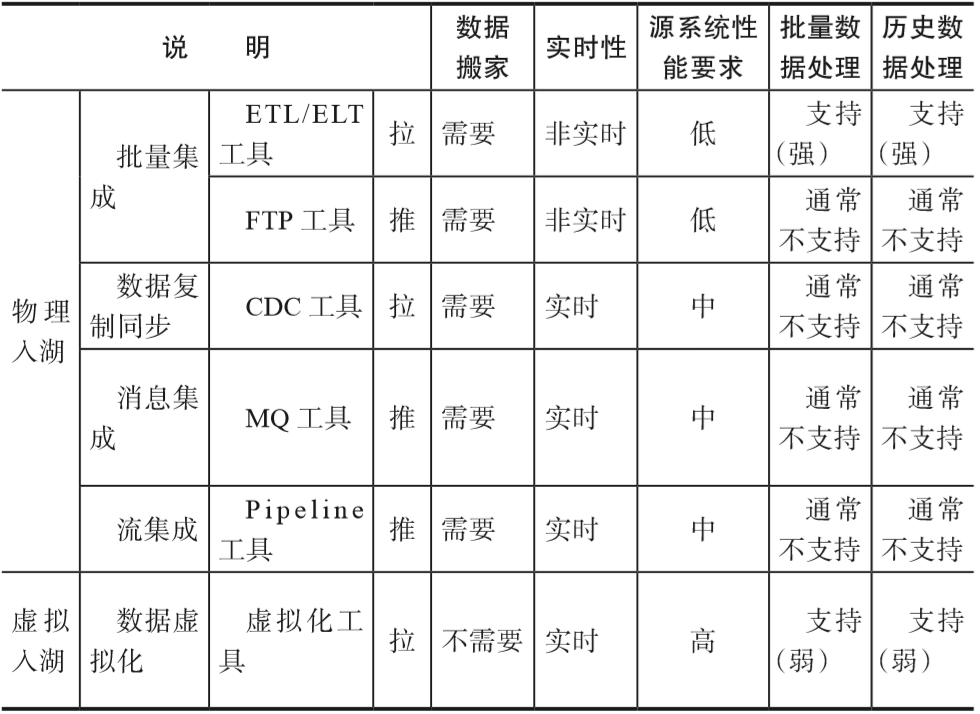
5种数据入湖方式的对比可以参考表5-2。
▼表5-2 数据入湖方式对比
可以通过数据湖主动从数据源PULL(拉)的方式入湖,也可以通过数据源主动向数据湖PUSH(推)的方式入湖。数据复制同步、数据虚拟化以及传统ETL批量集成都属于数据湖主动拉的方式;流集成、消息集成属于数据源主动推送的方式(如表5-3所示)。在特定的批量集成场景下,数据会以CSV、XML等格式,通过FTP推送给数据湖。
▼表5-3 PULL(拉)& PUSH(推)方式入湖
04 结构化数据入湖
结构化数据是指由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
触发结构化数据入湖的场景有两种:
第一,企业数据管理组织基于业务需求主动规划和统筹; 第二,响应数据消费方的需求。
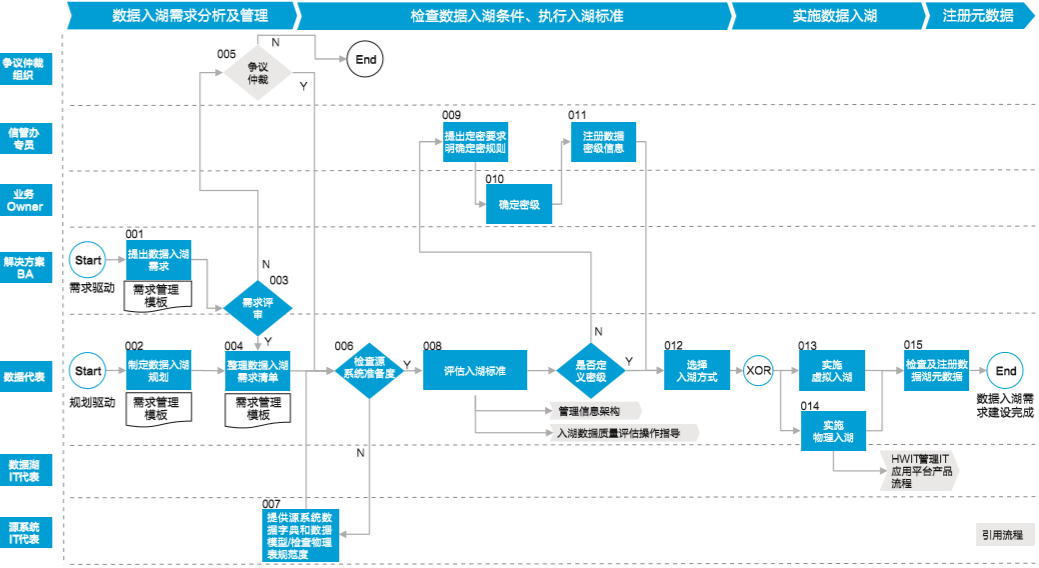
结构化数据入湖过程包括:数据入湖需求分析及管理、检查数据入湖条件和评估入湖标准、实施数据入湖、注册元数据(如图5-3所示)。
▲图5-3 结构化数据入湖流程
1. 数据入湖需求分析及管理
对于规划驱动入湖场景而言,由对应的数据代表基于数据湖的建设规划,输出入湖规划清单,清单包含主题域分组、主题域、业务对象、逻辑实体、业务属性、源系统物理表和物理字段等信息。
对于需求驱动入湖场景而言,由数据消费方的业务代表提出入湖需求,并提供数据需求的业务元数据和技术元数据的信息,包括业务对象、逻辑实体、业务属性对应界面的截图。
无论是主动规划还是被动响应需求,入湖需求清单必须通过业务代表和数据代表的联合评审。当业务代表和数据代表就评审结论发生争议时,可到专业评审组织申请仲裁。
