使用Weka进行K |
您所在的位置:网站首页 › 决策树iris分类weka › 使用Weka进行K |
使用Weka进行K
|
0x01 Weka简介
Weka是由新西兰怀卡托大学开发的智能分析系统(Waikato Environment for Knowledge Analysis) 。在怀卡托大学以外的地方,Weka通常按谐音念成Mecca,是一种现今仅存活于新西兰岛的,健壮的棕色鸟, 非常害羞,好奇心很强,但不会飞 。 Weka是用Java写成的,它可以运行于几乎所有的操作平台,包括Linux,Windows等操作系统。 Weka平台提供一个统一界面,汇集了当今最经典的机器学习算法及数据预处理工具。做为知识获取的完整系统,包括了数据输入、预处理、知识获取、模式评估等环节,以及对数据及学习结果的可视化操作。并且可以通过对不同的学习方法所得出的结果进行比较,找出解决当前问题的最佳算法。 Weka提供了许多用于数据可视化及预处理的工具(也称作过滤器),包括种类繁多的用于数据集转换的工具等。所有机器学习算法对输入数据都要求其采用ARFF格式。 Weka作为一个公开的知识过去的工作平台,集合了大量能承担数据(知识)挖掘任务的机器学习算法,包括分类,回归、聚类、关联规则等。 0x02 K-均值算法K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。 0x03 K-近邻算法最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。 KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 0x04 Weka中使用K-均值算法找到一个实例数据集,可以去我的资源页寻找:WEKA入门用的银行数据集bank-data.arff 鼠标操作即为图中红圈:
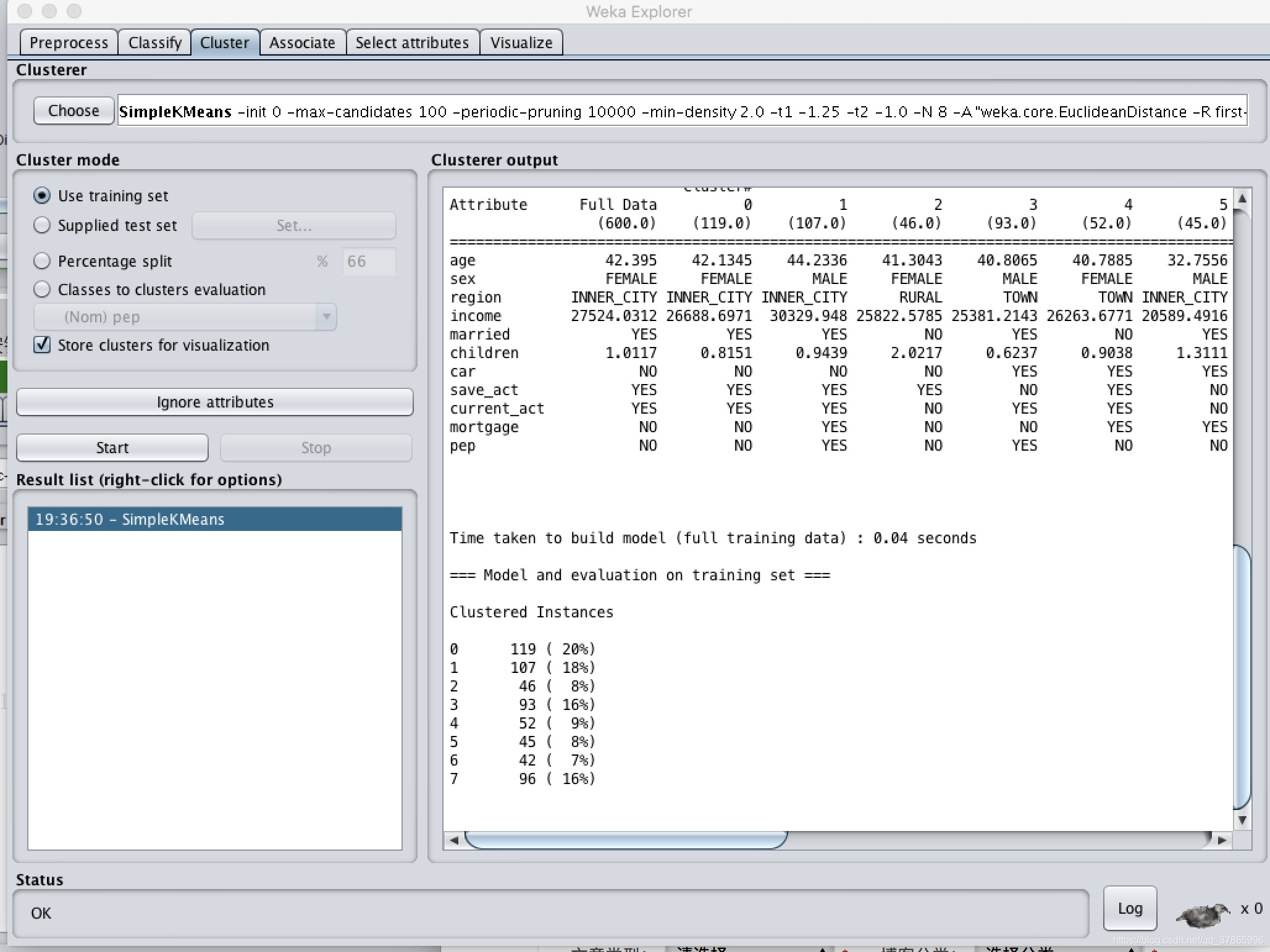
选择“SimpleKMeans”,使用K-均值算法。 点击旁边的文本框,修改“numClusters”为8,说明我们希望把这600条实例聚成8类,即K=8;下面的“seed”参数是要设置一个随机种子 ,依此产生一个随机数 ,用来得到K均值算法中第一次给出的K个簇中心的位置。我们不妨暂时让它就为100,点击OK。 选中“Cluster Mode”的“Use training set”(使用训练集),选择“Store clusters for visualization”(存储聚类可视化),点击“Start”按钮。
结果为: === Run information === Scheme: weka.clusterers.SimpleKMeans -init 0 -max-candidates 100 -periodic-pruning 10000 -min-density 2.0 -t1 -1.25 -t2 -1.0 -N 8 -A "weka.core.EuclideanDistance -R first-last" -I 500 -num-slots 1 -S 100 Relation: bank-data-weka.filters.unsupervised.attribute.Remove-R1 Instances: 600 Attributes: 11 age sex region income married children car save_act current_act mortgage pep Test mode: evaluate on training data === Clustering model (full training set) === kMeans ====== Number of iterations: 12 Within cluster sum of squared errors: 1266.2501405267758 Initial starting points (random): Cluster 0: 54,FEMALE,INNER_CITY,47796.8,YES,0,NO,YES,YES,NO,NO Cluster 1: 54,MALE,INNER_CITY,26707.9,YES,1,NO,YES,YES,YES,YES Cluster 2: 57,FEMALE,RURAL,41438.2,NO,3,NO,YES,NO,NO,NO Cluster 3: 37,MALE,TOWN,24814.5,YES,1,YES,NO,YES,YES,YES Cluster 4: 27,FEMALE,TOWN,15538.8,NO,0,YES,YES,YES,YES,NO Cluster 5: 34,MALE,INNER_CITY,25333.2,YES,3,YES,NO,NO,YES,NO Cluster 6: 65,FEMALE,INNER_CITY,37706.5,NO,0,YES,YES,YES,YES,NO Cluster 7: 35,FEMALE,INNER_CITY,28598.7,YES,0,YES,YES,YES,NO,NO Missing values globally replaced with mean/mode Final cluster centroids: Cluster# Attribute Full Data 0 