一文搞懂正则表达式 |
您所在的位置:网站首页 › 什么叫正则性问题 › 一文搞懂正则表达式 |
一文搞懂正则表达式
|
前言 在日常的开发工作中,正则表达式犹如空气般无所不在,扮演着不可或缺的角色。我们时常依赖正则来解决各类问题,例如精准定位符合特定规则的文本。然而,我注意到许多开发者对正则持有“复杂难记”的观念,难以全面掌握这一强大的工具,以至于每当在实际工作中遇到需要运用正则表达式的情况时,往往不得不翻阅资料才能编写出合适的正则。 正则表达式作为一种无比强大的工具,无疑值得我们在开发过程中深入学习并熟练运用。它能帮助我们高效解决各类复杂问题,显著提升工作效率,从而让我们的编程之旅更加得心应手,游刃有余。 什么是正则表达式你可以这样来理解正则是一个非常强大的文本处理工具,我们可以利用它来教验数据的有效性,比如用户输入的手机号是不是符合规则;另外,也可以用正则从文本中提取需要的内容,比如从网页中抽取我们需要的数据;此外,正则还可以用来做文本内容的替换从而得到我们想要的内容,可以说正则已经渗透到了我们日常工作的方方面面,不难发现学习并利用好正则至关重要。 怎么理解正则表达式呢?简单来说它就是描述字符串的规则,最简单的正则就是单个的普通字符,比如字 a 它可以匹配 Hanmeimei is a girl 中的 H 之后的 a 也可以匹配 is 之后的 a,这个和我们日常见到的普通的字符串查找其实是一样的。 