协处理器和 Rollup |
您所在的位置:网站首页 › 区块链中心化计算与处理模式核心是什么 › 协处理器和 Rollup |
协处理器和 Rollup
|
20 世纪 70 年代至 80 年代,计算技术发展迅速(微处理器中的晶体管数量在此期间从约 1,000 个增加到约 1,000,000 个)。但这种增长并不意味着人们经常购买或更新他们的计算机。由于智能合约平台受到最慢节点的限制,计算机前沿的加速不一定会导致区块链的计算速度成比例增加。只有更新区块链上节点的基准要求,才能实现加速。
不断更新节点的最低硬件要求和去中心化之间也存在明显的权衡。单独的质押者可能不想每隔几年升级一次硬件(他们当然不想每天监控性能),导致只有专业人士想要运行区块链基础设施。
所有这一切都表明,这些年来,CPU 得到了改进,我们在每台设备上获得了更多的 CPU 核心,使我们能够执行逐渐复杂的任务。如果我们认为区块链计算机的速度不会像传统计算一样快(由于基准节点要求),那么尝试寻找替代计算源是有意义的。这里有一个有趣的类比,传统计算中的 CPU 并不擅长图形处理任务,导致几乎每台计算机中 GPU 的兴起。同样,由于区块链专注于成为启用简单计算电池的安全状态存储,因此链下计算显然有机会扩展应用程序设计空间。如今,区块链仅对需要开放访问、自我主权、审查阻力和可组合性等属性的低计算应用程序有意义。为了将更多种类的应用程序放到链上,我们需要解除对应用程序开发人员的限制。我们这么说的前提是,这些限制也有利于实验。例如,由于计算限制,CLOB 无法在以太坊上有效运行,因此采用了 AMM,其交易量已达到一万亿美元。 有两种常见方法可以为区块链应用程序提供更多计算能力: 相对频繁地增加基线节点要求。这大致就是 Solana 和 Sui 等集成高性能区块链所采取的路径。节点的高基线使它们能够构建非常快速的区块链,并且还消除了应用程序设计中的一些设计限制。Phoenix是 Solana 上的限价订单簿 DEX,目前无法在以太坊(或任何 L2)上构建。不断增加的基线要求的另一面是,如果它们不断增长,那么运行节点可能只对专业基础设施提供商可行。历史 RAM 需求很好地展示了 Solana 上的硬件需求如何持续增长:网络存档(注意:我们使用 2020 年的 RAM 需求中位数)将计算转移到链下第三方。这是以太坊生态系统采取的策略。这些第三方本身可以是区块链(在汇总的情况下)、链下可验证计算设备(即协处理器)或可信第三方(如 dydx 订单簿等特定于应用程序的链下计算的情况)。 迈向链下计算的统一 最近,关于协处理器的讨论有所增加,它提供链下可验证计算。协处理器可以通过多种方式实现,包括但不限于零知识证明或可信执行环境(TEE)。一些例子是: ZK 协处理器:Axiom、Risc Zero 的 Bonsai。 TEE:马林牡蛎同时,在卸载计算方面,以太坊以rollup为中心的路线图将计算卸载到以太坊上的各种汇总。在过去的几年里,由于 Rollups 提供了更便宜、更快的交易和激励措施,不断有开发人员和用户迁移到 Rollups。在理想的世界中,rollup 允许以太坊通过链下执行来扩展其整体计算能力,而无需添加信任假设。更多计算不仅仅指执行更多事务,还指对每个事务进行更具表现力的计算。新的事务类型扩展了应用程序可用的设计空间,更高的吞吐量降低了执行这些表达性事务的成本,确保以经济实惠的方式访问更高级别的应用程序。 在进一步讨论之前,让我们简要定义一下汇总和协处理器,以防止混淆: Rollups:Rollups 维护与其基础/主机链不同的持久的分区状态,但仍然通过向其发布数据/证明来继承其基础的安全属性。通过将状态移出主机链,汇总可以在将这些状态转换的完整性证明发布到主机之前使用额外的计算来执行状态转换。对于不想支付以太坊高额费用但想要访问以太坊安全属性的用户来说,Rollup 最为有用。 在深入探讨协处理器之前,让我们先了解一下目前以太坊上智能合约开发的局限性。以太坊在其全局状态中具有持久状态存储 - 账户余额、合约数据等。这些数据无限期地保留在区块链上。但是,也有一些限制: 合约数据的最大大小是有限的(例如,当前每个合约为 24KB,并在 EIP 170 中设置)。存储大文件会超出这个范围。(*协处理器也无法解决)