2. 检查数据入湖条件和评估入湖标准
在数据入湖前要检查数据源准备度和评估数据入湖标准。
1)检查数据源准备度
数据有源是数据入湖的基本前提,数据源准备度检查不仅需要源系统的IT团队提供源系统的数据字典和数据模型并检查源系统的物理表规范度,而且需要数据代表评估源系统的数据质量。
2)评估入湖标准
入湖标准包括以下几点。
明确数据Owner:为保证入湖数据的管理责任清晰,在数据入湖前应明确数据Owner。 发布数据标准:入湖数据应有数据标准,数据标准定义了数据属性的业务含义、业务规则等,是正确理解和使用数据的重要依据,也是业务元数据的重要组成部分。 认证数据源:原则上以初始源进湖,数据源认证是保证数据湖数据一致性和唯一性的重要措施。 定义数据密级:定义完整、明确的数据密级是数据湖数据共享、权限控制等的关键依据。信息安全管理专员向业务Owner提出定密需求,并与业务Owner确定定密规则,确定数据密级、定密时间、降密期/降密条件等,然后由信息安全管理专员在信息架构管理平台注册密级信息。 评估入湖数据质量:对入湖数据做质量评估,给入湖数据打质量标签。
如果不满足上述任意一条入湖标准,就应推动源系统数据代表完成整改,满足要求后方可实施数据入湖。
3. 实施数据入湖
数据代表依据消费场景合理选择入湖方式,在不要求历史数据、小批量数据且实时性要求高的场景,建议虚拟入湖;在要求历史数据、大批量数据且实时性要求不高的场景,可以物理入湖。
虚拟入湖由数据代表实施,数据代表负责设计和部署虚拟表。 物理入湖由对应数据湖的IT代表承接IT实施需求,设计集成方案和数据质量监测方案,实施数据入湖。数据代表组织UAT测试、上线验证。
4. 注册元数据