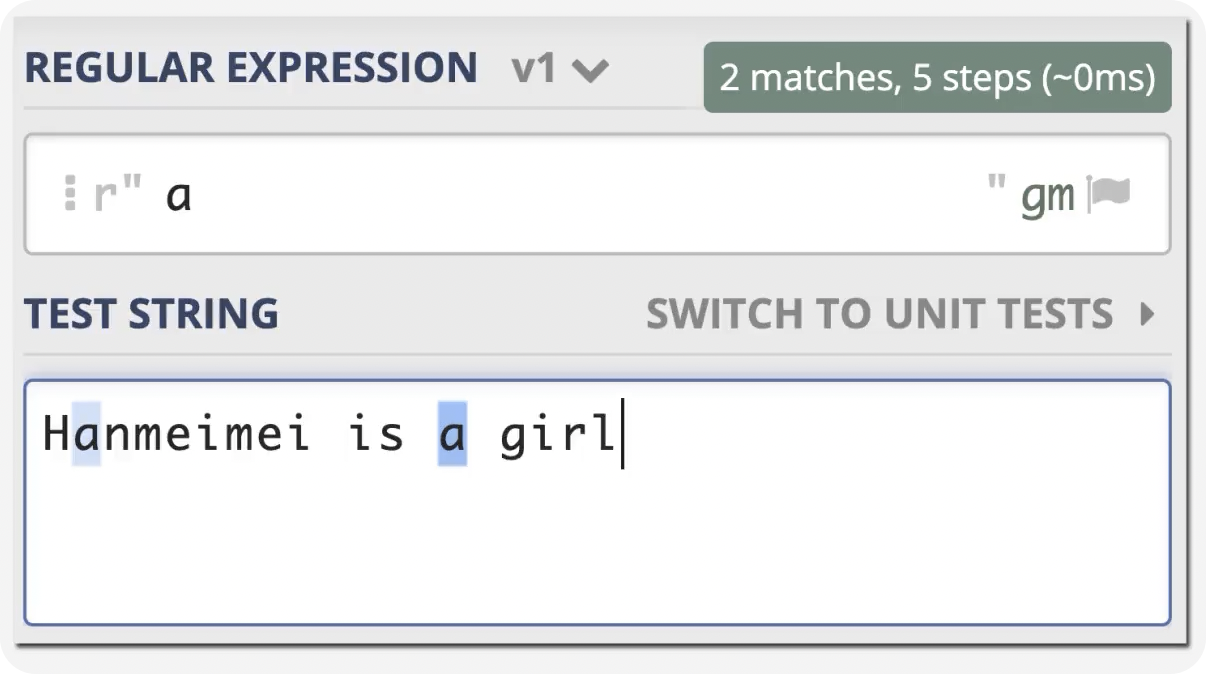 除了刚刚说的普通的字符串的查找之外,有时候我们还需要查找符合某个规则的文本;比如我们想找出字符串中所有的数字,而任意数字在正则中可以用 \d 来表示,它表示 0~9 这十个数字。 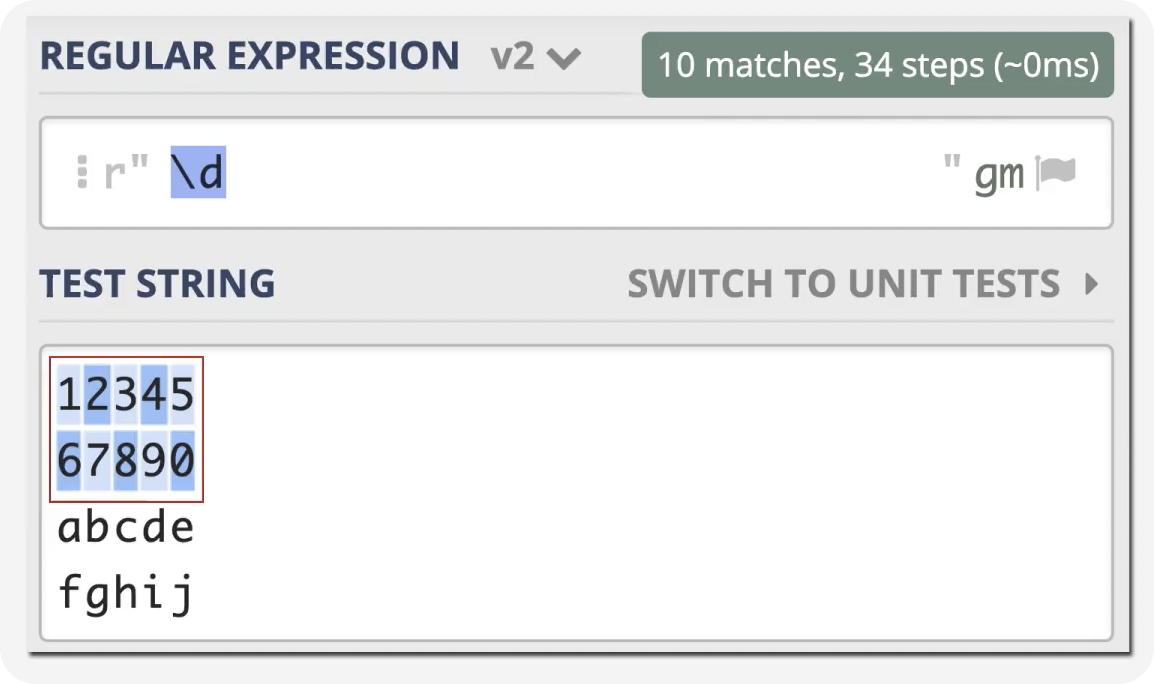 单个的 \d 只能表示一个数字我们如果在后面加上量词,比如 \d{11} 这样的话就表示 11 位数字。我们的手机号就是 11 位的,如果文本中只有姓名和手机号,我们就可以用这个提取出里面的手机号。 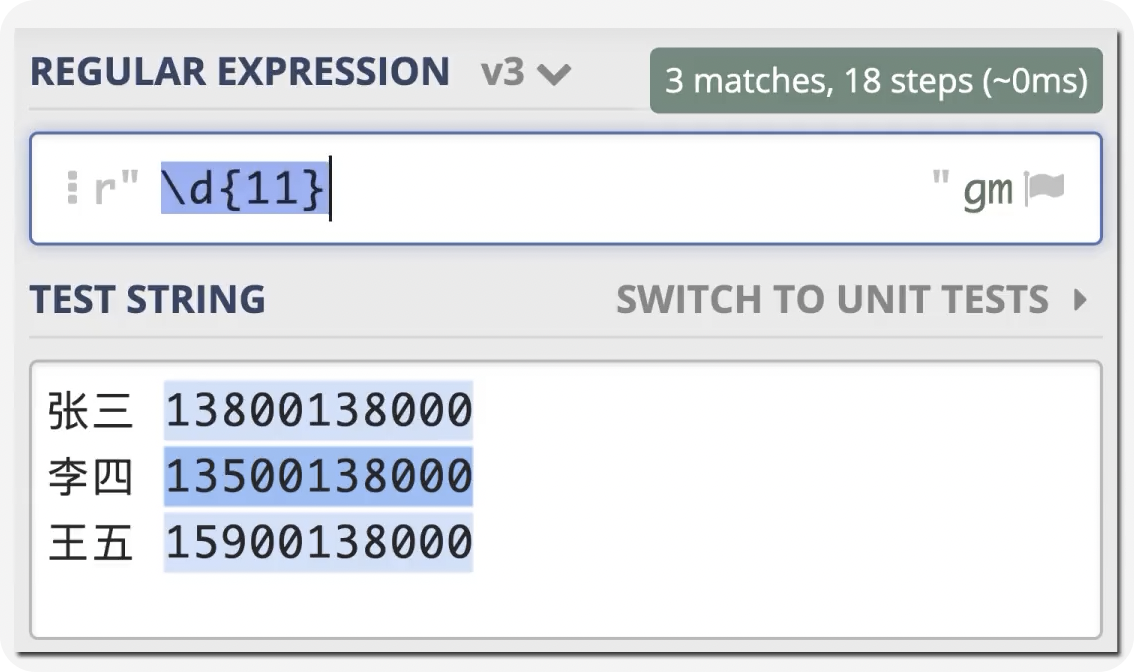 正则不仅仅能找出符合要求的文本,还可以对文本进行替换。比如说我们有这样一段文本 the cat cat is in the the hat.,我们想要从文本中找出重复的单词把它统一替换成一个单词,最终的结果就是 the cat is in the hat.,可以发现正则在日常工作中使用非常广泛也非常重要。 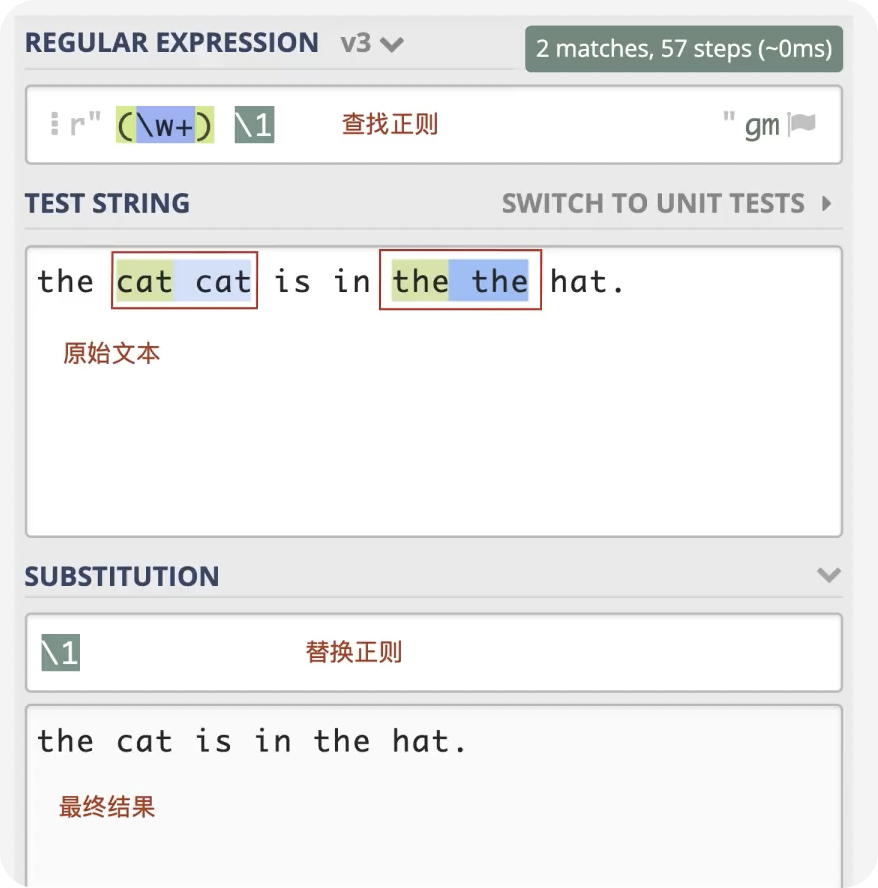 原字符 原字符正则表达式中其实有很多的原字符,比如 \d,它在正则中不代表反斜杠和字母 d 而是代表任意的数字,所谓的原字符就是指正则表达式中具有特殊含义的那些专用的字符,正则表达式中原字符非常多那么我们如何才能记住它们呢?