一种基于人脸表情识别的个性化音乐推荐方法及系统与流程 |
您所在的位置:网站首页 › 企鹅拍脸表情图片 › 一种基于人脸表情识别的个性化音乐推荐方法及系统与流程 |
一种基于人脸表情识别的个性化音乐推荐方法及系统与流程
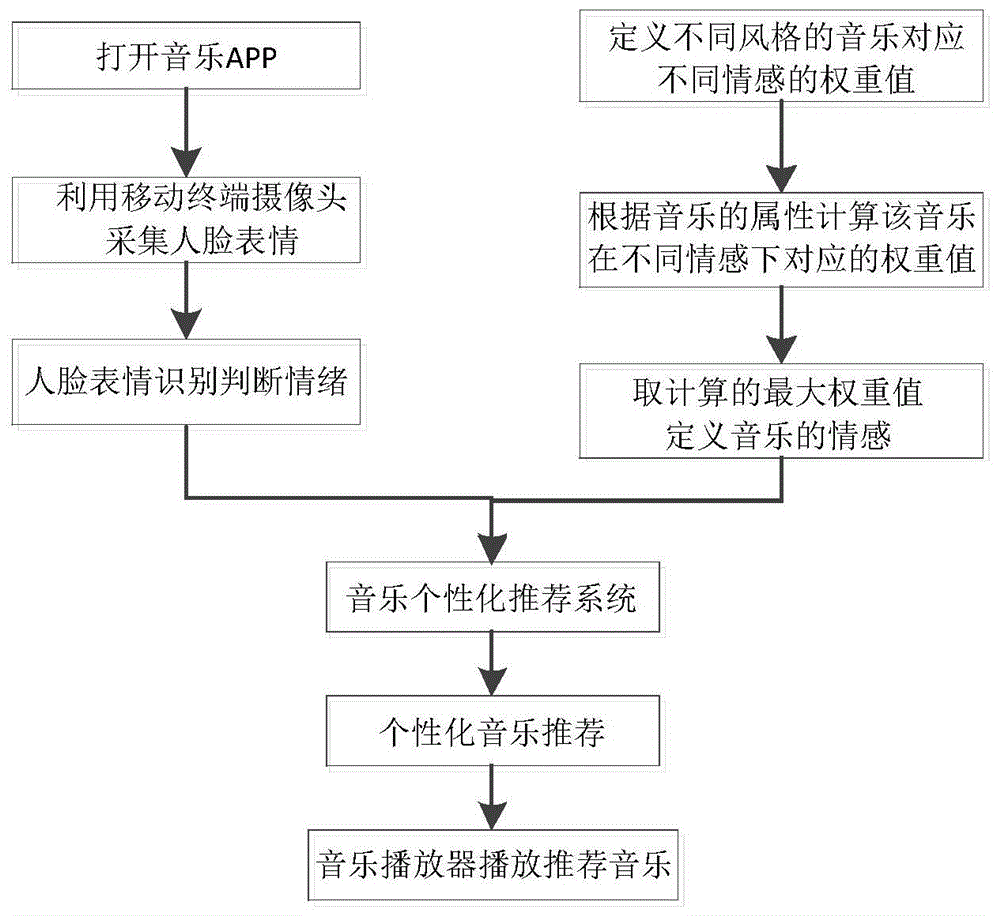 本发明实施例涉及音乐推荐技术领域,具体涉及一种基于人脸表情识别的个性化音乐推荐方法及系统。 背景技术: 音乐类app个性化推荐根据用户的兴趣和行为特点,帮助用户在海量音乐中快速发现自己喜欢或可能喜欢的音乐,提高用户黏性,促进音乐播放和付费。推荐系统是基于海量数据挖掘分析的商业智能平台,推荐主要基于用户的浏览历史和行为记录等信息,如:试听、下载、收藏、分享、关注。 现有音乐推荐方法包括:1、基于人口统计学的推荐,其根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户;2、基于内容的推荐,在推荐引擎出现之初应用最为广泛的推荐机制,其核心思想是根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品;3、基于协同过滤的推荐,基于协同过滤的推荐机制是现今应用最为广泛的推荐机制,典型的算法是基于用户的协同过滤推荐,基本原理是:根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“k-邻居”的算法;然后,基于这k个邻居的历史偏好信息,为当前用户进行推荐。但是上述音乐推荐方法均不能根据人脸表情进行音乐推荐,无法满足个性化需求。 技术实现要素: 为此,本发明实施例提供一种基于人脸表情识别的个性化音乐推荐方法及系统,以解决现有流媒体类应用不能根据人脸表情推荐音乐的问题。 为了实现上述目的,本发明实施例提供如下技术方案: 根据本发明实施例的第一方面,公开了一种基于人脸表情识别的个性化音乐推荐方法,其特征在于,所述推荐方法为: 利用移动终端的摄像头采集人脸表情,通过对人脸表情识别判断人的心情特征; 对音乐库中的音乐进行标签化分类,根据音乐的音频特征和歌词情感分析对不同风格的音乐计算其情感权重值,选择权重值占比最大的情感定义为该首音乐的情感属性; 将人脸表情识别后得出的心情特征与音乐库中符合该情感属性的音乐进行映射匹配,推荐符合当前人的心情的音乐。 进一步地,所述人脸表情识别步骤为: s1、基于pcanet-cnn的任意姿态对人脸表情进行识别,对样本图片预处理得到统一像素的灰度图像,然后将统一像素的灰度图像分为正脸图像和侧脸图像,对所得的正脸图像提取尺寸为k1xk2大小的特征块,对所得到的侧脸图像提取尺寸为k1xk2大小的特征块; s2、将步骤s1中的正脸图像作为无监督特征学习pcanet的输入进行无监督正脸特征学习,得到正脸特征; s3、将步骤s1中的侧脸图像作为有监督特征学习cnn的输入,并结合