简单理解springboot的依赖注入 |
您所在的位置:网站首页 › 依赖注入有哪些方式 › 简单理解springboot的依赖注入 |
简单理解springboot的依赖注入
|
依赖注入,Dependency Injection,简称DI,是spring中的核心技术,此技术贯穿Spring全局,是必须要熟练掌握的知识点。 在本文中,我们将要深入研究spring中的IOC和DI,理解核心思想,并学会如何在spring boot中使用基于java和注解的方式正确使用DI来创建spring应用程序。 控制反转 IOC要理解DI,首先需要理解spring的核心思想之一,控制反转(Inversion of Control,简称IOC),下面将通过一个简单的例子来演示什么是IOC,以及解释为什么IOC是一种优秀的思想。 首先,创建一个spring boot项目,来模拟一个简单的场景。 根据MVC的分层思想,模拟一个简单的分层(与实际开发中的分层有区别): sql层:模拟数据库映射DAO层:模拟数据库交互Service层:模拟服务层,实现主要的业务逻辑
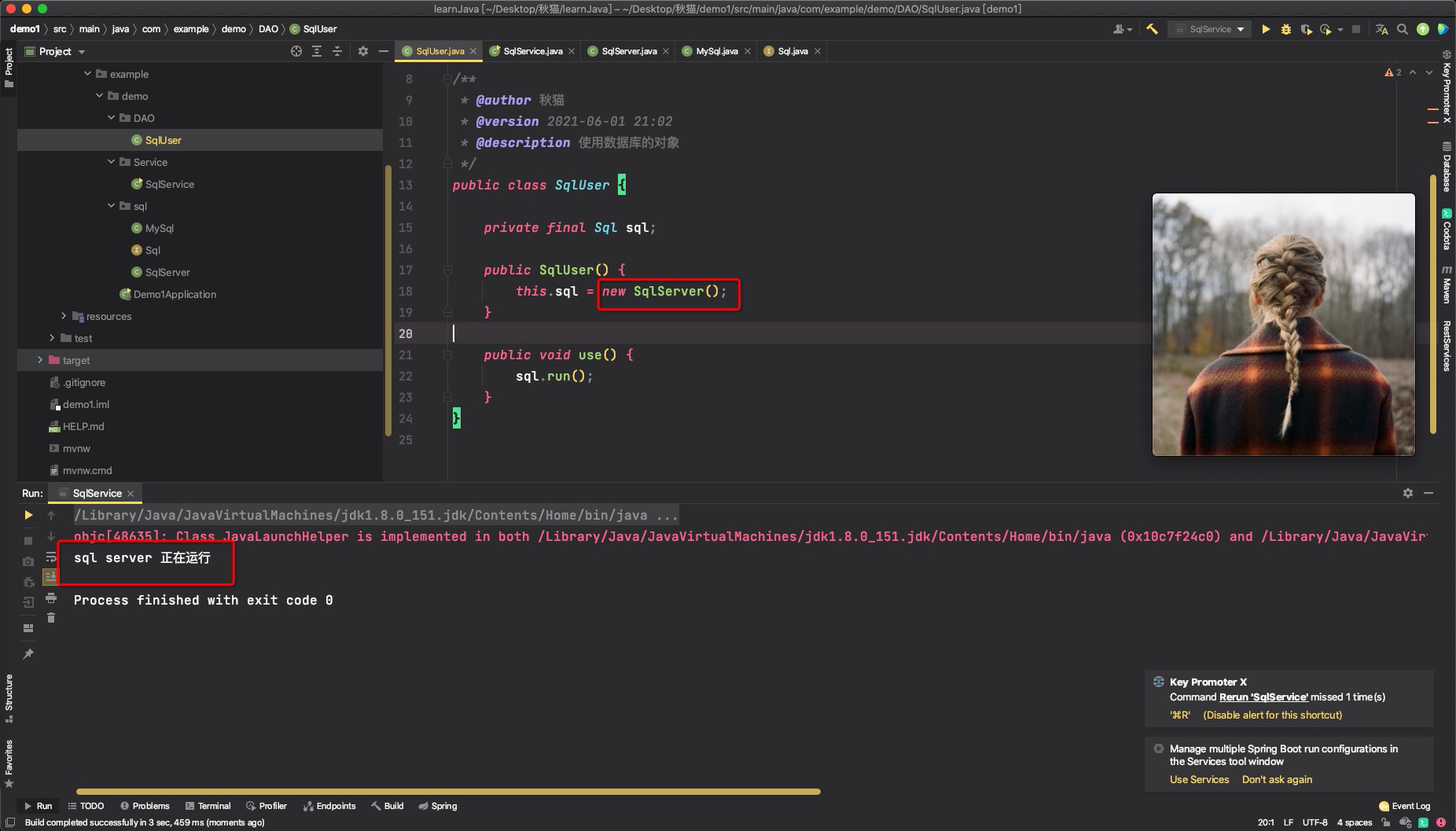
跟预想的一样,SqlUser正确使用了MySQL数据库。 我们现在要把这几个类都想象成一个个的对象,SqlUser是向SqlService提供服务的,而不是程序员作为上帝它们向我们提供服务。现在SqlService觉得MySql不好用,想换成SqlServer数据库,它要求SqlUser能支持SqlServer数据库。 但是现在Sql底层还不支持SqlServer怎么办? SqlUser又去要求Sql接口能够提供SqlServer的实现。 Sql觉得这个简单,直接新增一个实现类就OK了: public class SqlServer implements Sql{ @Override public void run() { System.out.println("sql server 正在运行"); } }SqlUser这里怎么改成对SqlServer的支持呢? 一个最笨的办法:把MySql对象全部换成SqlServer(注意思考这个过程中我们做了什么) public class SqlUser { private final SqlServer sqlServer; public SqlUser() { this.sqlServer = new SqlServer(); } public void use() { sqlServer.run(); } }SqlService不需要修改任何代码即可切换到使用SqlServer
