python数据分析案例简单实战项目(二) |
您所在的位置:网站首页 › 保定病例分布情况查询系统 › python数据分析案例简单实战项目(二) |
python数据分析案例简单实战项目(二)
|
项目背景
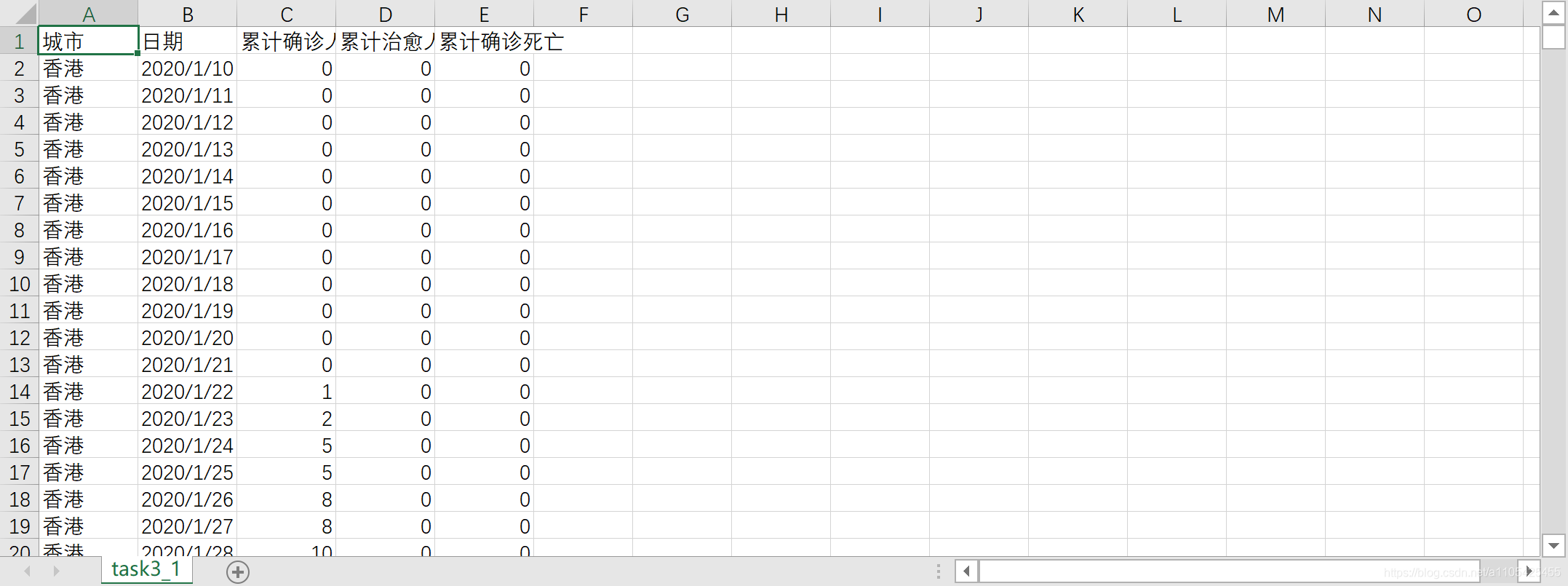
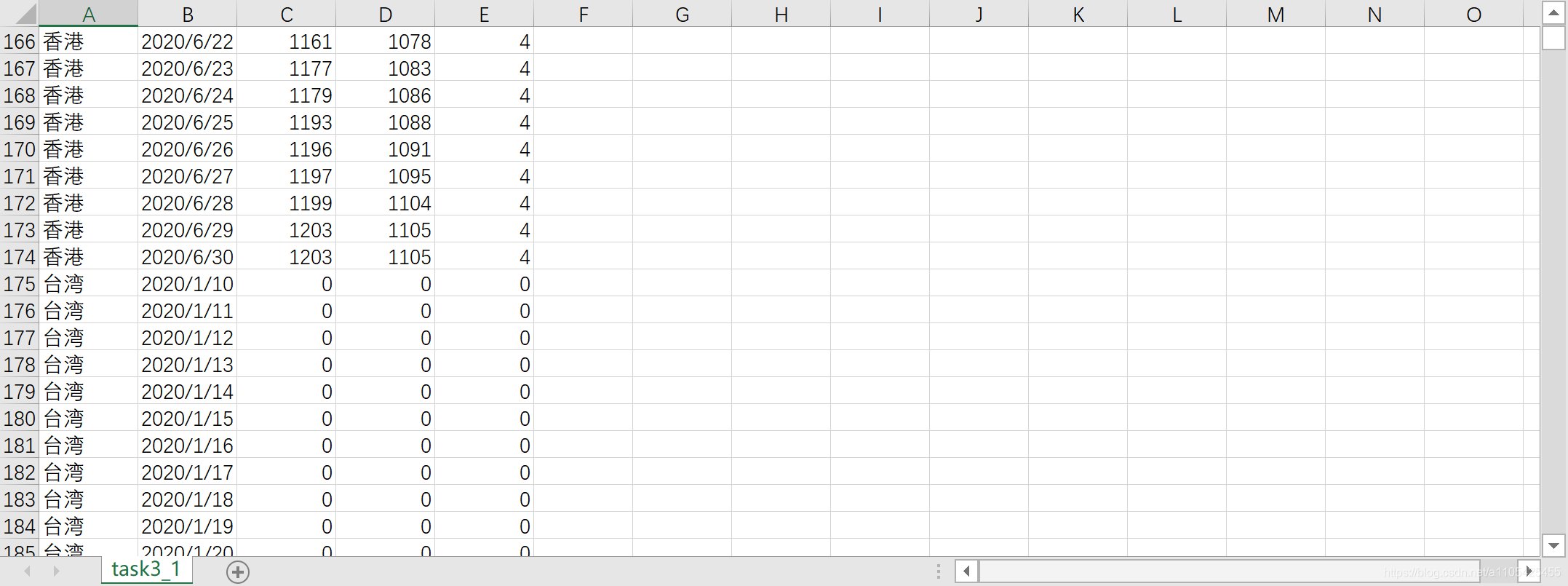
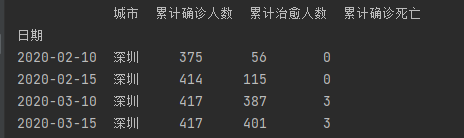
2020 年 1 月新型冠状病毒(以下简称新冠)肺炎在极短时间内就在全球范围内大规模流行,据美国约翰斯·霍普金斯大学 11 月 8 日发布的新冠疫情最新统计数据显示,截至美国东部时间 11 月 8 日 11 时 24 分全球累计确诊人数超过 5000 万,死亡人数超过125 万。由于新冠病毒的传播速度快、致死率较高,世界卫生组织称新冠是百年一遇的人类公敌。自新冠肺炎爆发以来,面对社会对疫情信息的迫切需求,各级政府部门通过多种渠道及时发布第一手相关数据,许多组织和个人也迅速行动,利用多种分析手段为公众提供疫情数据的解读分析,以消除公众的恐慌情绪,提高人们的自我防护意识,配合政府的防疫措施,为我国最终打赢疫情防控阻击战发挥了巨大的推动作用。 项目目标 1.根据附件1中“城市疫情”的数据统计各城市自首次通报确诊病例后至 6 月 30日的每日累计确诊人数、累计治愈人数和累计死亡人数,将结果保存为“task3_1.csv”,第一行为字段名,按城市、日期、累计确诊人数、累计治愈人数、累计死亡人数的次序分别放在 A 列~E 列。在报告中给出实现方法的相关描述,并列表给出武汉、深圳、保定每月 10、25 日的统计结果。先将数据中的城市分类,再对逐个城市逐行即每个日期(缺失的日期补全)进行累加得到累计确诊,治愈,死亡人数。 代码: import pandas as pd data = pd.read_excel(r"C:\Users\Crown\Desktop\附件1.xlsx",header =0)#导入数据 data["城市"].value_counts()#排序城市 data.rename(columns={'新增确诊':'累计确诊人数'},inplace=True)#更改列标签 data.rename(columns={'新增治愈':'累计治愈人数'},inplace=True)#更改列标签 data.rename(columns={'新增死亡':'累计确诊死亡'},inplace=True)#更改列标签 index = pd.date_range('20200110','20200630')#创建日期索引 for i in range(0,len(data["城市"].value_counts())):#对城市进行循环 da = data[data["城市"] == data["城市"].value_counts().index[i]]#得到只包含一个城市的数据 da['日期'] = pd.to_datetime(da['日期']) da = da.set_index('日期').reindex(index,fill_value=0)#进行日期的补全 da['城市'] = data['城市'].value_counts().index[i]#补全城市列数据 da = da.rename_axis('日期').reset_index()#保留日期列 da['累计确诊人数'].astype('int') da['累计治愈人数'].astype('int') da['累计确诊死亡'].astype('int') da['累计确诊人数'] = da['累计确诊人数'].cumsum()#累加 da['累计治愈人数'] = da['累计治愈人数'].cumsum()#累加 da['累计确诊死亡'] = da['累计确诊死亡'].cumsum()#累加 list1 =[]#空列表拿来存放想找到的城市的索引 list2 = ['武汉','深圳','保定'] if data["城市"].value_counts().index[i] in list2:#判断是否是要列出数据的城市 list1.append(i)#将索引存起来 if i in list1:#判断城市 da['日期'] = pd.to_datetime(da['日期'])#转换类型供查找 da1 = da.set_index('日期')#将日期作为索引 s1 = da1['2020-01-10':'2020-01-10']#存放第一个数据 for i in range(1, 7):#数据是从20年1月到6月的 故range(1,7) s = da1['2020-0{}-15'.format(i):'2020-0{}-15'.format(i)] s1 = pd.concat([s1, s], axis=0, join='outer')#数据合并 s = da1['2020-0{}-10'.format(i+1):'2020-0{}-10'.format(i+1)] s1 = pd.concat([s1, s], axis=0, join='outer') print(s1)#打印出来 da = da.set_index("城市") # 将城市作为索引 存入csv是第一行便是城市 if i == 0: da.to_csv(r"C:\Users\Crown\Desktop\task3_1.csv", index=True, na_rep='0', encoding='GB18030',mode = 'a')#写入csv文件,包括表头和索引 encoding需要用GB18030否则文字乱码 else: da.to_csv(r"C:\Users\Crown\Desktop\task3_1.csv", index=True, header = None,na_rep='0', encoding='GB18030', mode='a')#追加写入,不包括表头部分输出结果
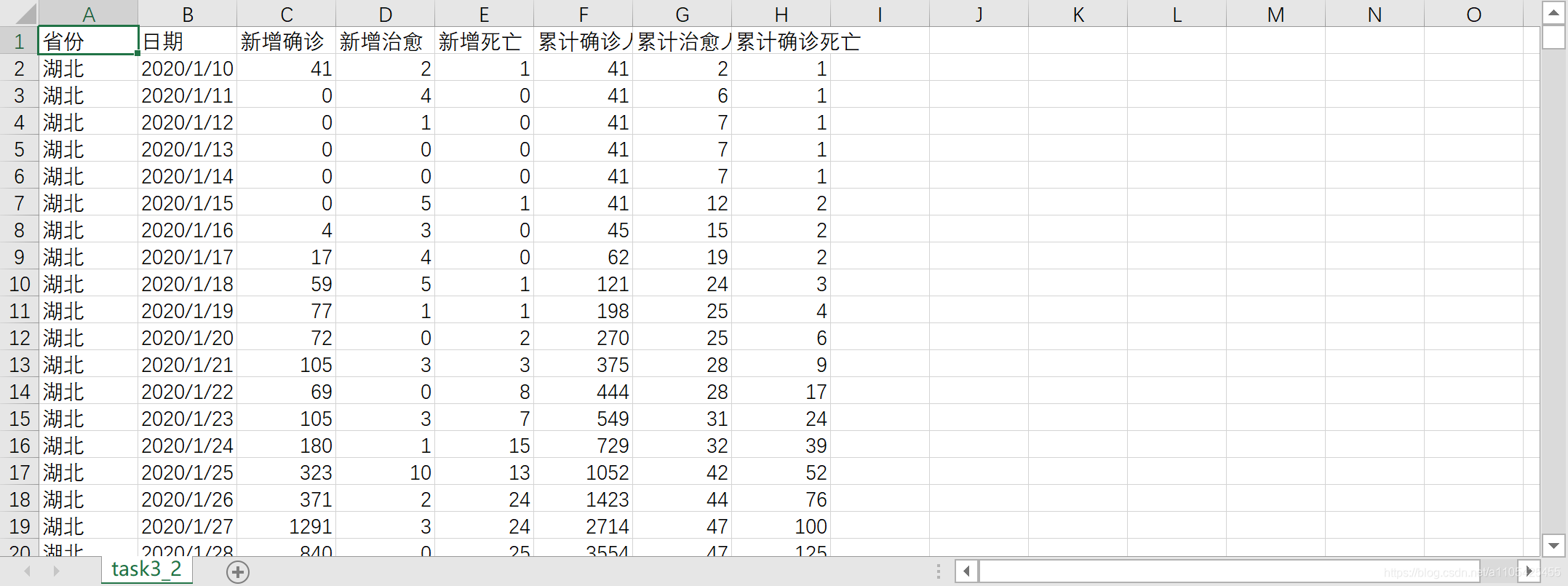
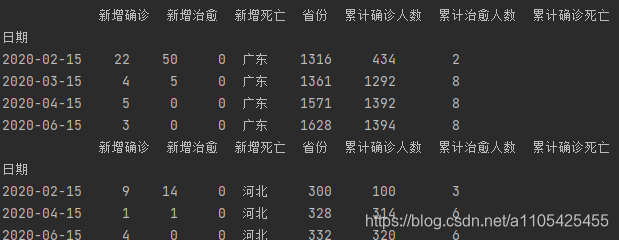
疑问1 判断城市是否是武汉,深圳,保定时 if da[‘城市’][0] == ‘武汉’ 判断数据城市列的第一行是否是武汉城市 报错 百度说是列名中可能会有空格,去除列名空格后还是一样报错,不知怎么解决。 2.根据任务 1 的结果,并结合附件 1“城市省份对照表”统计各省级行政单位按日新增和累计数据,将结果保存为“task3_2.csv”,第一行为字段名,按省份、日期、新增确诊人数、新增治愈人数、新增死亡人数、累计确诊人数、累计治愈人数、累计死亡人数的次序分别放在 A 列~H 列。在报告中给出实现方法的相关描述,并列表给出湖北、广东、河北每月 15 日的统计结果。将附件1中的第二个表中的数据制作成字典,将第一个表中的数据通过字典将城市转换为省份,转换为省份之后其日期会重复,需要进行日期合并处理,处理后接下来的操作与任务1类似。 