数字电路设计 |
您所在的位置:网站首页 › 五级流水线cpu设计图 › 数字电路设计 |
数字电路设计
|
数字电路设计——流水线处理器
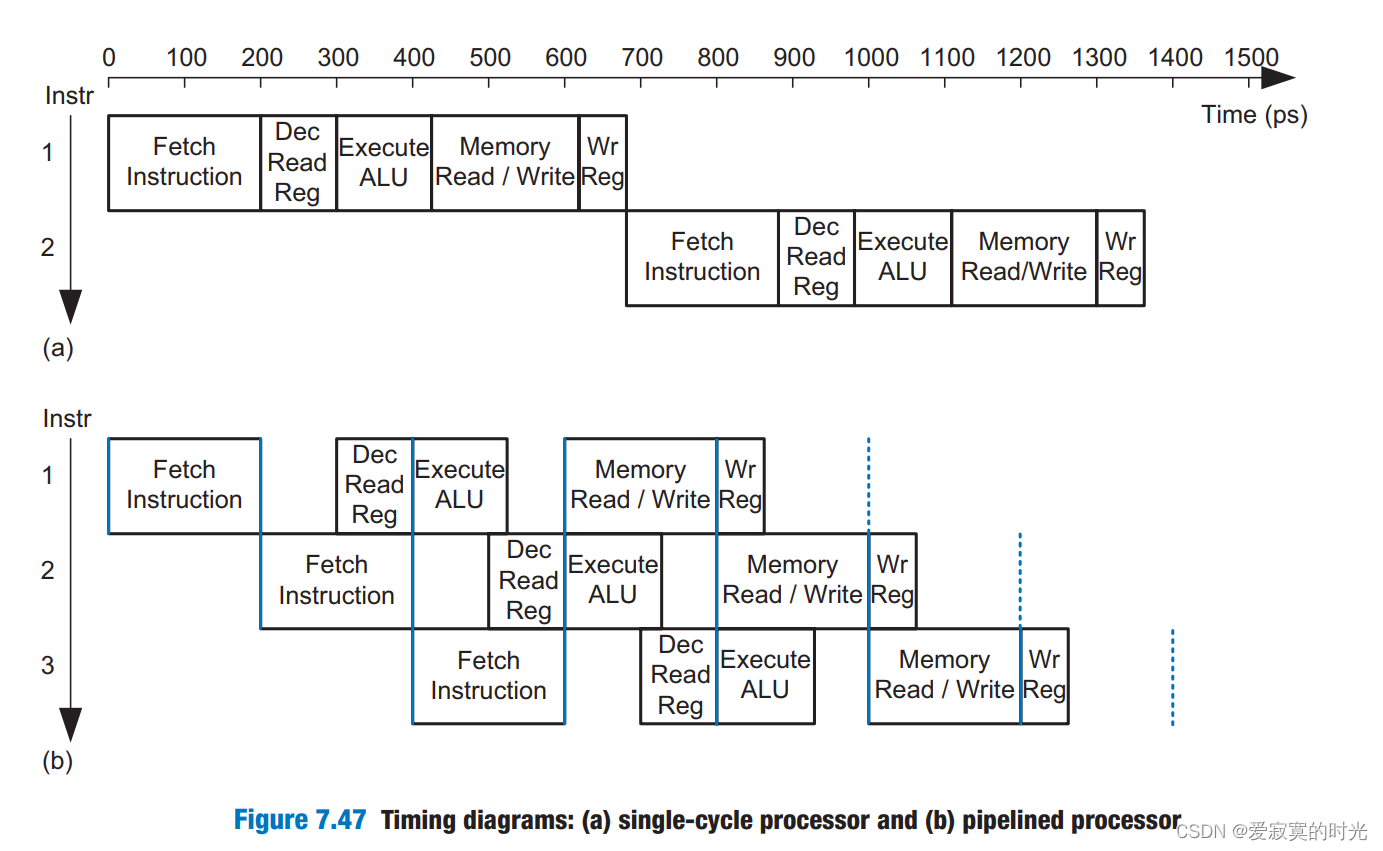
从内存或是寄存器组读写、操作ALU是处理器中最耗时的操作。我们将一个指令拆成五个流水线阶段,每个阶段同时执行耗时的组合逻辑。这五个阶段分别是取指令、解码、执行、访存和写回。 在取指令阶段,处理器从指令存储器中读取一条指令。在解码阶段,处理器从寄存器组读取两个操作数,并解码指令产生相应的控制信号。在执行阶段,处理器执行ALU命令。在访存阶段,处理器从内存中读取数据或者是写入数据。最后,在写回阶段,处理器将结果写回到寄存器组。 下图是单周期和流水线CPU的执行时序比较:
相对于单周期和多周期的CPU设计,流水线CPU最大的困难就是如何处理Hazards(冒险)问题,Hazards发生于一个指令的执行过程依赖于之前的几个指令,这就导致所依赖的指令没有执行完成就开始执行了下一条指令,这将会导致不正确的结果。因此,除了介绍流水线CPU的数据通路设计,我们还需要介绍解决Hazards的几个常用方案,包括forwarding(前送)、stalls(等待)、flushes(清空)来解决Hazards问题。 流水线数据通路流水线数据通路的设计思想很简单,在原有的单周期的CPU的基础上,人为的将数据通路切分成5个阶段,每个阶段使用FF触发器隔开即可:
上图中一个不易发现但最为严重的问题是,寄存器组的写入地址A3,当写回阶段将数据写回寄存器的时候,WD3的输入数据是正确的,但是A3写入地址则是后几个指令的写入地址,解决这个问题可以同步A3的数据传输:
流水线控制逻辑和单周期的CPU使用同样的逻辑控制单元,不同的是,一个指令的控制信号同样需要进行流水同步,这样保证在每个阶段收到的控制信号是当前指令的控制信号,而不是下一条指令的控制信号:
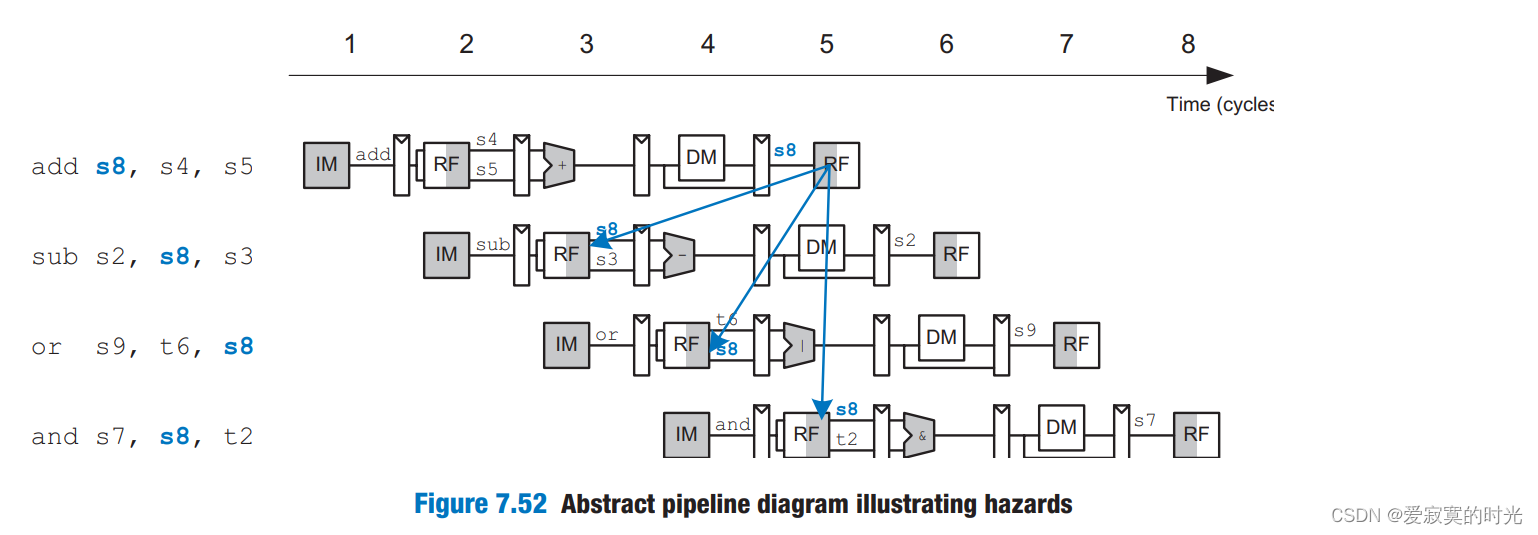
流水线CPU中的指令存在多个指令同时执行的情况,因此当一个指令依赖于上几条未执行结束指令的结果的时候,此时就会发生Hazards。下图展示了一种Hazards的情况:
图中指令二和三都需要指令一add的s8寄存器的结果,而指令四是在第5周期的后半周期读,所以能够读取到正确的结果。 图中的Hazards又被称为写后读(RAW,read after write)Hazard 。若不进行干预,则会产生不正确的结果。最简单的解决方案是从软件汇编的角度来解决,人为的在第一条指令后面插入两个nop指令,这称为软件互锁(software interlock):
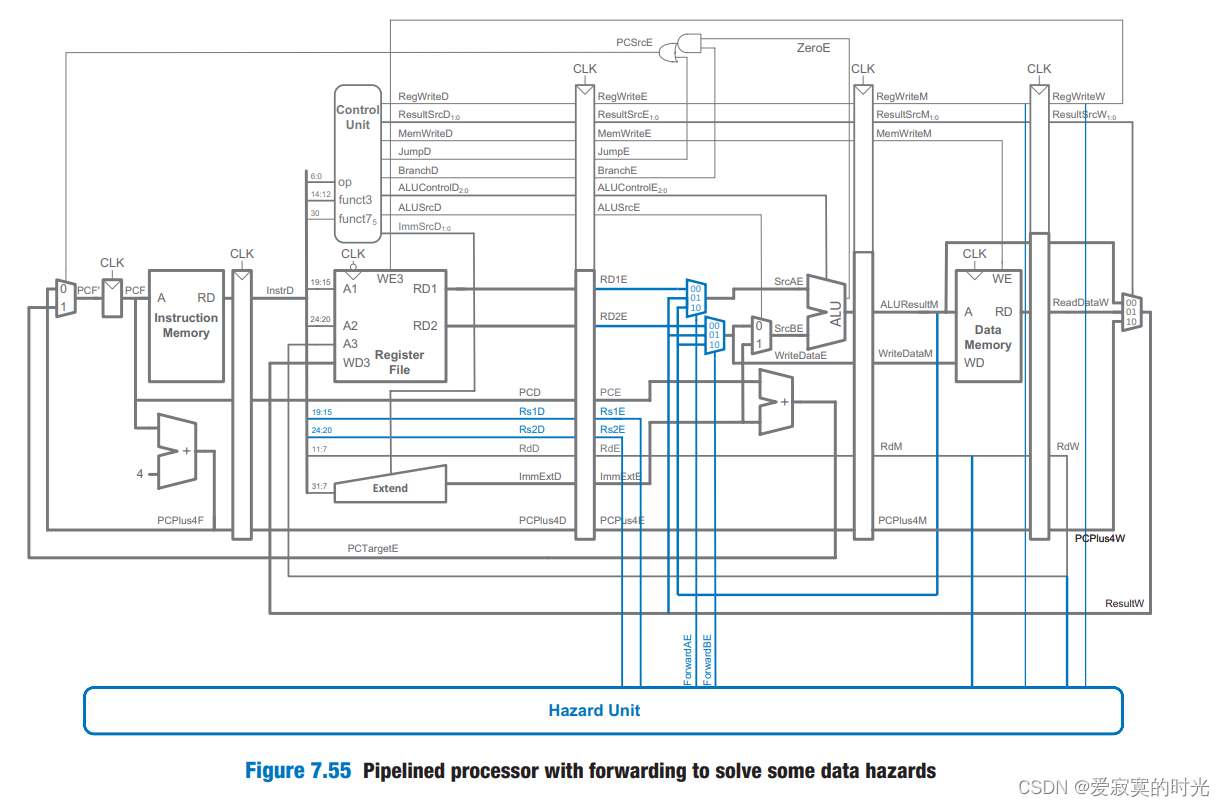