现在看上去似乎皆大欢喜? 问题又来了,用了一段时间SqlService觉得SqlServer不好用,想切换回MySql怎么办? 照之前的办法,SqlUser中的所有SqlServer对象还得全部换成MySql,我们现在只有十行代码,觉得还可以接受,如果项目后期,SqlUser中有一千行代码呢,一百个对SqlServer的引用怎么办? 聪明一点的办法:使用多态。SqlUser中SqlServer的声明改为Sql接口,构造器中还是给sql new一个SqlServer对象,后面的逻辑代码中调用Sql对象接口,这样的话如果再需要更改sql的实现,只需要在构造器中将new SqlServer改为new MySql即可,需要修改的代码量大大减少。 public class SqlUser { private final Sql sql; public SqlUser() { this.sql = new MySql(); } public void use() { sql.run(); } }
虽然现在SqlUser自身代码的耦合性降低了,但是在业务逻辑上看,SqlUser与Sql层的耦合性还是很高,因为SqlService每次想要调用不同的服务,SqlUser都需要去修改代码。 这个时候SqlUser不服了,为什么每次SqlService的需求在变,却要我修改代码? 有没有一种方法,SqlService想要SqlUser实现哪个功能就调用哪个功能,SqlUser只用躺平,再也不用参与到SqlService与Sql的爱恨情仇之中了呢?(这里可能有人会问,如果这样的话,把SqlUser层存在的意义是什么呢?答案是解耦。想一下,如果SqlService直接去调用Sql,那SqlService的处境不是和现在的SqlUser一样了吗?每次有新的需求都需要去修改大量的代码。) 既然这么问了,那肯定是有的,这就是本节的主题IOC了,如果把SqlUser改成这样: public class SqlUser { private final Sql sql; // 区别在这 public SqlUser(Sql sql) { this.sql = sql; } public void use() { sql.run(); } }仔细对比一下两种构造器的区别 // 旧 public SqlUser() { this.sql = new MySql(); }// 新 public SqlUser(Sql sql) { this.sql = sql; }仔细思考一下哪里不同! 