在这里给我给大家介绍一个方法就是分类记忆。 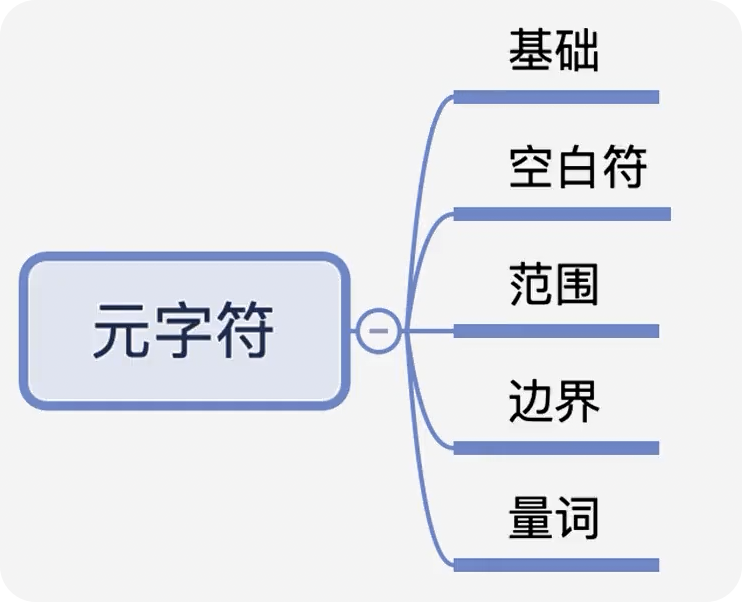 我们可以把原字符大概的分成这么几类,有基础常用的、特殊的空白符、表示某个范围的、表示边界的、表示次数的量词;原字符虽然非常的多但如果我们按照分类去理解记忆,效果就会好很多。接下来我们就按照前面说的原字符的分类来逐一的进行讲解。 基础的原字符 首先非常常用的基础的原字符,比如英文的点它表示换行以外的任意字符,\d 表示任意的数字,\w 表示任意的数字字母或者下滑线,而 \s 表示任意的空白符,另外还有与之对应的 \D、\W 和 \S 分别表示着和原来相反的意思。 特殊的空白符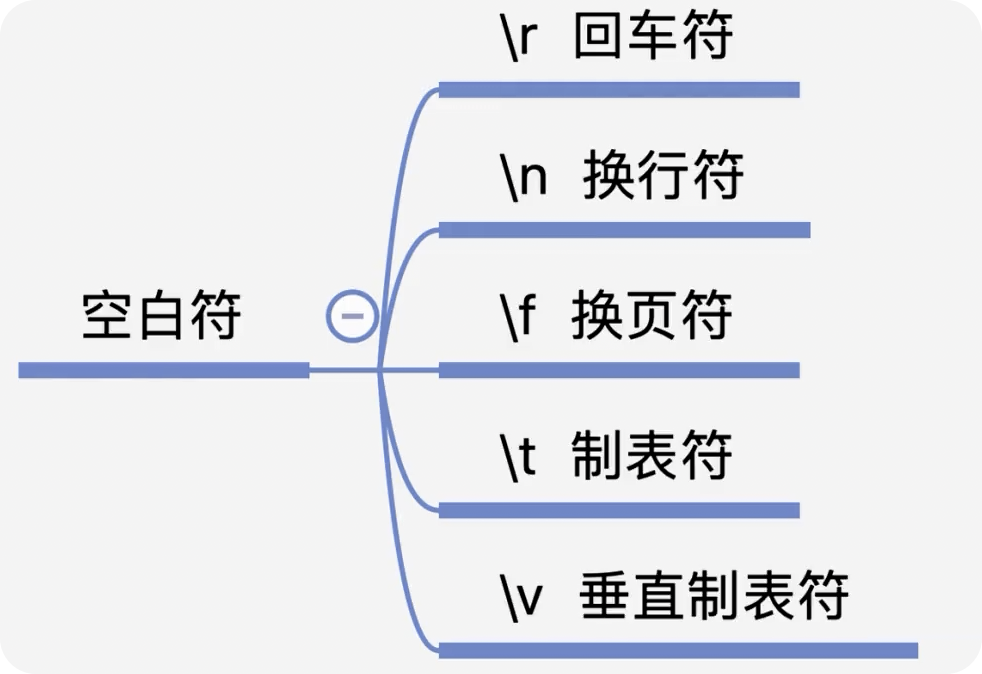 接着我们来看一下空白符有哪些,其实我们在编程中经常会遇到比如说换行符 \n TAB 制表符 \t 等,有编程经验的同学应该知道在每行文本的结束的位置都有换行,那么不同的系统会稍有区别比如说像 Windows 系统是 \r\n,Linux 和 MacOS 是 是\n,那么在正则中这些空白符也是类似的只要记住它们就行,平时使用正则大部分场景我们使用\s 就可以满足需求。 