步骤s2的正脸特征,通过有监督学习cnn的处理建立侧脸特征和正脸特征之间的映射关系; s4、利用步骤s3的映射关系得到对任意姿态具有鲁棒性的统一正脸特征; s5、将步骤s4所得的对姿态具有鲁棒性的统一正脸特征送入支持向量机svm中进行识别模型的训练,得到一个针对任意姿态的统一识别模型; s6、利用步骤s3所述的映射关系以及步骤s5所述的统一识别模型识别出任意姿态人脸图像所属的人脸表情类别。 进一步地,所述音乐库中的音乐属性标签包括客观标签和主观标签,所述客观标签为音乐的音频特征,所述主观标签为音乐的歌词情感分析。 进一步地,所述客观标签包括:歌曲节拍、流派和调性,根据歌曲节拍、流派和调性分别对应开心、生气、悲伤和中立的情绪赋予不同的权重值。 进一步地,所述歌曲节拍包括:广板、慢板、柔板、行板、小行板、中板、小快板、快板、急板,所述流派包括:巴洛克、古典、浪漫、民族、印象,所述调性包括大调和小调。 进一步地,所述音乐对应情感的权重计算方法为:确定音乐的节拍、流派和调性,分别将不同情感对应的歌曲节拍、流派和调性的权重值进行求和,得到不同情感下音乐情感的权重值之和,取最大的权重值之和对应的情感定义为该音乐的情感属性。 根据本发明实施例的第二方面,公开了一种基于人脸表情识别的个性化音乐推荐系统,所述推荐系统根据人脸表情识别结果判定人的心情特征,将人的心情特征与推荐歌单中的音乐进行映射匹配,根据音乐对应的情感属性选择符合当前人的心情特征的歌曲推荐给使用者,当推荐歌单中没有符合当前人的心情特征的歌曲时,通过个性化推荐引擎从音乐库中匹配对应情感的歌曲进行推荐。 进一步地,所述推荐歌曲通过音乐播放器进行播放。 本发明实施例具有如下优点: 本发明实施例公开了一种基于人脸表情识别的个性化音乐推荐方法及系统,通过人脸表情识别技术判断当前人的心情,并将音乐库中的音乐根据其音乐属性计算对应不同情感的权重值,取最大权重值对应的情感定义为该歌曲的情感属性,将人脸表情识别判定的心情特征与音乐库中音乐的情感进行映射匹配,个性化推荐符合当前人心情特征的歌曲,帮助用户在海量音乐中快速发现自己喜欢或可能喜欢的音乐,提高用户黏性,促进音乐播放和付费。 附图说明 为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引伸获得其它的实施附图。 本说明书所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。 图1为本发明实施例提供的一种基于人脸表情识别的个性化音乐推荐方法流程图; 图2为本发明实施例提供的一种基于人脸表情识别的个性化音乐推荐系统架构图; 具体实施方式 以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。 