旧的构造器中,sql对象的控制权在SqlUser自己的手里,指定哪一个实现由SqlUser控制。 新的构造器中,sql对象的控制权在调用SqlUser的对象手里,调用SqlUser的对象想要使用哪一个实现就在构造器中传入哪一个实现。 完成了控制权的反转!这就是IOC。 但构造器只是IOC实现的一种方式,还有其他的实现方式会在后面的小节中讨论。 现在看看SqlService使用SqlUser对象的方式有哪些改变: public class SqlService { private final SqlUser sqlUser; public SqlService() { // 区别在这 sqlUser = new SqlUser(new MySql()); } public void service() { sqlUser.use(); } public static void main(String[] args) { SqlService sqlService = new SqlService(); sqlService.service(); } }现在SqlService构造器中需要明确指定想要使用的Sql实现是哪一种,并传入一个实现对象,这时SqlUser已经完全解脱了,自己什么都不用做,就可以轻松应对SqlService的各种需求。 那么有人又要问了,这么做SqlUser是解脱了,但是SqlService的使用不是变麻烦了吗?那不是一样的吗? 其实非也。对于SqlService来说,它的自主性更高了,以前它只能使用SqlUser提供的功能,而现在它可以自由选择。把SqlUser想象成社交软件,把SqlService想象成我们用户,按照之前的方式我们只可以使用软件提供的昵称、头像,软件给你什么你就用什么,而现在我们可以自定义,想用什么就用什么,孰优孰劣一想便知。 依赖注入 DI搞清楚什么是IOC之后,可以来看看DI了。IOC只是一种设计模式,一种思想,IOC有很多的实现方式,DI就是IOC的一种强大的实现方式。 再来看上一小节的例子,SqlUser实现了控制反转,但是SqlService还没有,SqlUser对象的控制权还是在自己的手中。那么SqlService对SqlUser的控制权可以交给谁呢?答案是IOC容器。 继续思考,对于上面的这个SqlService的使用变麻烦的问题,我给出的解释是SqlService的自主性变高了,但不可避免的是,使用确实变得复杂了,以前只需要新建一个SqlUser对象,现在还需要再新建一个Sql的实现对象。 这就引申出另一个问题,在创建SqlUser对象之前,必须先有Sql实现对象,它们之间形成了依赖关系。