表示数量的原字符刚刚我们说到的基础的原字符也好,空白符也好,它们都只能匹配单个字符比如说 \d 只能匹配一个数字,有时候我们需要匹配单个字符或某个部分来重复 N 次或者至少出现一次或者最多出现三次这样,这就需要我们来用到表示量次的原字符。  在正则中英文的 * 它代表出现 0 到多次 + 表示出现 1 到多次 ? 表示 0 到 1 次,而 {m,n} 可以表示 m 到 n 次。 就比如说由于业务需要我们在日制中添加了 user 这样一个字段,但旧日志可能是没有这个字段的;这个时候我们可以使用 ? 来表示它出现 0 次或 1 次,在这里就可以表示 User 这个字段存在和不存在两种情况。 范围原字符学习到了量词我们就可以使用 /d{11} 来匹配所有的手机号,但是我们要明白这个范围比较大有一些不是手机号的也能匹配上,比如说 11 个 0 这个时候我们就需要在这一个特殊的范围内进行查找我们符合我们要求的数字。  管道符号它是隔开多个正则来表示满足其中任意一个就行,比如 ab|bc 它能匹配上 ab 也能匹配上 bc;中括号它可以代表多选一可以表示中括号里面任意单个字符,所以任意的元音字母我们就可以用 [aeiou] 来表示;另外中括号中我们可以用 - 来表示范围比如说 [a-z] 可以表示所有的小写字母;如果中括号中的第一个是脱字符(^)它可以表示非,那么就表示不能出现里面的任何一个单个元素。 