KNN算法介绍及案例 |
您所在的位置:网站首页 › 分类算法有哪些实际案例分析题 › KNN算法介绍及案例 |
KNN算法介绍及案例
|
目录
一、KNN介绍K-近邻(K-Nearest Neighboor)算法定义理解K近邻总结KNN⼯作流程
二、案例实现
作为机器学习中最基础的算法,KNN在简单分类问题上有其独特的优势,其理念类似于中国的成语“近朱者赤,近墨者黑”,这种将特征数字转化为空间距离判断的方法也是我们认识机器学习世界的第一步。 一、KNN介绍 K-近邻(K-Nearest Neighboor)算法定义如果⼀个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别。 理解K近邻已知《战狼》《红海⾏动》《碟中谍 6》是动作⽚,⽽《前任 3》《春娇救志明》《泰坦尼克号》是爱情⽚。但是如果⼀旦现在有⼀部新的电影《美⼈⻥》,有没有⼀种⽅法让机器也可以掌握⼀个分类的规则,⾃动的将新电影进⾏分类? 1、下面介绍鸢尾花分类案例,这个案例也是机器学习中的一个经典案例,它的数据集内置于sklearn库中,可以直接导入使用。 from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.neighbors import KNeighborsClassifie # 1.获取数据集 iris = load_iris() # 数据集特征名称 print(iris.feature_names)输出: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']鸢尾花有四个特征,sepal length、sepal width、petal length、petal width。 2、将数据集划分为训练集和测试集,按7:3的比例划分,并将训练集和测试集的特征数据进行标准化。 # 2.数据预处理 # 2.1 数据分割 x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=2) # 2.2 标准化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test)3、实例化分类器,使用交叉验证网格搜索,进行模型训练 # 3.模型训练 # 3.1 实例化分类器 estimator = KNeighborsClassifier(n_neighbors=9) # 3.2 使用交叉验证网格搜索 # estimator-->分类器 # param_grid-->指定的数据 # cv=5-->5折交叉验证 params_grid = {"n_neighbors":[1,3,5,7,9,11]} estimator = GridSearchCV(estimator,param_grid=params_grid,cv=5) # 3.3 模型训练 estimator.fit(x_train,y_train)4、对模型进行评估,传入测试集数据,预测出来的结果跟实际的测试集结果和真实结果进行比较。 # 4.