实施例1 本实施例公开了一种基于人脸表情识别的个性化音乐推荐方法,所述推荐方法为: 根据人脸表情判断人的情绪作为现有技术进行使用,利用移动终端的人脸捕捉单元调用摄像头采集人脸表情,通过对人脸表情识别判断人的心情特征; 对音乐库中的音乐进行标签化分类,根据音乐的音频特征和歌词情感分析对不同风格的音乐计算其情感权重值,选择权重值占比最大的情感定义为该首音乐的情感属性; 将人脸表情识别后得出的心情特征与音乐库中符合该情感属性的音乐进行映射匹配,推荐符合当前人的心情的音乐。 人脸表情识别步骤为:s1、基于pcanet-cnn的任意姿态对人脸表情进行识别,对样本图片预处理得到统一像素的灰度图像,然后将统一像素的灰度图像分为正脸图像和侧脸图像,对所得的正脸图像提取尺寸为k1xk2大小的特征块,对所得到的侧脸图像提取尺寸为k1xk2大小的特征块; s2、将步骤s1中的正脸图像作为无监督特征学习pcanet的输入进行无监督正脸特征学习,得到正脸特征; s3、将步骤s1中的侧脸图像作为有监督特征学习cnn的输入,并结合步骤s2的正脸特征,通过有监督学习cnn的处理建立侧脸特征和正脸特征之间的映射关系; s4、利用步骤s3的映射关系得到对任意姿态具有鲁棒性的统一正脸特征; s5、将步骤s4所得的对姿态具有鲁棒性的统一正脸特征送入支持向量机svm中进行识别模型的训练,得到一个针对任意姿态的统一识别模型; s6、利用步骤s3所述的映射关系以及步骤s5所述的统一识别模型识别出任意姿态人脸图像所属的人脸表情类别。 步骤s1中预处理的过程包括:通过一个级联的vj框架检测样本图片中的人脸,再通过二值化对检测到的人脸图片进行灰度处理得到灰度图像,然后对所得灰度图像进行大小归一化得到统一像素的灰度图像,步骤s1中统一像素的灰度图像大小设为96*96,正脸图像和侧脸图像的特征块大小设置为5*5。 步骤s2中无监督特征学习的过程包括: 步骤s2-1,对正脸图像进行白化处理; 步骤s2-2,通过预训练得到不同尺寸的卷积核,再用所得卷积核对正验图像进行卷积,得到pcanet第一层的输出; 步骤s2-3,将pcanet第一层的输出作为pcanet第二层的输入,经过与第一层相同的卷积过程得到pcanet第二层的输出; 步骤s2-4,对pcanet第二层的输出进行二值哈希处理以及直方图分块处理,最终将所得特征堆叠串联起来形成对光照具有鲁棒性的正脸特征。 步骤s2-1中白化处理的过程:读取正脸图像的像索特征,然后以步长大小为1、特征块大小为5*5对得到的像素特征进行分块处理,然后对每一个小的特征块串联得到一个一维的特征,对此一维的特征均除以其标准差,从而得到具有相同方差的特征。 步骤s3的具体实现包括:s3-1,将步骤s1中侧脸图像输入至有监督特征学习cnn的卷积层,将步骤s2中所得正脸特征作为cnn的标签,通过反向传播算法更新卷积核;对输入的侧脸图像首先经过卷积层和池化层得到cnn第一层的输出,然后将池化后的结果作为cnn第二层的输入,经过卷积和池化得到第二层的输出,即得到侧脸特征; s3-2,计算侧脸特征和正脸特征之间的重构误差函数来计算侧脸特征和正脸特征之间的平均误差值,并以此平均误差来反向传播更新各层卷积核,当此平均误差值趋于收敛时,算法停止,得到侧脸特征和正脸特征之间的映射关系,所述映射关系由两层cnn中的权重w、w2以及偏置b1,b2构成。 