Python网络爬虫 |
您所在的位置:网站首页 › 二手房背景介绍模板图片 › Python网络爬虫 |
Python网络爬虫
|
一、选题的背景 为什么要选择此选题?要达到的数据分析的预期目标是什么?(10 分) 通过爬取Q房二手房信息,对爬取的数据进行进一步清洗处理,分析各维度的数据,筛选对房价有显著影响的特征变量,探索上海二手房整体情况、价格情况。 二、主题式网络爬虫设计方案(10 分) 1.主题式网络爬虫名称:二手房爬虫及数据分析 2.主题式网络爬虫爬取的内容与数据特征分析: 通过request爬取Q房二手房的信息、BeautifulSoup分析网页结构获取数据,其中内容为上海二手房的房屋简介、楼层、规格、地址、房价、面积。 3.主题式网络爬虫设计方案概述: 需要分为几个步骤实现:通过获取网页资源,使用etree解析网页,定位爬取资源将数据保存到csv文件中。 三、主题页面的结构特征分析(10 分) 数据来源:https://shanghai.qfang.com/ Htmls页面解析:
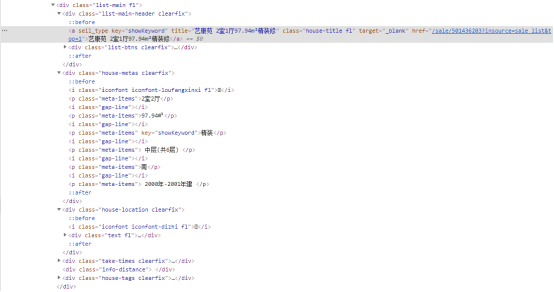
通过find方法查找所需要的相关页面代码
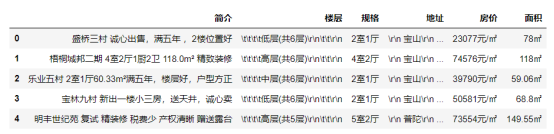
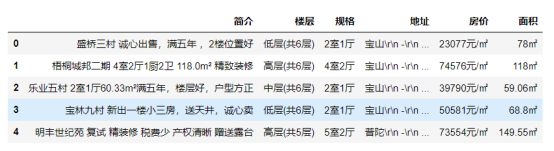
四、网络爬虫程序设计(60 分) 数据爬取及采集: 1 #导入库 2 import requests 3 from lxml import etree 4 import time 5 import re 6 import pandas as pd 7 8 #初始化空列表 9 jianjie_list, louceng_list, guige_list, dz_list, fangjia_list, mianji_list = [], [], [], [], [], [] 10 11 for a in range(10): 12 #爬取前10页的内容 13 url = "https://shanghai.qfang.com/sale/f{}".format(a*10) 14 15 #设置请求头 16 headers = { 17 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36" 18 } 19 #requests请求链接 20 resp = requests.get(url,headers=headers).text 21 22 #使用lxml模块中的etree方法将字符串转化为html标签 23 html = etree.HTML(resp) 24 25 #xpath定位标签 26 list = html.xpath("/html/body/div[4]/div/div[1]/div[4]/ul/li") 27 28 #爬取内容具体链接 29 for li in list: 30 #爬取简介 31 jianjie = li.xpath("./div[2]/div[1]/a/text()")[0] 32 #爬取楼层 33 louceng = li.xpath("./div[2]/div[2]/p[4]/text()")[0] 34 #爬取规格 35 guige = li.xpath("./div[2]/div[2]/p[1]/text()")[0] 36 #爬取地址 37 dz = li.xpath("./div[2]/div[3]/div/text()")[0] 38 #爬取房价 39 fangjia = li.xpath("./div[3]/p[2]/text()")[0] 40 #爬取面积 41 mianji = li.xpath("./div[2]/div[2]/p[2]/text()")[0] 42 43 #输出 44 print(jianjie) 45 print(louceng) 46 print(guige) 47 print(dz) 48 print(fangjia) 49 print(mianji) 50 # 将字段存入初始化的列表中 51 jianjie_list.append(jianjie) 52 louceng_list.append(louceng) 53 guige_list.append(guige) 54 dz_list.append(dz) 55 fangjia_list.append(fangjia) 56 mianji_list.append(mianji) 57 58 #pandas中的模块将数据存入 59 df = pd.DataFrame({ 60 "简介" : jianjie_list, 61 "楼层" : louceng_list, 62 "规格" : guige_list, 63 "地址" : dz_list, 64 "房价" : fangjia_list, 65 "面积" : mianji_list, 66 }) 67 #储存为csv文件 68 df.to_csv("fangzi.csv" , encoding='utf_8_sig', index=False)