代码如下: import pandas as pd index = pd.date_range('20200110','20200630') def settime(da,sf):#补齐日期 da['日期'] = pd.to_datetime(da['日期']) da = da.set_index('日期').reindex(index, fill_value=0) da['省份'] = sf da = da.rename_axis('日期').reset_index() return da data_sheet2 = pd.read_excel(r"C:\Users\11054\Desktop\附件1.xlsx", header=0, sheet_name=1) # 导入数据 sheet_name=1读取第二张表 list_keys = [] # 存储key list_values = [] # 存储value for i in range(0, len(data_sheet2)): # 将表2的数据写入列表 list_keys.append(data_sheet2['城市'][i]) list_values.append(data_sheet2['省份'][i]) co = dict(zip(list_keys, list_values)) # 转换成城市对应省份的字典 字符串无法直接转换成字典,需要先用zip转换成元组再转换成字典 data_sheet1_meiri = pd.read_excel(r"C:\Users\11054\Desktop\附件1.xlsx", header=0) # 导入表1数据 每日数据 for i in range(0, len(data_sheet1_meiri)): # 遍历数据 将城市改为省份 if data_sheet1_meiri['城市'][i] in co.keys(): data_sheet1_meiri.loc[[i], ['城市']] = co[data_sheet1_meiri['城市'][i]] data_sheet1_leiji = pd.read_excel(r"C:\Users\11054\Desktop\附件1.xlsx", header=0) # 导入表1数据 逐行累加数据 for i in range(0, len(data_sheet1_leiji)): # 遍历数据 将城市改为省份 if data_sheet1_leiji['城市'][i] in co.keys(): data_sheet1_leiji.loc[[i], ['城市']] = co[data_sheet1_leiji['城市'][i]] data_sheet1_leiji.rename(columns={'新增确诊': '累计确诊人数'}, inplace=True) # 更改列标签 data_sheet1_leiji.rename(columns={'新增治愈': '累计治愈人数'}, inplace=True) # 更改列标签 data_sheet1_leiji.rename(columns={'新增死亡': '累计确诊死亡'}, inplace=True) # 更改列标签 for i in range(0, len(data_sheet1_meiri["城市"].value_counts())): # 对城市进行循环 da_sheet1_meiri1 = data_sheet1_meiri[data_sheet1_meiri["城市"] == data_sheet1_meiri["城市"].value_counts().index[i]] # 得到只包含一个城市的数据 但是日期存在重复 da_sheet1_leiji1 = data_sheet1_leiji[data_sheet1_leiji["城市"] == data_sheet1_leiji["城市"].value_counts().index[i]] # 得到只包含一个城市的数据 但是日期存在在重复 da_sheet1_meiri = da_sheet1_meiri1.groupby('日期', as_index=False).sum()#得到日期数据整合好的 da_sheet1_leiji = da_sheet1_leiji1.groupby('日期', as_index=False).sum() #得到日期数据整合好的 da_sheet1_meiri['省份'] = data_sheet1_meiri["城市"].value_counts().index[i]#加入省份列 da_sheet1_leiji['省份'] = data_sheet1_leiji["城市"].value_counts().index[i] # 加入省份列 da_sheet1_leiji = settime(da_sheet1_leiji,data_sheet1_leiji["城市"].value_counts().index[i]) da_sheet1_meiri = settime(da_sheet1_meiri,data_sheet1_meiri["城市"].value_counts().index[i]) da_sheet1_leiji['累计确诊人数'] = da_sheet1_leiji['累计确诊人数'].cumsum() da_sheet1_leiji['累计治愈人数'] = da_sheet1_leiji['累计治愈人数'].cumsum() da_sheet1_leiji['累计确诊死亡'] = da_sheet1_leiji['累计确诊死亡'].cumsum() da = pd.concat([da_sheet1_meiri, da_sheet1_leiji], axis=1, join='inner') da = da.loc[:, ~da.columns.duplicated()] # ~df.columns.duplicated()去除重复列 list_index = [] # 空列表拿来存放想找到的省份的索引 list_cs = ['湖北', '广东', '河北'] if data_sheet1_meiri["城市"].value_counts().index[i] in list_cs: # 判断是否是要列出数据的省份 list_index.append(i) # 将索引存起来 if i in list_index: # 判断省份 da['日期'] = pd.to_datetime(da['日期']) # 转换类型供查找 da1 = da.set_index('日期') # 将日期作为索引 s1 = da1['2020-01-15':'2020-01-15'] # 存放第一个数据 for k in range(2, 7): s = da1['2020-0{}-15'.format(k):'2020-0{}-15'.format(k)] s1 = pd.concat([s1, s], axis=0, join='outer') # 数据合并 print(s1) # 打印出来 da2 = da.set_index("省份") # 将省份作为索引 存入csv是第一行便是省份 if i == 0: da2.to_csv(r"C:\Users\11054\Desktop\task3_2.csv", index=True, na_rep='0',header=True, encoding='GB18030', mode='a') # 写入csv文件,包括表头和索引 encoding需要用GB18030否则文字乱码 else: da2.to_csv(r"C:\Users\11054\Desktop\task3_2.csv", index=True, header=None, na_rep='0', encoding='GB18030', mode='a') # 追加写入,不包括表头部分输出结果:
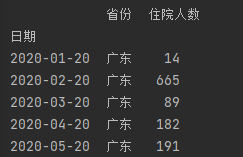
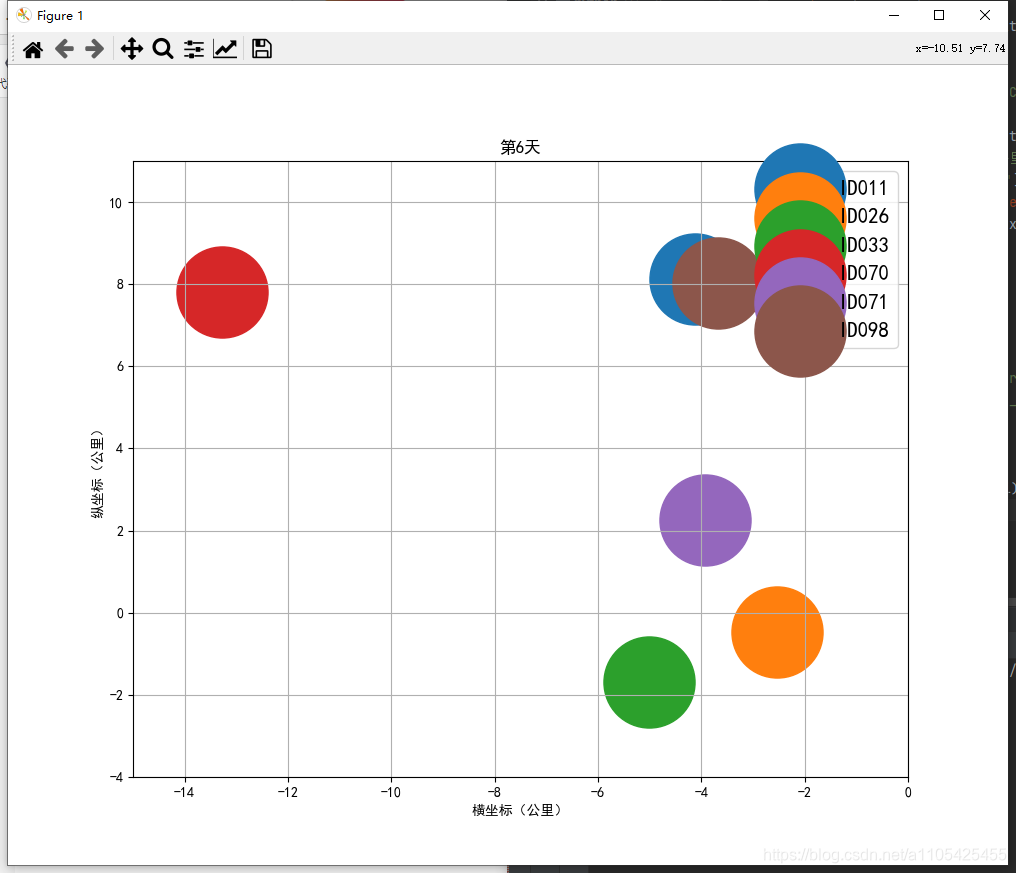
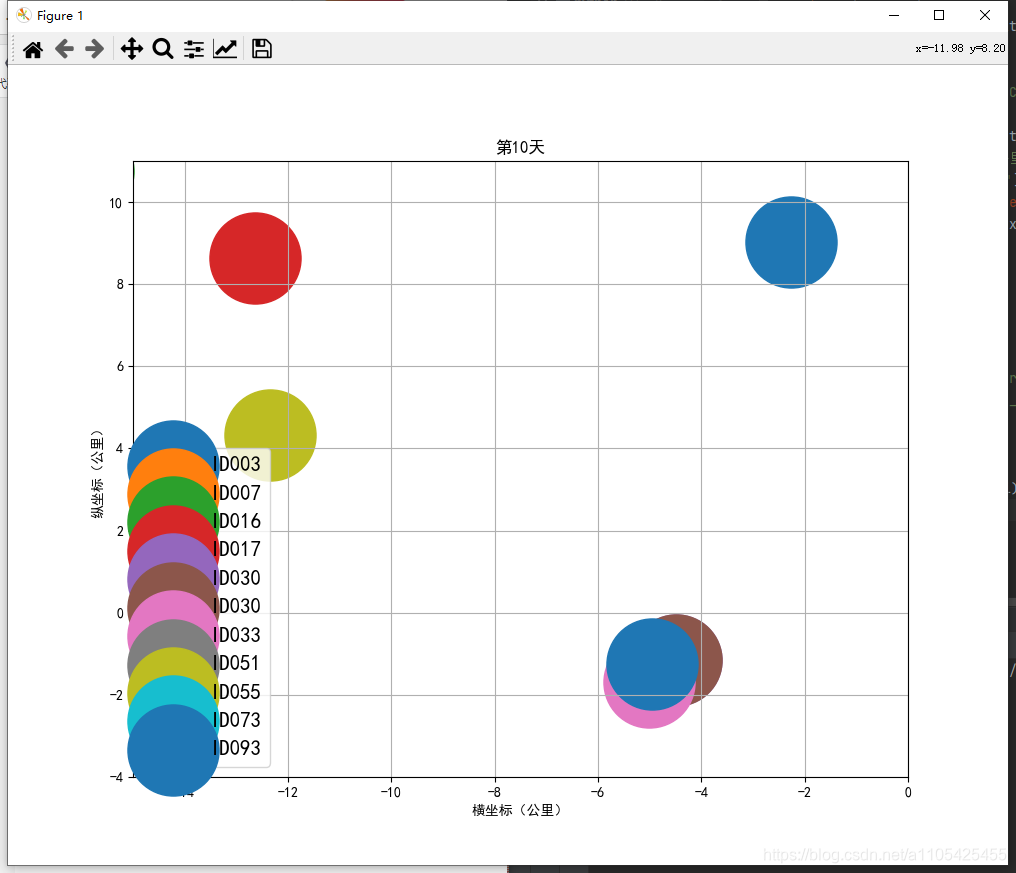
住院人数等于累计确诊-累计治愈-累计死亡 代码如下: import pandas as pd data = pd.read_csv(r"C:\Users\Crown\Desktop\task3_2.csv",header = 0,encoding='GB18030')#导入数据 del data['新增确诊']#删除不必要的列 del data['新增治愈']#删除不必要的列 del data['新增死亡']#删除不必要的列 for i in range(0,len(data)):#遍历循环 计算住院人数 data.loc[[i],['累计确诊人数']] -= (int(data['累计治愈人数'][i]) +int(data['累计确诊死亡'][i]))#住院人数等于累计确诊-累计治愈-累计死亡 del data['累计治愈人数']#删除不必要的列 del data['累计确诊死亡']#删除不必要的列 data.rename(columns = {'累计确诊人数':'住院人数'},inplace = True)#进行重命名 list2 = ['湖北', '广东', '上海'] for i in range(0,3): data1 = data[data["省份"] == str(list2[i])] data1['日期'] = pd.to_datetime(data1['日期'])#转换类型供查找 da1 = data1.set_index('日期')#将日期作为索引 s1 = da1.loc['2020-01-20':'2020-01-20']#存放第一个数据 for k in range(2,7): s = da1.loc['2020-0{}-20'.format(k):'2020-0{}-20'.format(k)] s1 = pd.concat([s1, s], axis=0, join='outer')#数据合并 print(s1) data.to_csv(r"C:\Users\Crown\Desktop\task3_3.csv", index=False, na_rep='0',header=True, encoding='GB18030',mode='a') # 写入csv文件,包括表头,不需要索引 encoding需要用GB18030否则文字乱码部分输出结果: 找出第六天,第十天的数据画散点图 代码如下: import pandas as pd import matplotlib.pyplot as plt import numpy as np list = [6,10] data_sheet3 = pd.read_excel(r"C:\Users\Crown\Desktop\附件1.xlsx", header=0, sheet_name=3) # 导入数据 sheet_name=3读取第四张表 for i in list: da_sheet3 = data_sheet3[data_sheet3['通报日期'] == i] x, y = da_sheet3['横坐标(公里)'], da_sheet3['纵坐标(公里)'] label = da_sheet3['疫情场所'] figure = plt.figure(figsize=(10, 8)) c1 = np.random.rand(1,len(x)) for j in range(0,len(x)): k =label.iloc[j] plt.scatter(x.iloc[j], y.iloc[j], s=4300,label = k) # 对于圆形,圆的面积为 area = pi/4*s . plt.legend(prop={'family': 'SimHei', 'size': 15}) # fontproperties='SimHei'字体设置显示中文 plt.xlabel('横坐标(公里)') plt.ylabel('纵坐标(公里)') plt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体显示中文 plt.rcParams['axes.unicode_minus'] = False # 正常显示负号 plt.xlim(-15, 0) plt.ylim(-4, 11) plt.grid(True) plt.title('第{}天'.format(i)) plt.show()结果如下: scatter函数中的s并不是直接对应实际坐标轴的尺寸 5.设计数字大屏,展示国内新冠疫情汇总概要信息、时空变化情况、重点关注区域等。数字大屏使用到pyecharts库 pyecharts pyecharts的使用可参考官方文档:https://gallery.pyecharts.org/#/Line/line_areastyle_boundary_gap 参数说明可参考:https://blog.csdn.net/qq_42374697/article/details/105632257 https://blog.csdn.net/weixin_31907553/article/details/112620949 代码如下: import pandas as pd from pyecharts import options as opts from pyecharts.charts import Map,Timeline,Pie,Page,Line data = pd.read_csv(r"C:\Users\Crown\Desktop\task3_2.csv",header = 0,encoding='GB18030')#导入数据 tr = Timeline().add_schema(play_interval=1000, height=40, is_loop_play=True,is_auto_play=True,control_position = "left",is_rewind_play= False)#时间轴 tl = Timeline().add_schema(play_interval=1000, height=40, is_loop_play=True,is_auto_play=True,control_position = "left",is_rewind_play= False)#时间轴 list1 = []#存放日期 list2 = []#存放确诊人数 list3 = []#存放治愈人数 list4 = []#存放死亡人数 for i in range(1,7):#以月为单位进行遍历 得到1月到i月各个省份的累计确诊,治愈,死亡人数 list1.append("2020-0{}".format(i))#存入日期 data2 = data#防止改变data data2['日期'] = pd.to_datetime(data2['日期'])#转换日期类型 data2 = data2.set_index('日期')#将日期作为索引 data2 = data2.sort_index()#对日期进行排序 