人工智能导论实验四 / 深度学习算法及应用 |
您所在的位置:网站首页 › 人工神经网络的基本原理及其应用实验报告 › 人工智能导论实验四 / 深度学习算法及应用 |
人工智能导论实验四 / 深度学习算法及应用
|
一.实验目的
代码已开源:https://github.com/LinXiaoDe/ArtificialIntelligence/tree/master/lab4
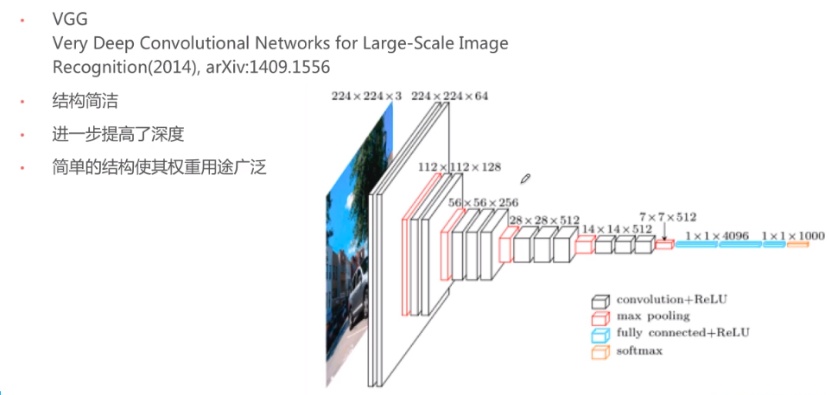
1、了解深度学习的基本原理 2、能够使用深度学习开源工具识别图像中的数字 3、了解图像识别的基本原理 二.实验要求1、解释深度学习原理; 2、对实验性能进行分析; 3、回答思考题; 三.实验的硬件、软件平台硬件:计算机 软件:操作系统:Linux 应用软件:PyTorch,CUDA , Python,使用CNN进行图像分类识别 四. 卷积神经网络 CNN 实现原理 (1) CNN原理卷积神经网络(CNN)主要是用于图像识别领域,它指的是一类网络,而不是某一种,其包含很多不同种结构的网络。所有CNN最终都是把一张图片转化为特征向量,特征向量就相当于这张图片的DNA。就像VGG网络一样,通过多层的卷积,池化,全连接,降低图片维度,最后转化成了一个一维向量。这个向量就包含了图片的特征,(这个特征不是肉眼上的图片特征,而是针对于神经网络的特征)
之所以用VGG举例,因为他的网络结构非常简洁,清晰,相当好理解,简单介绍一下: 他的输入是一张224x224 的三通道图片,经过两层卷积之后,图片维度不变,通道数增加到了64。之后那个红色的层是最大池化(max pooling)把图片维度变成了112x112。后续就是不断重复步骤1,2。当变成1维向量之后,经过全连接(fully connected)加ReLU激活,softmax处理之后,变成了一个包含1000个数字的特征向量。CNN的工作步骤:卷积,池化,全连接,降低图片维度
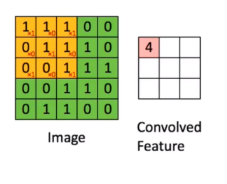
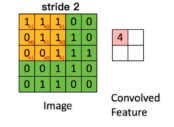
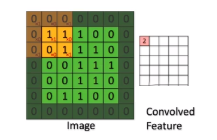
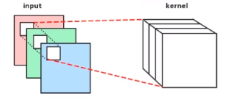
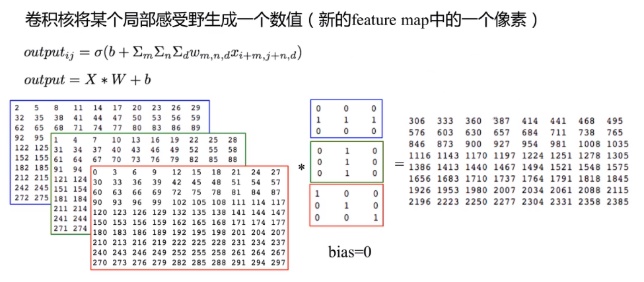
在前向传播过程中,输入的图形数据经过多层卷积层的卷积和池化处理,提出特征向量,将特征向量传入全连接层中,得出分类识别的结果。当输出的结果与我们的期望值相符时,输出结果。 1.1 前向传播中的卷积操作 用一个小的权重矩阵去覆盖输入数据,对应位置加权相乘,其和作为结果的一个像素点;这个权重在输入数据上滑动,形成一张新的矩阵:
如图:
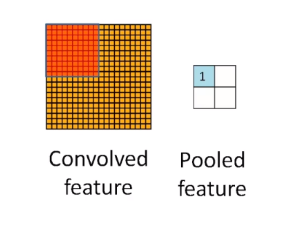
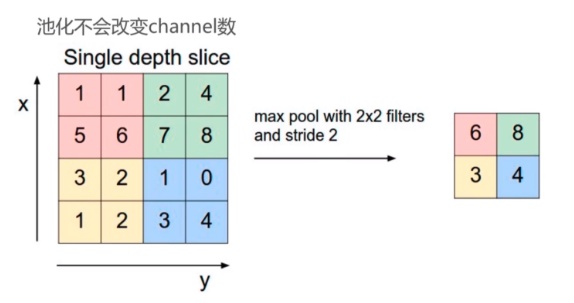
池化又称为降采样(down_sampling),类型: 最大池化(max pooling):在感受野内取最大值输出;平均池化(average pooling):在感受野内取平均值进行输出;其他如L2池化等。理解: 一个选择框,将输入数据某个范围(矩阵)的所有数值进行相应计算,得到一个新的值,作为结果的一个像素点;池化也有步长和补齐的概念,但是很少使用,通常选择框以不重叠的方式,在padding=0的输入数据上滑动,生成一张新的特征图:
特征图进过卷积层和下采样层的特征提取之后,将提取出来的特征传到全连接层中,通过全连接层,进行分类,获得分类模型,得到最后的结果。 2. 卷积神经网络的反向传播过程当卷积神经网络输出的结果与我们的期望值不相符时,则进行反向传播过程。求出结果与期望值的误差,再将误差一层一层的返回,计算出每一层的误差,然后进行权值更新。 3. 卷积神经网络的权值更新卷积层的误差更新过程为:将误差矩阵当做卷积核,卷积输入的特征图,并得到了权值的偏差矩阵,然后与原先的卷积核的权值相加,并得到了更新后的卷积核。 2和3两个部分和神经网络是一致的 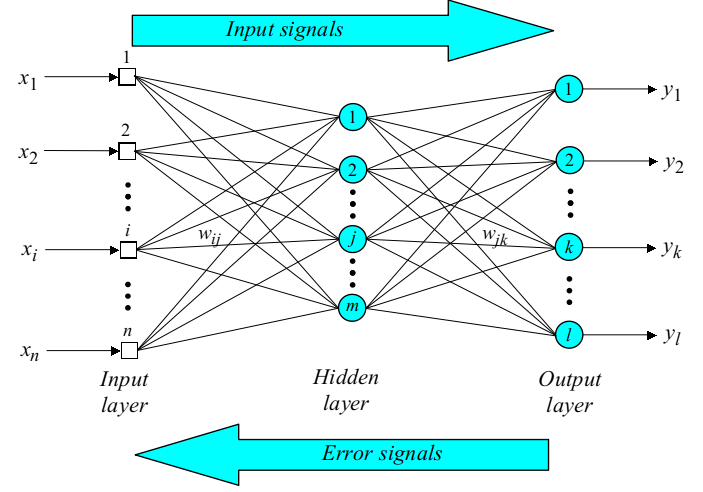
back propagation 算法思想: 训练数据输入到神经网络中,神经网络计算真实输出与实际输出之间的差异,然后通过调节权值来减小这种差异两阶段 训练数据输入,通过前向层层计算到输出层输出结果 计算真实输出与实际输出之间的错误,通过反向从输出层-隐藏层-输入层的调节权值来减少错误 (3) BP算法步骤: 第一步,初始化设定初始的权值w1,w2,…,wn和阈值θ为如下的一致分布中的随机数 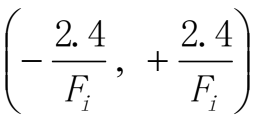
Fi是输入神经元数量总和 第二步:计算激活函数值根据输入x1§, x2§,…, xn§ 和权值w1,w2,…,wn计算输出y1§, y2§,…, yn§ (a)计算隐藏层神经元的输出 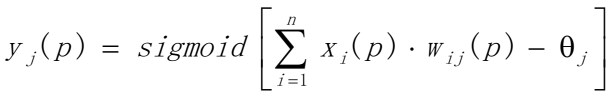
n是第j个隐藏层神经元的输入数量,sigmoid是激活函数 (b)计算输出层神经元的输出 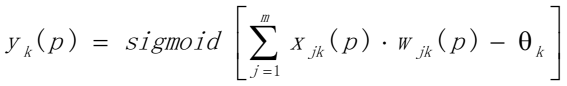
m是第k个输出神经元的输入数量 第三步:权值更新(从后往前)(a)计算输出层的错误梯度 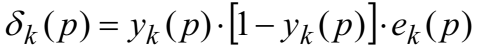 计算权值纠正值 计算权值纠正值
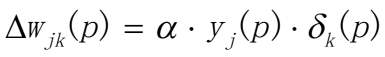 更新输出层的权值 更新输出层的权值
(b)计算隐藏层的错误梯度 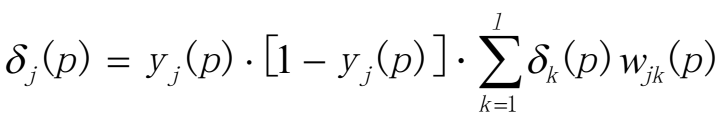
计算权值纠正值 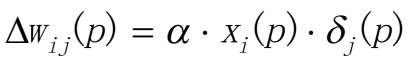
更新隐藏层的权值 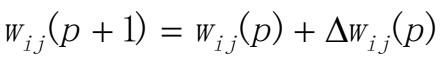 第四步:迭代循环
第四步:迭代循环
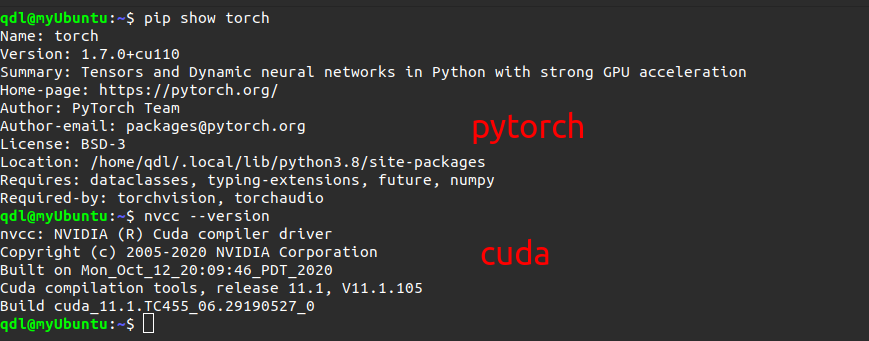
增加p值,不断重复步骤二和步骤三直到收敛 五.实验内容与步骤1、安装开源深度学习工具设计并实现一个深度学习模型,它能够学习识别图像中的数字序列。然后使用数据训练它:你可以使用人工合成的数据(推荐),或直接使用现实数据。 1.环境搭建安装CUDA和PyTorch PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一个基于Python的可续计算包,提供两个高级功能: 1、具有强大的GPU加速的张量计算(如NumPy) 2、包含自动求导系统的深度神经网络。
NVIDIA CUDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA CUDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。 在这之前,我自行安装过,可以参考我的一篇博客:https://littlede.blog.csdn.net/article/details/109407098 下面是我的安装结果: 数据集介绍  MNIST数据集包含60000个训练集和10000测试数据集。分为图片和标签,图片是28*28的像素矩阵,标签为0~9共10个数字获取数据集:http://yann.lecun.com/exdb/mnist/
(1) 数据集格式
MNIST数据集包含60000个训练集和10000测试数据集。分为图片和标签,图片是28*28的像素矩阵,标签为0~9共10个数字获取数据集:http://yann.lecun.com/exdb/mnist/