知道了这些我们就可以轻松搞定前面的问题,手机号的匹配可以这样优化第二位可能 是3~9 那么我们可以写成 [3456789] 或者写成中 [3-9 或者是我们用 [^012] 也就是说把 012 排除掉。  边界原字符 边界原字符前面我们学习了如何匹配文本中包含的内容,但是有时候我们除了要找出符合某种组成规则的字符外还对匹配到的文本的位置有要求,比如说某个日志文件我们需要找出每行以时间开头的日志。这里要使用的正则不仅要满足时间的格式要求,它还要满足匹配道美行的开头才行,这时我们就需要用到边界相关的原字符了。 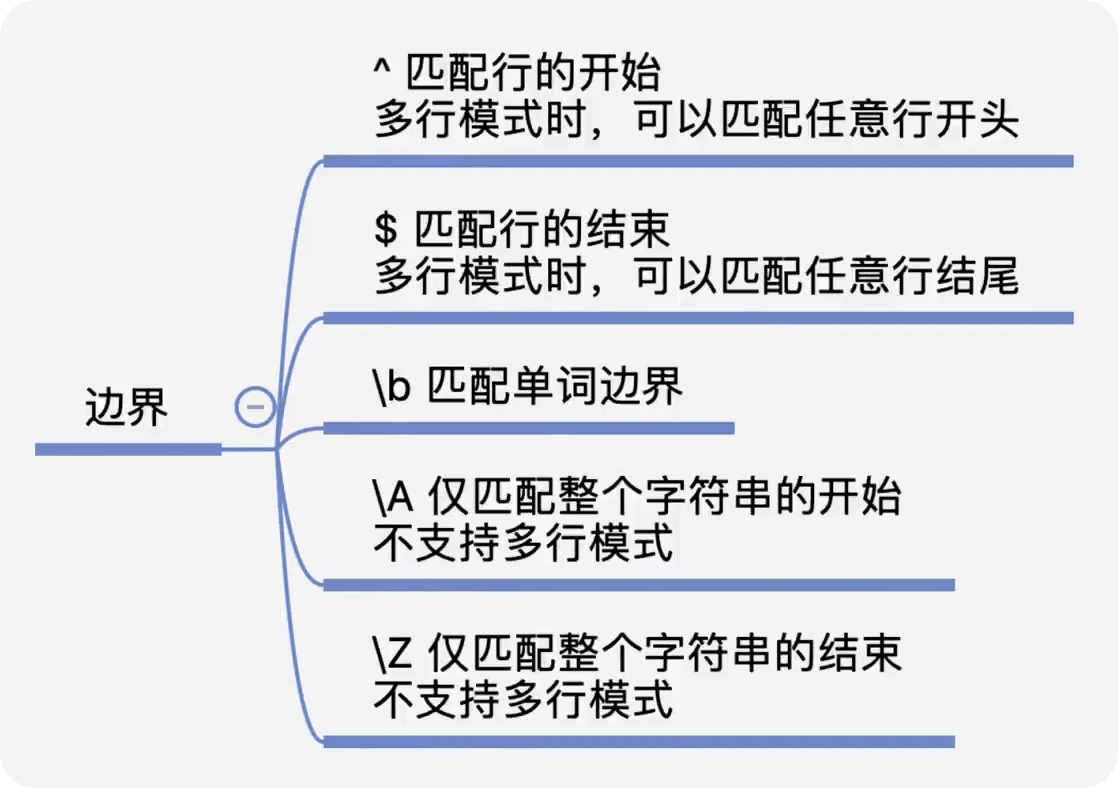 和刚才说到的中括号中的脱字符不同,如果正则中开始是脱字符,它表示每行开头的部分只有满足正则的规则的前提下才能够匹配上; 类似的正则中有美元的符号 $ 表示匹配行的结束;而 \b 来表示匹配的单词的边界;\A 和 \Z 它匹配整个字符串的开始和结束而不是每行的首尾;与 \A 不同的是脱字符可以匹配任意行的开头而不是整个文本的开头。 贪婪和非贪婪 接着我们来看一下正则中的贪婪与非贪婪,正则表达式中表示次数的量词默认是贪心的;也就是说它尽可能的多的去匹配符合要求的内容 ,举个例子来说我们要找出引号里面的单词;可能很多同学很容易写出 .+ 这样的正则。 但这样对吗?