分布式架构最全详解(万字图文总结) |
您所在的位置:网站首页 › 前端部署架构设计 › 分布式架构最全详解(万字图文总结) |
分布式架构最全详解(万字图文总结)
|
分布式架构
分布式架构是指将系统的各个组件和服务分布在多台独立的计算机节点上,通过网络进行通信和协作,以实现高性能、高可用性和可伸缩性的系统架构。 分布式架构在现代计算系统中发挥着重要的作用,其主要功能和作用包括: 1.提高性能 分布式架构将系统的负载分布到多个节点上,可以实现并行处理和负载均衡。 通过并行处理,系统可以同时处理多个请求或任务,提高系统的处理能力和响应速度。 2.提高可用性 分布式架构通过将系统的服务和数据分布在多个节点上,实现了冗余备份和故障恢复机制。 即使某个节点发生故障,其他节点仍然可以继续提供服务,确保系统的可用性,通过增加节点的数量,可以进一步提高系统的可用性和容错性。 3.实现可伸缩性 分布式架构可以根据负载变化自动扩展或缩减节点的数量,实现系统的可伸缩性。 当负载增加时,可以动态添加更多节点来分担压力,当负载减少时,可以缩减节点数量以降低成本。 4.支持大规模数据处理 分布式架构可以处理大规模的数据集和复杂的计算任务,通过将数据分布在多个节点上,可以实现数据的并行处理和分布式计算。 分布式架构分类常见的分布式架构包括微服务架构、分布式数据库系统、分布式存储系统等。 1.微服务架构微服务架构的核心要素在于服务的发现、注册、路由、熔断、降级、分布式配置。 比如:以Spring Cloud为代表的微服务框架,都会实现以上的微服务组件。 目前国内企业使用的微服务架构:主要是: Spring CloudSpring Cloud AlibabaServiceMesh这三套Spring Cloud体系包含如下:
Spring Cloud Alibaba是阿里研发的一套微服务架构的落地技术方案,可以很好的兼容SpringCloud,可以简要理解为Spring Cloud的升级版。 Spring Cloud Alibaba体系包含如下图所示:
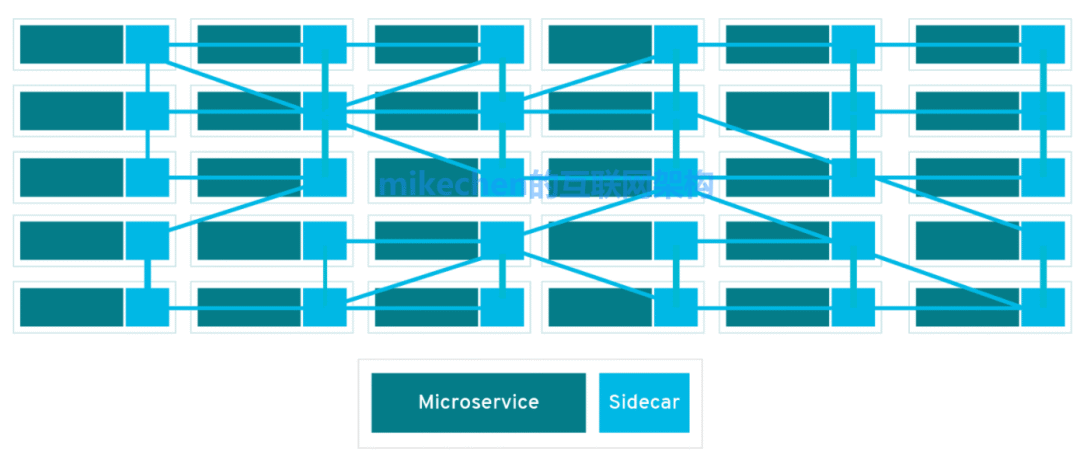
Service Mesh,是一个形象化的词语表达:Service(服务)和Mesh(网格),它描述了服务间的依赖形态,就像下面这张网一样。
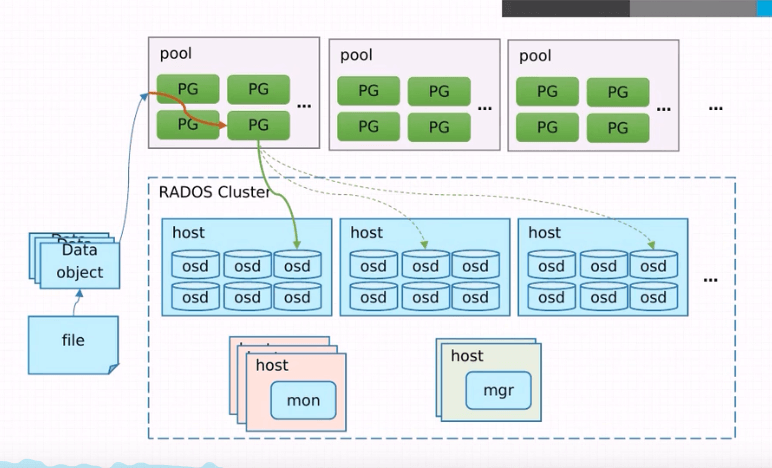
分布式数据库,从名字上可以拆解为:分布式+数据库,由多个独立实体组成,并且彼此通过网络进行互联的数据库,这就是分布式数据库。 市面上分布式数据库产品分成几大类: 1.物联网方向 时序数据库产品,满足IoT数据的收集、存储和统计,常见的有:InfluxDB、Kudu、kdb、OpenTSDB等。 2.交易关系方向 替代传统交易关系型数据库产品Oracle,DB2等满足不了海量吞吐、海量并发、海量交易、海量存储的在线交易业务场景。 例如: 蚂蚁金服Oceanbase;腾讯TDSQL;热璞HotDB;中兴GoldenDB等;3.分析关系方向 解决结构化数据存储和数据分析的业务场景,不过这块收到KV分析型产品巨大的冲击。 常见的有: Greenplum;Vertical;Gbase8a等;4.KV分析方向 Hadoop、Spark是当下的基石,国内国外较多公司都是在其基础上再做二次研发,尤其是实现兼容SQL标准语法。 5.KV文档方向 解决在线文档类型的非结构化数据存储、数据处理,都在努力兼容SQL标准语法。 常见的有: MongoDB;巨衫SequoiaDB等;6.HTAP方向 随着分布式数据库的发展,我们又迎来了新的一次融合,那就是 OLTP 与 OLAP 将再一次合并为 HTAP(融合交易分析处理)数据库。 常见的分布式数据库有: 谷歌Spanner谷歌F1;CockroachDB;国内TiDB; 3.分布式存储系统常见的分布式文件系统包括:HDFS、Ceph、GlusterFS、FastDFS等。 1.HDFS HDFS,全称Hadoop Distributed File System ,HDFS是Hadoop生态系统中的分布式文件系统,用于存储海量数据和支持大规模数据处理。 2.Ceph Ceph是一种分布式存储系统,具有高可扩展性、高可靠性和高性能等特点。 Ceph架构,如下图所示:
3.GlusterFS
GlusterFS是一种基于用户空间的分布式文件系统,可以将多个服务器或节点组成一个文件系统。 4.分布式计算分布式计算是指,利用多个计算机或处理器共同处理一个计算任务。 将任务分解为多个子任务,由不同的计算机或处理器分别处理这些子任务,最后将处理结果进行合并,从而完成整个计算任务的过程。 有很多分布式计算产品可供选择,以下是一些常见的分布式计算产品: 1.Apache Hadoop 一个开源的分布式计算平台,用于处理大规模的数据集,它采用分布式文件系统和MapReduce计算模型,适用于大数据处理和分析。 2.Apache Spark Spark是一个开源的快速通用的分布式计算引擎,支持高级数据分析和机器学习,它采用内存计算和弹性分布式数据集,适用于实时数据处理和复杂的计算任务。 3.TensorFlow 一个开源的机器学习框架,支持分布式计算和GPU加速,适用于深度学习和其他复杂的数学计算任务。 4.Apache Flink 一个开源的流处理和批处理框架,支持分布式计算和低延迟数据流处理,适用于实时数据处理和批处理任务。 5.Apache Storm 一个开源的分布式实时计算系统,适用于实时数据处理和流数据分析。 6.Amazon EC2 亚马逊云计算服务中的一种,提供弹性计算、存储和网络服务,支持多种计算实例类型,包括分布式计算实例,适用于大规模计算和分析任务。 5.分布式通信分布式通信是指分布式系统中各个节点之间进行数据交换和协作的过程。 比如:典型的RPC框架就是典型的分布式通信。 RPC框架比较出名的有google的gRPC,facebook的thrift,也及阿里的Dubbo。 Dubbo主要包含如下几个核心组件:
Thriftt是一个RPC框架(RPC是远程过程调用),与Dubbo类似,最初由Facebook开发,后面进入Apache开源项目。 Thrift架构,如下图所示:
gRPC由Google开发的高性能RPC框架,使用Protocol Buffers进行序列化,支持多种编程语言。 6.负载均衡负载均衡是一种在计算机网络和系统架构中使用的技术,用于均衡分发工作负载到多个资源,比如:服务器、计算节点或存储设备上,以提高系统的性能、可伸缩性。 如下图所示:
负载均衡主要分为:二层、三层、四层、以及七层负载均衡。
1.二层负载均衡(mac) 根据OSI模型分的二层负载,一般是用虚拟mac地址方式,外部对虚拟MAC地址请求,负载均衡接收后分配后端实际的MAC地址响应)。 2.三层负载均衡(ip) 一般采用虚拟IP地址方式,外部对虚拟的ip地址请求,负载均衡接收后分配后端实际的IP地址响应。 3.四层负载均衡(tcp) 四层的负载均衡就是基于IP 端口的负载均衡,在三次负载均衡的基础上,用ip port接收请求,再转发到对应的机器。 实现四层负载均衡的软件有: F5:硬件负载均衡器,功能很好,但是成本很高。lvs:重量级的四层负载软件nginx:轻量级的四层负载软件,带缓存功能,正则表达式较灵活haproxy:模拟四层转发,较灵活4.七层负载均衡(http) 七层的负载均衡,就是基于虚拟的URL或主机IP的负载均衡,根据虚拟的url或IP,主机名接收请求,再转向相应的处理服务器。 实现七层负载均衡的软件有: haproxy:天生负载均衡技能,全面支持七层代理,会话保持,标记,路径转移;nginx:只在http协议和mail协议上功能比较好,性能与haproxy差不多;apache:功能较差Mysql proxy:功能尚可。总的来说,一般是lvs做4层负载;nginx做7层负载。 7.分布式安全分布式架构需要考虑数据和通信的安全性,安全机制包括身份认证、访问控制、数据加密、安全传输协议等,以保护数据的机密性、完整性和可用性。 8.分布式事务分布式事务是指涉及多个计算机,或进程的一系列操作,这些操作需要保证在所有节点上的一致性和原子性。 如下图所示: 上图一次大的事务操作,由不同的小事务操作组成,这些小事务的操作分布在不同的服务器上,这些操作要么全部成功,要么全部失败。 |








【本文地址】
今日新闻 |
推荐新闻 |