以便于对其进行切分 if i%2 == 1:#1,3,5月 data2 = data2.truncate('2020-01','2020-0{}-31'.format(i))#对数据进行切分,得到1月到i月的全部数据 else: if i == 2:#2月 data2 = data2.truncate('2020-01','2020-0{}-28'.format(i))#对数据进行切分,得到1月到i月的全部数据 else:#4,6月 data2 = data2.truncate('2020-01','2020-0{}-30'.format(i))#对数据进行切分,得到1月到i月的全部数据 data2 = data2.groupby('省份', as_index=False).sum()#对1月到i月的各个省份的各项数据进行合并 此时新增确诊人数即为累计确诊人数 data2['日期'] = '2020-0{}'.format(i)#加入日期列 list2.append(int(data2.groupby('日期').sum()['新增确诊']))#存入确诊人数 list3.append(int(data2.groupby('日期').sum()['新增治愈']))#存入治愈人数 list4.append(int(data2.groupby('日期').sum()['新增死亡']))#存入死亡人数 for i in range(1,7):#以月为单位进行遍历 data1 = data#防止改变data data1['日期'] = pd.to_datetime(data1['日期'])#转换日期类型 data1 = data1.set_index('日期')#将日期作为索引 data1 = data1.sort_index()#对日期进行排序 以便于对其进行切分 if i%2 == 1: data1 = data1.truncate('2020-01','2020-0{}-31'.format(i)) else: if i == 2: data1 = data1.truncate('2020-01','2020-0{}-28'.format(i)) else: data1 = data1.truncate('2020-01','2020-0{}-30'.format(i)) data1 = data1.groupby('省份', as_index=False).sum()#对1月到i月的各个省份的各项数据进行合并 此时新增确诊人数即为累计确诊人数 去除了日期列 data1['日期'] = '2020-0{}'.format(i)#加入日期列 data2 =data1 data2 = data2.sort_values(by='新增确诊', ascending=False)#从大到小排序‘新增确诊’这一列,方便得到累计确诊人数前五的省份 x = data2['省份'].tolist()#转换为list y = data2['新增确诊'].tolist() map = (#进行大屏显示 画地图 Map() .add(series_name="确诊病例", # 系列名称,用于 tooltip 的显示,legend 的图例筛选。 data_pair=[list(z) for z in zip(x, y)], # 数据项 (坐标点名称,坐标点值) maptype='china') # 地图类型 .set_global_opts( # 全局配置项 title_opts=opts.TitleOpts(title='疫情地图'), # title_opts = opts.TitleOpts()主标题函数 visualmap_opts=opts.VisualMapOpts( # visualmap_opts=opts.VisualMapOpts()视觉映射函数 is_piecewise=True, # 是否分段 # 自定义的每一段的范围,以及每一段的文字,以及每一段的特别的样式。 pieces=[{"max": 9, "min": 0, "label": "0-9", "color": "#FFECEC"}, {"max": 99, "min": 10, "label": "10-99", "color": " #FFB5B5"}, {"max": 499, "min": 100, "label": "100-4999", "color": "#ff7575"}, {"max": 999, "min": 500, "label": "500-999", "color": "#FF2D2D"}, {"max": 4999, "min": 1000, "label": "1000-4999", "color": " #EA0000"}, {"max": 9999, "min": 5000, "label": "5000-9999", "color": "#AE0000"}, {"max": 999999, "min": 9999, "label": ">9999", "color": " #750000"},] ) ) ) pie = (#画饼图 Pie() .add( series_name="累计确诊", radius=["40%", "55%"], data_pair=[list(z) for z in zip(x[:3], y[:3])],#前3个省份 label_opts=opts.LabelOpts( position="outside", formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ", background_color="#eee", border_color="#aaa", border_width=1, border_radius=4, rich={ "a": {"color": "#999", "lineHeight": 22, "align": "center"}, "abg": { "backgroundColor": "#e3e3e3", "width": "100%", "align": "right", "height": 22, "borderRadius": [4, 4, 0, 0], }, "hr": { "borderColor": "#aaa", "width": "100%", "borderWidth": 0.5, "height": 0, }, "b": {"fontSize": 16, "lineHeight": 33}, "per": { "color": "#eee", "backgroundColor": "#334455", "padding": [2, 4], "borderRadius": 2, }, }, ) ) .set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", orient="vertical")) .set_series_opts( tooltip_opts=opts.TooltipOpts( trigger="item", formatter="{a} {b}: {c} ({d}%)" ) ) ) line = (#画折线图 Line() .add_xaxis(xaxis_data = list1) .add_yaxis("累计确诊人数", y_axis=list2, is_smooth=True) .add_yaxis("累计治愈人数", y_axis=list3, is_smooth=True) .add_yaxis("累计确诊死亡", y_axis=list4, is_smooth=True) .set_series_opts( areastyle_opts=opts.AreaStyleOpts(opacity=0.5), label_opts=opts.LabelOpts(is_show=False), ) .set_global_opts( title_opts=opts.TitleOpts(title="全国疫情"), tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"), yaxis_opts=opts.AxisOpts( type_="value", axistick_opts=opts.AxisTickOpts(is_show=True), splitline_opts=opts.SplitLineOpts(is_show=True), ), xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False), ) ) tl.add(pie, "2020-0{}".format(i))# 将日期加入到timeline中 tr.add(map, "2020-0{}".format(i)) # 将日期加入到timeline中 page = Page(layout=Page.DraggablePageLayout)#合并在一页 page.add(tr,tl,line) page.render('国内疫情.html')#将结果保存代码运行目录下会生成 国内疫情.html 这个文件 map: Page的的排列方式为从上到下,可用Grid实现并行显示 6.设计数字大屏,展现并分析国际疫情态势和发展变化。国际疫情的数据为附件一的第三个表,思路跟任务5基本相同 其中世界地图可视化是的国家名称都为英文而数据中的国家都为中文,并且国家名称都显示的话过于密集,所以需要先对国家名称做处理,再令map.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) 表中数据并没有每日新增这一列数据,制作时间轴滑动显示各个国家累计确诊,治愈,死亡人数时需要取这个国家到每个月最后一号的最大数据可用data1 = data1.groupby('国家', as_index=False).max() # 对1月到i月的各个省份的各项数据取最大值 对国家名称做处理:定义字典,使map.add(name_map = name_map) name_map = { 'Singapore Rep.': '新加坡', 'Dominican Rep.': '多米尼加', 'Palestine': '巴勒斯坦', 'Bahamas': '巴哈马', 'Timor-Leste': '东帝汶', 'Afghanistan': '阿富汗', 'Guinea-Bissau': '几内亚比绍', "Côte d'Ivoire": '科特迪瓦', 'Siachen Glacier': '锡亚琴冰川', "Br. Indian Ocean Ter.": '英属印度洋领土', 'Angola': '安哥拉', 'Albania': '阿尔巴尼亚', 'United Arab Emirates': '阿联酋', 'Argentina': '阿根廷', 'Armenia': '亚美尼亚', 'French Southern and Antarctic Lands': '法属南半球和南极领地', 'Australia': '澳大利亚', 'Austria': '奥地利', 'Azerbaijan': '阿塞拜疆', 'Burundi': '布隆迪', 'Belgium': '比利时', 'Benin': '贝宁', 'Burkina Faso': '布基纳法索', 'Bangladesh': '孟加拉国', 'Bulgaria': '保加利亚', 'The Bahamas': '巴哈马', 'Bosnia and Herz.': '波斯尼亚和黑塞哥维那', 'Belarus': '白俄罗斯', 'Belize': '伯利兹', 'Bermuda': '百慕大', 'Bolivia': '玻利维亚', 'Brazil': '巴西', 'Brunei': '文莱', 'Bhutan': '不丹', 'Botswana': '博茨瓦纳', 'Central African Rep.': '中非', 'Canada': '加拿大', 'Switzerland': '瑞士', 'Chile': '智利', 'China': '中国', 'Ivory Coast': '象牙海岸', 'Cameroon': '喀麦隆', 'Dem. Rep. Congo': '刚果民主共和国', 'Congo': '刚果', 'Colombia': '哥伦比亚', 'Costa Rica': '哥斯达黎加', 'Cuba': '古巴', 'N. Cyprus': '北塞浦路斯', 'Cyprus': '塞浦路斯', 'Czech Rep.': '捷克', 'Germany': '德国', 'Djibouti': '吉布提', 'Denmark': '丹麦', 'Algeria': '阿尔及利亚', 'Ecuador': '厄瓜多尔', 'Egypt': '埃及', 'Eritrea': '厄立特里亚', 'Spain': '西班牙', 'Estonia': '爱沙尼亚', 'Ethiopia': '埃塞俄比亚', 'Finland': '芬兰', 'Fiji': '斐', 'Falkland Islands': '福克兰群岛', 'France': '法国', 'Gabon': '加蓬', 'United Kingdom': '英国', 'Georgia': '格鲁吉亚', 'Ghana': '加纳', 'Guinea': '几内亚', 'Gambia': '冈比亚', 'Guinea Bissau': '几内亚比绍', 'Eq. Guinea': '赤道几内亚', 'Greece': '希腊', 'Greenland': '格陵兰', 'Guatemala': '危地马拉', 'French Guiana': '法属圭亚那', 'Guyana': '圭亚那', 'Honduras': '洪都拉斯', 'Croatia': '克罗地亚', 'Haiti': '海地', 'Hungary': '匈牙利', 'Indonesia': '印度尼西亚', 'India': '印度', 'Ireland': '爱尔兰', 'Iran': '伊朗', 'Iraq': '伊拉克', 'Iceland': '冰岛', 'Israel': '以色列', 'Italy': '意大利', 'Jamaica': '牙买加', 'Jordan': '约旦', 'Japan': '日本', 'Kazakhstan': '哈萨克斯坦', 'Kenya': '肯尼亚', 'Kyrgyzstan': '吉尔吉斯斯坦', 'Cambodia': '柬埔寨', 'Korea': '韩国', 'Kosovo': '科索沃', 'Kuwait': '科威特', 'Lao PDR': '老挝', 'Lebanon': '黎巴嫩', 