所述步骤s4具体包括:s4-1,输入一张任意姿态的灰度人脸图像,通过步骤s3的侧脸特征和正脸特征之间的映射关系,得到这张任意姿态的灰度人脸图像所对应的正脸特征; s4-2,对所有的任意姿态的灰度人脸图像均按照步骤s4-1的处理,得到对姿态具有鲁棒性的统一正脸特征。 步骤s6中识别出任意姿态的人脸表情的具体过程包括:对任意一张待测人脸图片,采用步骤s1所述预处理的方法进行预处理得到统一像素的的灰度图像,然后按照步骤s4处理得到此未知姿态的人脸表情图片所对应的统一正脸特征,将此统一正脸特征送入步骤s5中训练好的统一识别模型中得到此待测人脸图片所属的表情类别。 所述音乐库中的音乐属性标签包括客观标签和主观标签,所述客观标签为音乐的音频特征,所述主观标签为音乐的歌词情感分析,客观标签包括:歌曲节拍、流派和调性,所述歌曲节拍包括:广板、慢板、柔板、行板、小行板、中板、小快板、快板、急板,所述流派包括:巴洛克、古典、浪漫、民族、印象,所述调性包括大调和小调,根据歌曲节拍、流派和调性分别对应开心、生气、悲伤和中立的情绪赋予不同的权重值。 以古典音乐为例,参考表一,古典音乐不同节拍、流派和调性对应不同情绪的权重值。 表一古典音乐对应不同情绪权重值 歌曲《小夜曲》的音乐属性为柔板、浪漫、小调,则开心对应的权重值之和为14,生气对应的权重值之和为6,悲伤对应的权重值之和为22,中立对应的权重值之和为7,取权重值之和的最大值对应的情绪定义该音乐的情感,则歌曲《小夜曲》对应的情感为悲伤; 歌曲《土耳其进行曲》的音乐属性为小行板、古典、大调,则开心对应的权重值之和为20,生气对应的权重值之和为17,悲伤对应的权重值之和为14,中立对应的权重值之和为9,取权重值之和的最大值对应的情绪定义该音乐的情感,则歌曲《土耳其进行曲》对应的情感为开心。 实施例2 本实施例公开了一种基于人脸表情识别的个性化音乐推荐系统,推荐系统包括终端装置和云端系统,终端装置包括:摄像头、人脸捕捉单元和音乐播放器,云端系统包括:人脸表情识别系统、音乐情感权重值表、个性化推荐引擎和音乐库,所述推荐系统根据人脸表情识别结果判定人的情绪,将人的心情特征与推荐歌单中的音乐进行映射匹配,根据音乐对应的情感属性选择符合当前人的情绪的歌曲推荐给使用者,当推荐歌单中没有符合当前人的心情特征的歌曲时,通过个性化推荐引擎从音乐库中匹配对应心情特征的歌曲进行推荐,推荐歌曲通过音乐播放器进行播放。 虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。 |
【本文地址】
今日新闻 |
推荐新闻 |