若仔细观察,第一条指令的结果在周期3就可以得出,因此剩余的指令可以直接使用周期三的结果而不用等待写入寄存器组,这称为数据前送。但是特殊情况下我们还是需要等待指令结果的执行完毕,称为Stalls。 总体来说Hazards分为数据Hazards和控制Hazards,数据Hazards就如例子所示,而控制Hazards则是发生在需要修改PC寄存器的时候,在修改PC寄存器的指令结束运行之前,可能已经在执行接下来下面的指令了,而正确的执行过程则是执行跳转处的指令,这将导致指令的意外执行。 通过数据前送解决Hazards一些Hazards能够被数据前送(forwarding)也称旁路(bypassing)解决,有些指令需要等到访存或是写回阶段才能执行完毕,其中结果早在ALU阶段就已经计算得出,因此可以将ALU阶段执行的结果直接送入下一个指令流水,完成数据前送。 我们可以在ALU部件的两个操作数的多路选择器中增加来自访存和写回阶段的总线,如图:
下图是实现电路,在原有的基础上增加了Hazard 单元组件,以及ALU前端的两个前送多路选择器,Hazard 单元组件接收当前ALU执行阶段的两个操作数,以及当前要写入的寄存器地址RdM和RdW,来决定是否从访存或是写回阶段前送数据到ALU中:
当前Hazard 单元组件还要接收RegWriteW和RegWriteM信号来确定寄存器是否被真的写入了。因此,数据前送发生在,当前周期下,写回或访存阶段要写入寄存器A,并且当前ALU要从寄存器A读取值。有一个例外,X0被硬连线为0,不应该被前送。 若写回和访存都匹配当前ALU的操作数的话,访存有更高的优先级,因为其代表了最近一条的指令。下面给出的ForwardAE的逻辑,ForwardBE的逻辑也同理:
数据前送能解决当一个ALU执行阶段的RAW。不幸的是,lw指令不行,lw指令必须等待指令访存之后才能得到结果,这样lw指令就无法再执行阶段进行数据前送。下面的图片说明了这个问题:
解决方案就是Stalls(等待)。将一个指令挂起,直到源操作数可用。下图展示了and指令在译码阶段被挂起:
注意在第4周期执行阶段没有用到,第5周期访存阶段没有用到,第6周期写回阶段没有用到。这种一个周期暂停使用的现象就像气泡一样往前传递。气泡最后会在5个周期内被清除,因此气泡的存在只有极小的性能影响。 总之,Stall一个阶段可以通过停用上一个阶段的FF触发寄存器来实现,因此本阶段的输入不会发生变化,当一个阶段被Stall之前,之前的阶段都应该被Stall,并且该阶段之后的阶段应该被清空(flushed),来防止指令被重复执行。所以,Stall对性能有较大的影响,因此只在必要的阶段使用。 下图展示了增加Stalls功能的Hazard 处理单元:
当Stall发生的时候,StallD和StallF会阻止一个周期的取指令和译码,FlushE同样清空一个执行阶段ALU的输入,这样可以实习向前传播一个周期的空运行(nop) ,即引入一个气泡。 我们将启用Stall的信号记为lwStall,那么:
beq指令存在一个控制Hazards,因为只有beq在更新PC之后,CPU才能决定下一个指令的位置。 一种解决办法的为下面的指令添加两个周期的Stalls,beq在执行阶段之后才知道beq的结果,但是这会严重影响性能。 另一种方法称为分支预测,CPU可以先继续往下执行,一旦发生指令跳转,CPU可以立刻丢弃错误执行的指令,若发送预测错误,浪费的两个周期称为分支预测失败罚时。
上图中beq指令在周期3才能决定下一个指令是0x24还是0x58,假如CPU预测不进行分支跳转,则CPU载入下面两个指令的代码进行执行,当发生指令跳转之后,CPU必须清空(flushed)前两个周期IM和RF的代码,在第4个周期开始执行0x58的代码。
理想情况下流水线处理器的CPI为1,因为一个周期就会取指令一次。但是因为Stalls的存在,必然会浪费几个周期,因此CPI应稍微大于1,取决于具体执行的代码。 具体的当一个需要Stall的load指令需要的CPI=2,当一个分支预测失败的beq指令需要CPI=3,其他情况指令的CPI=1。 通过关键路径来决定最短时钟周期:
|
 下图是一些指令的执行过程:
下图是一些指令的执行过程: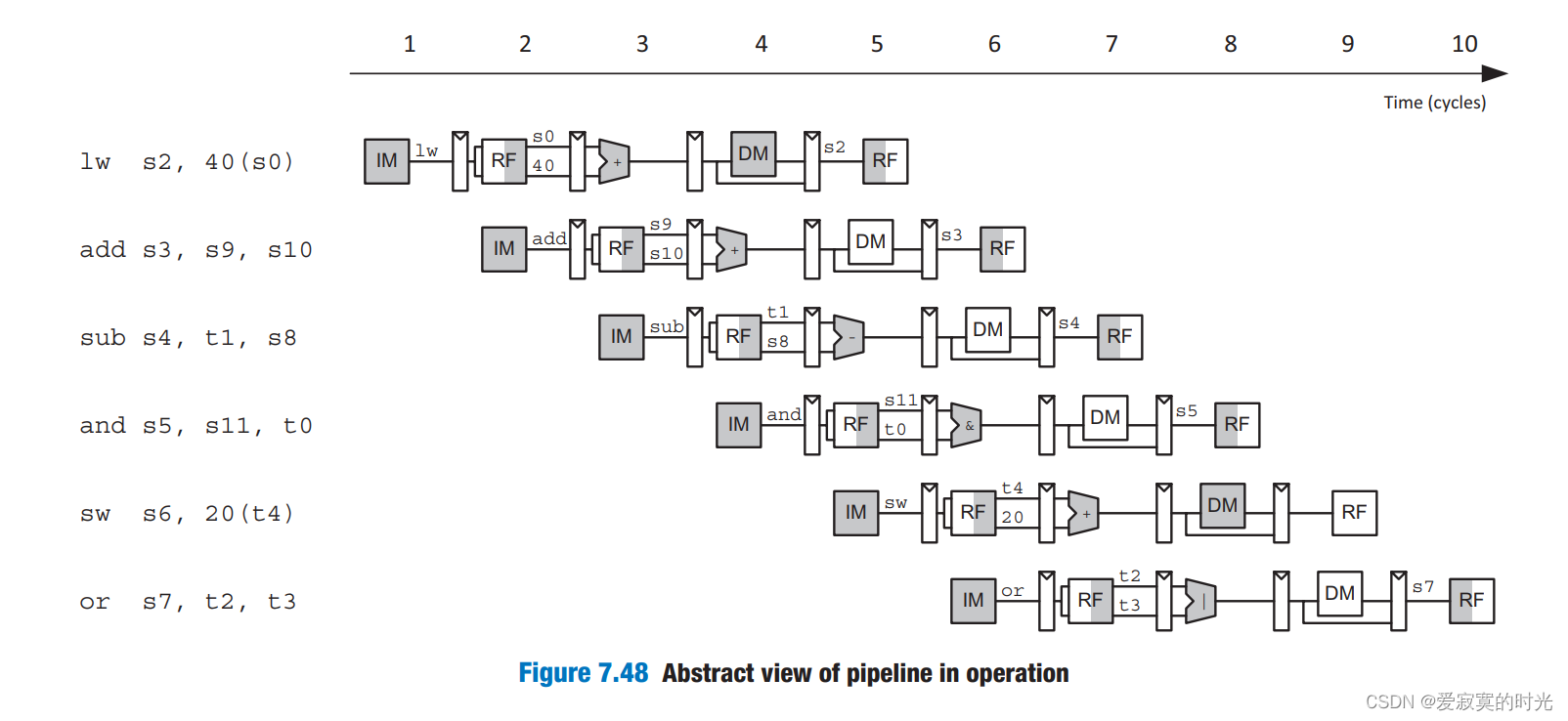 其中IM表示instruction memory,RF表示register file,DM表示data memory。阴影的器件表示该器件在本周期使用,特别的,RF的左边阴影表示写RF,右边阴影表示读RF。
其中IM表示instruction memory,RF表示register file,DM表示data memory。阴影的器件表示该器件在本周期使用,特别的,RF的左边阴影表示写RF,右边阴影表示读RF。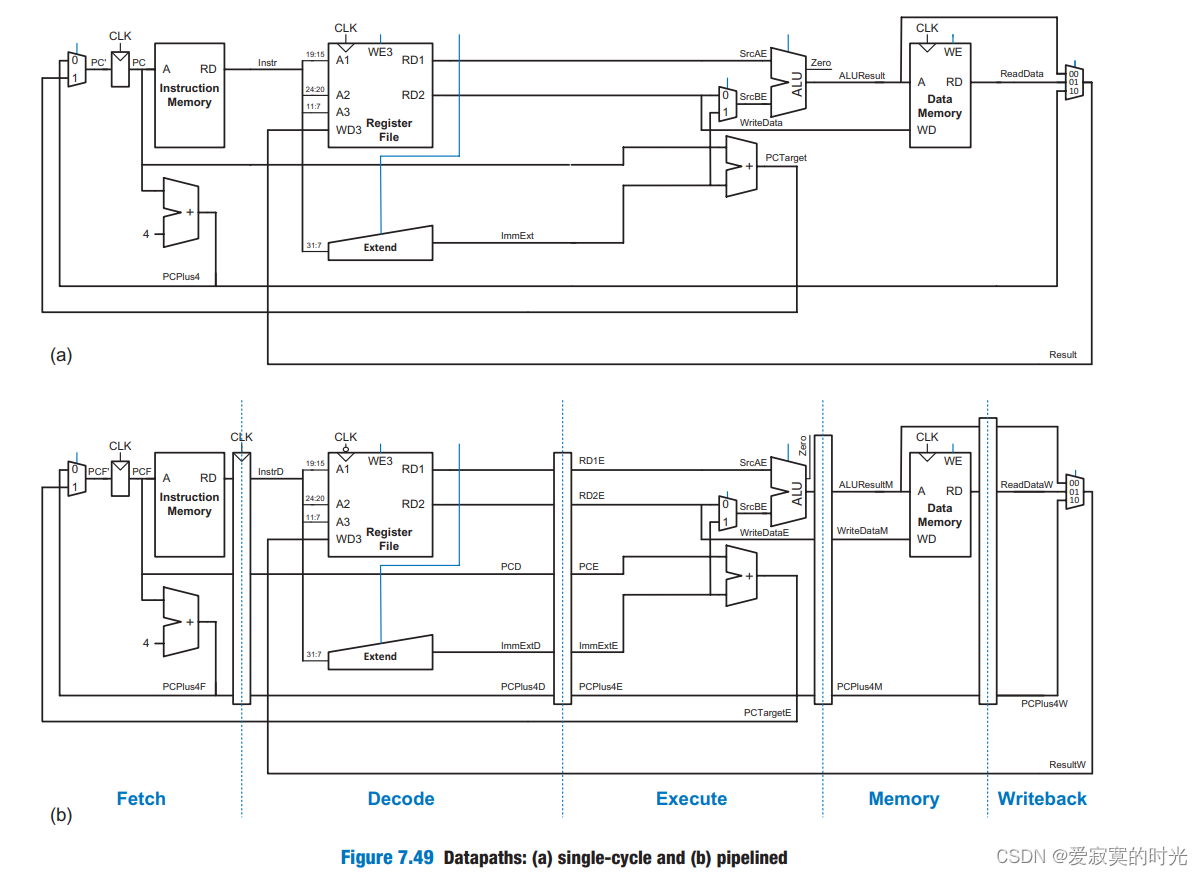 上图中一个寄存器组的CLK接入了一个非门,这样则是在一个周期的下降沿写入数据,可以实现在一个周期的前半部分读取数据,在一个周期的后半部分写入数据。
上图中一个寄存器组的CLK接入了一个非门,这样则是在一个周期的下降沿写入数据,可以实现在一个周期的前半部分读取数据,在一个周期的后半部分写入数据。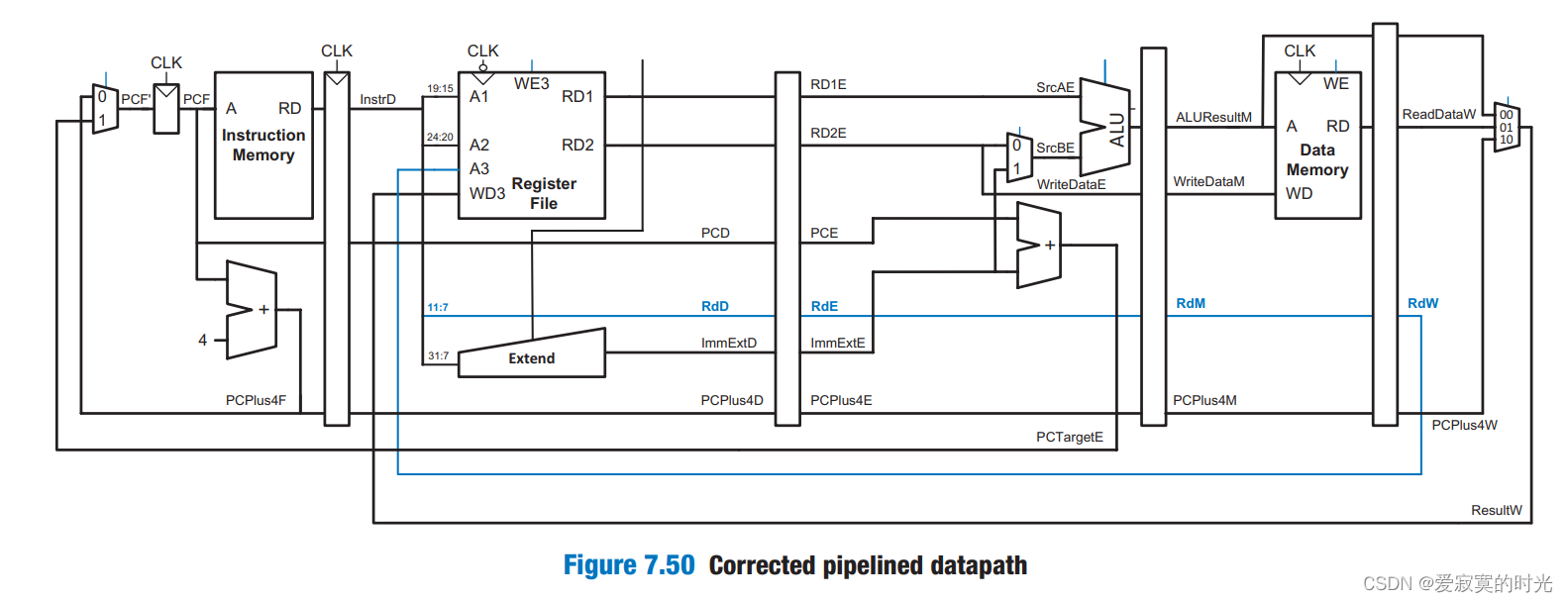 除此之外,PC计数器的下一个PC值PCF’也有类似的问题,假如当前指令需要修改PC计数器的值,只能在写回阶段修改,但是执行到写回阶段,当前指令的后几条指令已经开始执行了,这些反馈回路都会造成Hazards,之后我们会修正这种控制Hazards。