'Liberia': '利比里亚', 'Libya': '利比亚', 'Sri Lanka': '斯里兰卡', 'Lesotho': '莱索托', 'Lithuania': '立陶宛', 'Luxembourg': '卢森堡', 'Latvia': '拉脱维亚', 'Morocco': '摩洛哥', 'Moldova': '摩尔多瓦', 'Madagascar': '马达加斯加', 'Mexico': '墨西哥', 'Macedonia': '马其顿', 'Mali': '马里', 'Myanmar': '缅甸', 'Montenegro': '黑山', 'Mongolia': '蒙古', 'Mozambique': '莫桑比克', 'Mauritania': '毛里塔尼亚', 'Malawi': '马拉维', 'Malaysia': '马来西亚', 'Namibia': '纳米比亚', 'New Caledonia': '新喀里多尼亚', 'Niger': '尼日尔', 'Nigeria': '尼日利亚', 'Nicaragua': '尼加拉瓜', 'Netherlands': '荷兰', 'Norway': '挪威', 'Nepal': '尼泊尔', 'New Zealand': '新西兰', 'Oman': '阿曼', 'Pakistan': '巴基斯坦', 'Panama': '巴拿马', 'Peru': '秘鲁', 'Philippines': '菲律宾', 'Papua New Guinea': '巴布亚新几内亚', 'Poland': '波兰', 'Puerto Rico': '波多黎各', 'Dem. Rep. Korea': '朝鲜', 'Portugal': '葡萄牙', 'Paraguay': '巴拉圭', 'Qatar': '卡塔尔', 'Romania': '罗马尼亚', 'Russia': '俄罗斯', 'Rwanda': '卢旺达', 'W. Sahara': '西撒哈拉', 'Saudi Arabia': '沙特阿拉伯', 'Sudan': '苏丹', 'S. Sudan': '南苏丹', 'Senegal': '塞内加尔', 'Solomon Is.': '所罗门群岛', 'Sierra Leone': '塞拉利昂', 'El Salvador': '萨尔瓦多', 'Somaliland': '索马里兰', 'Somalia': '索马里', 'Serbia': '塞尔维亚', 'Suriname': '苏里南', 'Slovakia': '斯洛伐克', 'Slovenia': '斯洛文尼亚', 'Sweden': '瑞典', 'Swaziland': '斯威士兰', 'Syria': '叙利亚', 'Chad': '乍得', 'Togo': '多哥', 'Thailand': '泰国', 'Tajikistan': '塔吉克斯坦', 'Turkmenistan': '土库曼斯坦', 'East Timor': '东帝汶', 'Trinidad and Tobago': '特里尼达和多巴哥', 'Tunisia': '突尼斯', 'Turkey': '土耳其', 'Tanzania': '坦桑尼亚', 'Uganda': '乌干达', 'Ukraine': '乌克兰', 'Uruguay': '乌拉圭', 'United States': '美国', 'Uzbekistan': '乌兹别克斯坦', 'Venezuela': '委内瑞拉', 'Vietnam': '越南', 'Vanuatu': '瓦努阿图', 'West Bank': '西岸', 'Yemen': '也门', 'South Africa': '南非', 'Zambia': '赞比亚', 'Zimbabwe': '津巴布韦', 'Comoros': '科摩罗' }完整代码如下: import pandas as pd from pyecharts import options as opts from pyecharts.charts import Map,Timeline,Pie,Page,Line data = pd.read_excel(r"C:\Users\Crown\Desktop\附件1.xlsx",header = 0,sheet_name=2)#导入国际疫情数据 name_map = {。。。}#参考上面 tr = Timeline().add_schema(play_interval=1000, height=40, is_loop_play=True, is_auto_play=True, control_position="left", is_rewind_play=False) tl = Timeline().add_schema(play_interval=1000, height=40, is_loop_play=True, is_auto_play=True, control_position="left", is_rewind_play=False) # 时间轴 list1 = [] # 存放日期 list2 = [] # 存放确诊人数 list3 = [] # 存放治愈人数 list4 = [] # 存放死亡人数 for i in range(1, 7): # 以月为单位进行遍历 得到1月到i月各个省份的累计确诊,治愈,死亡人数 list1.append("2020-0{}".format(i)) # 存入日期 data2 = data data2['日期'] = pd.to_datetime(data2['日期']) # 转换日期类型 data2 = data2.set_index('日期') # 将日期作为索引 data2 = data2.sort_index() # 对日期进行排序 以便于对其进行切分 if i % 2 == 1: # 1,3,5月 data2 = data2.truncate('2020-01', '2020-0{}-31'.format(i)) # 对数据进行切分,得到1月到i月的全部数据 else: if i == 2: # 2月 data2 = data2.truncate('2020-01', '2020-0{}-28'.format(i)) # 对数据进行切分,得到1月到i月的全部数据 else: # 4,6月 data2 = data2.truncate('2020-01', '2020-0{}-30'.format(i)) # 对数据进行切分,得到1月到i月的全部数据 data2 = data2.groupby('日期', as_index=False).sum() data2['日期'] = '2020-0{}'.format(i) # 加入日期列 list2.append(int(data2.groupby('日期', as_index=False).sum()['累计确诊'])) # 存入确诊人数 list3.append(int(data2.groupby('日期', as_index=False).sum()['累计治愈'])) # 存入治愈人数 list4.append(int(data2.groupby('日期', as_index=False).sum()['累计死亡'])) # 存入死亡人数 for i in range(1, 7): # 以月为单位进行遍历 