元数据是公司的重要资产,是数据共享和消费的前提,为数据导航和数据地图建设提供关键输入。对元数据进行有效注册是实现上述目的的前提。
虚拟表部署完成后或IT实施完成后,由数据代表检查并注册元数据,元数据注册应遵循企业元数据注册规范。
05 非结构化数据入湖
1. 非结构化数据管理的范围
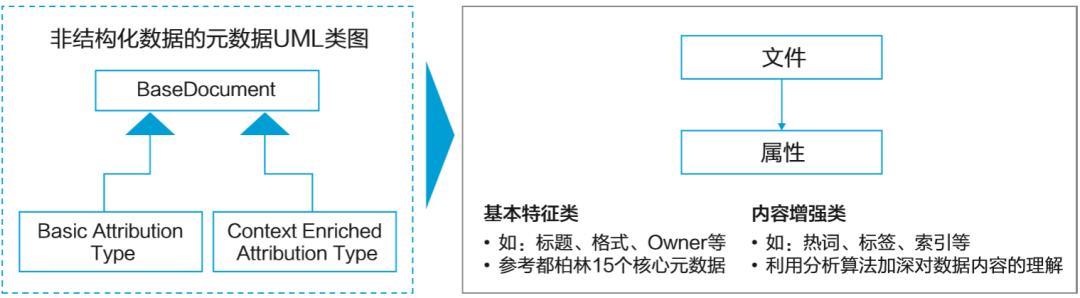
非结构化数据包括无格式的文本、各类格式的文档、图像、音频、视频等多样异构的格式文件。相较于结构化数据,非结构化数据更难以标准化和理解,因而非结构化数据的管理不仅包括文件本身,而且包括对文件的描述属性,也就是非结构化的元数据信息。
这些元数据信息包括文件对象的标题、格式、Owner等基本特征,还包括对数据内容的客观理解信息,如标签、相似性检索、相似性连接等。这些元数据信息便于用户对非结构化数据进行搜索和消费。非结构化数据的元数据实体如图5-4所示。
▲图5-4 非结构化数据的元数据实体
都柏林核心元数据是一个致力于规范Web资源体系结构的国际性元数据解决方案,它定义了一个所有Web资源都应遵循的通用核心标准。
基本特征类属性由公司进行统一管理,内容增强类属性由承担数据分析工作的项目组自行设计,但其分析结果都应由公司元数据管理平台自动采集后进行统一存储。
2. 非结构化数据入湖的4种方式
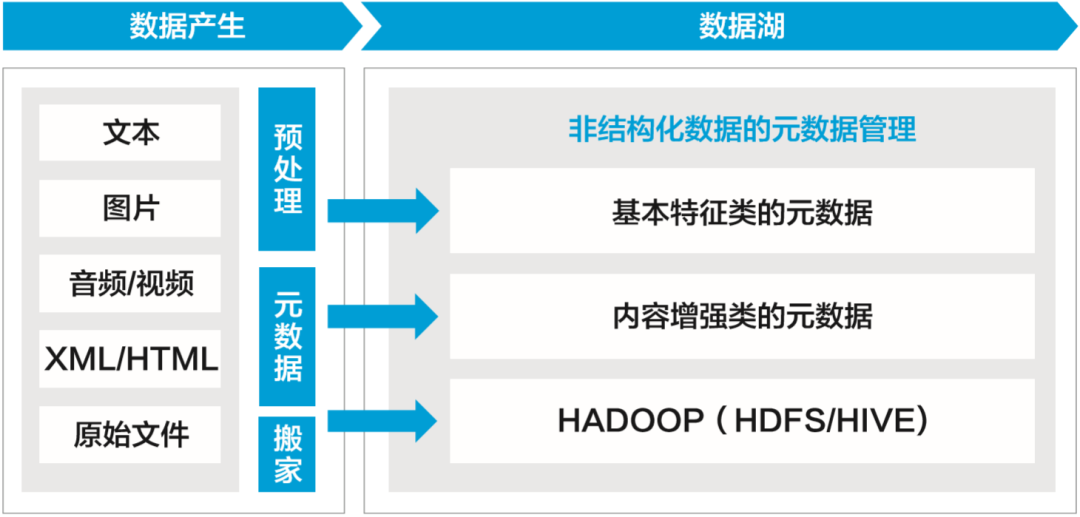
非结构化数据入湖包括基本特征元数据入湖、文件解析内容入湖、文件关系入湖和原始文件入湖4种方式,其中基本特征元数据入湖是必选内容,后面三项内容可以根据分析诉求选择性入湖和延后入湖,如图5-5所示。
▲图5-5 非结构化数据入湖 1)基本特征元数据入湖