除此之外,PC计数器的下一个PC值PCF’也有类似的问题,假如当前指令需要修改PC计数器的值,只能在写回阶段修改,但是执行到写回阶段,当前指令的后几条指令已经开始执行了,这些反馈回路都会造成Hazards,之后我们会修正这种控制Hazards。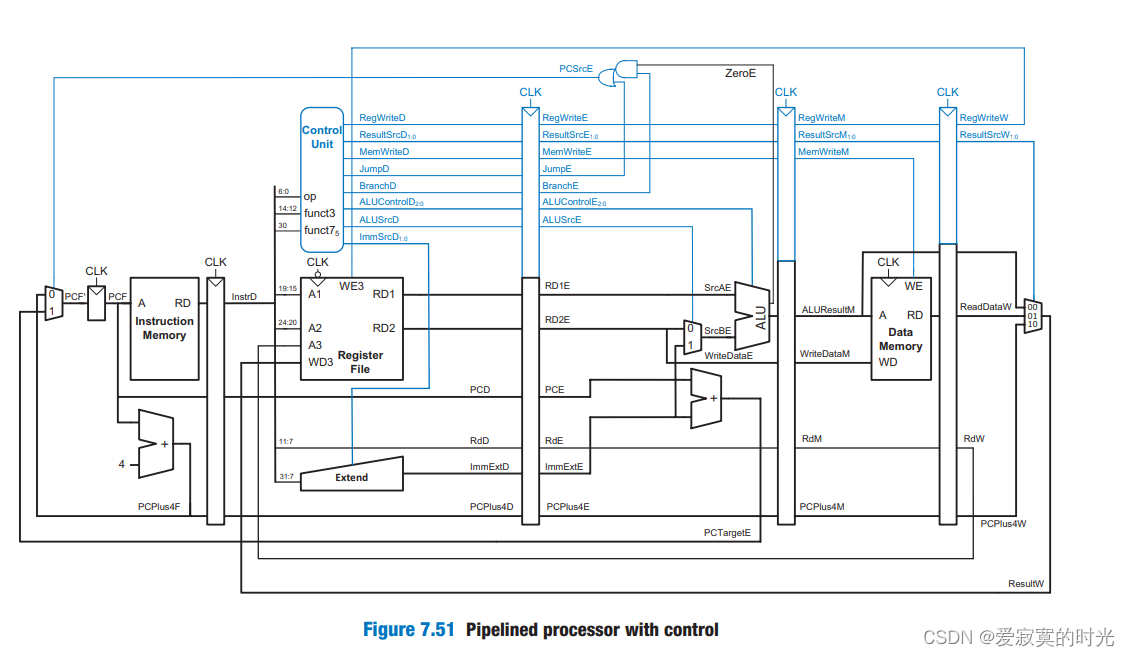
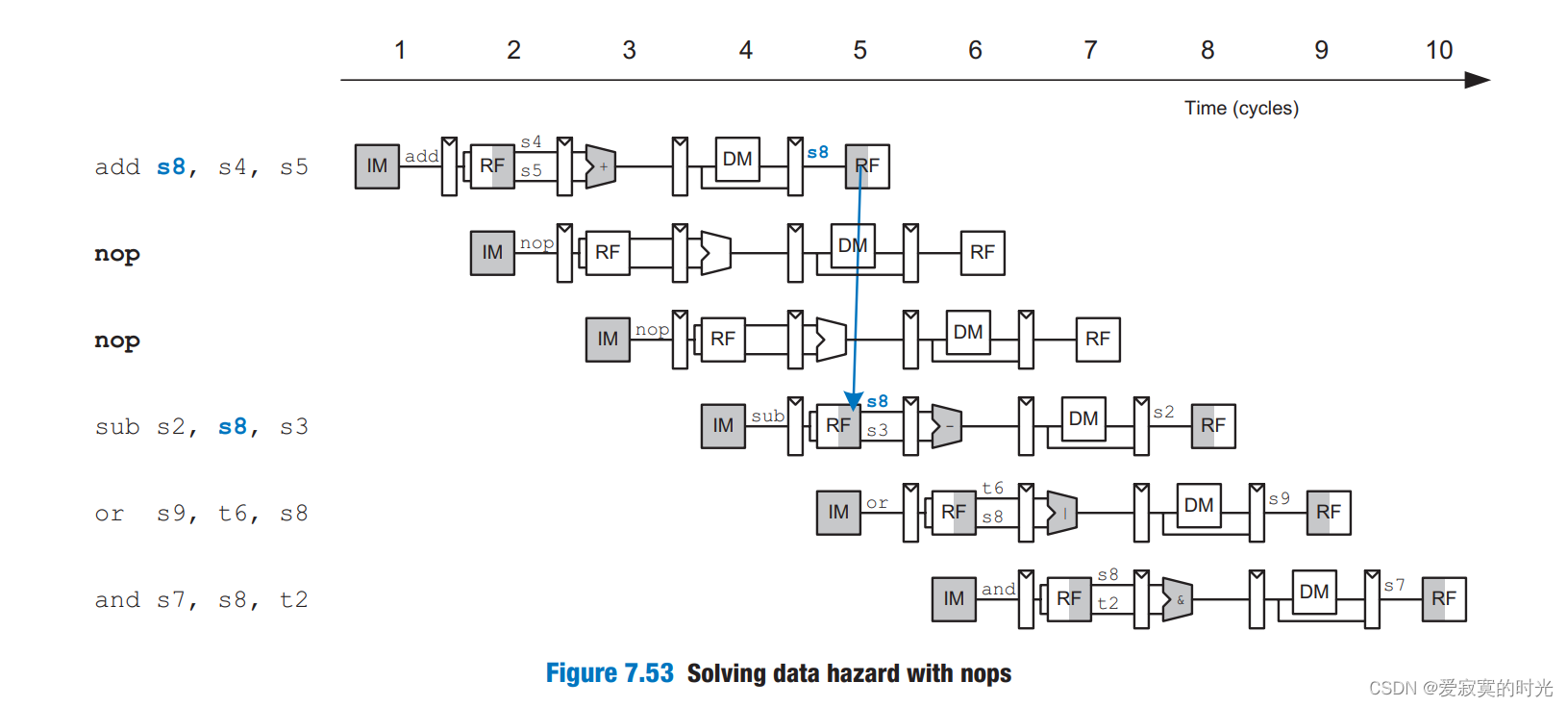 这样就能够保证后面的指令都是正确的结果,但是这种方法既拖慢了流水线的速度,也增加了编译器的实现难度。
这样就能够保证后面的指令都是正确的结果,但是这种方法既拖慢了流水线的速度,也增加了编译器的实现难度。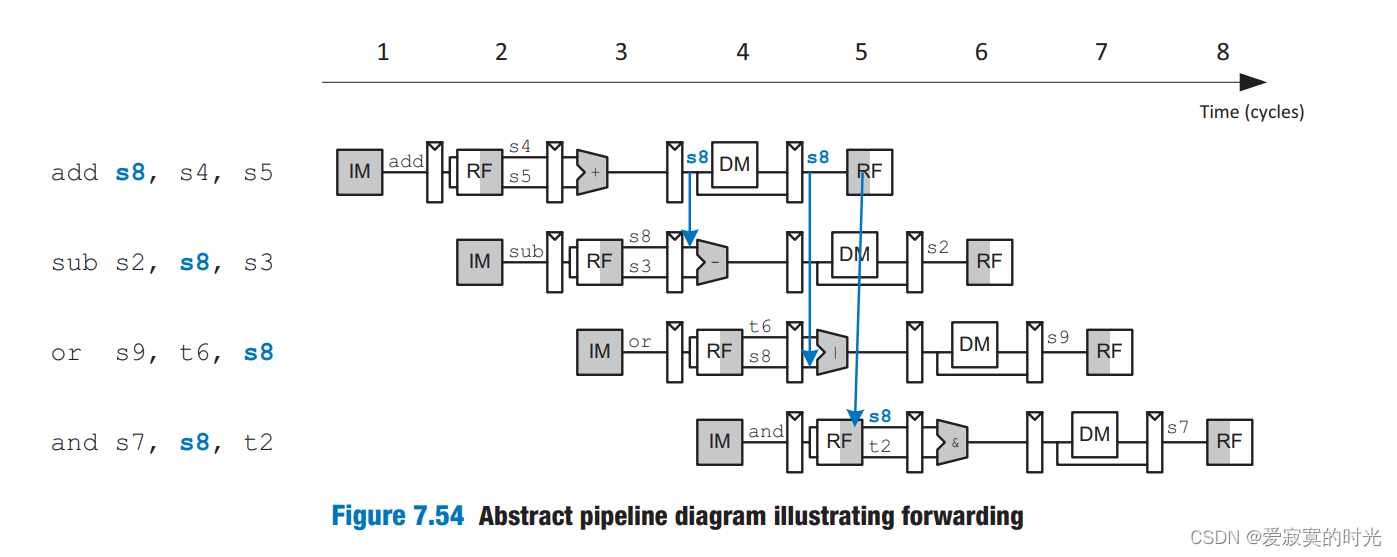
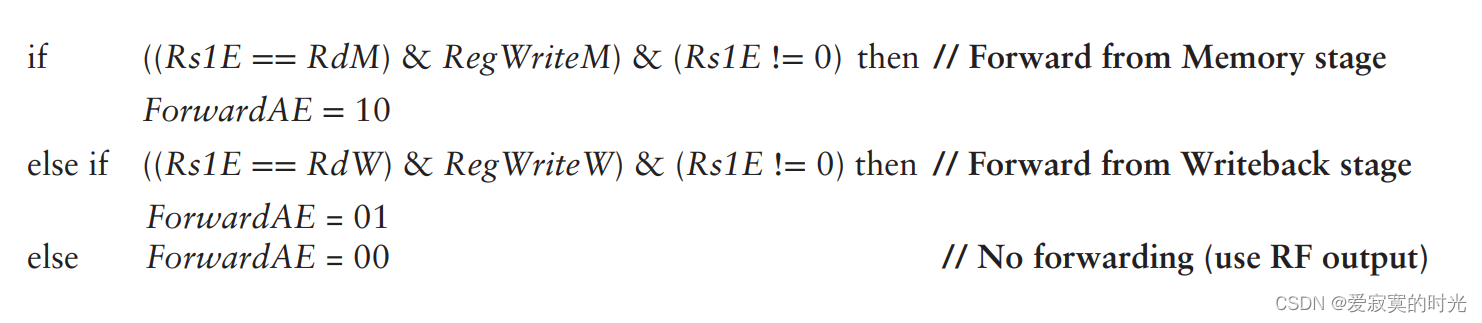
 我们称lw是一个两周期延迟的指令,因为lw指令的结果最少在其之后的第二个周期(or指令)才有效,这种无法通过数据前送来解决。
我们称lw是一个两周期延迟的指令,因为lw指令的结果最少在其之后的第二个周期(or指令)才有效,这种无法通过数据前送来解决。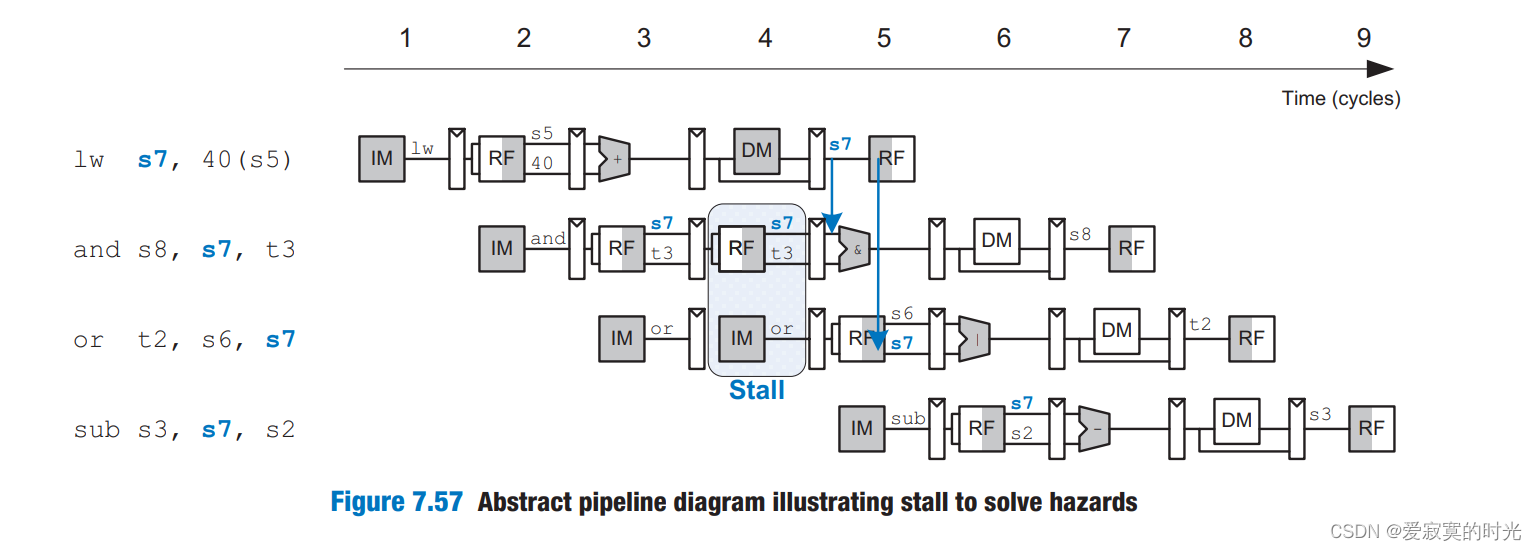 译码阶段被挂起了一个周期,当然在译码之前的阶段(取指令)也需要挂起一个周期。在第5周期,or在后半周期读,而lw在前半周期写,因此不需要数据前送。