data1 = data data1['日期'] = pd.to_datetime(data1['日期']) # 转换日期类型 data1 = data1.set_index('日期') # 将日期作为索引 data1 = data1.sort_index() # 对日期进行排序 以便于对其进行切分 if i % 2 == 1: data1 = data1.truncate('2020-01', '2020-0{}-31'.format(i)) else: if i == 2: data1 = data1.truncate('2020-01', '2020-0{}-28'.format(i)) else: data1 = data1.truncate('2020-01', '2020-0{}-30'.format(i)) data1 = data1.groupby('国家', as_index=False).max() # 对1月到i月的各个省份的各项数据取最大值 data1['日期'] = '2020-0{}'.format(i) # 加入日期列 data2 = data1 data2 = data2.sort_values(by='累计确诊', ascending=False) # 从大到小排序‘新增确诊’这一列,方便得到累计确诊人数前五的省份 x = data2['国家'].tolist() # 转换为list y = data2['累计确诊'].tolist() map = ( # 进行大屏显示 画图 Map() .add(series_name="确诊病例", # 系列名称,用于 tooltip 的显示,legend 的图例筛选。 data_pair=[list(z) for z in zip(x, y)], # 数据项 (坐标点名称,坐标点值) maptype='world', # 地图类型 is_map_symbol_show=True, name_map=name_map) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( # 全局配置项 title_opts=opts.TitleOpts(title='疫情地图'), # title_opts = opts.TitleOpts()主标题函数 visualmap_opts=opts.VisualMapOpts( # visualmap_opts=opts.VisualMapOpts()视觉映射函数 is_piecewise=True, # 是否分段 # 自定义的每一段的范围,以及每一段的文字,以及每一段的特别的样式。 pieces=[{"max": 9, "min": 0, "label": "0-9", "color": "#FFECEC"}, {"max": 99, "min": 10, "label": "10-99", "color": " #FFB5B5"}, {"max": 499, "min": 100, "label": "100-4999", "color": "#ff7575"}, {"max": 999, "min": 500, "label": "500-999", "color": "#FF2D2D"}, {"max": 9999, "min": 1000, "label": "1000-9999", "color": " #EA0000"}, {"max": 99999, "min": 10000, "label": "10000-99999", "color": "#AE0000"}, {"max": 999999, "min": 100000, "label": "100000-999999", "color": " #750000"}, {"max": 99999999999, "min": 100000, "label": ">999999", "color": "#4D0000"}] ) ) ) pie = ( # 画饼图 Pie() .add( series_name="累计确诊", radius=["40%", "55%"], data_pair=[list(z) for z in zip(x[:3], y[:3])], # 前3个省份 label_opts=opts.LabelOpts( position="outside", formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ", background_color="#eee", border_color="#aaa", border_width=1, border_radius=4, rich={ "a": {"color": "#999", "lineHeight": 22, "align": "center"}, "abg": { "backgroundColor": "#e3e3e3", "width": "100%", "align": "right", "height": 22, "borderRadius": [4, 4, 0, 0], }, "hr": { "borderColor": "#aaa", "width": "100%", "borderWidth": 0.5, "height": 0, }, "b": {"fontSize": 16, "lineHeight": 33}, "per": { "color": "#eee", "backgroundColor": "#334455", "padding": [2, 4], "borderRadius": 2, }, }, ) ) .set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", orient="vertical")) .set_series_opts( tooltip_opts=opts.TooltipOpts( trigger="item", formatter="{a} {b}: {c} ({d}%)" ) ) ) line = ( # 画折线图 Line() .add_xaxis(xaxis_data=list1) .add_yaxis("累计确诊人数", y_axis=list2, is_smooth=True) .add_yaxis("累计治愈人数", y_axis=list3, is_smooth=True) .add_yaxis("累计确诊死亡", y_axis=list4, is_smooth=True) .set_series_opts( areastyle_opts=opts.AreaStyleOpts(opacity=0.5), label_opts=opts.LabelOpts(is_show=False), ) .set_global_opts( title_opts=opts.TitleOpts(title="全国疫情"), tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"), yaxis_opts=opts.AxisOpts( type_="value", axistick_opts=opts.AxisTickOpts(is_show=True), splitline_opts=opts.SplitLineOpts(is_show=True), ), xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False), ) ) tl.add(pie, "2020-0{}".format(i)) # 将不同日期的数据加入到timeline中 tr.add(map, "2020-0{}".format(i)) # 将不同日期的数据加入到timeline中 page = Page(layout=Page.DraggablePageLayout) # 合并在一页 page.add(tr, tl, line) page.render('全球疫情.html') # 将结果保存结果如下: 大致可以分为一下三个阶段: 1.