如果有多个双引号的时候是不会正常工作的,因为表示次数的量词默认是贪心的,它要尽可能多的去匹配符合要求的内容 ,不过想要让它变成非贪婪也很容易我们只需要在量词后面加上问号就可以了。 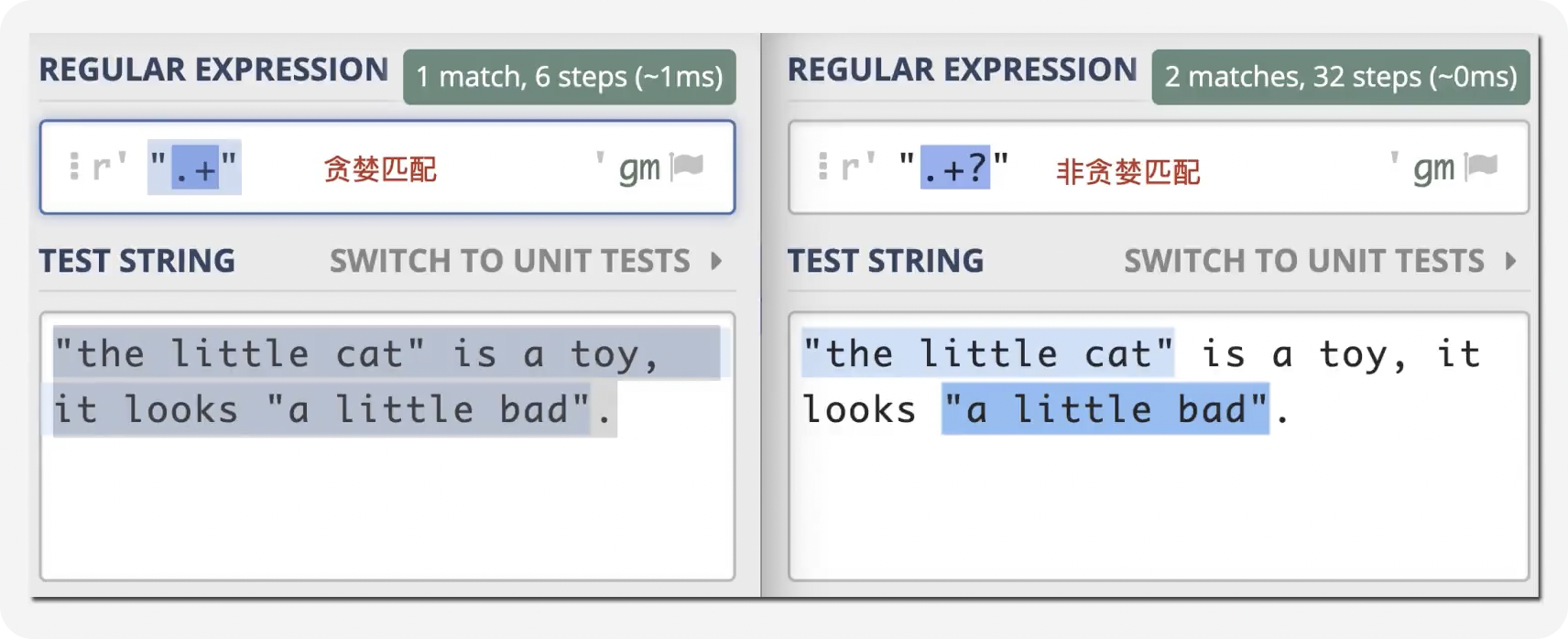 从示例中可以看出对比上的差异左右的文本是一样的,其中有两对双引号不同之处在于,图的左边不加问号时是贪婪匹配,可以看到匹配上了第一个引号到最后一个引号之间的所有的内容;而右边这个图它表示 1 到多次,加号后面有一个问号,结果就找到了符合要求的并且长度是最短的,这就是进行了非贪婪的匹配。 环视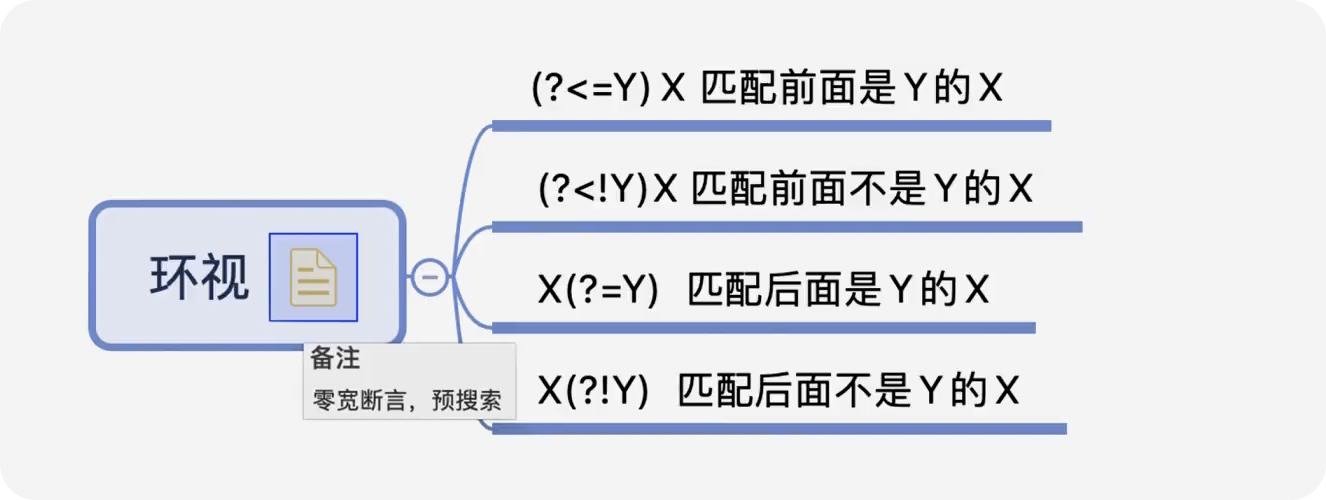 当我们对想要的提取的字符串的左边或者是右边的环境有要求的时候,比如说我们要查找左边是数字的字母,这个时候我们需要用到正则的环视,简单的说环视就是在我们给定的规则前或者是规则后来加一些限制。 下图就是利用环视来提取出左边是标签右边是标签的字符。 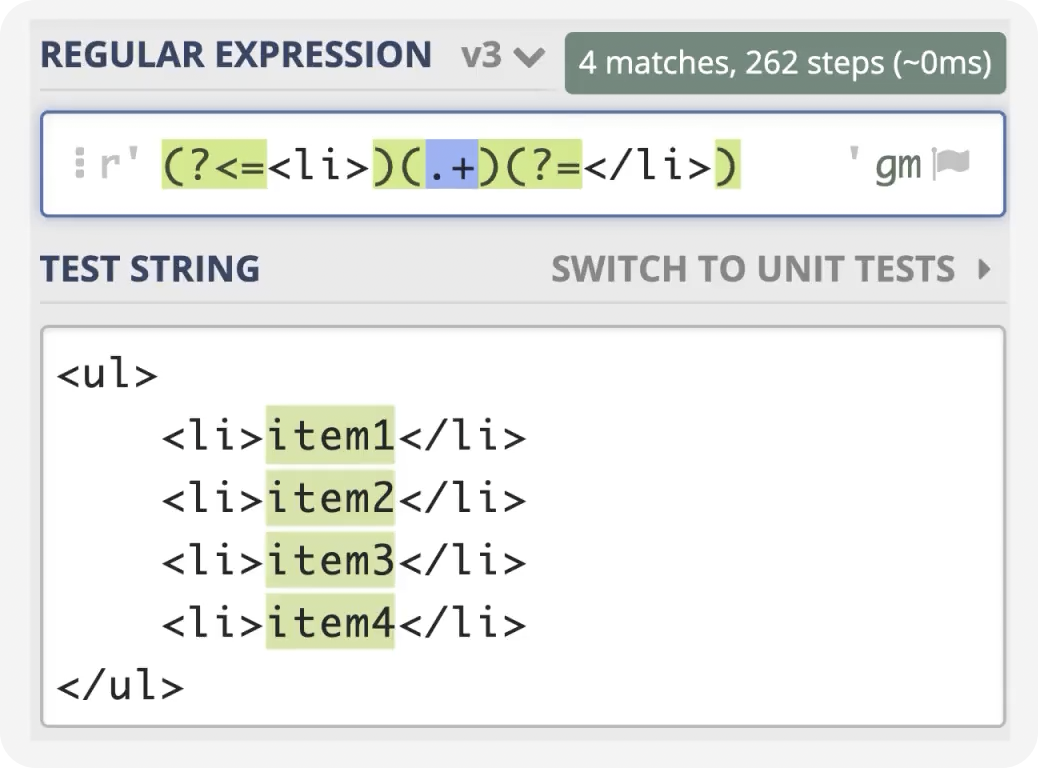 子组 子组 们再来了解一下正则中的子组,它的功能是将正则分成若干个小组用扩号来扩起来,那么将正则保存成一个子组。子组可以用来表示某个部分的内容在后面重复出现或者是对某个部分的内容进行替换。另外,正则匹配的时候我们还可以指定 flag,比如用点可以匹配所有字符,包括换行多行的匹配模式或者是大小写不敏感的匹配模式。 