linux内存管理笔记(一) |
您所在的位置:网站首页 › 内存分段有多少段的区别 › linux内存管理笔记(一) |
linux内存管理笔记(一)
|
1. 分段机制概述
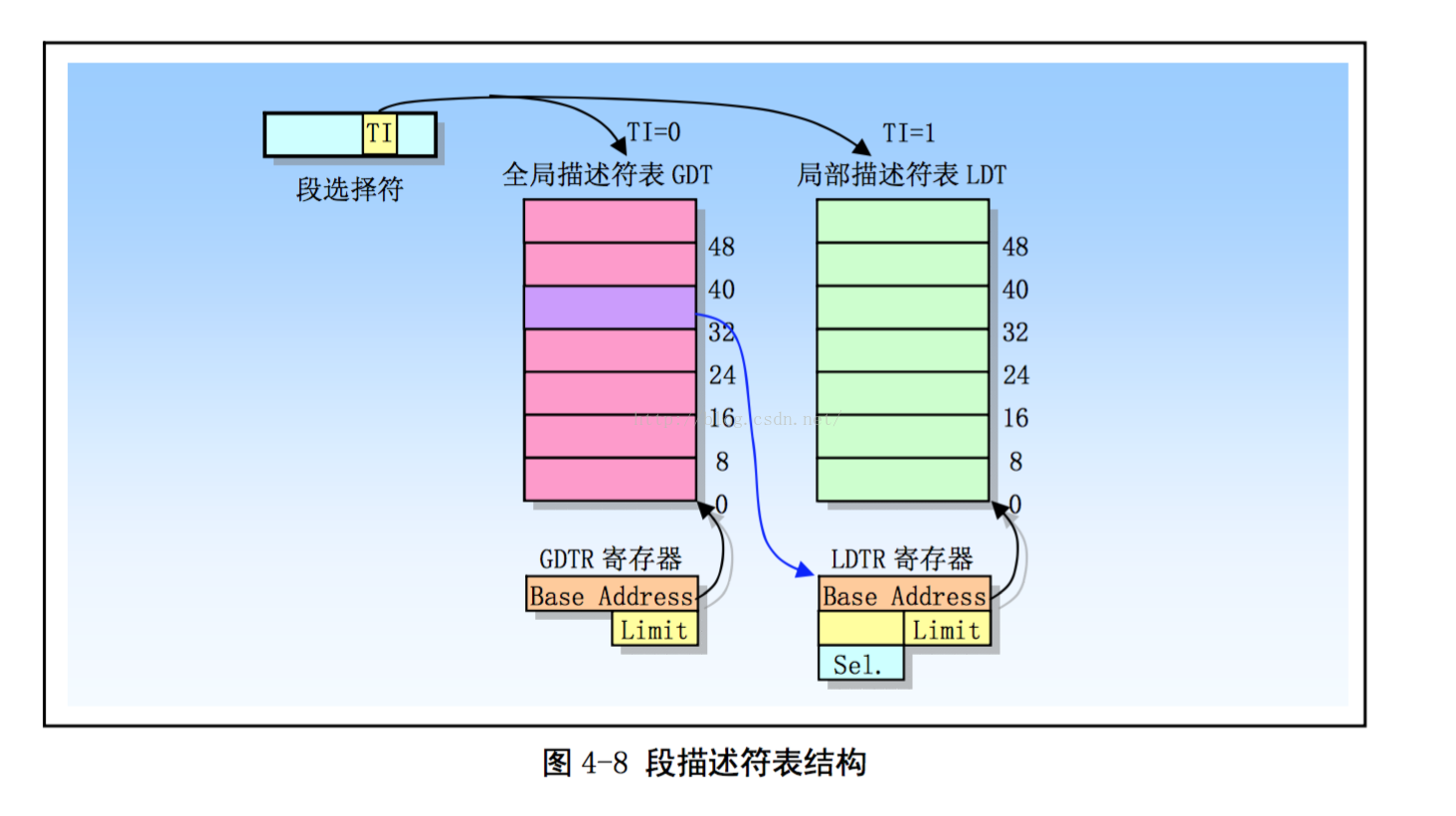
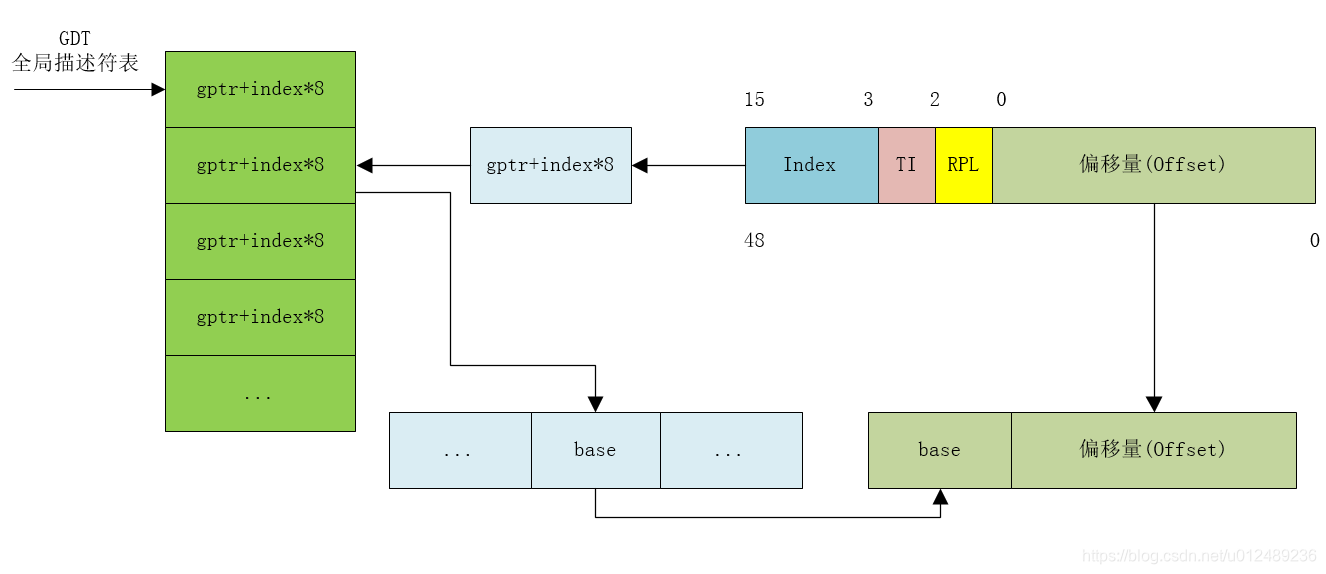
对于分段机制,要从Intel的微处理器的8086开始说起,刚开始内存空间比较小,内存寻址采用的是直接访问物理地址的方式。由于技术的发展,计算机做的事情越来越多,程序也越来越大,为了更大的内存空间,把地址总线扩展到20位。但是,对于内存设计,一个很尴尬的问题产生了,之前的设计CPU的ALU宽度只有16位,也就是说,ALU不能访问20位的地址空间,那时就设计了段机制来处理这种情况。为了坚持这种兼容性,386依然运用段机制,直至现在的64位处理器已经看不到段机制的身影。 1.1 分段机制产生的原因为了保持兼容,分段机制的被引入,我们来实际的理解分段机制解决了什么实质性的问题呢?在分段机制还没有出现的时候,程序运行是需要从内存分配出足够多的连续内存,然后整个程序装载进去。例如: 某个程序大小是100M,然后我们就需要有连续的100M内存空间才能把这个程序装载到内存里面。如果无法找到连续的100M内存空间,就无法把这个程序装载进内存空间,程序就无法得到运行。 假设我们的内存可以提供连续的区域来使得程序运行,那么我们来看一下还会存在有什么问题呢? 地址空间不隔离(安全性):如何有两个程序运行A和B,程序A在内存的地址假设为0x0->0x100,而程序B在内存中的地址假设为0x100->0x199。那么假设程序员A本来想存在属于A的地址0x50,而不小心访问到属于B的地址0x150,那么不好的事情就将发生了,A和B程序都异常了。对于程序员B来说,是飞来横祸,同时也很难定位到问题,这种情况会导致程序能访问所有的内存空间,恶意修改数据可能超成安全问题。程序运行时地址不确定(动态链接):程序每次要运行的时候,都是需要装载到内存中的,假设你在程序中写死了要操作某个地址的内存,例如你要地址0x150。但是问题来了,你能够保证你操作的地址0x150真的就是你原来想操作的那个位置吗?很可能程序第一次装载进内存的位置是0x100->0x199,而程序第二次运行的时候,这个程序装载进内存的位置变成了0x0->0x100,而你操作的0x150地址压根就不是属于这个程序所占有的内存。内存使用率低下(内存共享):假设我们写了3个程序其中程序A大小为10M,程序B为70M,程序C的大小为30M你的计算机的内存总共有100M。这三个程序加起来有110M,显然这三个程序是无法同时存在于内存中的。并且最多只能够同时运行两个程序。可能是这样的,程序A占有的内存空间是0x00000000~0x00000009,程序B占有的内存空间是0x00000010~0x00000079。假设这个时候程序C要运行该怎么做?可以把其中的一个程序换出到磁盘上,然后再把程序C装载到内存中。