译码阶段被挂起了一个周期,当然在译码之前的阶段(取指令)也需要挂起一个周期。在第5周期,or在后半周期读,而lw在前半周期写,因此不需要数据前送。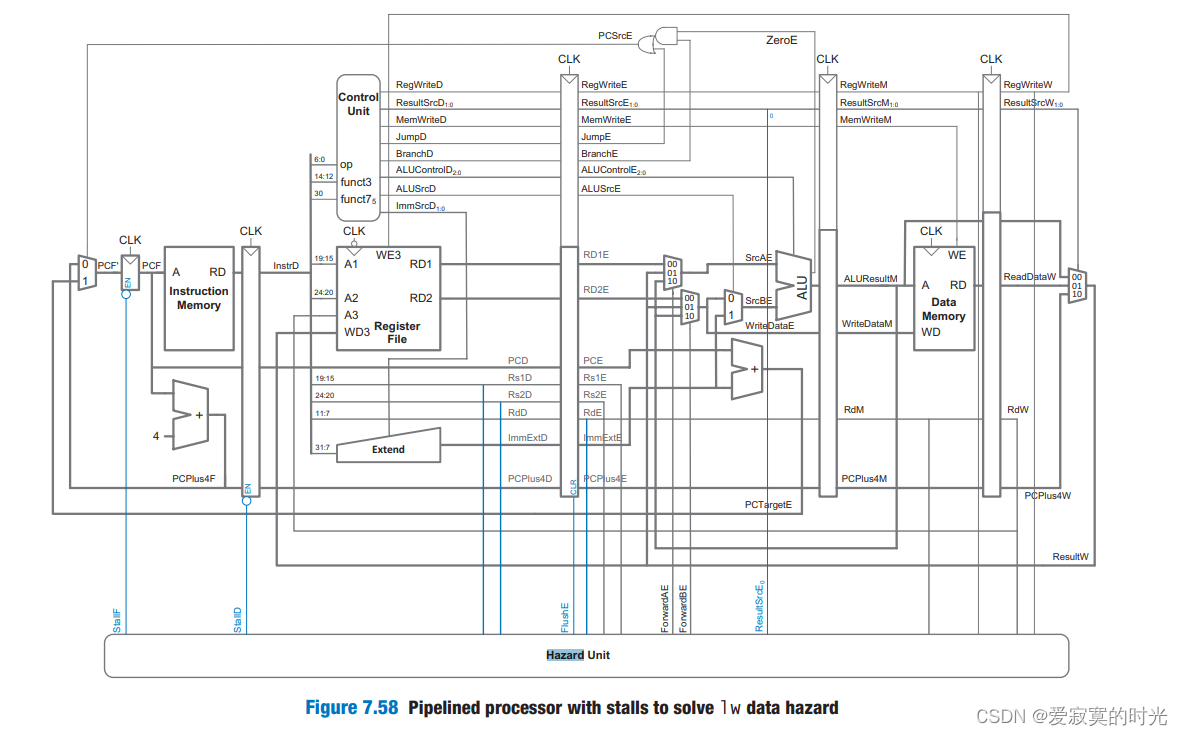 当下面条件满足的时候,启动Stall:
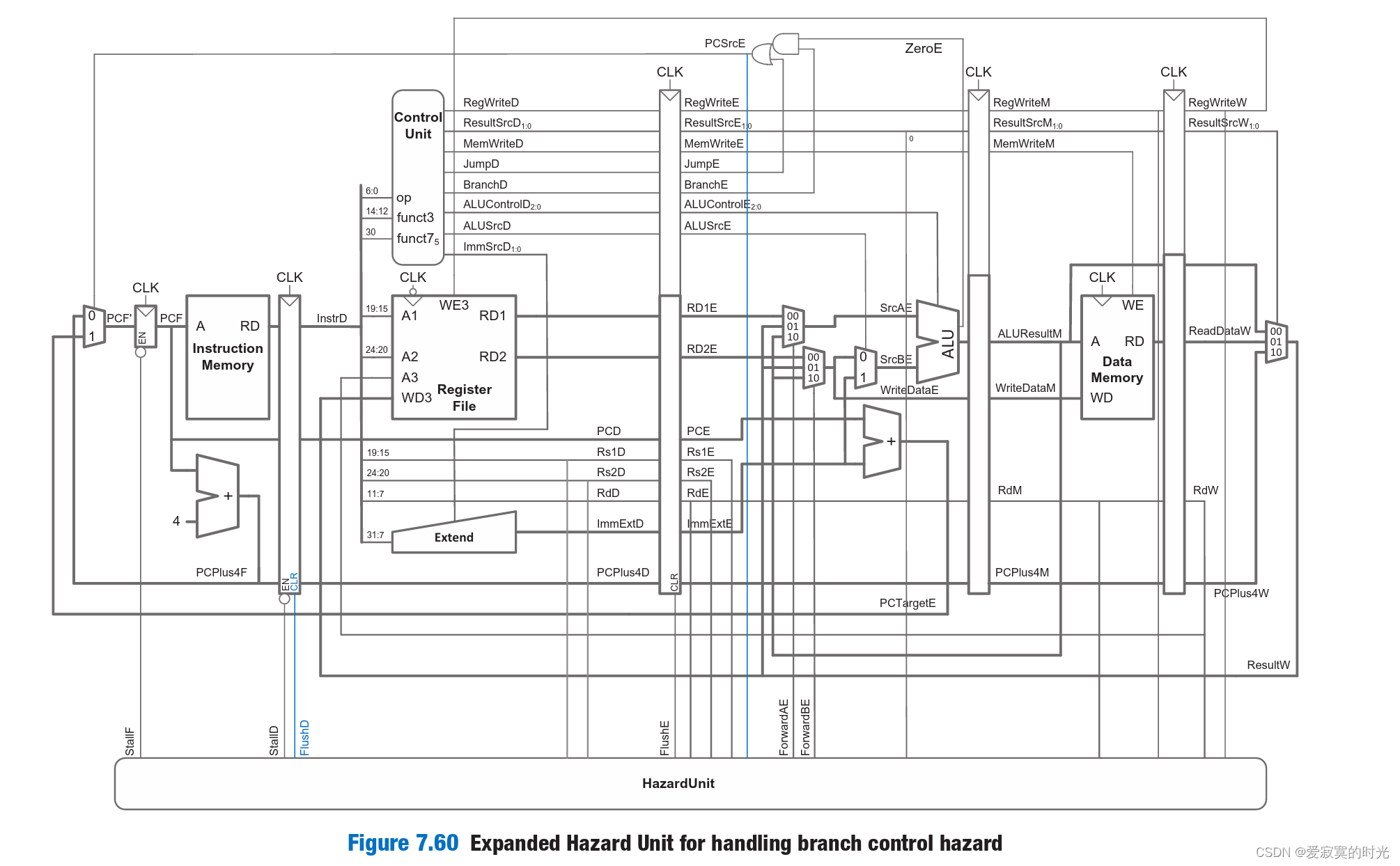
当下面条件满足的时候,启动Stall: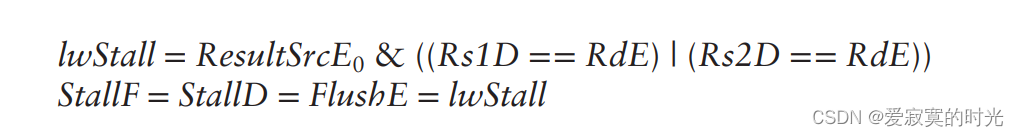
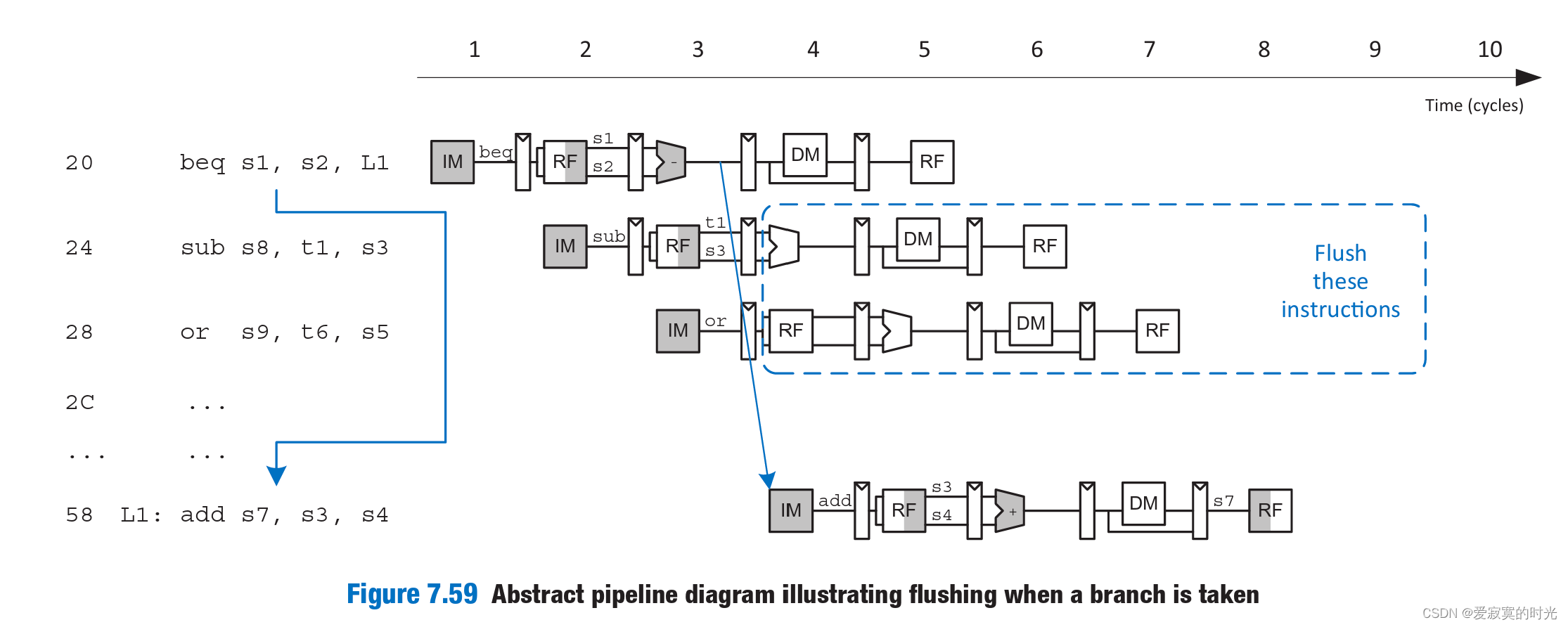
 上图是实现清除前两个流水线的功能,当Hazard 单元判断PCSrcE为1 的时候,表明发生分支跳转,因此FlushD,FlushE被置1,取指令阶段和译码阶段的FF除法寄存器被同步清空,执行逻辑如下:
上图是实现清除前两个流水线的功能,当Hazard 单元判断PCSrcE为1 的时候,表明发生分支跳转,因此FlushD,FlushE被置1,取指令阶段和译码阶段的FF除法寄存器被同步清空,执行逻辑如下:
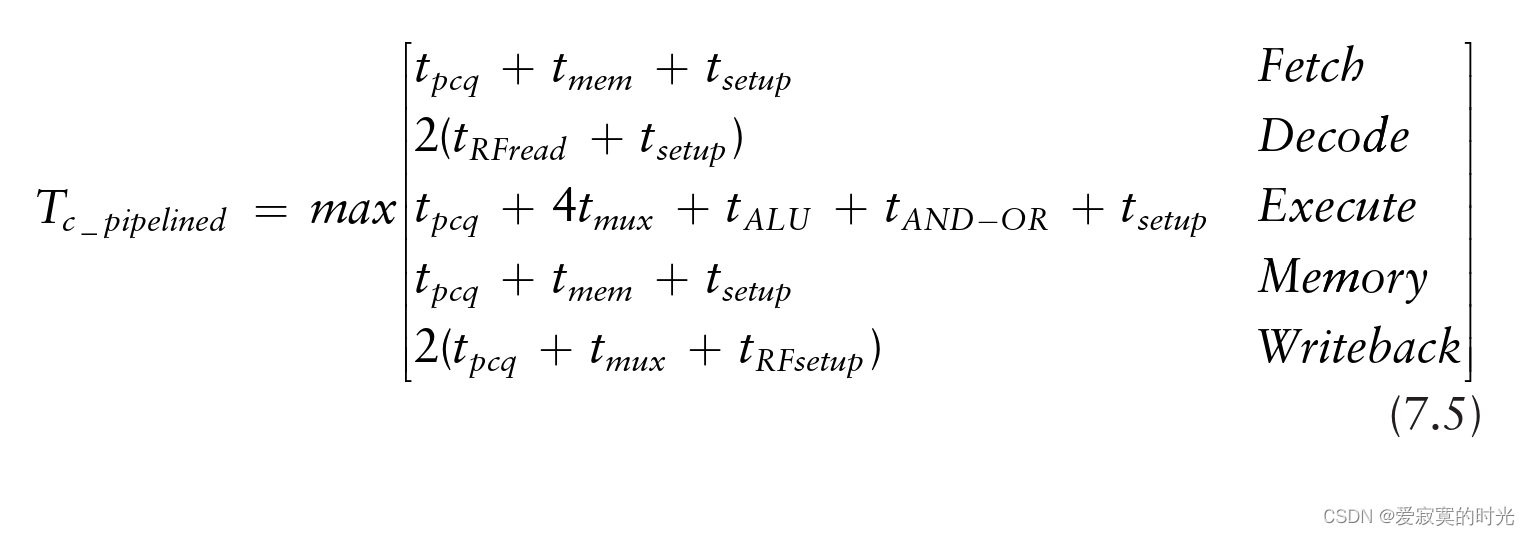
【本文地址】
今日新闻 |
推荐新闻 |