1 2 3 4 5 6 7 (600.0) (119.0) (107.0) (46.0) (93.0) (52.0) (45.0) (42.0) (96.0) ================================================================================================================ age 42.395 42.1345 44.2336 41.3043 40.8065 40.7885 32.7556 52.381 43.75 sex FEMALE FEMALE MALE FEMALE MALE FEMALE MALE FEMALE FEMALE region INNER_CITY INNER_CITY INNER_CITY RURAL TOWN TOWN INNER_CITY INNER_CITY INNER_CITY income 27524.0312 26688.6971 30329.948 25822.5785 25381.2143 26263.6771 20589.4916 36953.0262 28131.2747 married YES YES YES NO YES NO YES NO YES children 1.0117 0.8151 0.9439 2.0217 0.6237 0.9038 1.3111 0.6429 1.3021 car NO NO NO NO YES YES YES YES YES save_act YES YES YES YES NO YES NO YES YES current_act YES YES YES NO YES YES NO YES YES mortgage NO NO YES NO NO YES YES YES NO pep NO NO YES NO YES NO NO NO NO Time taken to build model (full training data) : 0.04 seconds === Model and evaluation on training set === Clustered Instances 0 119 ( 20%) 1 107 ( 18%) 2 46 ( 8%) 3 93 ( 16%) 4 52 ( 9%) 5 45 ( 8%) 6 42 ( 7%) 7 96 ( 16%)观察其散点图:
训练用的文件为test.arff,测试使用yuce.arff。文件获取:https://pan.baidu.com/s/1o7iGfHo#list/path=%2F
选择IBk。 设置距离度量:
选择K值。 开始: === Run information === Scheme: weka.classifiers.lazy.IBk -K 5 -W 0 -A "weka.core.neighboursearch.LinearNNSearch -A \"weka.core.ManhattanDistance -R first-last\"" Relation: testKNN_predicted Instances: 1000 Attributes: 4 feiji binqilin youxi leixing Test mode: 10-fold cross-validation === Classifier model (full training set) === IB1 instance-based classifier using 5 nearest neighbour(s) for classification Time taken to build model: 0 seconds === Stratified cross-validation === === Summary === Correctly Classified Instances 947 94.7 % Incorrectly Classified Instances 53 5.3 % Kappa statistic 0.9205 Mean absolute error 0.0471 Root mean squared error 0.162 Relative absolute error 10.5914 % Root relative squared error 34.3632 % Total Number of Instances 1000 === Detailed Accuracy By Class === TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class 0.939 0.027 0.945 0.939 0.942 0.914 0.986 0.972 largeDoses 0.970 0.030 0.941 0.970 0.955 0.933 0.995 0.984 smallDoses 0.933 0.023 0.955 0.933 0.944 0.915 0.987 0.976 didntLike Weighted Avg. 0.947 0.026 0.947 0.947 0.947 0.921 0.989 0.977 === Confusion Matrix === a b c |





【本文地址】
今日新闻 |
推荐新闻 |