关于R实现缺失值的可视化 |
您所在的位置:网站首页 › 代码缺失 › 关于R实现缺失值的可视化 |
关于R实现缺失值的可视化
|
R实现缺失值的可视化
缺失值的可视化识别缺失值缺失值的类别1.Missing Completely at Random(MCAR)2.Missing at Random(MAR)3.Missing Not at Random(MNAR)
缺失值的识别
缺失值的可视化创建缺失表缺失图的绘制
利用相关性,判断缺失值类型
因为准备考研,所以把R语言的学习耽误了许久。现在准备一边等考研成绩,一边再把R重新学过。 缺失值的可视化缺失值大体上可以分为两类,一类是NA,即NULL;还有一种是异常点,比如在记录患者胰岛素含量的变量下出现数字0等明显异常的数值。 识别缺失值 缺失值的类别 1.Missing Completely at Random(MCAR)指的是数据的缺失是完全随机的,并不依赖于任何不完全变量或完全变量,不影响样本的无偏性。就像是抛硬币一样,在理想情况下结果是完全随机的,所以在数据量足够的情况下,对于此类含缺失值的数据可以直接删除。 2.Missing at Random(MAR)可以理解为某一类的人员会出现缺失值,比如在体测中血压值高于某个阈值的学生将不记录长跑成绩,这也便导致了缺失值的概率并不为恒值,即缺失值的出现并非随机,而是和某个变量值相关。 3.Missing Not at Random(MNAR)指的是数据的缺失与不完全变量自身的取值有关,比如在人口普查时人们不愿意提供真实的工资收入数据,从而导致的偏差值,缺失值。 缺失值的识别在R中,可以利用is.na()进行缺失值的逻辑值判断,R将会针对每一个变量值给出TRUE和FALSE的回答。如果只需要简单了解总的缺失值个数,也可以用sum(is.na(data))来做到。当然后面会使用其他函数来制作缺失表。 缺失值的可视化下面的例子将会使用到VIM包和mice包,与其含有的airquality数据集 > #清空数据 > rm(list = ls()) > #运行对应的R包 > library(VIM) > library(mice) > #导入数据 > data("airquality") > #对数据进行简答查看 > summary(airquality) Ozone Solar.R Wind Temp Min. : 1.00 Min. : 7.0 Min. : 1.700 Min. :56.00 1st Qu.: 18.00 1st Qu.:115.8 1st Qu.: 7.400 1st Qu.:72.00 Median : 31.50 Median :205.0 Median : 9.700 Median :79.00 Mean : 42.13 Mean :185.9 Mean : 9.958 Mean :77.88 3rd Qu.: 63.25 3rd Qu.:258.8 3rd Qu.:11.500 3rd Qu.:85.00 Max. :168.00 Max. :334.0 Max. :20.700 Max. :97.00 NA's :37 NA's :7 Month Day Min. :5.000 Min. : 1.0 1st Qu.:6.000 1st Qu.: 8.0 Median :7.000 Median :16.0 Mean :6.993 Mean :15.8 3rd Qu.:8.000 3rd Qu.:23.0 Max. :9.000 Max. :31.0 > head(airquality,6) Ozone Solar.R Wind Temp Month Day 1 41 190 7.4 67 5 1 2 36 118 8.0 72 5 2 3 12 149 12.6 74 5 3 4 18 313 11.5 62 5 4 5 NA NA 