基于transformer的人群计数论文汇总 |
您所在的位置:网站首页 › 分类汇总的2个步骤是 › 基于transformer的人群计数论文汇总 |
基于transformer的人群计数论文汇总
|
文章目录
2021CCTrans: Simplifying and Improving Crowd Counting with Transformer
2022CCST: Crowd Counting with Swin TransformerSegmentation Assisted U-shaped Multi-scale Transformer for Crowd CountingTransCrowd: weakly-supervised crowd counting with transformersAn End-to-End Transformer Model for Crowd Localization
参考
2021
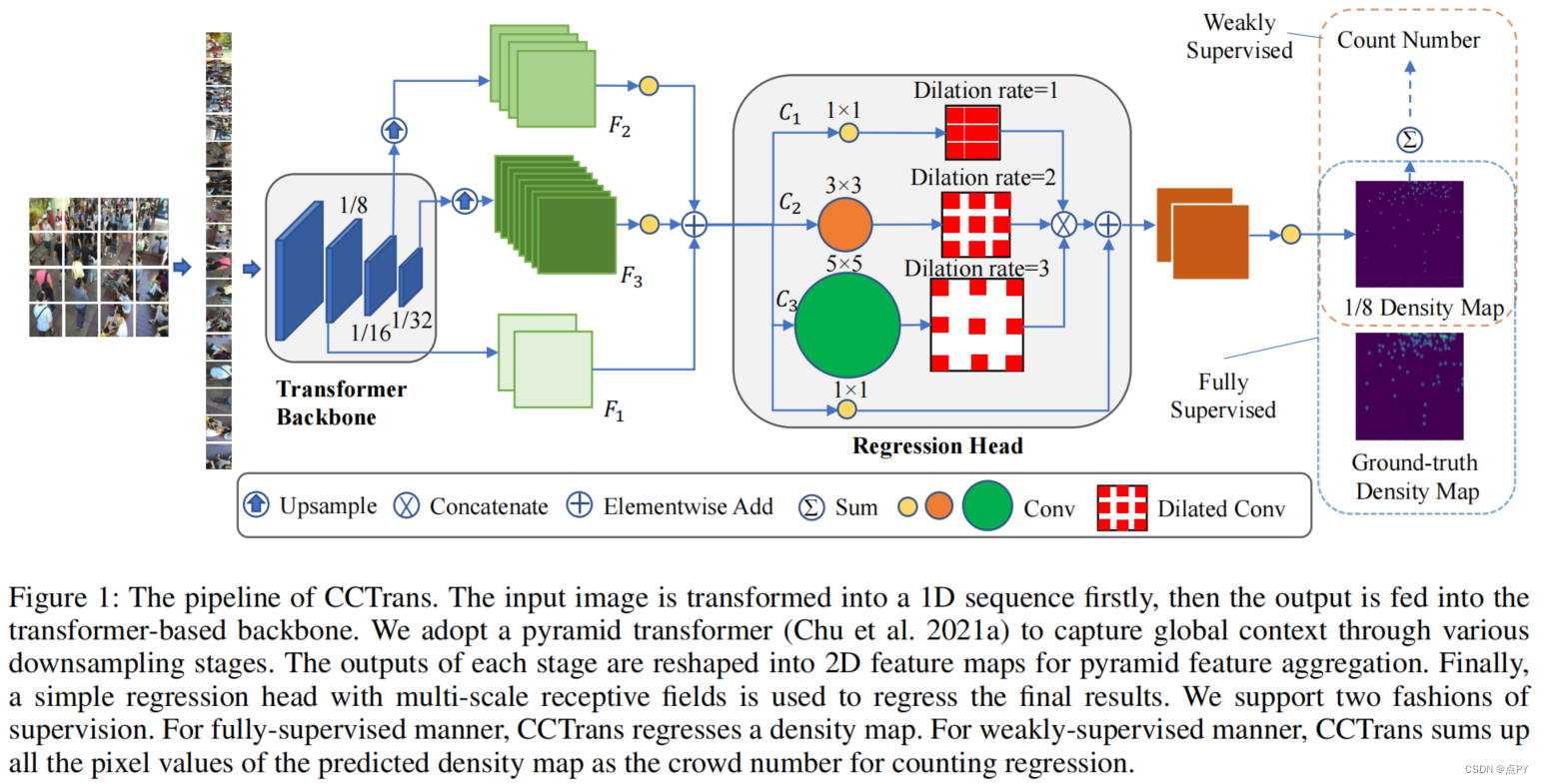
CCTrans: Simplifying and Improving Crowd Counting with Transformer
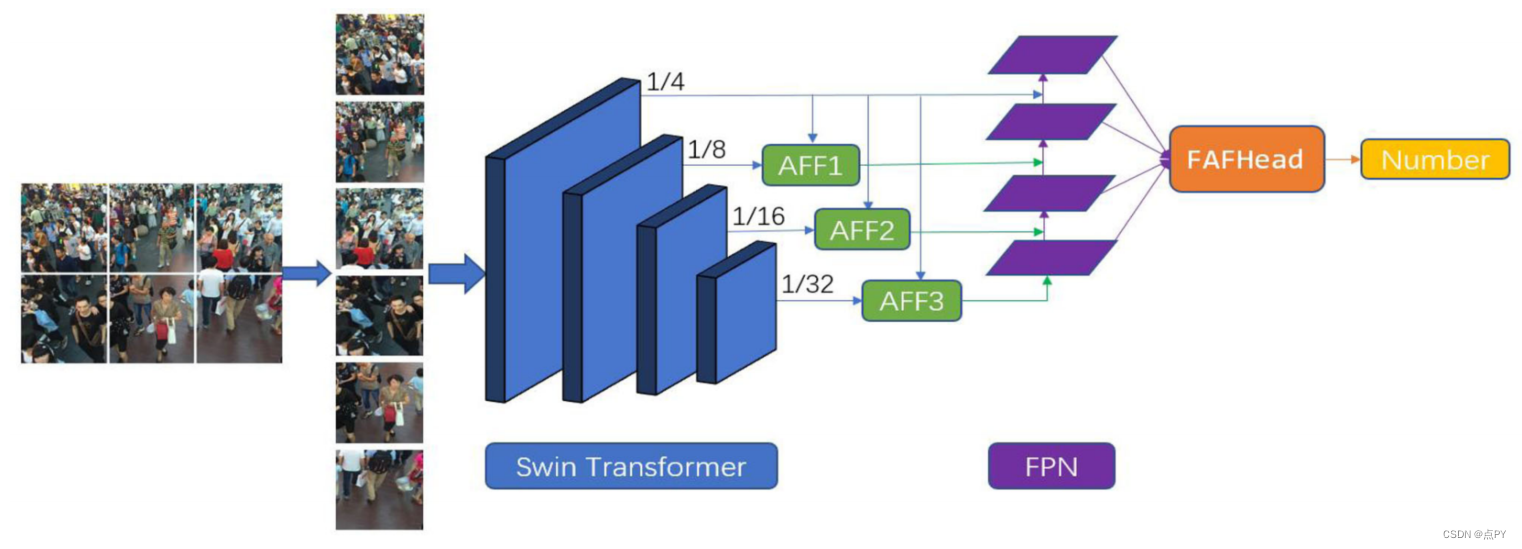
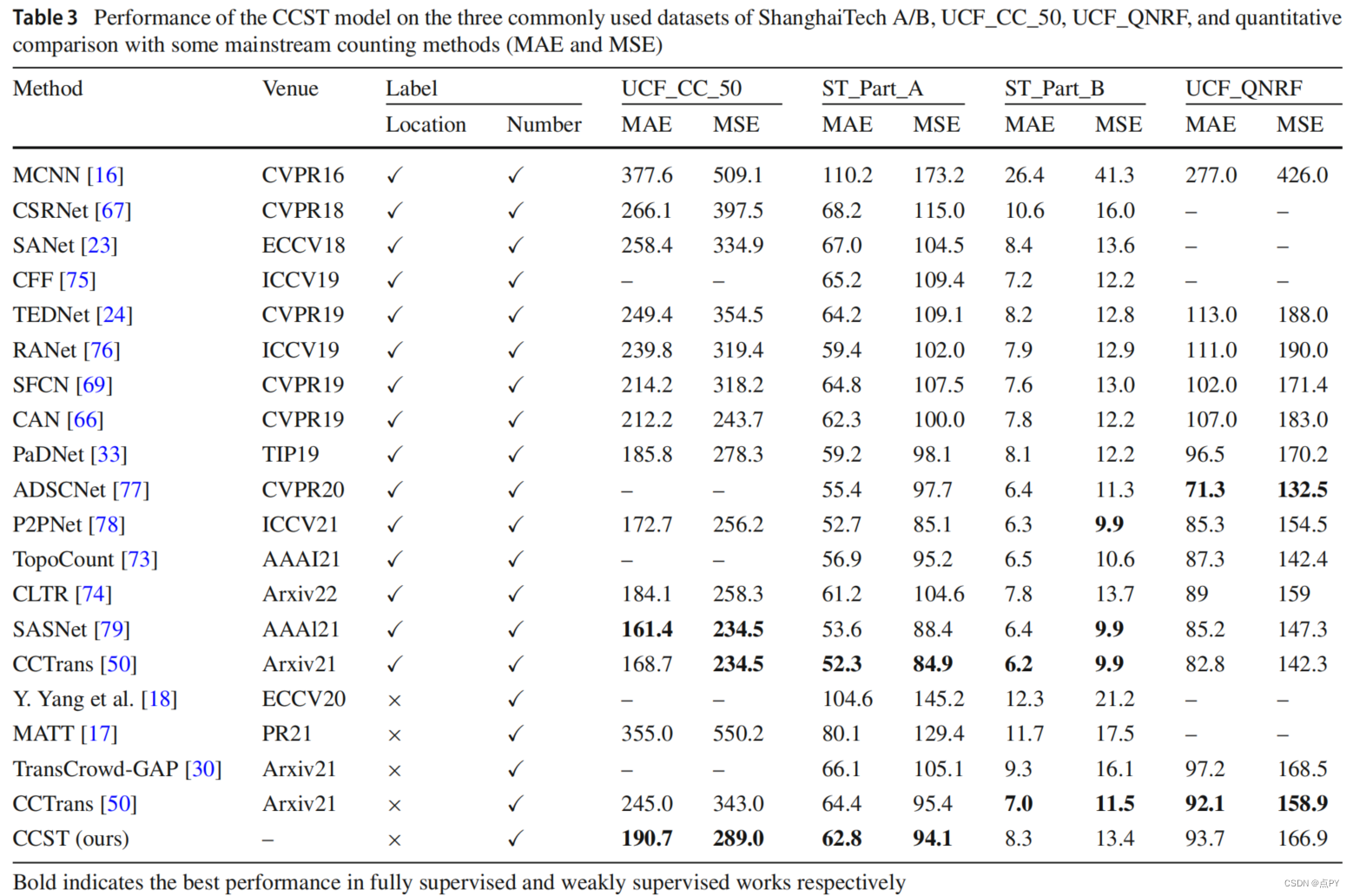
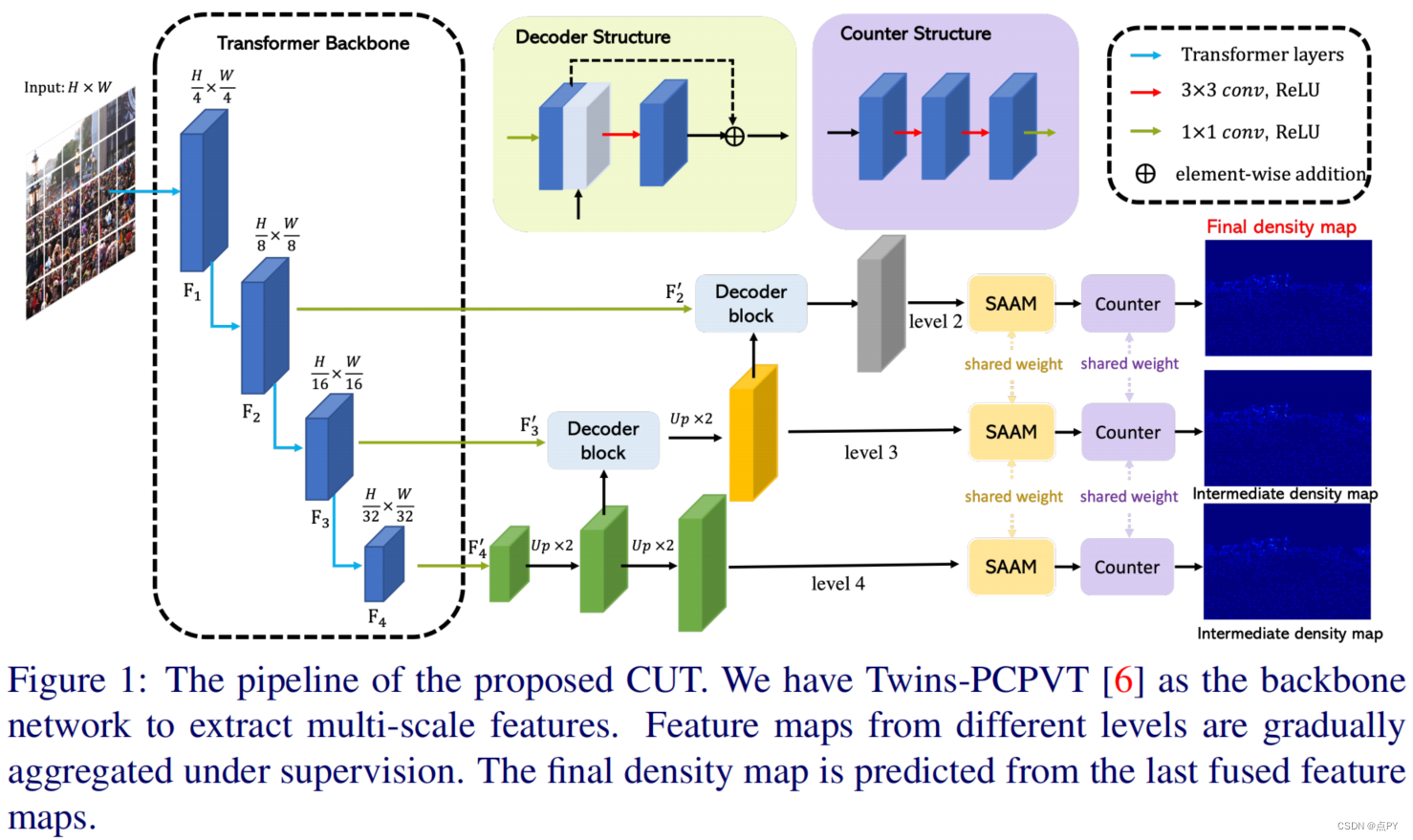
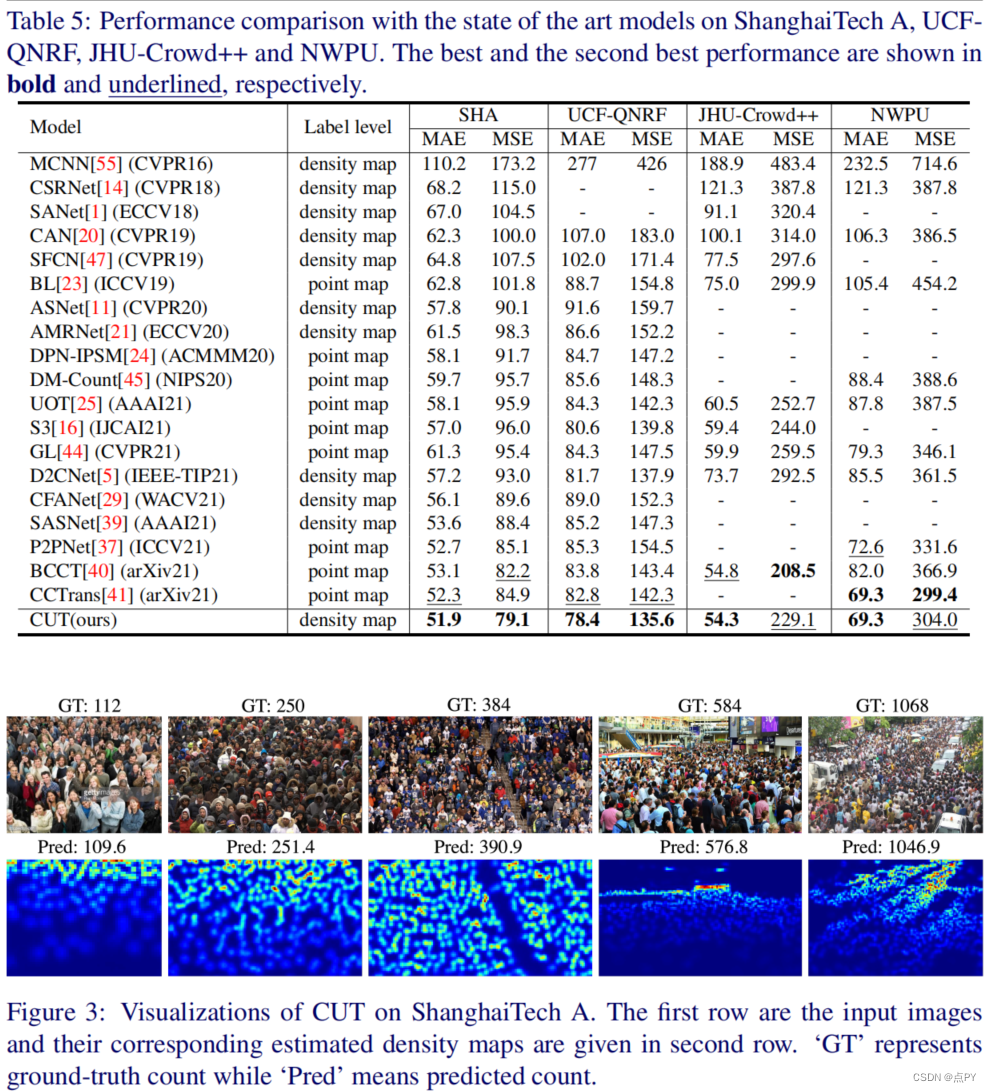
code: https://github.com/wfs123456/CCTrans 摘要:最近大多数用于人群计数的方法都是基于卷积神经网络(CNN),它具有很强的局部特征提取能力。但是,由于有限的接受域,CNN在全局环境建模方面本身就失败了。