读/写合约存储比文件系统或数据库慢。访问 1KB 的数据可能会花费数百万的 Gas。当全局状态持续存在时,各个节点仅以“修剪”模式在本地保留最近的状态。完整的状态历史记录需要存档节点。没有用于处理图像、音频和文档等文件的本机文件系统原语。智能合约只能将基本数据类型读取/写入存储。 围绕这个问题的解决方案是: 大文件可以分成较小的部分以适应合同存储限制。 文件引用可以存储在链上,文件可以存储在链外系统中,例如 IPFS。协处理器:协处理器本身不维护任何状态;它们的行为类似于 AWS 上的 lambda 函数,应用程序可以向它们发送计算任务,然后它们返回带有计算证明的结果。协处理器从根本上增加了任何给定事务的可用计算量,但由于协处理器上的证明也是在每个事务的基础上进行的,因此使用它们将比汇总更昂贵。考虑到成本,协处理器可能对想要以可验证的方式执行复杂的一次性任务的协议或用户有用。协处理器的另一个好处是,它们允许使用链外计算的应用程序也可以访问以太坊的完整历史状态,而无需向应用程序本身添加任何信任假设;这在今天的普通智能合约中是不可能的。 为了深入了解汇总和协处理器之间的差异,让我们参考这两种原语的 ZK 风格。ZK rollups 可以访问零知识证明的可验证性和压缩方面,从而从根本上提高生态系统的吞吐量。另一方面,协处理器仅访问 zk 证明的可验证性属性,这意味着系统的整体吞吐量保持不变。此外,ZK rollups 需要能够证明任何针对该 rollup 的虚拟机的程序的电路(例如,以太坊上的 rollups 已经为针对 EVM 的合约构建了 zkEVM)。相比之下,ZK 协处理器只需要为它们要执行的任务构建电路。 因此,rollup 和协处理器之间的两个最大区别似乎是: rollup 维护分区持久状态,而协处理器则不维护(它们使用主机链的状态)。 rollup(顾名思义)将多个事务一起批处理,而协处理器通常作为单个事务的一部分用于复杂的任务(至少在当前范例中)。最近,Booster Rollups被提出,它执行交易就像直接在主机链上运行一样,可以访问主机的完整状态。然而,Booster Rollups 也有自己的存储,允许它们跨主机和 Rollup 扩展计算和存储。Booster Rollup 提案指出了链外计算设计范围中存在一个频谱,传统的 Rollup 和协处理器位于该频谱的两端。Rollups、Booster Rollups 和 Coprocessors 都提供对更多计算的访问,唯一的区别在于它们保留了从基础 L1 分区的状态量。 在 2023 年模块化峰会上的一次名为“屏蔽交易是rollup”的演讲中,Henry De Valence 谈到了这个确切的概念,并提出了一个非常简单的图像来定义rollup: 该演讲假设基础链卸载给第三方的任何执行都是rollup。根据他的定义,协处理器也将是rollup。这与我们在链下可验证计算的旗帜下统一rollup和协处理器的观点略有不同,但总体情绪保持不变! 在他的Endgame愿景中,Vitalik 讨论了区块生产中心化、区块验证不信任且高度去中心化的未来。我们相信,这大致是思考现在正在发生的事情的正确模型。在 zk-rollup 中,区块生产和状态转换计算是中心化的。然而,证明使得验证变得廉价且去中心化。类似地,zk 协处理器没有区块生产;它仅访问历史数据并计算该数据的状态转换。zk 协处理器上的计算可能总是在中心化机器上执行;尽管如此,随结果一起返回的有效性证明允许任何人在使用结果之前验证它们。也许将 Vitalik 的愿景重述为正确的:“未来计算是中心化的,但中心化计算的验证是去信任的且高度去中心化的。” 相识又有差别 尽管总体上很相似,但rollup和协处理器如今服务于截然不同的市场。