交换式以太网的诞生 |
您所在的位置:网站首页 › 交换式以太网与共享式以太网的差异在于 › 交换式以太网的诞生 |
交换式以太网的诞生
|
电路交换,终端(电话)独占端线路自然而然,天经地义,可计算机收发的是数据包(即数据分组),当多台终端接入到同一个共享介质的网络,所有终端可 “同时” 收发数据,一起统计复用网络,多台终端如何协调共享介质的访问,这就是教科书上所谓 MAC(媒体访问控制协议) 子层的职责。 值得注意的是,早期 arpanet 实验基本都是点对点线路,虽然数据以数据包分组为单位收发,但几乎不涉及多台终端同时收发的共享介质仲裁,一条线缆只拴一台终端,网络协议集中解决网络层以上问题,底层复用既有线路和协议。 在以太网出现后,底层链路层,MAC 子层才开始变得不同。 最初以太网 MAC 协议竟然以如此简洁的方式给出:随时发送,失败了重试,直到成功或尝试到放弃。这个极简机制后,以太网自发演化到了交换式,与广域网路由/交换不同,交换式以太网是真正从零开始,根正苗红的原教旨分组交换网。 我来猜猜事情是如何发生的: 值得一提的是,双绞线并不是创造甚至演化出来的,而是复用了已有的电话线。电话线早已深入人心,便宜,方便,柔软,可同轴电缆是什么,贵,安装繁琐,硬,以前的那种有线电视电缆,远不如电话线。 复用电话线的形式似乎是一个范式,汽车也复用了马车的形式。 但更大的突破在软件上。 冲突域虽没变化,但共享介质已被压缩到一个盒子那么狭小的空间。空间尺度的变化影响了软件的变化。 在如此狭小的空间里可以用一种比 CSMA/CD 更精确更有效的方式解决冲突。共享线缆越短,相同大小数据占据线路的时间越短,当这个时间小到一定程度时,全局调度将可接受。 假设信号以光速传播,共享线缆压缩到足够短,那么只需借用 “在一个点通过一个数据包” 的时间独占介质即可,这个时间尺度很容易全局调度,相比较之下,如果在整张以太网全局调度,则调度时间大大增加,增加到光速通过网络尺寸的时间尺度,数据包通过一个大概 200 米的网络,需独占 1us 左右的时间,这将大大限制平均吞吐。 CSMA/CD 在大空间尺度下虽然被证明有足够好的统计性能,但这是不得不这么做,根本原因在时间。冲突信息的回传受光速限制,这没有办法解决。当共享介质的空间尺寸被压缩了将近 1000 倍,10000 倍时,问题就容易解决了。 闭合一个开关即可介质独占。如果多个端口向同一个端口发送,则先通过 buffer 暂存一个。在电路层面,所有端口都全局可见,因此所有这些调度操作都可在极短时间精确完成,这个时间尺度在数据传输时延的若干数量级之下,这提供了全局控制的可行性依据。 逐步压缩长度,逐步压缩了仲裁时间,逐步清晰化了全局视图,最终彻底隔离了冲突域。下图是一个 4 口交换机示例: 隔离了冲突域之后,冲突不再存在,时间被良好安排,所有时间片将不会再被浪费在冲突和退避重试上,吞吐性能开始起飞,100Mbps,1000Mbps,10Gbps,25Gbps,… 800Gbps,1.6Tbps,万变不离其宗。 