(1) 数据集格式
数据以非常简单的文件格式存储,旨在存储矢量和多维矩阵。此格式的常规信息在此页的末尾给出,但是您无需阅读即可使用数据文件。 有4个文件: train-images-idx3-ubyte:训练集图像 train-labels-idx1-ubyte:训练集标签 t10k-images-idx3-ubyte:测试集图像 t10k-labels-idx1-ubyte:测试集标签训练集包含60000个示例,测试集包含10000个示例。测试集的前5000个示例来自原始的NIST训练集。最后的5000个来自原始的NIST测试集。前5000个比后5000个更干净,更容易。 训练设置标签文件train-labels-idx1-ubyte [offset] [type] [value] [description]` `0000 32 bit integer 0x00000801(2049) magic number (MSB first)` `0004 32 bit integer 60000 number of items` `0008 unsigned byte ?? label` `0009 unsigned byte ?? label` `........` `xxxx unsigned byte ?? label The labels values are 0 to 9. 训练集图像文件train-images-idx3-ubyte [offset] [type] [value] [description]` `0000 32 bit integer 0x00000803(2051) magic number` `0004 32 bit integer 60000 number of images` `0008 32 bit integer 28 number of rows` `0012 32 bit integer 28 number of columns` `0016 unsigned byte ?? pixel` `0017 unsigned byte ?? pixel` `........` `xxxx unsigned byte ?? pixelPixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black). 测试集标签文件t10k-labels-idx1-ubyte [offset] [type] [value] [description] 0000 32 bit integer 0x00000801(2049) magic number (MSB first) 0004 32 bit integer 60000 number of items 0008 unsigned byte ?? label 0009 unsigned byte ?? label ........ xxxx unsigned byte ?? label The labels values are 0 to 9.The labels values are 0 to 9. 测试集图像文件t10k-images-idx3-ubyte [offset] [type] [value] [description] 0000 32 bit integer 0x00000803(2051) magic number 0004 32 bit integer 10000 number of images 0008 32 bit integer 28 number of rows 0012 32 bit integer 28 number of columns 0016 unsigned byte ?? pixel 0017 unsigned byte ?? pixel ........ xxxx unsigned byte ?? pixel像素按行组织。像素值为0到255。0表示背景(白色),255表示前景(黑色)。 (2) 数据集处理使用torchvision的datasets直接下载MNIST数据 data_train和data_test root为数据集存放的路径transform指定数据集导入的时候需要进行的变换train设置为true表明导入的是训练集合,否则会测试集合。 train_data = datasets.MNIST(root = "./data/", transform=transform, train = True, download = True) test_data = datasets.MNIST(root="./data/", transform = transform, train = False)使用 torchvision 的 transforms进行格式转化 Compose是把多种数据处理的方法集合在一起。transform里面还有很多好的方法,可以用在图片资源较少的数据集做Data Argumentation操作,这里只是做了个简单的Tensor格式转换和Batch Normalize transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5],std=[0.5])]) # 给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。 # 即:Normalized_image=(image-mean)/std. MINIST是(1,28,28)不是RGB的三维 # 只有一维的灰度图数据,所以不是[0.5,0.5,0.5],而是[0.5]数据集获取结果: train_data 的个数:60000个训练样本test_data 的个数:10000个训练样本一个样本的格式为[data,label],第一个存放数据,第二个存放标签 (3) 加载数据集
使用torch.utils.data.DataLoader加载数据集设置batch_size=64后,加载器中的基本单位是一个batch的数据加载到dataloader中后,一个dataloader是一个batch的数据
train_loader = torch.utils.data.DataLoader(train_data,batch_size=64,
shuffle=True,num_workers=2)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=64,
shuffle=True,num_workers=2)
(4)查看图形结果
从二维数组生成一张图片
oneimg,label = train_data[0]
oneimg = oneimg.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
oneimg = oneimg * std + mean
oneimg.resize(28,28)
plt.imshow(oneimg)
plt.show()
(3) 加载数据集
使用torch.utils.data.DataLoader加载数据集设置batch_size=64后,加载器中的基本单位是一个batch的数据加载到dataloader中后,一个dataloader是一个batch的数据
train_loader = torch.utils.data.DataLoader(train_data,batch_size=64,
shuffle=True,num_workers=2)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=64,