14.3 56 5 5 6 28 NA 14.9 66 5 6 > sum(is.na(airquality)) [1] 44可以看出数据集内部含有44个缺失值 创建缺失表 > md.pattern(airquality) Wind Temp Month Day Solar.R Ozone 111 1 1 1 1 1 1 0 35 1 1 1 1 1 0 1 5 1 1 1 1 0 1 1 2 1 1 1 1 0 0 2 0 0 0 0 7 37 44表内第一列代表完整数据的个数,即有111个完整数据,44个缺失值。 其中1表示无缺失,0代表有缺失值。 看第二行表示仅缺失Ozone的数据有35个,同样地,仅缺失Solar.R的数据有5个,同时缺失Ozone和Solar.R的数据有两个。同时该代码能展现出缺失图。 纵看则表示,缺失Solar.R的有7个数据,缺失Ozone的则有37个数据。
最后可以将指示变量设置为0-1变量替代数据集的变量值,以得到影子矩阵,再通过影子矩阵求得指示变量和初始变量之间的相关性,有利于我们分析判断变量的缺失与其他变量之间的关系。 > #利用相关性探索缺失值 > #构建影子矩阵 > #将指示变量设置为0-1变量替代数据集的变量值 > #1表示缺失,0表示不缺失 > x y 0)] > cor(y) Ozone Solar.R Ozone 1.00000000 0.02244102 Solar.R 0.02244102 1.00000000通过矩阵可以看出二者缺失的情况相关性很弱,只有0.022,即二者缺失的相关关系很弱,可以认为二者的数据缺失之间没有关系。 接着进行缺失值与其他变量之间的相关关系分析。 > cor(airquality,y,use = 'pairwise.complete.obs') Ozone Solar.R Ozone NA 0.004333819 Solar.R 0.022416130 NA Wind 0.048128600 -0.059707639 Temp 0.002188971 -0.113316379 Month -0.256852370 -0.109762193 Day 0.053995425 -0.165076368可以看出除了Month以外的变量都与Ozone的缺失关系很小,而鉴于Month与其数据缺失的相关度也只有0.26左右,可以认为其为MAR或是MCAR。 而和Solar.R缺失相关度最高的是Day变量,但其也只有0.17左右,则可以认为其是MCAR。 |

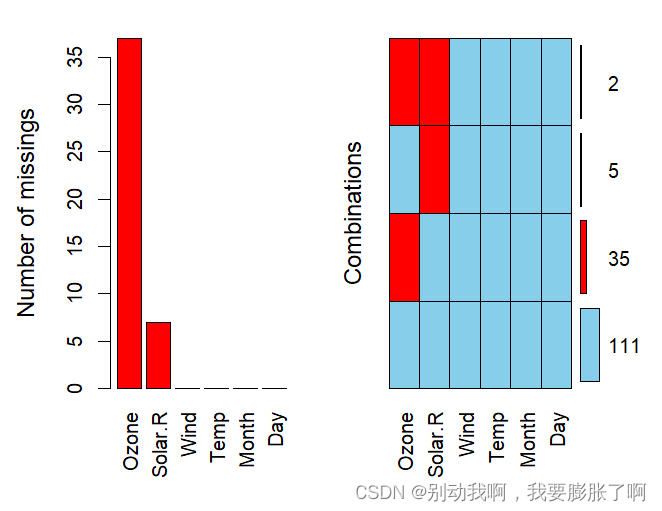
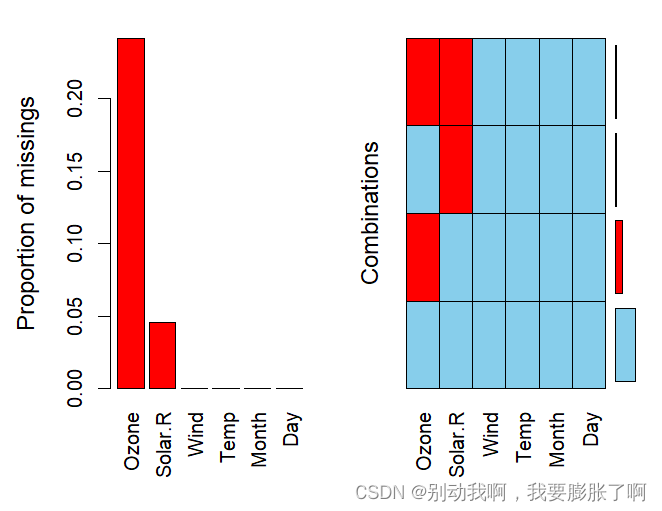 其中,matrixplot()函数可以针对每一个数据进行缺失值的可视化。 颜色表达了变量值的大小,浅色值小,深色值大,而红色代表着缺失值。
其中,matrixplot()函数可以针对每一个数据进行缺失值的可视化。 颜色表达了变量值的大小,浅色值小,深色值大,而红色代表着缺失值。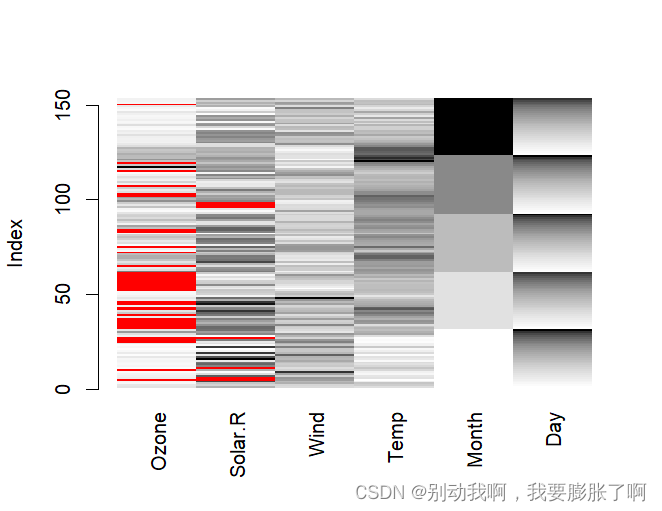 同时,利用marginplot()也可以创建带有箱线图的缺失图
同时,利用marginplot()也可以创建带有箱线图的缺失图 左侧的37个红点代表缺失Ozone的数据,下方的五个红点代表缺失Solar.R的数据,左下的蓝点则表示同时缺失二者的数据。从散点图也可以看出二者的关系,属于非线性关系。而绿色和红色分别表示了无缺失值和有缺失值的Solar,R和Ozone箱线图。
左侧的37个红点代表缺失Ozone的数据,下方的五个红点代表缺失Solar.R的数据,左下的蓝点则表示同时缺失二者的数据。从散点图也可以看出二者的关系,属于非线性关系。而绿色和红色分别表示了无缺失值和有缺失值的Solar,R和Ozone箱线图。【本文地址】