交换以太网从此突破了共享介质以太网的距离限制,网络的规模不再由冲突信号回传时间决定,而仅由信号强度决定,更容易拓展到更大规模的网络比如城域网,广域网。 “时间被良好安排,所有时间片将不会再被浪费在冲突和退避重试上” 让事情开始: 在一个大得多的空间范围统御全局很难,无论获取全局视图还是指令传递和响应的时间都不可接受,这种情况不得不在一定规则下做分布式管理,但在一个路口指挥交通却很容易,指令喊一声都能马上听到。 这就是交换式以太网的演化由来。 我非常惊叹于两种 “传统优化手段”:增加物理资源,适应时间尺度。这两点完美体现在以太网交换机上。 全双工问题通过增加一条线缆解决,从物理上彻底隔离两个方向,实现独立收发,而不仅仅是逻辑上做 “分时复用”,原因在于收发对等,它毫无弹性。而冲突问题则通过缩短共享介质的物理尺寸,待仲裁时间远低于传输时延后实现全局资源调度。在数量级的时间尺度差异的更细粒度上控制资源切换,好像它们在 “同时” 使用一样。这里没有采用增加物理资源的方式,因为统计复用本身在时间上存在极大弹性,通过排队缓存突发,可以将时间片尽可能摊平,保障资源利用率。 … 时间尺度和弹性的利用可谓非常精妙。此前的文章也提到过,在广域网传输领域优化软中断的锁时延收益甚小,因为与传播时延相比,CPU 处理时延微不足道,但同样的事在数据中心就十分必要,因为同样的 CPU 处理时延在数据中心占比大了几乎 1000 倍。 数据中心内部的传输协议算法不能太复杂的原因即在于此,一个复杂的算法非常消耗 CPU 资源,处理时延本身对总体性能影响巨大,然而同样的算法在广域网领域就可以放手开干。总之,如果一个操作时间占比被缩放到了微不足道的尺度,这部分就可以玩更多花样了。交换机操作的时间尺度控制在光速通过门电路的时间,与光速通过 200 米的时间相比,它微不足道,于是交换芯片的机制和策略可以有非常多的花样来优化,而几百米的同轴电缆上 CSMA/CD 已经接近最优了。 再看增加物理资源和弹性调度之间的取舍。 类似多核处理,增加物理资源提高并行度,而不是靠算法来调度资源,更好的算法提供了更好仲裁方式,而增加物理资源则取消了仲裁的必要。如果资源使用是非弹性的,需要持续仲裁,无法通过暂时排队将请求摊平到空闲时间片,此时需要增加物理资源。但弹性资源则比较适合用算法进行调度。 分组交换网本身就是弹性资源的例子,解决的就是电路交换线路利用率问题,分组交换本身就是一套 “数据调度算法”,即统计复用。 往时髦说,如今的云计算本身是 “调度弹性资源” 的另一个例子。类似 12306 购票,春晚,双 11,电商促销等分阶段突发业务的 “农闲期”,资源要避免过度闲置,厂商需要用较低的价格将这些农闲期的资源出售出去,这就存在一种 “上云的趋势”,云客户支付更低的费用给云厂商而开除了自己的 IT 管理员,退租了机架,这显然更划算。 … 更有趣的是,虽然交换式以太网已经出现 30 多年了,击败了几乎所有对手,越来越风靡,但以交换式以太网接入互联网的终端却越来越少了,而随着移动互联网的继续发展,更多终端以 Wi-Fi/4G/5G 方式接入,而不是有线的交换式以太网。 4G/5G 继承了太多传统电路交换的底层机制(它们本就是电信阵营),自不必说,时隙,频率都事先分配好了,可以理解成传统电话的无线版,但绝不会是共享介质,电信阵营从不看好统计复用,因此它们自然复杂,昂贵。 Wi-Fi 则完全不同,即使到了 2023 年,它本质上还是一个共享介质的半双工网络,“随时发送,失败了重试,直到成功或尝试到放弃” 的无线版本。之所以这么多年 Wi-Fi 还在共享介质,完全因为两点,首先空气和电磁波频率本身就是共享的,没有办法像有线网络那样通过 “拉一根线缆” 的方式增加物理资源解决问题,其次,由于共享介质,尺度无法压缩,在不增加复杂性的前提下冲突无法避免,如果引入固定的信道分配便不再是统计复用网络了,大大增加了接入复杂性和功耗以及管理成本,与互联网简单接入原则相悖。 总体而言,802.11 系列 Wi-Fi 与以太网属同根,虽尚未进阶 “交换式”,但相信随着硬件成本的下降以及频谱资源的释放和有效利用,Wi-Fi 的技术突破也指日可待,目前,可以期待一下 Wi-Fi 7。 另一条路上,TCP/IP 与以太网天然契合,几乎同年同月同日生,共同在一起 40 年,现如今它们几乎就是互联网的全部了,不过 TCP/IP 已经写了很多了,本文只能到此为止。 说到以太网交换机,教科书都是作为一个里程碑一笔带过,是时候表达一下我的观点了。当我写一些跟教科书以及各类文档不一样的东西时,有人建议我 “重新翻翻计网第四版吧”,我是懒得回应的,如果教材上有这些论述,我为什么还要抄一遍。我从不写文档,我写的是观点。然而通用技术教材最大特点就是(我们希望它)没有观点,以维持客观,虽然我们都知道任何著述都不可能没有观点,但我们依然相信它最好没有观点。我们对 TCP 如何脱颖而出不感兴趣,哪怕作者本人来讲,大部分人也懒得听,我们知道 TCP 是什么样就够了。那么很明确,想学 TCP/IP 网络知识和技能,我写的东西可能不适合你,我写的东西受众是已经学了 TCP/IP,但对某些问题百思不得其解的朋友,那么翻翻我的文章目录,总能找到你感兴趣的。 浙江温州皮鞋湿,下雨进水不会胖。 |
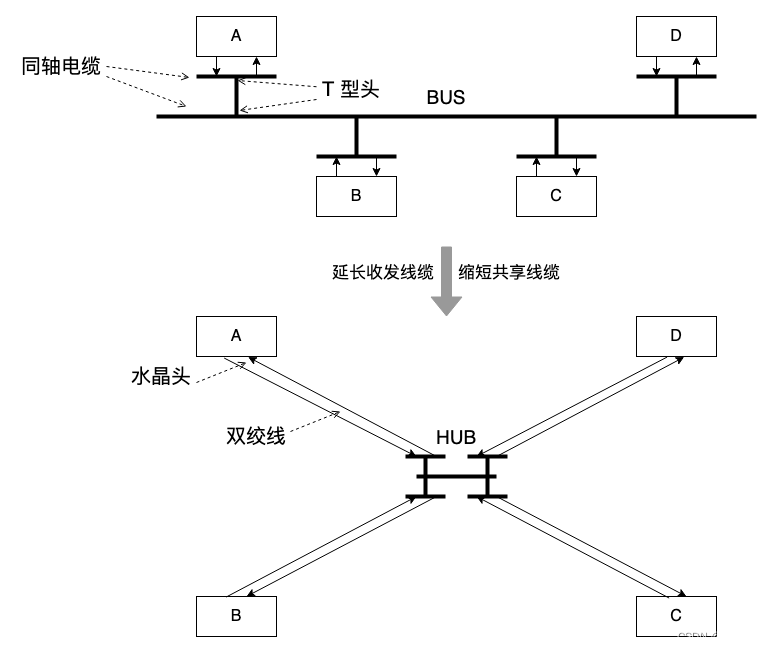 水晶头和双绞线相对 T 型头作为硬件和同轴线更方便部署(排错,更换)且廉价,HUB 显然比同轴电缆更进一步。
水晶头和双绞线相对 T 型头作为硬件和同轴线更方便部署(排错,更换)且廉价,HUB 显然比同轴电缆更进一步。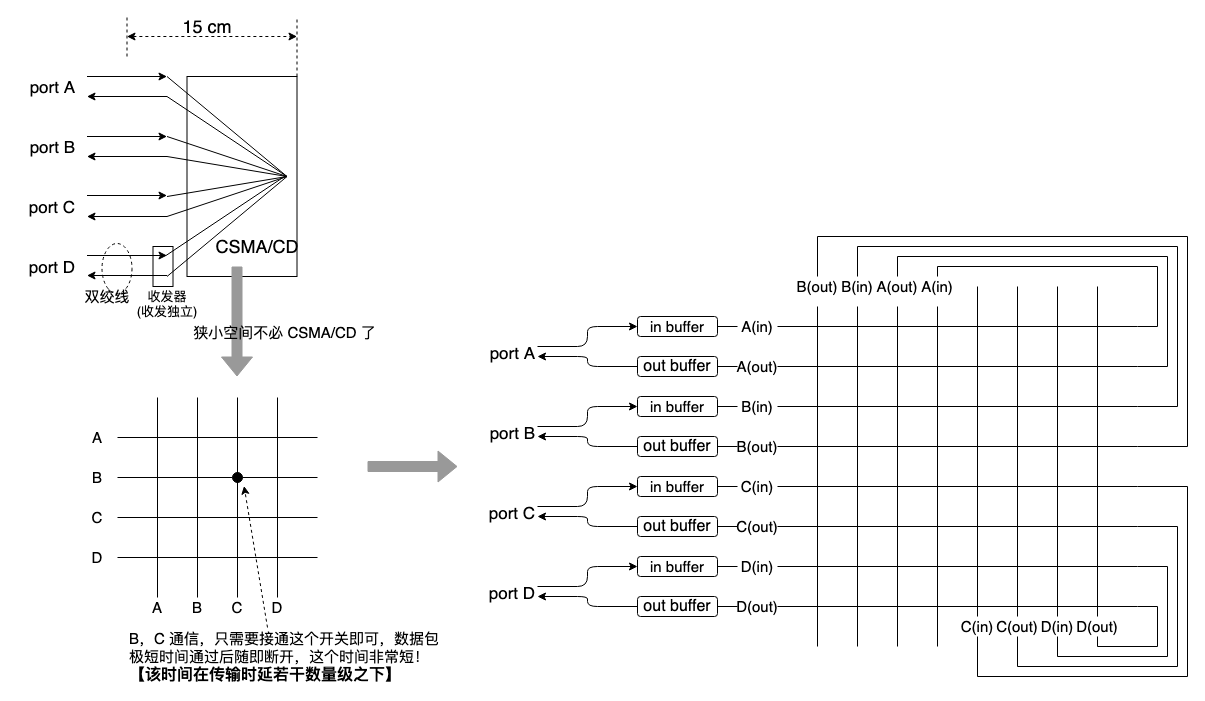

【本文地址】
今日新闻 |
推荐新闻 |