假设是把程序A换出,那么程序C还是无法装载进内存中,因为内存中空闲的连续区域有两块,一块是原来程序A占有的那10M,还有就是从0x00000080~0x00000099这20M,所以,30M的程序C无法装载进内存中。那么,唯一的办法就是把程序B换出,保留程序A,但是,此时会有60M的内存无法利用起来。为了解决这一些问题,分段的概念应运而生。在计算机科学领域,任何的问题都可以通过增加一个间接的中间层来解决问题,那么为了实现分段的这个技术,就需要引入虚拟地址空间的概念。 我们来了解下,虚拟地址空间和物理地址空间的概念,简单的说来,对于可以寻址的一片空间,如果这个空间是虚拟的,我们就叫做虚拟的地址空间;如果这个空间是真实存在的,我们就叫做物理地址空间。虚拟地址空间是虚拟的,所有就决定了他可以是任意的大,而物理地址空间必须是真实存在的,是由实际的硬件决定的。 1.2 硬件分段机制分段是一种隔离不同的代码、数据、栈模块的机制,能够保证不同进程或任务不会互相干扰。我们可以为一个进程分配属于它的段集合,CPU 的硬件机制会保证其代码不会越权访问段,也不会访问到段外的地址。 分段机制就是把虚拟地址空间中的虚拟内存组织成一些长度可变的的段的内存单元,80386虚拟地址空间中的逻辑地址由一个段部分和一个段内偏移部分构成,段是虚拟地址空间到线性地址转换的基础。每个段都有3个参数定义 段基地址:指定段在线性地址空间中的开始地址,基地址是线性地址对应于段中偏移0处段限长:是虚拟地址空间中段内最大可用偏移地址,定义了段的长度段属性:指定段的特性,如该段是否可读,可写或可执行,段的特权级等当需要访问处理器地址空间的某个字节时,段选择符指定了该字节所在的段,偏移量制定了该字节在段中相对于段基址的位置,处理器把逻辑地址转化成一个线性地址的过程如下: 1.使用段选择符中的偏移值(在GDT(全局描述符表) 或 LDT(局部描述符表)中定位相应的段描述符 2.利用段描述符校验段的访问权限和范围,以确保该段是可以访问的并且偏移量位于段界限内 3.利用段描述符中取得的段基地址加上偏移量,形成一个线性地址 段选择符(或称段选择子)是段的一个十六位标志符,如下图所示。段选择符并不直接指向段,而是指向段描述符表中定义段的段描述符。 段选择符包括 3 个字段的内容: 请求特权级RPL([0:1])表指引标志TI([2])TI = 0 ,表示描述符在GDT中,TI = 1,表示描述符在LDT中索引值,给出了描述符在GDT或LDT表中的索引项号下面是一些段选择符的示例: 段描述符表是段描述符的一个数组,如下图所示。描述符表的长度可变,最多可以包含8192个 8 byte 描述符。有两个描述符表: 全局描述符表GDT (Global descriptor table); 局部描述符表 LDT (Local descriptor table),由段选择符的bit[2]会选择到对应的GDT表还是LDT表去拿到对应的段基址。 而对于段描述符,每个段描述符长度是 8 字节,含有三个主要字段:段基地址、段限长和段属性。段描述符通常由编译器。链接器、加载器或者操作系统来创建,绝不可能由应用程序来创建。 