如果项目变得更庞大,依赖关系复杂起来,可能会变成这个样子
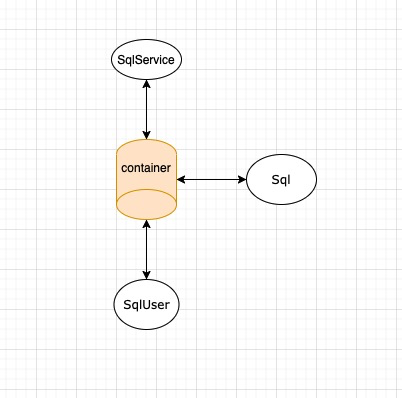
可以看出,对象之间的耦合性还是很高,如果一个被依赖的对象没有被创建,那么这个依赖的对象也无法成功运行。 对象之间的依赖关系生活中有许多形象的例子,而且生活中的做法已经给出了答案。 我要举的例子就是对象..."找对象"的那个对象,就说相亲吧。 一个单身男性想要找女朋友,他需要先有一个目标,一个单身女性。才可以去做其他的事情,比如追求、表白、求婚、结婚等等。但是他也是有要求的,身高、颜值等等,这就导致这个单身女性目标不好找,没有目标的话,追求、表白等等这些事情也就无法进行。他觉得目标实在太难找了,就去找了婚介所,里面有很多的单身女性,婚介所可以按照你的要求挑选合适的目标,同时他也作为婚介所中的单身男性之一,可以被婚介所提供给其他单身女性。 很好理解吧?现在就使用面向对象的方法解释一下这个例子。 把男性看作是一个对象man,man有一些方法,这些方法是追求、表白、求婚、结婚,但是man依赖于另一个对象woman,如果woman没有创建,man就没法执行这些方法,我们就说man和woman之间的耦合性很高。把婚介所看作一个容器container,container里有许许多多各种各样的man和woman,因为他们有不同的特征,所以代表了man和woman接口的实现或者基类的继承。 man现在想要执行结婚方法,container就会把man想要的woman给man,实现上称为把woman注入到man,而且如果有其他的woman对象依赖与man对象,container就可以把man注入给需要的woman,这样,man与woman之间就实现了解耦。 现在让我们回到Sql的恩怨情仇中,通过上面生动形象的讲解,应该可以理解这幅图了:
创建一个公共的容器,所有创建的对象都放到容器中,如果有对象对其他对象产生了依赖,容器将主动将依赖的对象给予被依赖的对象。这样也就实现了SqlService的控制反转,现在SqlUser的控制权交给了容器。这个容器在Spring中就被称为IOC容器。IOC容器中的对象就称为Bean。 使用Spring提供的容器之前,我们先来自己实现一个简单的容器。 