疫情不断恶化:确诊人数不断增长 2.疫情基本稳定:住院人数基本稳定(住院人数 = 确诊 - 治愈 - 死亡) 3.疫情好转:住院人数不断减少 画出各个国家的累计确诊人数和住院人数的折线图可以看出。 代码如下: import pandas as pd from pyecharts import options as opts from pyecharts.charts import Line,Page data = pd.read_excel(r"C:\Users\Crown\Desktop\附件1.xlsx",header = 0,sheet_name=2)#导入国际疫情数据 list = ['印度','伊朗','意大利','加拿大','秘鲁','南非'] page = Page(layout=Page.DraggablePageLayout) # 合并在一页 for i in list:#遍历 data1 = data[data['国家'] == i]#取只含一个国家的数据 line = ( Line() .add_xaxis(xaxis_data=data1['日期']) .add_yaxis("累计确诊人数", y_axis=data1['累计确诊']) .add_yaxis("住院人数",y_axis= data1['累计确诊']-(data1['累计治愈'] + data1['累计死亡'])) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( title_opts=opts.TitleOpts(title=data1['国家'][data1['国家'].index[0]]), tooltip_opts=opts.TooltipOpts(trigger="axis"), toolbox_opts=opts.ToolboxOpts(is_show=True), xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False,), ) ) page.add(line) page.render('疫情发展.html')
同样,画出折线图再对照附件2便能推出的疫情防控措施对本国疫情变化情况的影响。 代码: import pandas as pd from pyecharts import options as opts from pyecharts.charts import Line,Page data = pd.read_excel(r"C:\Users\Crown\Desktop\附件1.xlsx",header = 0,sheet_name=2)#导入国际疫情数据 list = ['美国','英国','俄罗斯'] page = Page(layout=Page.DraggablePageLayout) # 合并在一页 for i in list: data1 = data[data['国家'] == i] line = ( Line() .add_xaxis(xaxis_data=data1['日期']) .add_yaxis("累计确诊人数", y_axis=data1['累计确诊']) .add_yaxis("住院人数",y_axis= data1['累计确诊']-(data1['累计治愈'] + data1['累计死亡'])) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( title_opts=opts.TitleOpts(title=data1['国家'][data1['国家'].index[0]]), tooltip_opts=opts.TooltipOpts(trigger="axis"), toolbox_opts=opts.ToolboxOpts(is_show=True), xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False,), ) ) page.add(line) page.render('部分国家疫情防控.html') 美国:
点击下载附件1 |
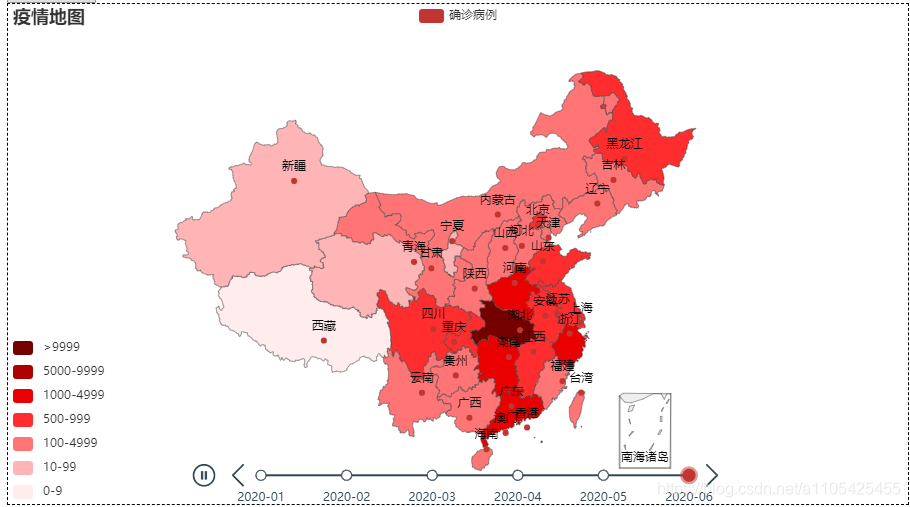 pie:
pie: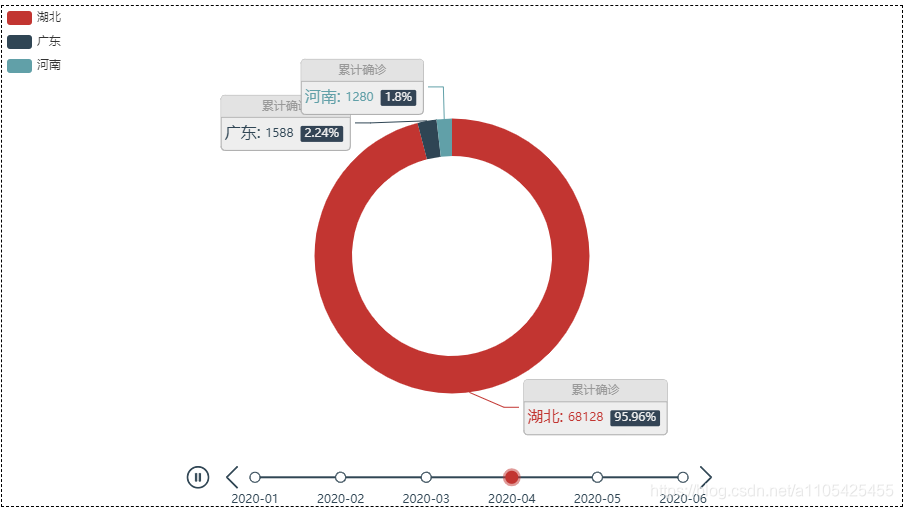 line:
line: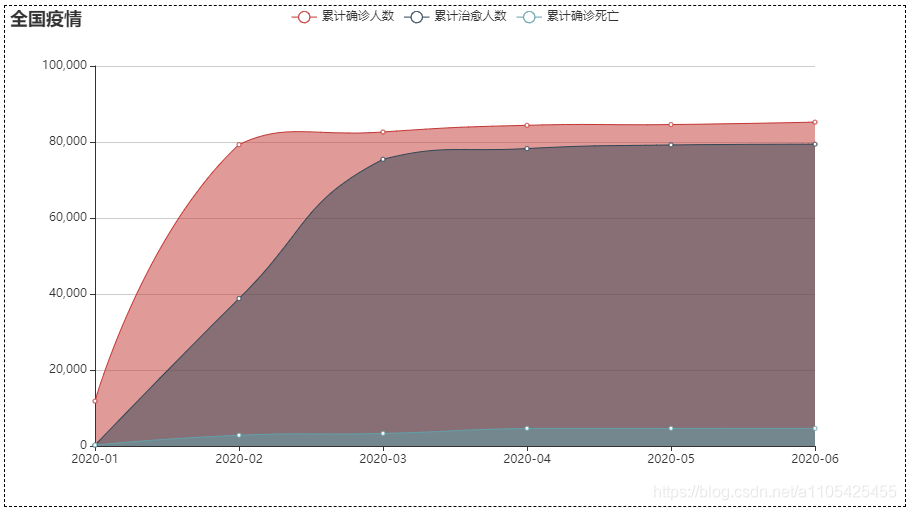
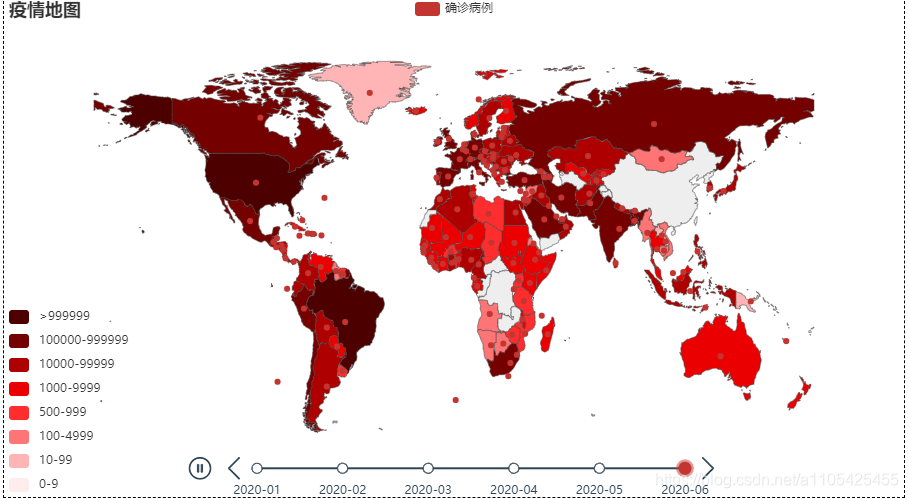
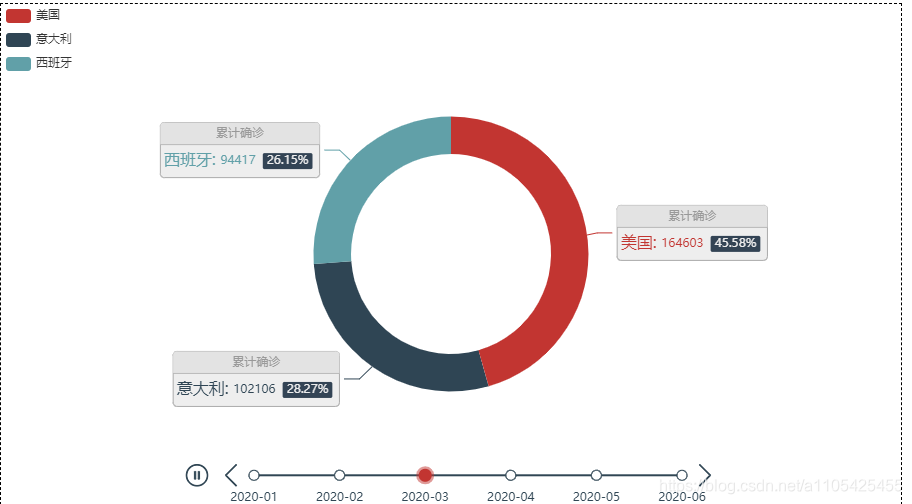
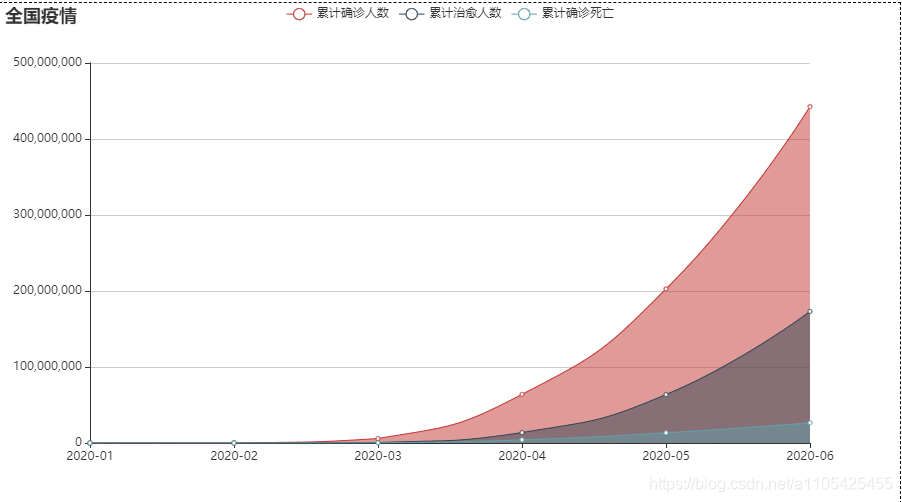
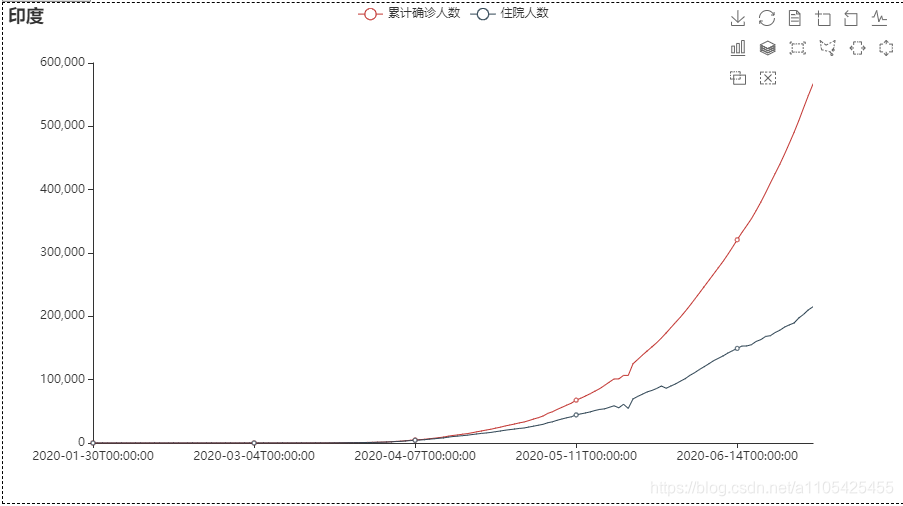
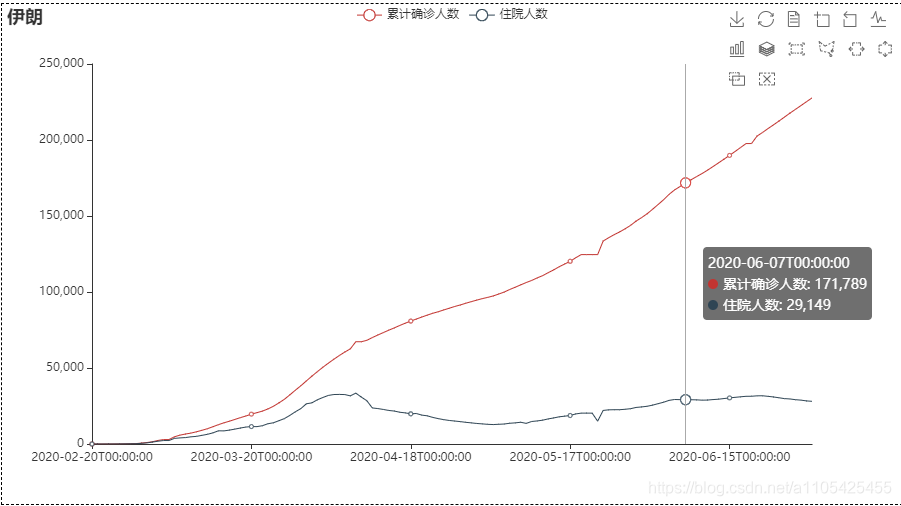
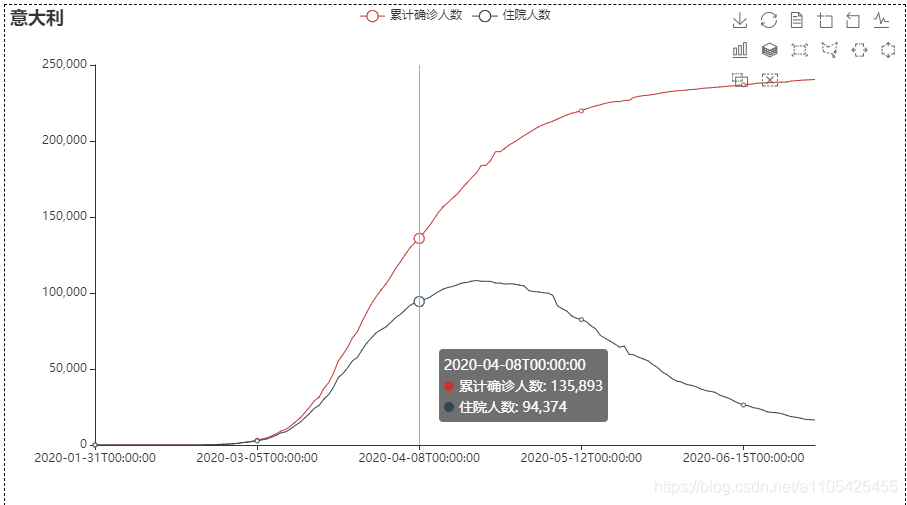
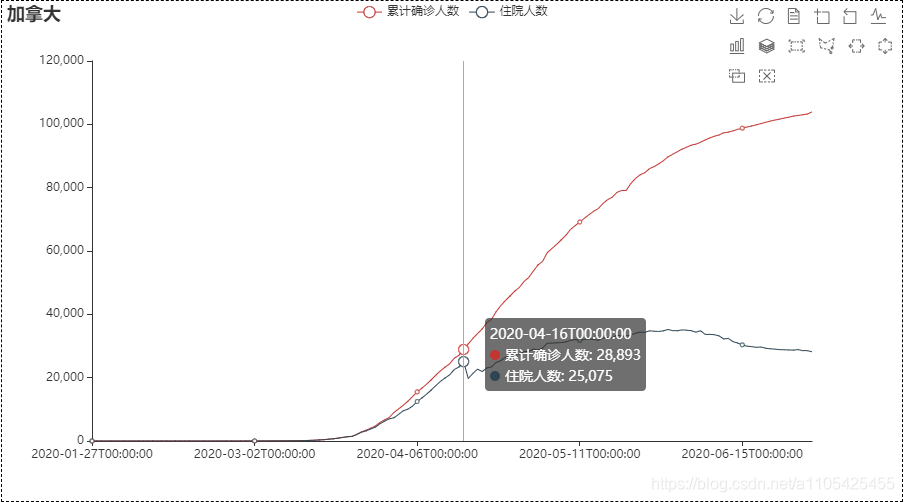
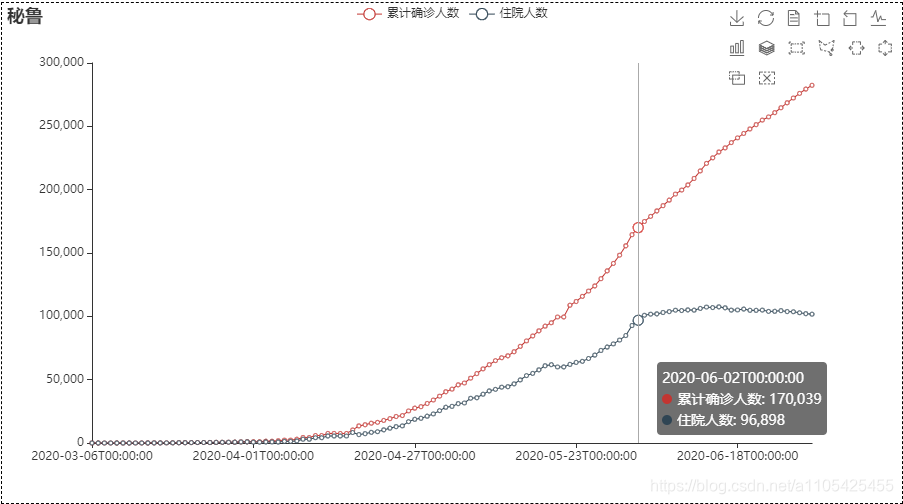
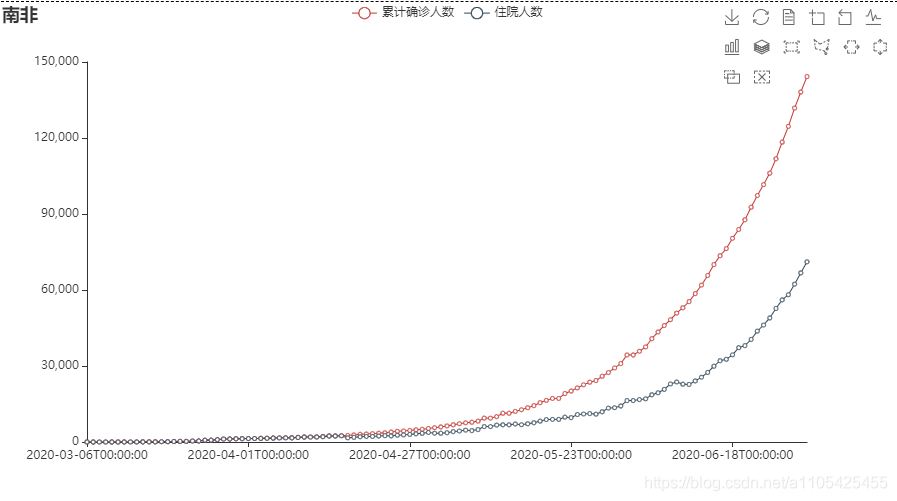 结合上述折线图分析可得:
结合上述折线图分析可得:

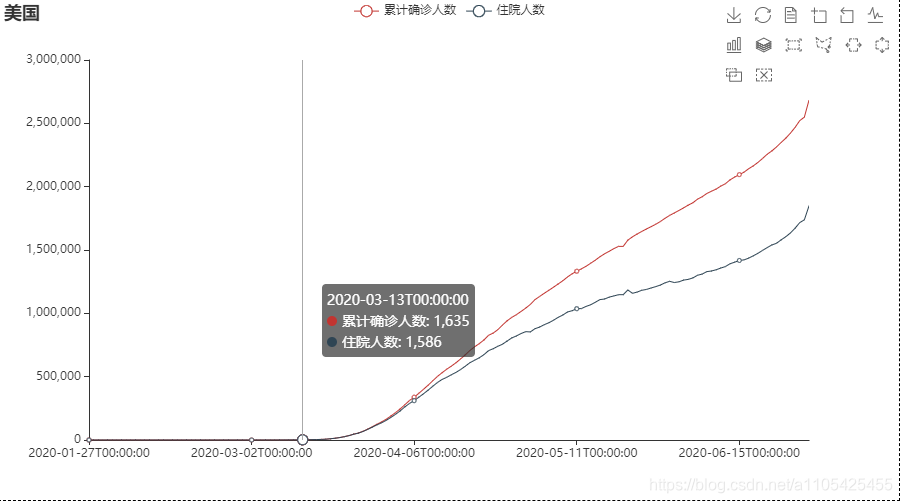
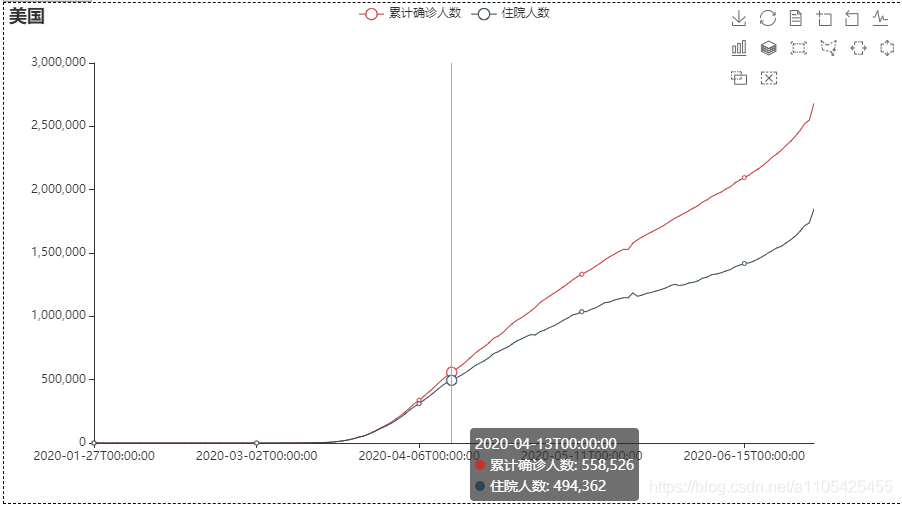 可以看出,措施举行后累计确诊人数和住院人数仍然大幅度上升,可见效果一般。
可以看出,措施举行后累计确诊人数和住院人数仍然大幅度上升,可见效果一般。
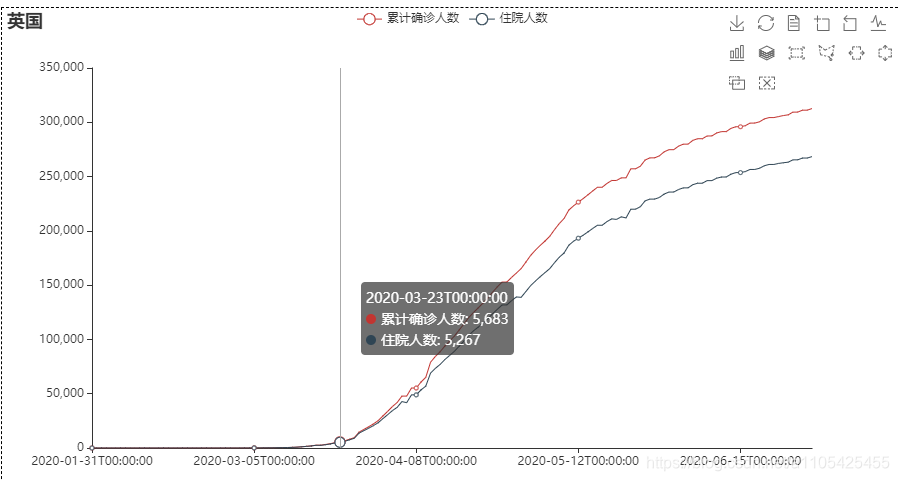 措施实施后,累计确诊人数和住院人数仍然大幅度上升,直到05-14左右,才较为缓慢的上升,可见措施实施一段时间后具有较好的作用。
措施实施后,累计确诊人数和住院人数仍然大幅度上升,直到05-14左右,才较为缓慢的上升,可见措施实施一段时间后具有较好的作用。
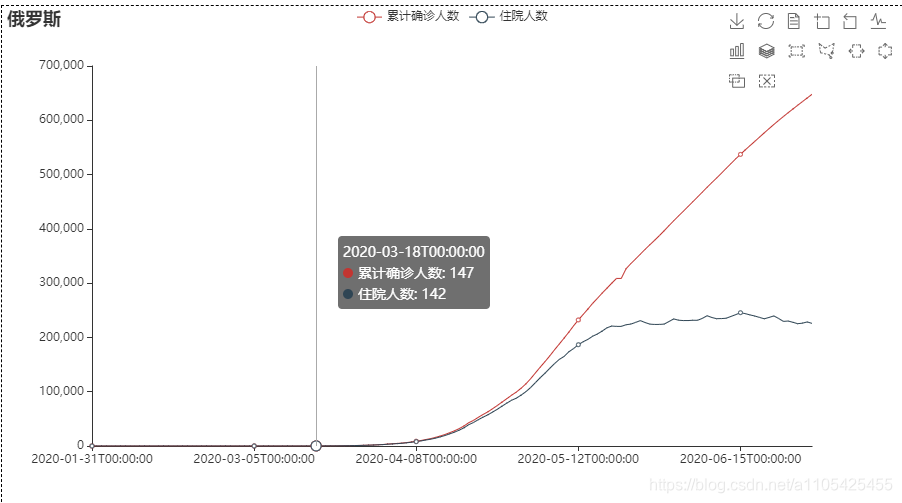
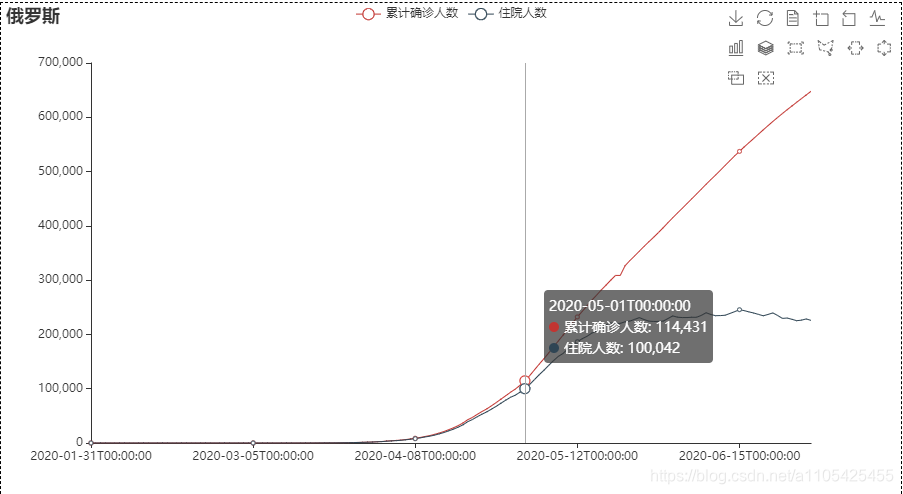 措施实施后,累计确诊人数和住院人数仍然大幅度上升,直到05-18左右,住院人数基本平稳,可见措施实施一段时间后具有很好的作用。
措施实施后,累计确诊人数和住院人数仍然大幅度上升,直到05-18左右,住院人数基本平稳,可见措施实施一段时间后具有很好的作用。【本文地址】
今日新闻 |
推荐新闻 |