shuffle=True,num_workers=2)
(4)查看图形结果
从二维数组生成一张图片
oneimg,label = train_data[0]
oneimg = oneimg.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
oneimg = oneimg * std + mean
oneimg.resize(28,28)
plt.imshow(oneimg)
plt.show()
batch_size设置了每批装载的数据图片为64个,shuffle设置为True在装载过程中为随机乱序下图为一个batch数据集(64张图片)的显示,可以看出来都为28*28的1维图片:
网络结构是两个卷积层,3个全连接层。 Conv2d参数介绍: in_channels(int) – 输入信号的通道数目out_channels(int) – 卷积产生的通道数目kerner_size(int or tuple) - 卷积核的尺寸stride(int or tuple, optional) - 卷积步长padding(int or tuple, optional) - 输入的每一条边补充0的层数 (1) CNN网络结构我定义了两个卷积层进行特征的提取: 第一个卷积层:因为输入的是灰度图片(RGB为3),定义输入通道定义为1;kernel选择为 3 x 3;步长为1;输出为32通道。 第二个卷积层的kernel则是 3 x 3,步长为1,输入和第一层的输入一致,32通道;输出为64通道。 选择MaxPool2d进行两个池化 class Model(nn.Module): def __init__(self) -> None: super(Model,self).__init__() # 卷积层1 self.conv1 = nn.Conv2d(1,32,kernel_size=3,stride=1,padding=1) self.pool = nn.MaxPool2d(2,2) # 卷积层2 self.conv2 = nn.Conv2d(32,64,kernel_size=3,stride=1,padding=1) self.fc1 = nn.Linear(64*7*7,1024) #两个池化,所以是7*7而不是14*14 self.fc2 = nn.Linear(1024,512) self.fc3 = nn.Linear(512,10) (2) 前向传播过程在前向传播的过程中,输入的图像是 28 x 28 x 1,经过第一个卷积层之后,由于kernel size = 3,所以其变为(28 - 3 + 1) x (28 - 3 + 1) x 32 即 26 x 26 x 32,经过一个ReLU激活函数后经过池化层,使用最大池化,size = 2,变为 13 x 13 x 8,再经过第二个卷积层,kernel size = 3,转变为 11x11x64,同样的,经过ReLU激活函数经过最大池化层,得到 7 x 7 x 64 的特征图,由于之后要进行全连接神经网络,所以将其展开成 7 x 7 x 64 的张量。我们回到CNN的定义,可以看到hideinput0的输入维度也是 7 x 7 x 64。 # 前向传播的过程 def forward(self,x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 7* 7) #将数据平整为一维的 x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) # x = F.log_softmax(x,dim=1) NLLLoss()才需要,交叉熵不需要 return x (3) 定义损失函数和优化函数 self.criterion = nn.CrossEntropyLoss() # 交叉熵 self.optimizer = optim.SGD(self.model.parameters(), lr=lr, momentum=0.9) # 随机梯度下降优化器 #也可以选择Adam优化方法 # self.optimizer = torch.optim.Adam(net.parameters(),lr=1e-2) # self.dp = nn.Dropout(p=0.5) 5.模型训练初始化加载模型,采用SGD作为优化器,由于是对数字图像的分类任务,所以我选择交叉熵作为损失函数。在训练的过程中,不断的执行前向+后向+优化,迭代epochs次,同时记录每100个batch的损失值提供给后续的训练结果分析使用。下面是实现的代码。 # 训练拟合 def fit(self,train_loader): net = self.model device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net = net.to(device) for epoch in range(self.epochs): running_loss = 0.0 for i,data in enumerate(train_loader,0):#0是下标起始位置默认为0 # data 的格式[[inputs, labels]] # inputs,labels = data inputs,labels = data[0].to(device), data[1].to(device) #初始为0,清除上个batch的梯度信息 self.optimizer.zero_grad() #前向+后向+优化 outputs = net(inputs) loss = self.criterion(outputs,labels) loss.backward() self.optimizer.step() # loss 的输出,每个一百个batch输出,平均的loss running_loss += loss.item() if i%100 == 99: print('[%d,%5d] loss :%.3f' % (epoch+1,i+1,running_loss/100)) running_loss = 0.0 self.train_loss.append(loss.item()) # 训练曲线的绘制 一个batch中的准确率 correct = 0 total = 0 _, predicted = torch.max(outputs.data, 1) total = labels.size(0)# labels 的长度 correct = (predicted == labels).sum().item() # 预测正确的数目 self.train_accs.append(100*correct/total) # 训练完成 print('Finished Training') # 保存训练结果 torch.save(net.state_dict(), self.PATH) 六.结果测试与分析 1. 模型评估我们的模型训练效果如何?训练是否收敛?对此,我记录了每100个batch的loss损失函数值,使用plt对训练准确率train_accs,训练损失train_loss,以及迭代次数train_iters进行绘图,观察绘制结果,反映模型的训练过程: def draw_train_process(title,iters,costs,accs,label_cost,lable_acc): plt.title(title, fontsize=24) plt.xlabel("iter", fontsize=20) plt.ylabel("acc(\%)", fontsize=20) plt.plot(iters, costs,color='red',label=label_cost) plt.plot(iters, accs,color='green',label=lable_acc) plt.legend() plt.grid() plt.show()下面是训练过程: 可以看到整个数据的训练过程中训练准确率train_accs逐渐上升,最终趋近100%,训练损失train_loss逐渐下降,最终趋近0.整体上训练效果还是比较可观的