public static void main(String[] args) { // 容器,键值对为对象名:对象 Map container = new HashMap(20); // 向容器中注册对象 container.put("MySql", new MySql()); container.put("SqlServer", new SqlServer()); // 从容器中取出需要的依赖 MySql mySql = (MySql) container.get("MySql"); // 使用依赖向容器中注册对象 container.put("SqlUserMySql", new SqlUser(mySql)); // 取出依赖 SqlUser mySqlUser = (SqlUser) container.get("SqlUserMySql"); // 使用依赖注册对象 container.put("SqlService", new SqlService(mySqlUser)); // 取出要使用的对象 SqlService sqlService = (SqlService) container.get("SqlService"); // 使用对象 sqlService.service(); }
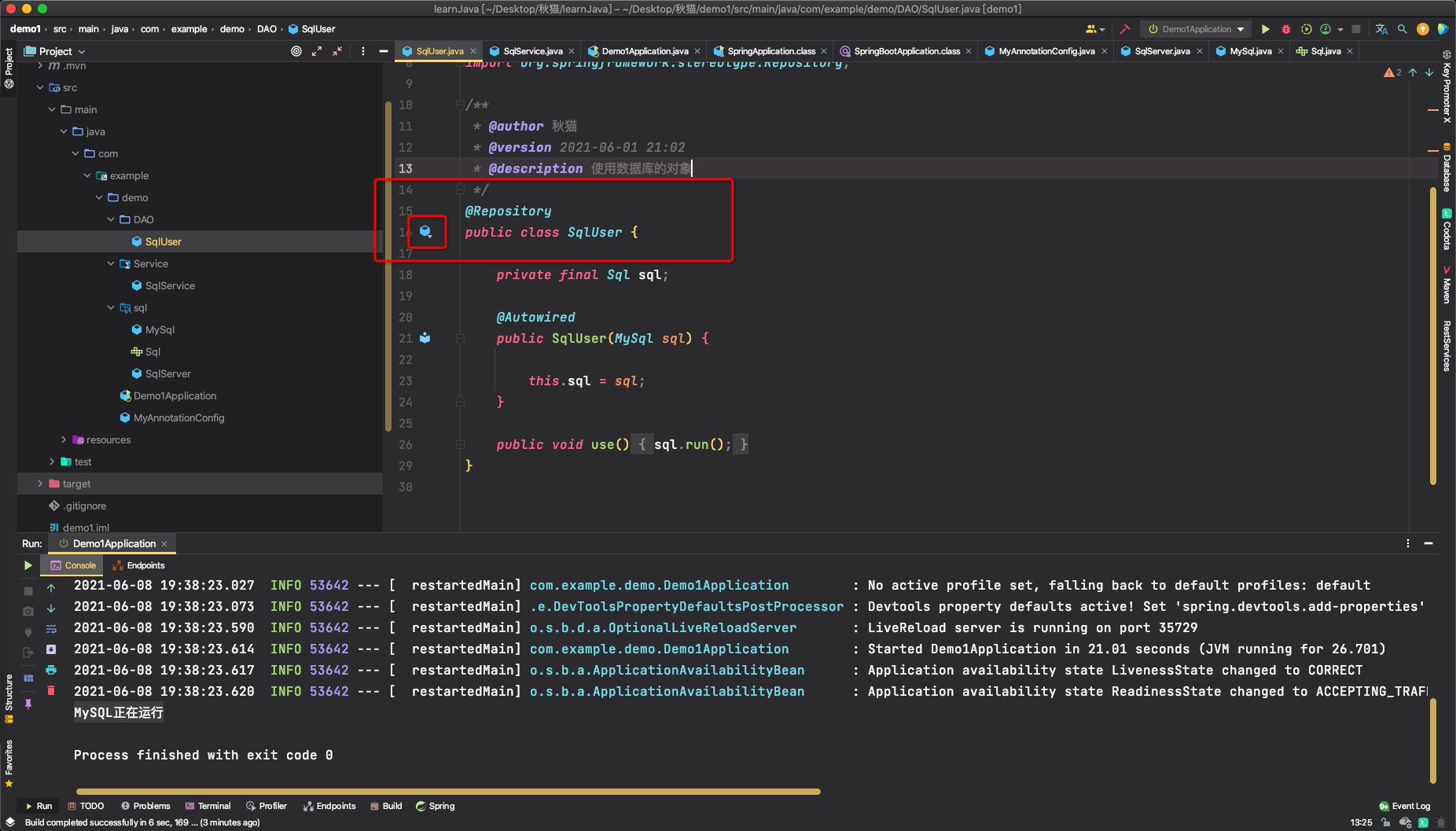
在本例中,我们用一个Map来模拟容器,并向容器中提交了两个Sql对象MySql、SqlServer。由于SqlUser依赖于Sql,所以在创建SqlUser之前,先从容器中取出MySql对象,在构造函数中使用MySql对象来创建SqlUser,并注册到容器中。创建SqlService的过程就如法炮制了。 在这个过程中可以看到,对象与对象之间的依赖关系变成了对象与容器之间的依赖关系。从对象存不存在变成了容器里有没有这个对象。 在实际的开发中,我们不需要手动的注册、取出这些对象,spring将会使用IOC容器自动帮我们完成这些操作。这个过程就称为依赖注入。 使用spring的依赖注入spring依赖注入目前最流行的方式是基于注解的自动配置 优点:配置简洁、清晰 缺点:对象间依赖关系太复杂时会头疼 除了基于注解的自动配置外,还有两种配置方式 Java配置:也是使用注解和类,与注解自动配置类似,理论上可以互相替换。 XML配置:比较老的配置方式,使用xml文件配置 没有特殊情况,都使用注解的自动配置。 自动配置主要依赖于两个注解: @Component:标记这个类是一个组件,此类将自动向容器注册Bean对象。@Autowired:可作用于属性、构造器或set方法,容器将自动注入对象。