段描述符通用格式如下: 了解了这个过程,我们来总体的梳理下,如果使用分段机制,那么怎么使虚拟地址空间转到对应的物理地址空间呢?转换过程如下图所示 上一节讨论了80x86如何从硬件上提供分段机制的支持,而本节讨论下linux如何使用分段机制。最开始的时候,操作系统不支持分段,内存的换入换出都是以整个进程的内存空间为单位,导致系统非常的耗时,同时利用率也不高,当内存不足,很容易导致内存交换失败。后来有了分段技术,把内存空间分成多个模块:代码段、数据段,或者是一个大的数据块,段成了内存交换的单位,在一定程度上增加了内存利用率。那时候还没有分页技术,虚拟地址(线性地址)是直接映射到物理空间的。 引入分页机制后,目前linux很少使用分段,分段和分页在某些方面是冗余的,因为他们都可以把物理地址空间分割成不同部分:分段给每个进程分配不同的逻辑地址空间,而分页可以把相同的逻辑地址空间映射到不同的物理地址上。因此,Linux优先采用了分页(分页操作系统),基于以下原因: 内存管理更简单:所有进程使用相同段寄存器值,也就是相同的线性地址集出于兼容大部分硬件架构的考虑,RISC架构对分段支持的不是很好所以自从x86-64起,除了在“传统模式”下,分段机制已被认为是过时的且不再被支持。虽然在x86-64的本机模式下仍然有分段机制的某些痕迹,但大多只是为了兼容,且它们不再具起到同样的作用,也不再提供真正的分段。 那么linux内核是怎么支持分段机制呢?我们来看上节的分段机制的原理图如下 比如,我们将虚拟地址空间分成4个段,用0-3来编号,每个段在段表中有一个项,在物理空间中,段的排列如下图所示 如果要访问段2中偏移量为600的虚拟地址,我们可以计算出物理地址为段基地址+偏量=2000+600=2600 3. Linux分段机制的软件实现Linux对段机制的应用效果是等价于几乎绕过了段基址。在Linux中仅有4个段,用户代码段、数据段和内核代码段、数据段。 SegmentBaseGLimitTypeDPLSD/BPuser code0x0000000010xfffff103111user data0x0000000010xfffff23111kernel code0x0000000010xfffff100111kernel data0x0000000010xfffff20111这些段相应的选择器分别由以下宏定义:_USER_CS, __USER_DS, __KERNEL_CS, 和__KERNEL_DS。举例来说,如果要定位内核代码段,内核只需要加载__KERNEK_CS宏的值到cs寄存器中。 接下来我们看一下linux代码吧,进入保护模式的函数go_to_protected_mode: void go_to_protected_mode(void) { /* Hook before leaving real mode, also disables interrupts */ realmode_switch_hook(); /* Enable the A20 gate */ if (enable_a20()) { puts("A20 gate not responding, unable to boot...