但是,转换器可以很容易地建模全局上下文。在本文中,我们提出了一种简单的方法CCTrans来简化设计管道。具体来说,我们利用一个金字塔视觉转换器主干来捕获全局人群信息,一个金字塔特征聚合(PFA)模型来结合低级和高级特征,一个有效的回归头与多尺度扩张卷积(MDC)来预测密度图。此外,我们还为我们的管道定制了损失函数。在没有花哨功能的情况下,大量的实验表明,我们的方法在弱监督和完全监督的人群计数的几个基准上取得了新的最先进的结果。此外,我们目前在NWPU-Crowd的排行榜上排名为No. 1。我们的代码将会是可用的。 code: https://github.com/Boli-trainee/CCST-Crowd-Counting-with-Swin-Transformer 摘要:准确估计图像中包含的个体数量是人群计数的目的。它一直面临着两大困难:人群密度分布不均匀和头部尺寸跨度大。针对前者,大多数基于cnn的方法将图像分割成多个斑块进行处理,忽略了斑块之间的连接。对于后者,使用特征金字塔的多尺度特征融合方法忽略了头部大小与层次特征之间的匹配关系。针对上述问题,我们提出了一种基于swin变压器的CCST群体计数网络,并定制了一种特征自适应融合回归头FAFHead。双子变压器可以充分进行块间的信息交换,有效缓解人群密度分布不均匀的问题。FAFHead可以自适应地融合多层次特征,改善了头部尺寸与特征金字塔层次的匹配关系,缓解了头部尺寸跨度大的问题。在普通数据集上的实验结果表明,CCST比所有弱监督计数工作和绝大多数流行的基于密度图的全监督工作具有更好的计数性能。 code: https://github.com/cha15yq/CUT 摘要: 由于网络网络的发展,自动计数在计算机视觉方面取得了显著的进展。然而,这个应用领域遇到了瓶颈,因为cnn由于其性质,受到局部注意的接受域的限制,并且无法建模更大规模的依赖关系。