案例实践我们回到今天开头提出的问题也就是如何将文本中重复出现的单词替换成单个单词。在这里我们可以分成两步来操作,首先我们需要查找出相关的内容然后再对其进行替换。 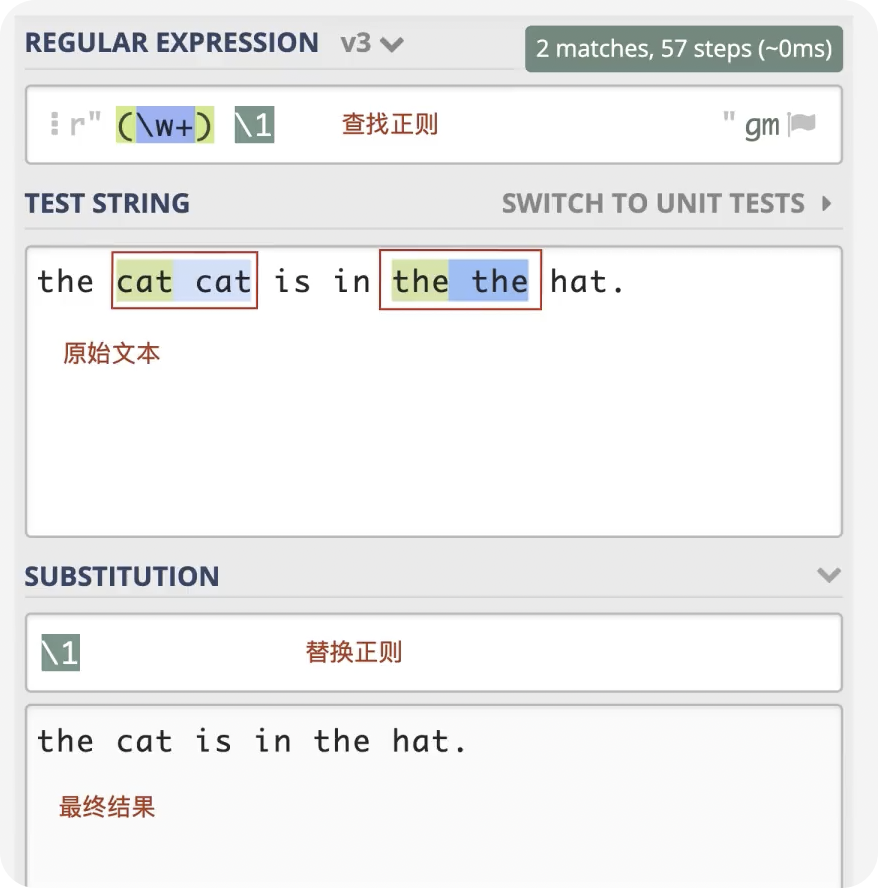 我们来先看一下查找部分,我们可以简单的用 w+ 来表示一个单词,把它用扩号扩起来意思就是保存成了一个子组;这是我们写正则中的第一个子组。然后我们在空格之后用 \1,它的意思就是前面的子组再重复出现一次,这样的话我们就找到了前面出现的单词后面又再重复出现一次相邻的两个单词。 在替换部分我们使用 \1 来表示正则中第一个子组,也就是说找到的是什么单词我们这里就把它替换成什么单词;然后可以看到最终的结果那里 cat 和 the 重复的已经移除。这样的话我们就完成了移除重复单词的工作,到这里我们就解决了开头我们提出的问题。 那么除了工作中我们能使用到正则在生活中其实我们也可以用正则来做一些非常有趣的事情,这里我引入一个案例比如说我们来用正则来帮助我们下载电视剧。用正则来提取出电视剧对应的网址,首先我们可以使用 chrome 或者 firefox 等浏览器在百度中搜索相应的电视剧的名字。 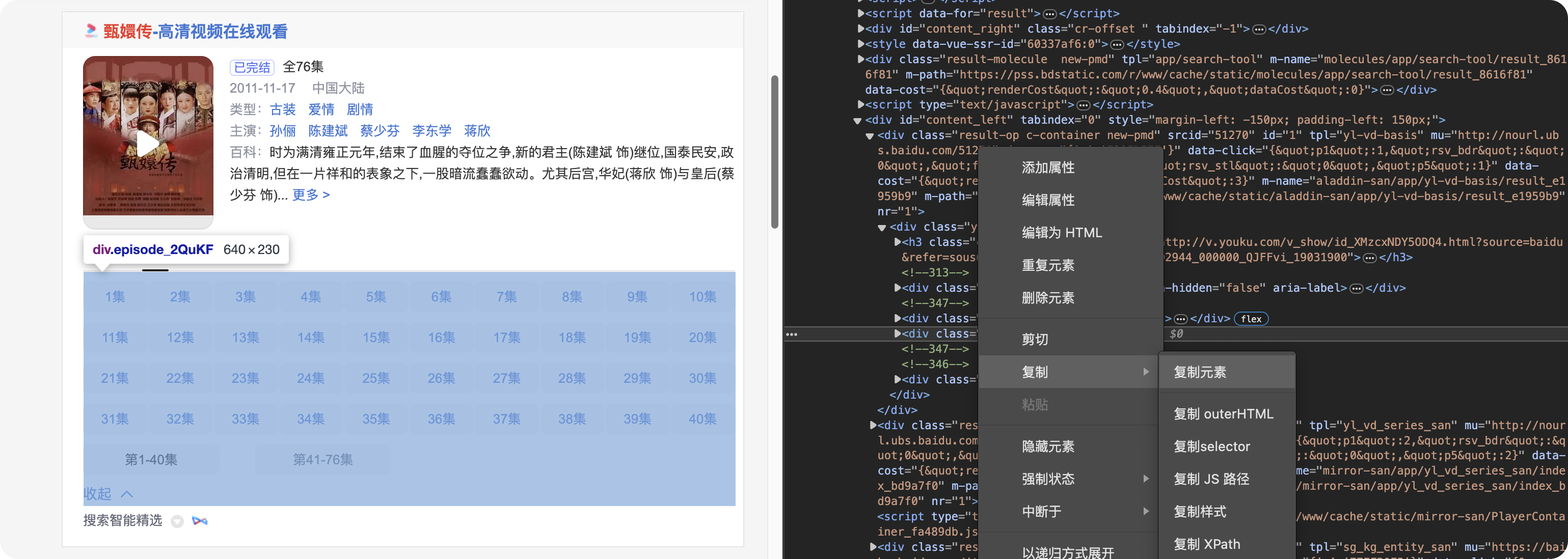 然后我们单击右键审核元素或者检查,然后获取到每一集电视剧的链接的 html 代码,接下来通过找出规律我们就可以写出一个能匹配上所有电视剧网址的这样的正则,然后可以点击查找所有。 