模型评估 # 4.1 传入测试集数据 预测出来的结果跟实际的测试集结果和真实结果 y_pre = estimator.predict(x_test) print(y_pre) print(y_test)输出结果,感觉效果还可以: [0 0 2 0 0 2 0 2 2 0 0 0 0 0 2 1 0 1 2 1 2 1 2 1 2 0 0 2 0 2 2 0 1 2 1 0 2 1 1 2 1 1 2 1 0] [0 0 2 0 0 2 0 2 2 0 0 0 0 0 1 1 0 1 2 1 1 1 2 1 1 0 0 2 0 2 2 0 1 2 1 0 2 1 1 2 1 1 2 1 0]5、计算预测结果的准确率。 # 4.2 输出准确率 注意:X-->测试集特征 y-->测试集真实结果 ret = estimator.score(x_test,y_test) print("准确率:",ret)输出结果,准确率约为93.33%,效果不错。 准确率:0.93333333333333336、查看最好的模型、最好的得分、最好的结果。 print('最好的模型:',estimator.best_estimator_) print('最好的得分:',estimator.best_score_) print('最好的结果:',estimator.cv_results_)输出结果,可以看到k折交叉验证中n_neighbors=11时模型效果最好,最好的得分为95.23%,最好的结果,emmm……,看不懂,别管他了,就是训练后的一些参数之类的。 最好的模型:KNeighborsClassifier(n_neighbors=11) 最好的得分:0.9523809523809523 最好的结果:{'mean_fit_time': array([0.00159645, 0.00079775, 0.00059829, 0.00079808, 0.00039959, 0.00079002]), 'std_fit_time': array([0.00079751, 0.00039888, 0.0004885 , 0.00039904, 0.0004894 , 0.00039527]), 'mean_score_time': array([0.00299163, 0.00279202, 0.00199509, 0.00179429, 0.00160146, 0.0018033 ]), 'std_score_time': array([0.00089207, 0.00159566, 0.00063113, 0.00039838, 0.00049443, 0.00040261]), 'param_n_neighbors': masked_array(data=[1, 3, 5, 7, 9, 11], mask=[False, False, False, False, False, False], fill_value='?', dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 9}, {'n_neighbors': 11}], 'split0_test_score': array([0.85714286, 