@Component此注解的定义如下 @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Indexed public @interface Component { String value() default ""; }此注解有三个拓展注解,用于标记MVC分层中的不同层,与@Component注解的作用相同,只是为了增加代码的可读性,@Component注解则表示这是一个普通的Bean。 @Controller:控制层@Service:服务层@Repository:DAO层当这四种注解之一作用于一个类时,这个类就会被自动识别为Bean,启动Spring Boot程序时,容器中就会存在这个Bean了。 在IDEA中加上此注解之后,左侧会有一个小图标的提示,表示这是一个spring bean
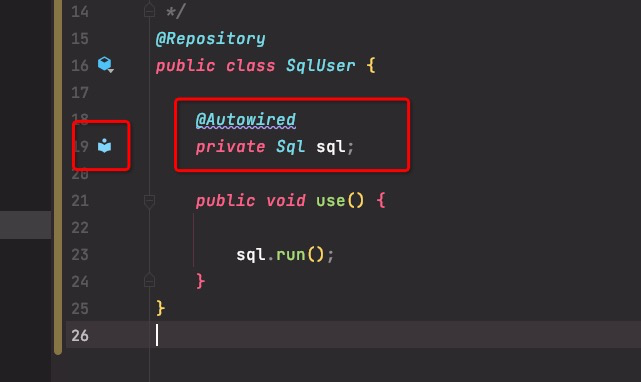
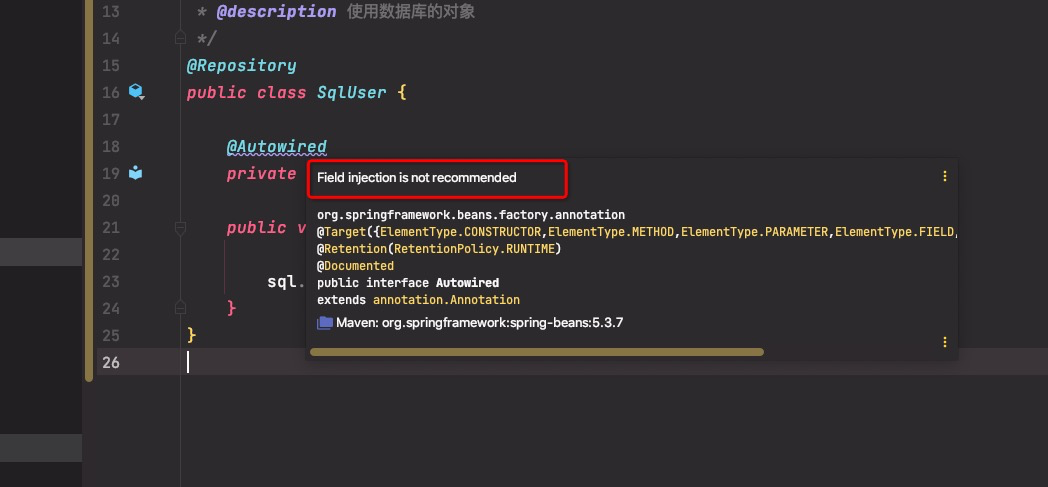
此注解的定义如下 @Target({ElementType.CONSTRUCTOR, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD, ElementType.ANNOTATION_TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface Autowired { boolean required() default true; }此注解的官方定义如下 Marks a constructor, field, setter method, or config method as to be autowired by Spring's dependency injection facilities. 标记由Spring的DI自动注入的构造器、字段、set方法或者配置方法 其中提到了三种比较常用的自动装配方法: 基于构造器的自动装配基于setter方法的自动装配基于字段的自动装配注意此注解有一个required参数,默认为true,如果容器中没有相应的bean,就会报错;当设置为false时,如果容器中没有相应的bean,不会报错,也不会注入。 基于构造的自动装配将@Autowired注解作用于一个类构造器,在对象创建之前调用构造器,可以完成对类中属性的自动注入,构造器的参数就是依赖的对象。 