主要通过从源端集成的文档本身的基本信息入湖。入湖的过程中,数据内容仍存储在源系统,数据湖中仅存储非结构化数据的基本特征元数据。基本特征元数据入湖需同时满足如下条件。
已经设计了包含基本特征元数据的索引表。 已经设计了信息架构,如业务对象和逻辑实体。 已经定义了索引表中每笔记录对应文件的Owner、标准、密级,认证了数据源并满足质量要求。
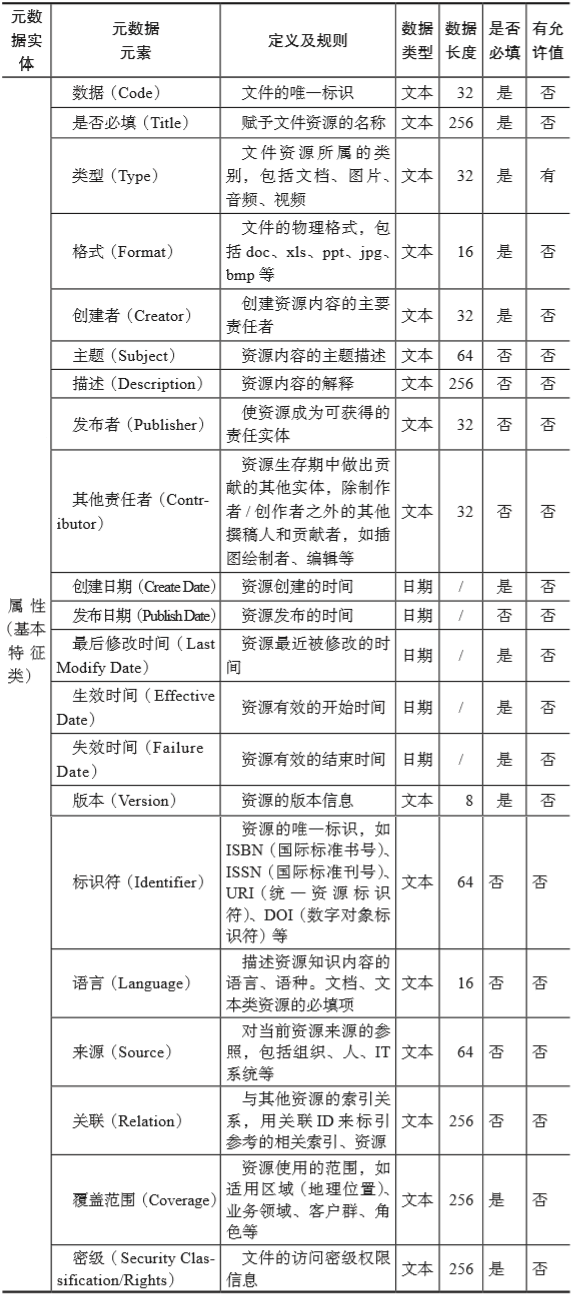
参考都柏林核心元数据,非结构化数据的基本特征类属性元数据规范如表5-4所示。
▼表5-4 非结构化数据的基本特征类属性
2)文件解析内容入湖
对数据源的文件内容进行文本解析、拆分后入湖。入湖的过程中,原始文件仍存储在源系统,数据湖中仅存储解析后的内容增强元数据。内容解析入湖需同时满足如下条件。
已经确定解析后的内容对应的Owner、密级和使用的范围。 已经获取了解析前对应原始文件的基本特征元数据。 已经确定了内容解析后的存储位置,并保证至少一年内不会迁移。
3)文件关系入湖
根据知识图谱等应用案例在源端提取的文件上下文关系入湖。入湖的过程中,原始文件仍存储在源系统,数据湖中仅存储文件的关系等内容增强元数据。文件关系入湖需同时满足如下条件:
已经确定文件对应的Owner、密级和使用的范围。 已经获取了文件的基本特征元数据。 已经确定了关系实体的存储位置,并保证至少一年内不会迁移。
4)原始文件入湖
根据消费应用案例从源端把原始文件搬入湖。数据湖中存储原始文件并进行全生命周期管理。原始文件入湖需同时满足如下条件。
已经确定原始文件对应的Owner、密级和使用的范围。 已经获取了基本特征元数据。 已经确定了存储位置,并保证至少一年内不会迁移。 |


【本文地址】
今日新闻 |
推荐新闻 |