0.85714286, 0.85714286, 0.9047619 , 0.9047619 , 0.9047619 ]), 'split1_test_score': array([1., 1., 1., 1., 1., 1.]), 'split2_test_score': array([1. , 0.95238095, 0.95238095, 0.95238095, 1. , 1. ]), 'split3_test_score': array([0.80952381, 0.85714286, 0.85714286, 0.9047619 , 0.85714286, 0.9047619 ]), 'split4_test_score': array([0.95238095, 0.95238095, 0.95238095, 0.95238095, 0.95238095, 0.95238095]), 'mean_test_score': array([0.92380952, 0.92380952, 0.92380952, 0.94285714, 0.94285714, 0.95238095]), 'std_test_score': array([0.07737179, 0.05714286, 0.05714286, 0.03563483, 0.05553288, 0.04259177]), 'rank_test_score': array([4, 5, 5, 3, 2, 1])}小伙伴,你学会了吗?扫描下方二维码关注公众号,在后台回复“KNN算法”即可获取源代码。 |
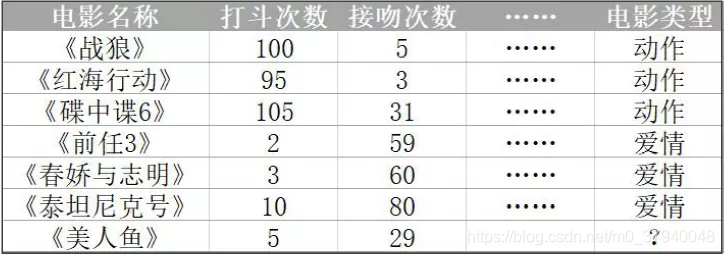 怎么知道《美人鱼》这个点离哪类点的距离最近?——两点距离,
怎么知道《美人鱼》这个点离哪类点的距离最近?——两点距离, 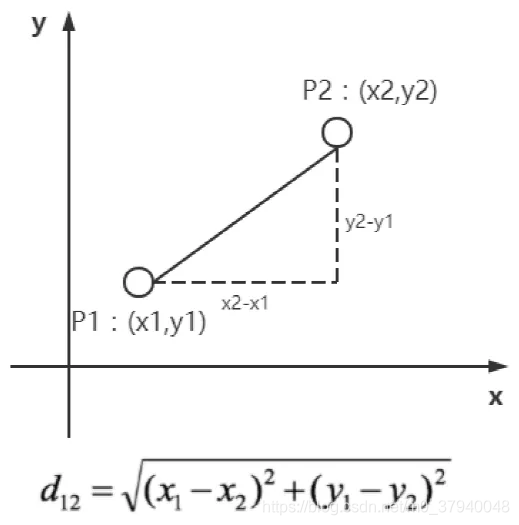 也叫做欧⽒距离,具体如下: 两个⼆维欧⽒距离
也叫做欧⽒距离,具体如下: 两个⼆维欧⽒距离 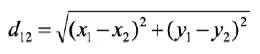
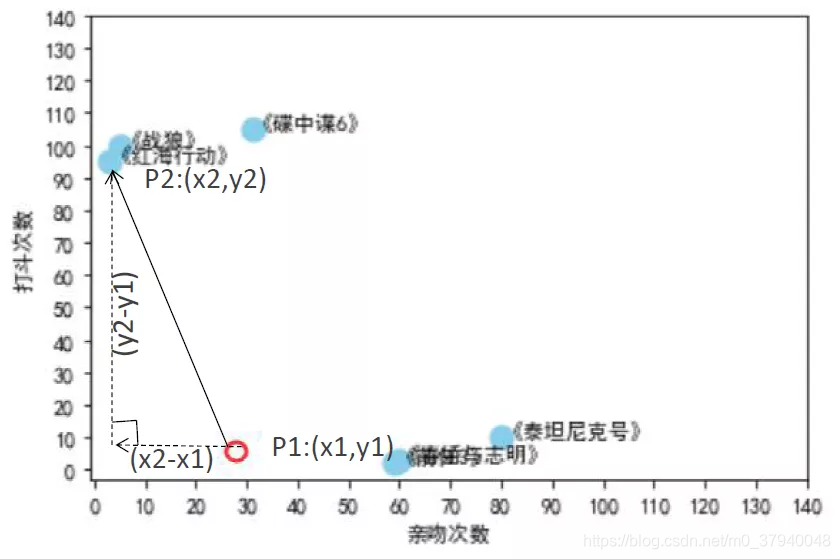 因此,需要计算《美人鱼》与每个电影的距离
因此,需要计算《美人鱼》与每个电影的距离 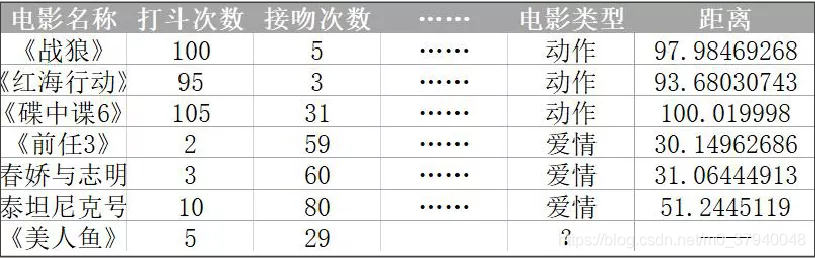 那只找⼀个最邻近的邻居即可判断《美⼈⻥》的类型吗?并不能,举个栗⼦如下,如果只找一个最近邻,那么Amy同学属于哪个区?
那只找⼀个最邻近的邻居即可判断《美⼈⻥》的类型吗?并不能,举个栗⼦如下,如果只找一个最近邻,那么Amy同学属于哪个区? 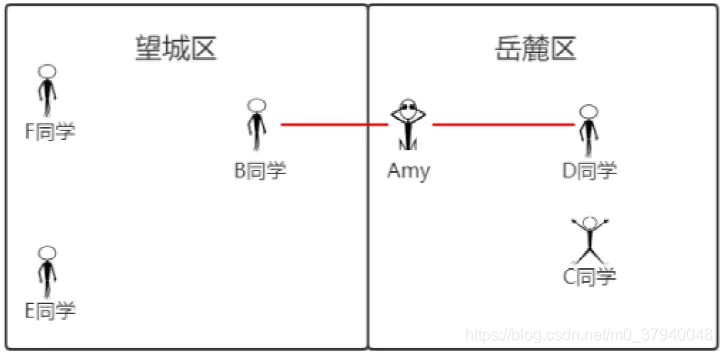 也就是说,应该多找⼏个近邻,才能更加准确的确定其分类。⽐如此处电影分类确定选取3个近邻,也就是说k=3,那么可以判断,《美人鱼》属于爱情片。
也就是说,应该多找⼏个近邻,才能更加准确的确定其分类。⽐如此处电影分类确定选取3个近邻,也就是说k=3,那么可以判断,《美人鱼》属于爱情片。
【本文地址】
今日新闻 |
推荐新闻 |