一个类中只能有一个构造器使用了@Autowired注解标记如果没有构造器使用@Autowired注解且存在多个构造器,将选择依赖数量最多的构造器完成注入如果没有构造器使用@Autowired注解且只存在一个构造器,将选择这个默认的构造器使用此方法注入的字段可以设置为final类型@Repository public class SqlUser { private final Sql sql; /** * 基于构造器的自动装配 */ @Autowired public SqlUser(MySql sql) { this.sql = sql; } public void use() { sql.run(); } }基于setter方法的自动装配将@Autowired注解作用于一个set方法,可以完成对类中属性的自动注入,set方法的参数就是依赖的对象。 类中的任意方法都可以完成注入,对名称、参数没有要求,setter方法是一种特殊情况,也是最常用的方法对象创建之后才会调用setter方法,因此字段不能设置为final类型@Repository public class SqlUser { private Sql sql; /** * 基于构造器的自动装配 */ @Autowired public void setSql(MySql sql) { this.sql = sql; } public void use() { sql.run(); } }基于字段的自动装配这种方法最简单,将@Autowired注解作用于类中的一个字段即可 装配时机是调用构造器之后、调用配置方法之前,因此也不可以将字段设置为final类型@Repository public class SqlUser { @Autowired private MySql sql; public void use() { sql.run(); } }三种方法的总结与比较在IDEA中使用这三种方法时都会有DI的标志
可以根据这个判断程序的依赖注入是不是正确 在使用基于字段的自动配置时,IDEA会提示 Field injection is not recommended
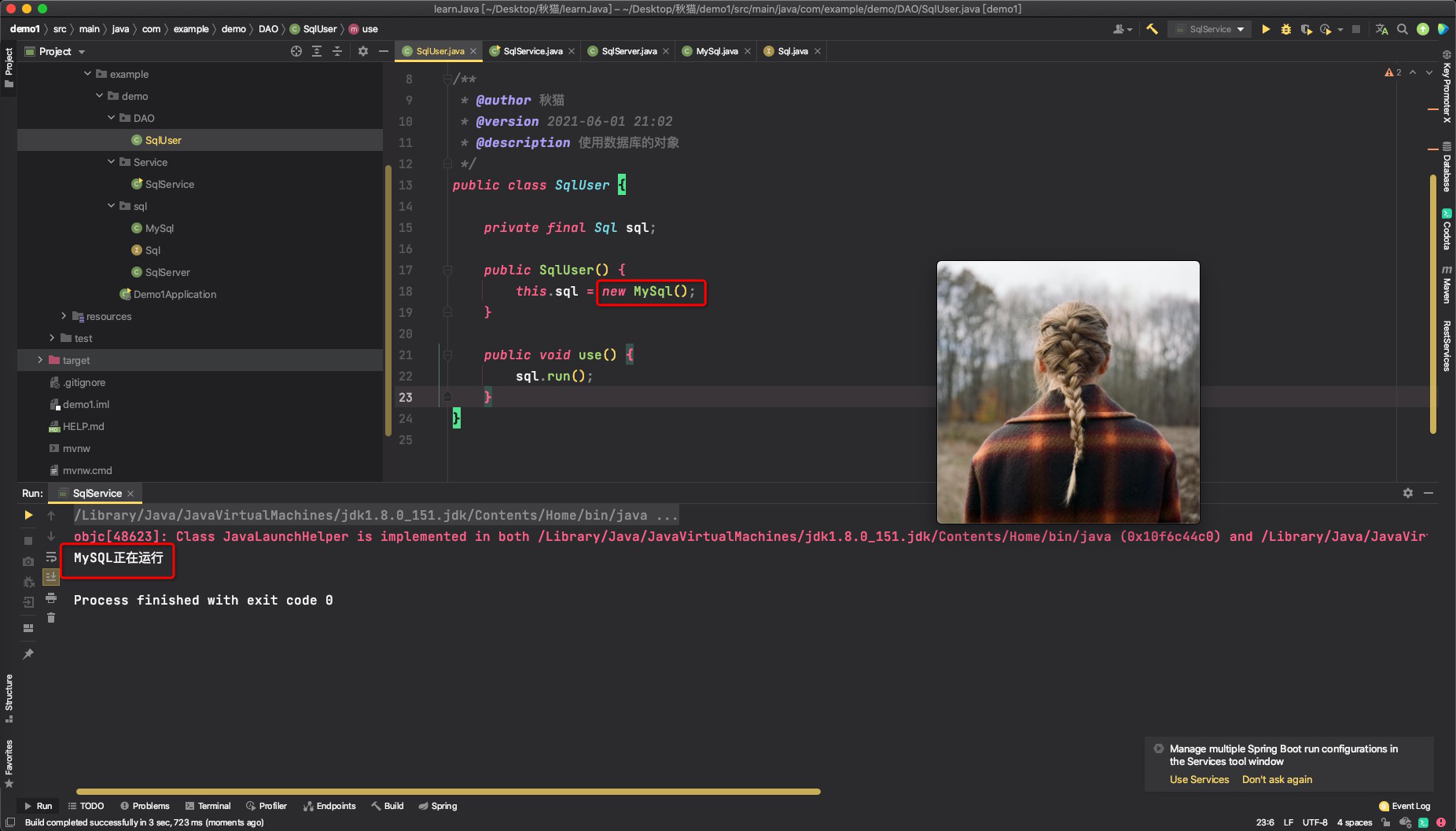
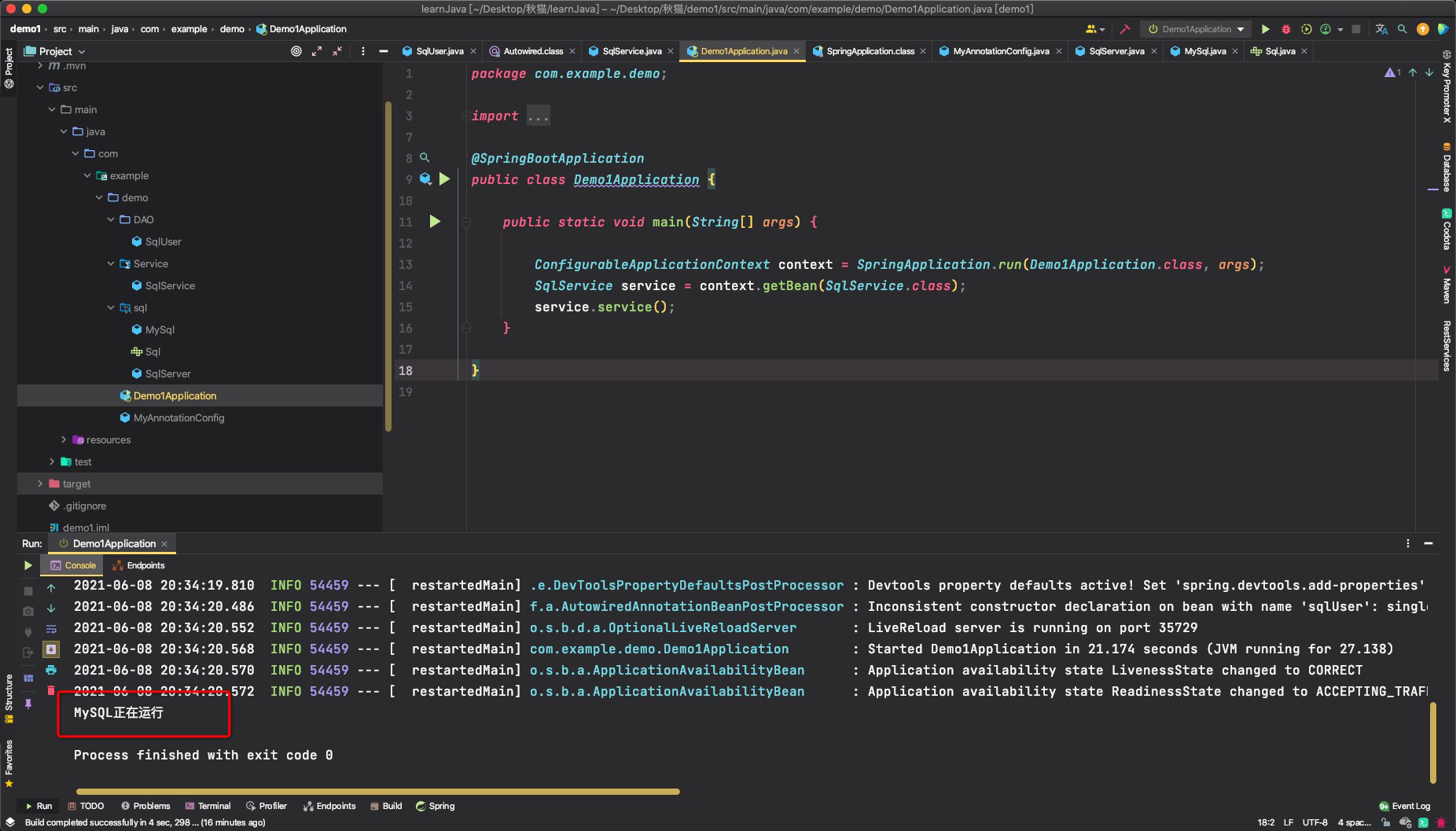
原因是现在spring boot已经不建议使用这种注入方法 这是为什么呢?下面就来看看这种方法有哪些缺点。 基于字段自动注入的缺点: 不能有效指明类的依赖。使用构造器的方式将明确指明类需要哪些依赖,使用Setter的方式表示此属性为可选依赖,而使用基于属性的方式很容易让程序员忽略需要的依赖,当bean容器中不包含此依赖时,程序将无法正常运行。违反了单一职责设计原则。使用这种方法会不自觉地给类增加过多的依赖,将违反单一职责原则。增加了耦合性。使用这种方法意味着你不能向一个接口类注入它的任意实现类,因为同时具有多个实现类时,IOC将不知道注入哪一个。