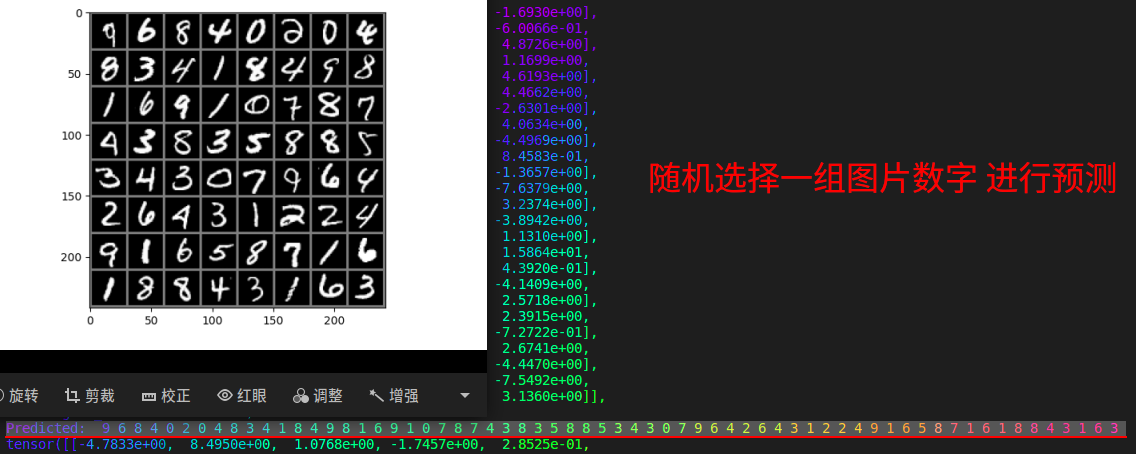
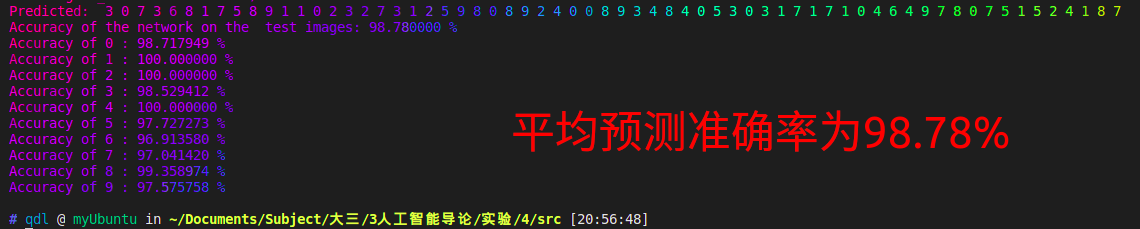
我们可以用images, labels = dataiter.next()获取一批图片,并且对图片进行预测,如下图所示。 # 检验一个batch的分类情况 def predOneBatch(self,test_loader): dataiter = iter(test_loader) images, labels = dataiter.next() # print images test_img = utils.make_grid(images) test_img = test_img.numpy().transpose(1,2,0) std = [0.5,0.5,0.5] mean = [0.5,0.5,0.5] test_img = test_img*std+0.5 plt.imshow(test_img) plt.show() print('GroundTruth: ', ' '.join('%d' % labels[j] for j in range(64))) self.model.load_state_dict(torch.load(self.PATH)) test_out = self.model(images) print(test_out) _, predicted = torch.max(test_out, dim=1) print('Predicted: ', ' '.join('%d' % predicted[j] for j in range(64)))我们随机获取了一批图片,并且对他们进行预测,预测结果在下方,可以发现,对于64个手写图片,结果都正确,可见预测十分准确。 为了观察训练结果如何,预测测试集上的整体准确率,我将训练集作为测试数据进行了预测,统计了预测结果准确率。 correct = 0 total = 0 with torch.no_grad():# 进行评测的时候网络不更新梯度 for data in test_loader: images, labels = data outputs = test_net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0)# labels 的长度 correct += (predicted == labels).sum().item() # 预测正确的数目 print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
为了检测CNN分类性能如何,我将10个数字分类,并且单独统计了每一个数字的准确率,代码实现如下: class_correct = list(0. for i in range(10)) class_total = list(0. for i in range(10)) with torch.no_grad(): for data in test_loader: images, labels = data outputs = test_net(images) _, predicted = torch.max(outputs, 1) c = (predicted == labels) for i in range(10): label = labels[i] class_correct[label] += c[i].item() class_total[label] += 1 for i in range(10): print('Accuracy of %d : %4f %%' % (i, 100 * class_correct[i] / class_total[i])) 测试结果:
观察结果发现,0~9共10个数字的预测准确率都在98%左右,其中0,1,3的预测精确度达到了100%,5和7的预测结果稍差,在95%左右。 六.思考题深度算法参数的设置对算法性能的影响? 本实验中的CNN的参数设置有如下这些。 卷积层 nn.Conv2d 参数·含义in_channels输入信号的通道数.out_channels卷积后输出结果的通道数.kernel_size卷积核的形状. 例如kernel_size=(3, 2)表示3X2的卷积核,如果宽和高相同,可以只用一个数字表示stride卷积每次移动的步长, 默认为1. 参数·含义padding处理边界时填充0的数量, 默认为0(不填充).dilation采样间隔数量, 默认为1, 无间隔采样.groups输入与输出通道的分组数量. 当不为1时, 默认为1(全连接).bias为 True 时, 添加偏置. 池化层:nn.MaxPool2d() 参数含义kernel_size最大池化操作时的窗口大小stride最大池化操作时窗口移动的步长, 默认值是 kernel_sizepadding输入的每条边隐式补0的数量dilation用于控制窗口中元素的步长的参数return_indices如果等于 True, 在返回 max pooling 结果的同时返回最大值的索引 这在之后的 Unpooling 时很有用ceil_mode如果等于 True, 在计算输出大小时,将采用向上取整来代替默认的向下取整的方式上面的参数我们不一定全部需要设置,一般的我们需要调整的参数是: CNN的各部分层数,卷积核的形状,卷积核的数量,卷积层的步长以及Padding,池化层的选择,激活函数的选择。 CNN层数:层数越多,模型的训练效果越好,但是训练时间也会相应增加,所以要结合实际进行设置。 卷积核的形状kernel_size:决定了其提取的特征的数目,需要进行调参根据经验才能确定,当前还没有一个确定的算法计算。 卷积层的步长和Padding:Padding = 0会使得边缘的特征提取不完全;为了防止过拟合,可以加入Dropout层,将小于阈值的值赋值为0,进行丢弃。除此之外,还可以对优化器的学习率进行修改,较小的学习率会使收敛速率较慢,但是较大的学习率又会导致发散和欠拟合。 优化方法选择:本次实验中选择的是SGD 随机梯度下降优化器方法,我们也可以选择也可以选择Adam优化方法,他们的选择情况也需要根据实际测试来调整。 self.optimizer = optim.SGD(self.model.parameters(), lr=lr, momentum=0.9) # 随机梯度下降优化器 #也可以选择Adam优化方法 # self.optimizer = torch.optim.Adam(net.parameters(),lr=1e-2) # self.dp = nn.Dropout(p=0.5) |
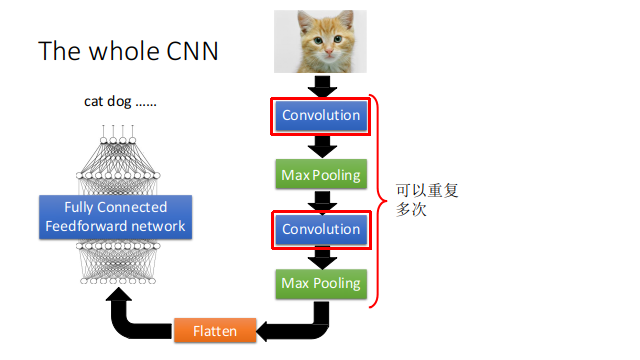
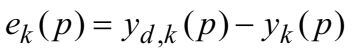



 下面,我们就能开始构建CNN卷积层了。
下面,我们就能开始构建CNN卷积层了。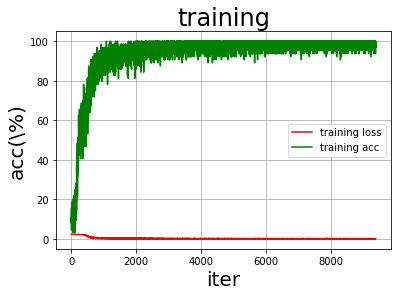
【本文地址】