为了解决这个问题,我们引入了一个基于多尺度变压器的人群计数网络,称为人群u变压器(CUT),它从多个层次上提取和聚合语义和空间特征。在这个设计中,我们使用人群分割作为一个注意力模块来获得细粒度的特征。此外,我们提出了一个损失函数,更好地关注计数性能的前景区域。在四个广泛使用的基准上的实验结果被提出,我们的方法显示了最先进的性能。
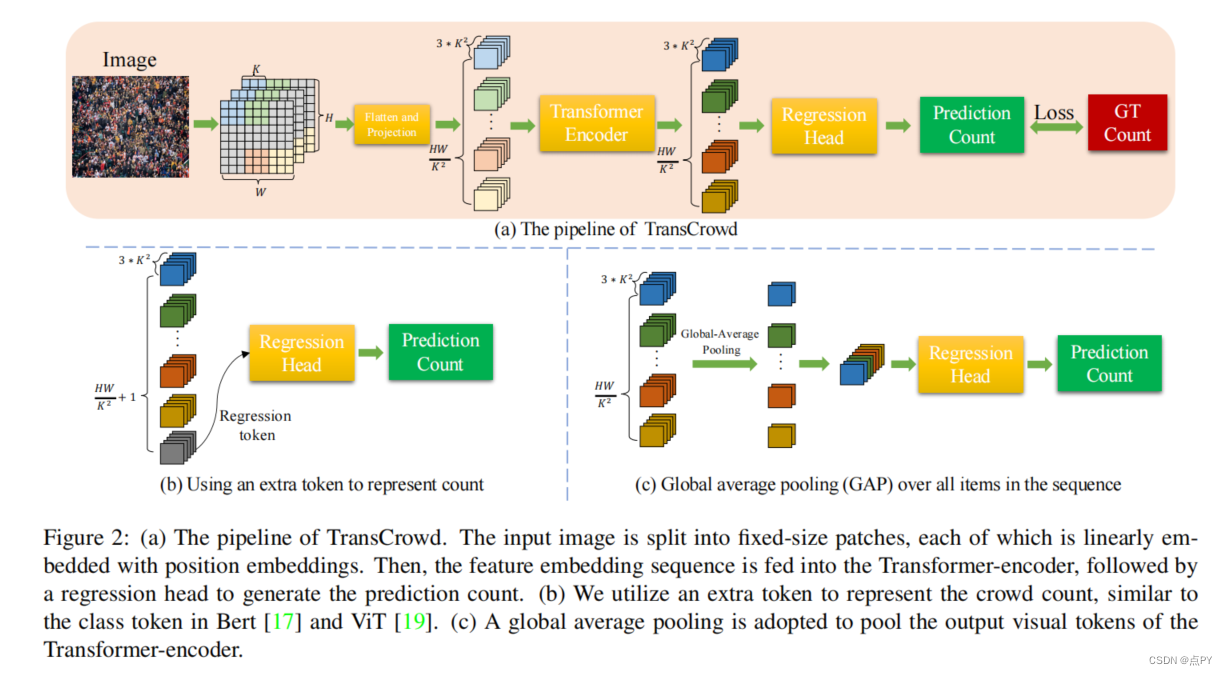
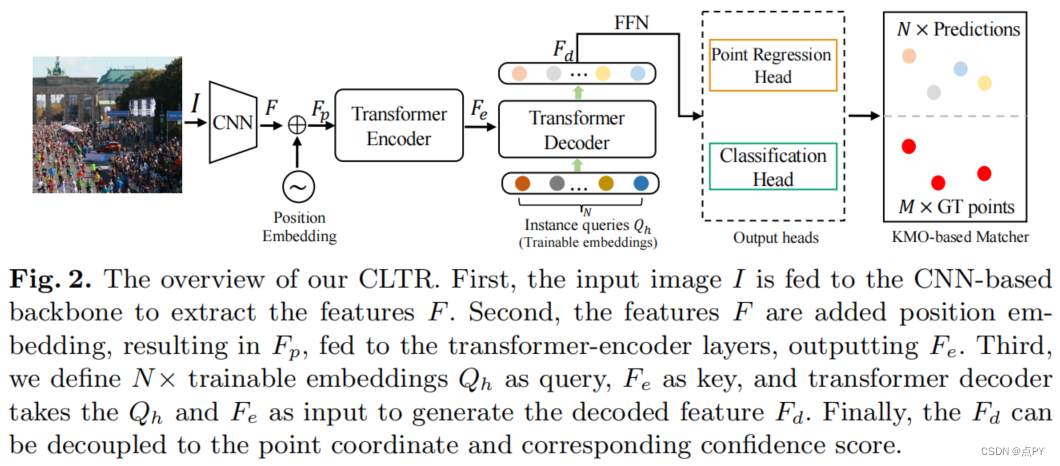
code: https://github.com/dk-liang/TransCrowd 摘要:主流的人群计数方法通常利用卷积神经网络(CNN)来回归密度图,需要点级的注释。然而,用一个点来注释每个人是一个昂贵而费力的过程。在测试阶段,不考虑点级注释来评估计数的准确性,这意味着点级注释是冗余的。