至于另外两种方法的使用,都可以达到相同的效果,下面是一些建议 对于必须的依赖,使用构造器注入,并将相应字段设置为final,可以指导使用别人正确地构造对象对于可选的依赖,使用setter注入,@Autowired注解中设置required=false最后 在我们例子的各类中增加@Component、@Autowired,将这些对象都交给IOC容器管理 @Component public class MySql implements Sql{ @Override public void run() { System.out.println("MySQL正在运行"); } }@Repository public class SqlUser { private final Sql sql; @Autowired(required = false) public SqlUser(MySql sql) { this.sql = sql; } public void use() { sql.run(); } }@Component public class SqlService { private final SqlUser sqlUser; @Autowired public SqlService(SqlUser sqlUser) { this.sqlUser = sqlUser; } public void service() { sqlUser.use(); } }在spring boot的启动类中添加如下代码 @SpringBootApplication public class Demo1Application { public static void main(String[] args) { ConfigurableApplicationContext context = SpringApplication.run(Demo1Application.class, args); SqlService service = context.getBean(SqlService.class); service.service(); } }关于启动类的问题,不是本文的主题,就不在此讨论了。只需要关注一个方法: getBean(SqlService.class) 此方法其实就是利用反射主动从IOC容器中获取Bean对象。 我们运行这个启动类。
可以看到,整个程序没有使用到一个new,就完成了所有对象的管理,这就是Spring的依赖注入! |



【本文地址】
今日新闻 |
推荐新闻 |