\n"); die(); } /* Reset coprocessor (IGNNE#) */ reset_coprocessor(); /* Mask all interrupts in the PIC */ mask_all_interrupts(); /* Actual transition to protected mode... */ setup_idt(); setup_gdt(); protected_mode_jump(boot_params.hdr.code32_start, (u32)&boot_params + (ds() 0, 0}; asm volatile("lidtl %0" : : "m" (null_idt)); }根据setup_idt()的实现,可以明显看到这没做什么,纯粹置一下idt为空的描述符表。 static void setup_gdt(void) { /* There are machines which are known to not boot with the GDT being 8-byte unaligned. Intel recommends 16 byte alignment. */ static const u64 boot_gdt[] __attribute__((aligned(16))) = { /* CS: code, read/execute, 4 GB, base 0 */ [GDT_ENTRY_BOOT_CS] = GDT_ENTRY(0xc09b, 0, 0xfffff), /* DS: data, read/write, 4 GB, base 0 */ [GDT_ENTRY_BOOT_DS] = GDT_ENTRY(0xc093, 0, 0xfffff), /* TSS: 32-bit tss, 104 bytes, base 4096 */ /* We only have a TSS here to keep Intel VT happy; we don't actually use it for anything. */ [GDT_ENTRY_BOOT_TSS] = GDT_ENTRY(0x0089, 4096, 103), }; /* Xen HVM incorrectly stores a pointer to the gdt_ptr, instead of the gdt_ptr contents. Thus, make it static so it will stay in memory, at least long enough that we switch to the proper kernel GDT. */ static struct gdt_ptr gdt; gdt.len = sizeof(boot_gdt)-1; gdt.ptr = (u32)&boot_gdt + (ds() |
【本文地址】