爬取运行生成一个.csv文件
导入库: 1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 import matplotlib.pyplot as plt 6 import seaborn as sns 7 fangzi = pd.DataFrame(pd.read_csv('fangzi.csv',encoding="utf-8")) 8 fangzi.head()对数据进行清理: 1 fangzi.duplicated()
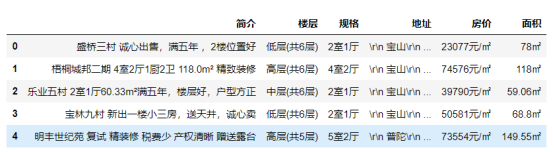
1 fangzi = fangzi.drop_duplicates() 2 fangzi.head() 3 #删除重复值
1 fangzi['房价'].isnull().value_counts() 2 #判断统计空值
1 fangzi['面积'].isnull().value_counts() 2 #判断统计空值
1 fangzi['楼层'] = fangzi['楼层'].map(str.strip) 2 fangzi.head() 3 #填充缺失值
1 fangzi['楼层'] = fangzi['楼层'].map(str.strip) 2 fangzi['地址'] = fangzi['地址'].map(str.rstrip) 3 fangzi.head() 4 #空格处理
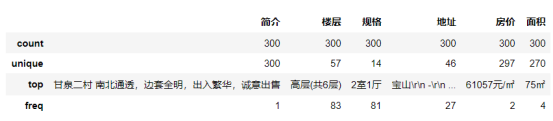
1 fangzi.describe() 2 #异常值处理
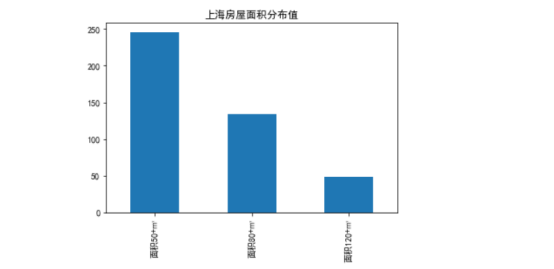
数据分析与可视化: 房屋面积占比分布所做的柱状图: 1 #导入库 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 plt.rcParams['font.family'] = ['SimHei']#乱码转中文 6 s=pd.Series([246,134,49],['面积50+㎡','面积80+㎡','面积120+㎡']) #设置柱状图属性 7 s.plot(kind = 'bar', title = '上海房屋面积分布值') #设置柱状图标题 8 plt.show() 9 #柱状图
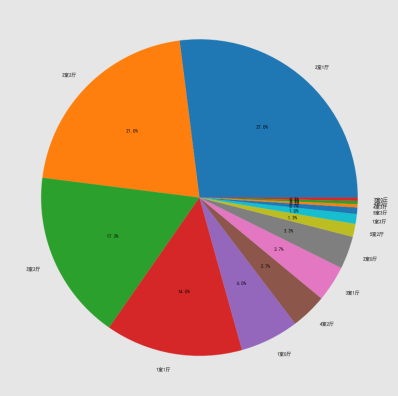
房屋规格占比所做的饼图: 1 df_score = fangzi['规格'].value_counts() #统计评分情况 2 plt.title("房子户型规格占比图") #设置饼图标题 3 plt.figure(figsize=(80, 15))#设置圆饼图比例 4 plt.rcParams['font.sans-serif'] = ['SimHei']#乱码转中文 5 plt.pie(df_score.values,labels = df_score.index,autopct='%1.1f%%') 6 #分布值饼图
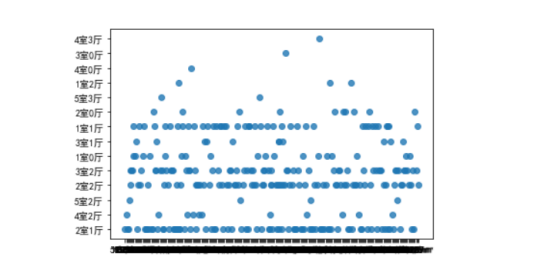
房屋面积规格所做的散点图: 1 sns.regplot(x = '面积',y = '规格',data=fangzi)#设置散点图属性 2 sns.figure(figsize=(10, 5))#设置比例 3 #散点图