因此,我们希望开发仅依赖于计数级注释的弱监督计数方法,这是一种更经济的标记方法。目前的弱监督计数方法采用CNN通过图像计数范式回归人群总数。然而,对于上下文建模的接受域有限是这些基于弱监督的基于cnn的方法的内在局限性。因此,这些方法不能达到令人满意的性能,在实际字的应用有限。变压器是自然语言处理中一种流行的序列-序列预测模型,它包含一个全局接受域。在本文中,我们提出了变换群集,它从基于变压器的序列到计数的角度重新提出了弱监督群体计数问题。我们观察到,所提出的跨群体算法利用变压器的自注意机制可以有效地提取语义群体信息。据我们所知,这是第一个采用纯变压器进行人群计数研究的工作。在5个基准数据集上的实验表明,与所有基于弱监督的ncrowdcnn的性能,与一些流行的全监督计数方法相比,具有较高的计数性能。 code: https://github.com/dk-liang/CLTR 摘要: 人群定位,即预测头部位置,是一项比简单的计数更实用、更高级的任务。现有的方法采用伪边界框或预先设计的定位图,依靠复杂的后处理来获得头部位置。在本文中,我们提出了一个优雅的、端到端人群本地化转换器,名为CLTR,它解决了基于回归的范式中的任务。该方法将人群定位视为一个直接集预测问题,将提取的特征和可训练的嵌入作为变压器-解码器的输入。为了减少模糊点,产生更合理的匹配结果,我们引入了一个基于KMO的匈牙利匹配器,它采用附近的上下文作为辅助匹配代价。在不同数据设置下的5个数据集上进行的大量实验表明了该方法的有效性。特别是,该方法在NWPU-Crowd、UCF-QNRF和上海科技A部分数据集上取得了最好的定位性能。 https://github.com/gjy3035/Awesome-Crowd-Counting/blob/master/src/Transformer.md |

【本文地址】
今日新闻 |
推荐新闻 |