有人可能会问,“如果我们可以在 ETH L1 上使用协处理器并获得其流动性,为什么我们需要rollup?” 虽然这是一个公平的问题,但我们认为有几个原因可以解释为什么rollup仍然有意义(并且提供了比当今协处理器更大的市场机会): 如前所述,协处理器允许您在同一事务中访问比 L1 更多的计算。但它们无助于改变调用协处理器的区块链可以执行多少交易(如果您正在考虑批处理,瞧,您已经到达了rollup)。通过维护分区持久状态,rollup可以增加想要访问具有以太坊安全属性的块空间的人可用的交易数量。这是可能的,因为汇总仅每 n 个区块发布到以太坊,并且不需要所有以太坊验证器来验证状态转换是否发生。有兴趣的人可以依靠证据。 即使您使用协处理器,您仍然需要支付与 L1 上任何其他交易相同数量级的费用。另一方面,通过批处理进行rollup可以将成本降低几个数量级。此外,由于rollup提供了在这种单独状态上运行事务的能力,因此它们的行为仍然像区块链(更快、去中心化程度较低的区块链,但仍然是区块链),因此它们对于可以从汇总访问的计算量也有明确的限制本身。在这种情况下,如果用户想要执行任意复杂的事务,则协处理器对于rollup非常有用(现在您正在rollup上执行可验证的事务,因此您只需遵守rollup的物理定律)。 这里需要注意的另一个要点是,目前大部分流动性都驻留在 ETH L1 上,因此对于许多依赖流动性来改进其产品的协议来说,仍然在以太坊主网上启动可能是明智的选择。以太坊主网上的应用程序可以通过在协处理器上间歇性地执行事务来访问更多计算。例如,像 Ambient 或 Uniswap v4 这样的 DEX 可以使用钩子与协处理器来执行复杂的逻辑,以决定如何更改费用,甚至根据市场数据修改流动性曲线的形状。
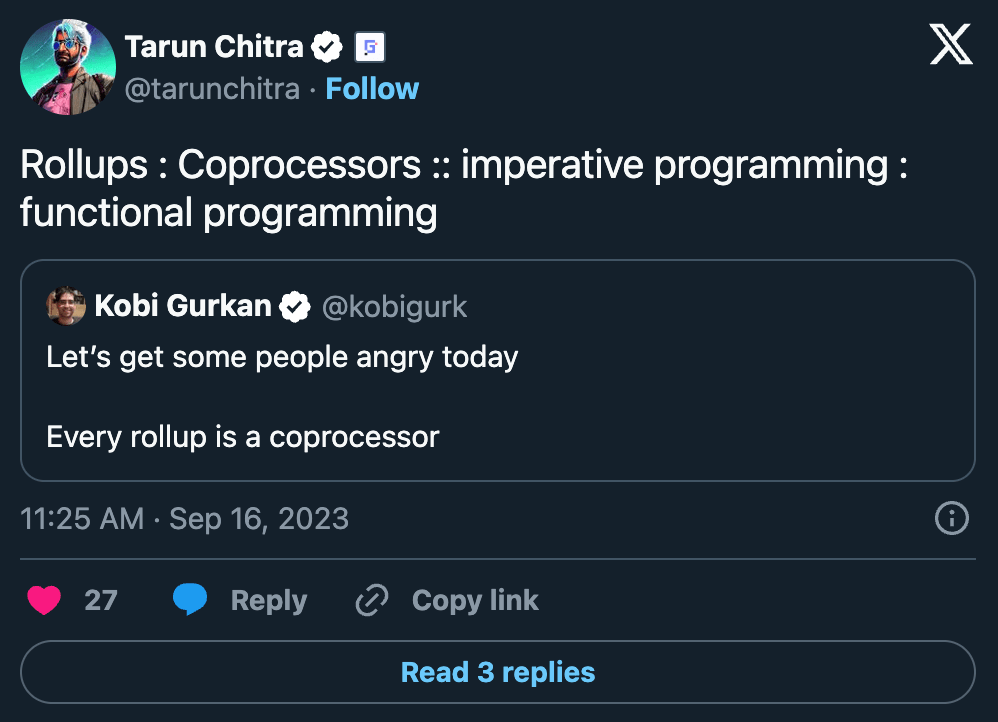
一个有趣的类比将rollup和协处理器之间的相互作用与命令式编程和函数式编程进行了比较。命令式编程侧重于可变状态和副作用,指定逐步执行任务的方式。函数式编程强调不可变数据和纯函数,避免状态变化和副作用。同样,rollup就像修改它们所持有的状态的命令式程序,而协处理器就像函数式程序,它们不会改变状态,但会生成结果以及计算证明。此外,就像命令式编程和函数编程一样,rollup和协处理器也有其用武之地,并且应该相应地使用。 基于证据的未来 如果我们最终进入一个计算中心化的世界,但中心化计算的验证是无需信任且高度去中心化的,那么以太坊将走向何方?世界计算机会被简化为一个数据库吗?这是坏事吗? 最终,以太坊的目标是让用户能够访问无需信任的计算和存储。过去,在以太坊上访问免信任计算的唯一方法是由所有节点执行和验证计算。随着证明技术(尤其是零知识证明)的进步,我们可以将验证器节点上发生的大部分计算转移到链外计算,而只让验证器在链上验证结果。这本质上将以太坊变成了世界上不可变的公告板。计算证明使我们能够验证交易是否正确完成,并且通过将它们发布到以太坊,我们可以获得这些证明的时间戳和不可变的历史存储。随着零知识证明在任意计算上变得更加高效,在某些时候,在 ZK 中进行计算的成本可能会大大低于在区块链(甚至可能是 100 个验证者的 CometBFT 链)上进行计算的成本。在这样的世界中,很难想象 ZK 证明不会成为访问去信任计算的主导模式。David Wong 最近也表达了类似的想法:
未来任何计算都可以被证明,这也使我们能够为有用户需求的各种无需信任的应用程序构建基础设施,而不是试图改造以太坊基础层以成为这些应用程序的家园。在理想情况下,定制的基础设施将创造更加无缝的用户体验,并且还将随着构建在其之上的应用程序进行扩展。这有望让 web3 应用程序能够与 web2 应用程序竞争,并迎来密码朋克们一直梦想的去信任的、基于证据的未来。 总而言之,我们相信我们正在朝着以下范式迈进: ——————————不要信任,要验证—————————— 返回搜狐,查看更多 |

【本文地址】
今日新闻 |
推荐新闻 |