热图绘制的小技巧 |
您所在的位置:网站首页 › 代谢物热图怎么做 › 热图绘制的小技巧 |
热图绘制的小技巧
|
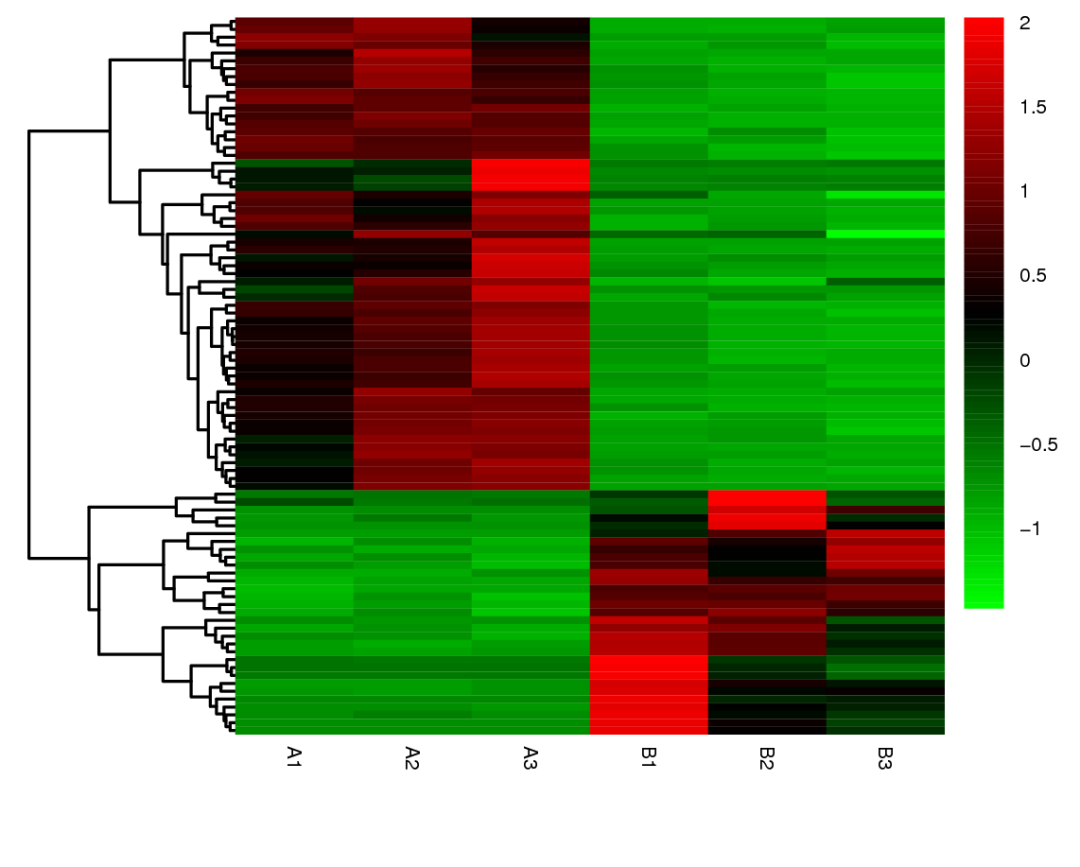
图 2 原来,图1中是直接使用表达量绘制而成,图例颜色的变化范围和表达量的变化范围一样大,稍小些的波动,将在很难颜色上直观看出,这不,除了图中零星的红色区域之外,整个图片都是绿色的,完全看不出同一个基因在不同样本的表达丰度差别。 其实很多情况下,我们是希望通过比较基因的变化情况,找到样本中的关键基因,而不是表达量的绝对值,而图2正是先对数据进行了归一化处理,处理后可以将数值范围锁定在一个较小的范围内,可以更加直观的比较同一基因在不同样本的差异情况,秒杀了图1这种无效的展示结果。数据处理的标准化 / 归一化,形式上是变化表达,本质上是为了比较认识。数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。为了能够将不同样本 / 分组的表达量进行比较,需要对指标进行规范化处理,通过函数变换将其数值映射到某个数值区间。 通过上面的例子来看,对数据进行归一化处理很有必要。标准化能避免由于单个数据过大(过小),导致冷热色分布不明显的现象。那么如何进行归一化呢?其实方法也有很多,下面给大家介绍两种常用的数据归一化方法,即图3和图4所使用的方法。 min-max标准化 1 min-max标准化(Min-max normalization)/ 0-1标准化(0-1 normalization)/ 线性函数归一化 / 离差标准化是对原始数据的线性变换,使结果落到 [0 , 1] 区间,转换函数如下: 其中max为同一个基因在不同样本中的最大值,min为同一个基因在不同样本中的最小值。
图3 Z-score归一法 2 在总体均值和总体标准差是已知的情况下,z-score标准分数被计算为: Z 值 = (X - µ) / σ 其中,X = 标准化的随机变量, µ = 样本均值, σ = 样本标准差。 Z值也叫标准分数(standard score),在统计学中,标准分数是一个观测或数据点的值高于被观测值或测量值的平均值的标准偏差的符号数,通过标准分数可以看出某分数在分布中相对位置,是常用的统计量之一。简单来说,它代表着原始数值和总体均值之间的距离,并以标准差为单位计算。在原始数值低于平均值时Z则为负数,反之则为正数,是一个不受原始测量单位影响的数值。经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数、正切等。当变量是正偏态分布的时候,选用log对数。
图4 由于归一化后,同一基因在不同的样本中的差异结果显而易见。虽然两种归一化方法均能有效改变图片的可读性,但联川选用的方法是基因丰度Z值转化后取对数的计算方法更能有效地展示对称的结果。具体换算公式如下:
其中将随机变量、样本均值以及样本标准差均取对数,以减少表达量之间的数值的差异,增加热图绘制软件对数字变化范围较小的数据的敏感性,增加图片的可读性。图2的结果说明颜色越红,表达量越大,反之,颜色越绿,表达量越小。 大家以后如果要绘制热图的话,切记一定要进行归一化处理哟。 参考网址 min-max归一化方法网址:https://en.wikipedia.org/wiki/Feature_scaling z-score方法:https://en.wikipedia.org/wiki/Standard_score返回搜狐,查看更多 |

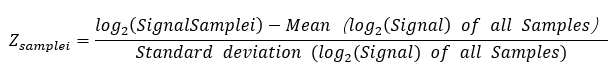
【本文地址】