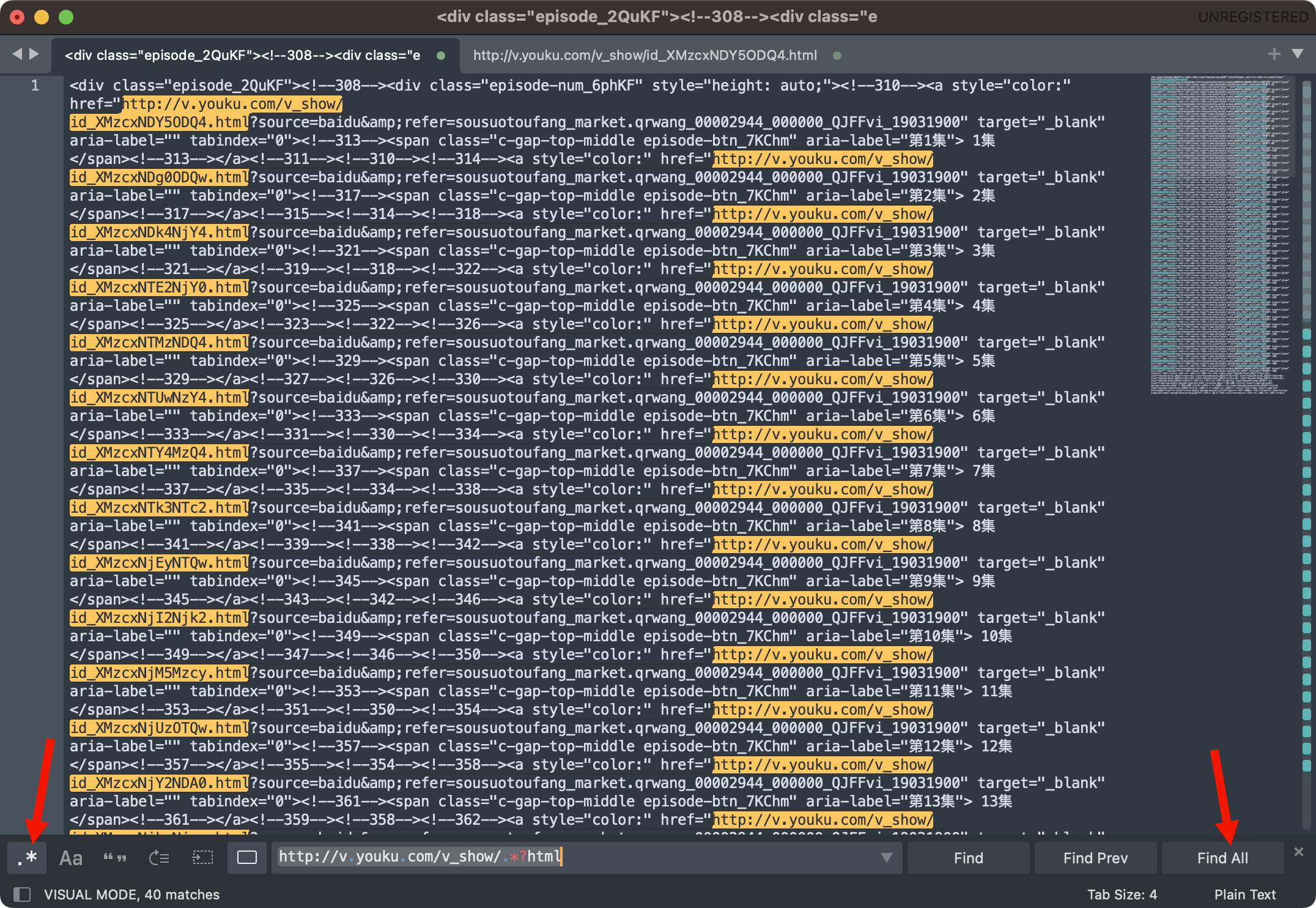 最后把查找的内容剪切出来,把剪切出来的内容粘贴到一个新的地方,通过替换等方式我们可以在这些网址的开头都加上 you-get 命令 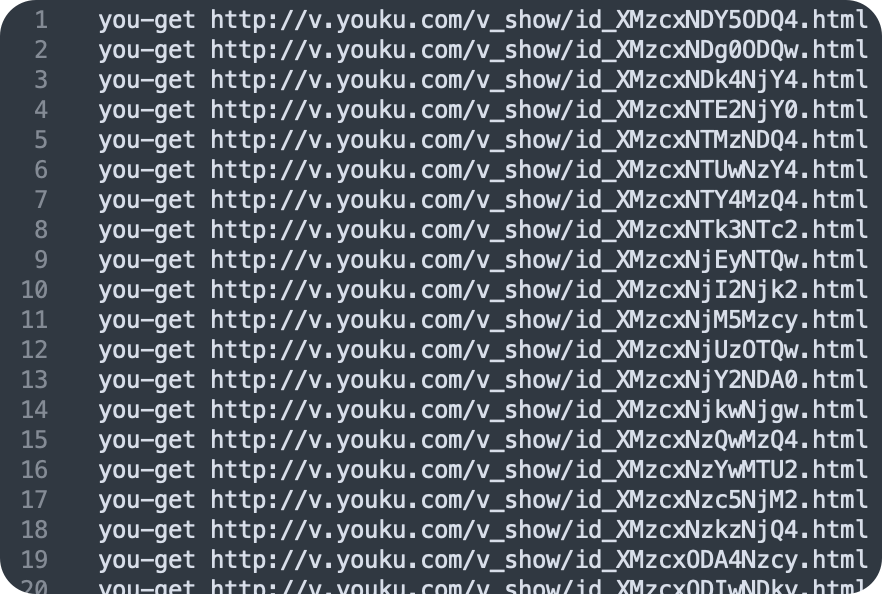 u-get 命令它是一个资源下载的工具,这个工具需要自己去安装才可以使用,最后我们在 sell 上执行这些命令就可以下载这部电视剧了。 总结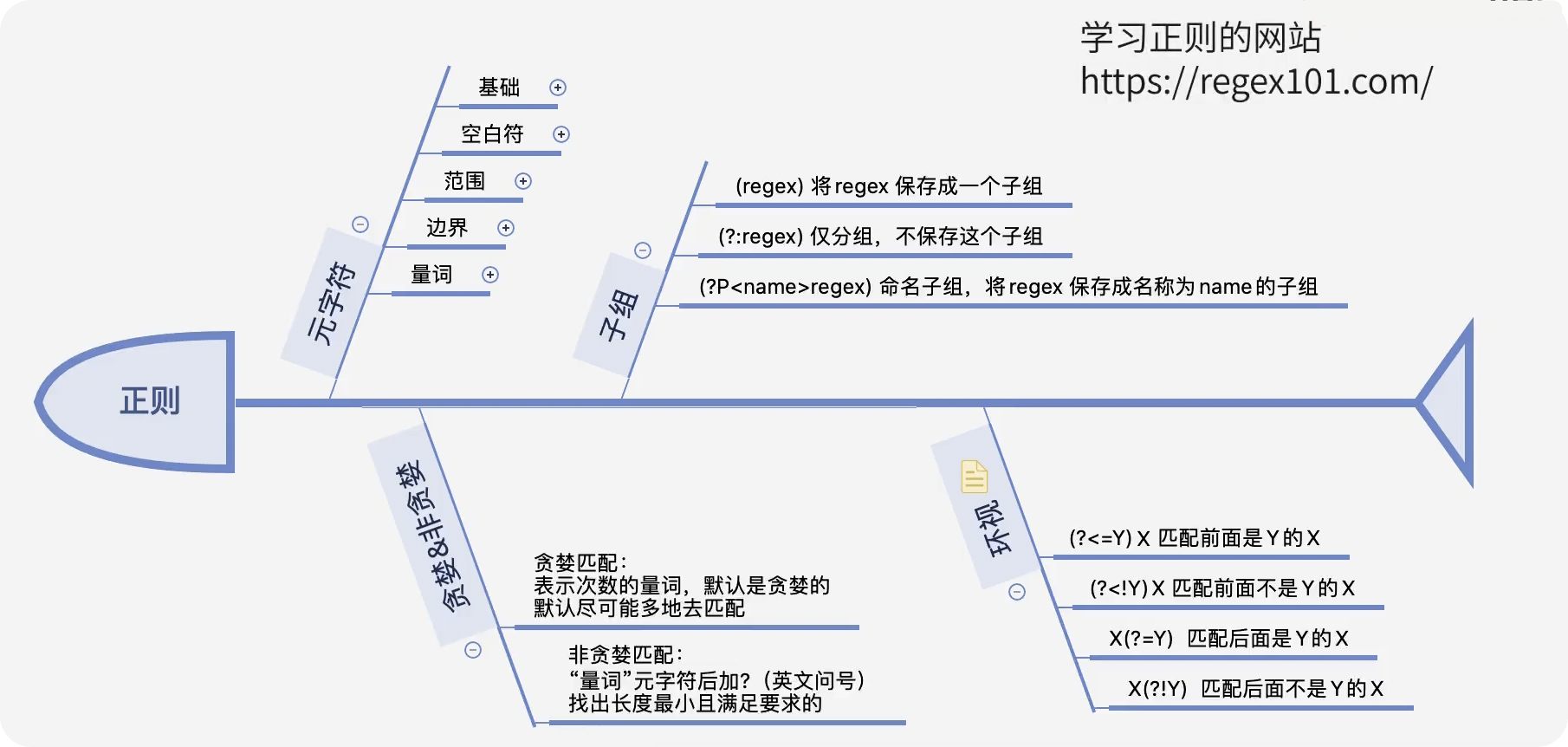 最后我来给你总结一下,正则表达式中原字符的分类记忆,大家可以在脑海中回忆一下,基础常用的、空白符、范围、边界、量词等; 子组则是将一个正则中的部分内容进行分组常常用于内容的替换;而贪婪和非贪婪其实就是量词后面添加问号,去改变匹配次数的偏好; 环视则是限制匹配内容之前或之后要符合某个规则。 今天通过大量的示例让你加强了对正则各类原字符,贪婪与非贪婪,环视等方面的理解,掌握了这些内容相信你就能够掌握日常工作中的一些基本使用了。这里给大家推荐一个网站 https://regex101.com/ 这个网站是学习正则非常棒的一个工具感兴趣可以进一步的了解一下。 |
【本文地址】