完整代码: 1 #导入库 2 import requests 3 from lxml import etree 4 import time 5 import re 6 import pandas as pd 7 8 #初始化空列表 9 jianjie_list, louceng_list, guige_list, dz_list, fangjia_list, mianji_list = [], [], [], [], [], [] 10 11 for a in range(10): 12 #爬取前10页的内容 13 url = "https://shanghai.qfang.com/sale/f{}".format(a*10) 14 15 #设置请求头 16 headers = { 17 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36" 18 } 19 #requests请求链接 20 resp = requests.get(url,headers=headers).text 21 22 #使用lxml模块中的etree方法将字符串转化为html标签 23 html = etree.HTML(resp) 24 25 #xpath定位标签 26 list = html.xpath("/html/body/div[4]/div/div[1]/div[4]/ul/li") 27 28 #爬取内容具体链接 29 for li in list: 30 #爬取简介 31 jianjie = li.xpath("./div[2]/div[1]/a/text()")[0] 32 #爬取楼层 33 louceng = li.xpath("./div[2]/div[2]/p[4]/text()")[0] 34 #爬取规格 35 guige = li.xpath("./div[2]/div[2]/p[1]/text()")[0] 36 #爬取地址 37 dz = li.xpath("./div[2]/div[3]/div/text()")[0] 38 #爬取房价 39 fangjia = li.xpath("./div[3]/p[2]/text()")[0] 40 #爬取面积 41 mianji = li.xpath("./div[2]/div[2]/p[2]/text()")[0] 42 43 #输出 44 print(jianjie) 45 print(louceng) 46 print(guige) 47 print(dz) 48 print(fangjia) 49 print(mianji) 50 # 将字段存入初始化的列表中 51 jianjie_list.append(jianjie) 52 louceng_list.append(louceng) 53 guige_list.append(guige) 54 dz_list.append(dz) 55 fangjia_list.append(fangjia) 56 mianji_list.append(mianji) 57 58 #pandas中的模块将数据存入 59 df = pd.DataFrame({ 60 "简介" : jianjie_list, 61 "楼层" : louceng_list, 62 "规格" : guige_list, 63 "地址" : dz_list, 64 "房价" : fangjia_list, 65 "面积" : mianji_list, 66 }) 67 #储存为csv文件 68 df.to_csv("fangzi.csv" , encoding='utf_8_sig', index=False) 69 import numpy as np 70 import pandas as pd 71 import matplotlib.pyplot as plt 72 import seaborn as sns 73 import matplotlib.pyplot as plt 74 import seaborn as sns 75 fangzi = pd.DataFrame(pd.read_csv('fangzi.csv',encoding="utf-8")) 76 #csv文件 77 fangzi.head() 78 79 #数据清理 80 fangzi.duplicated() 81 82 #删除重复值 83 fangzi = fangzi.drop_duplicates() 84 fangzi.head() 85 86 #判断统计空值 87 fangzi['房价'].isnull().value_counts() 88 89 #判断统计空值 90 fangzi['面积'].isnull().value_counts() 91 92 #判断统计空值 93 fangzi['规格'].isnull().value_counts() 94 95 #填充缺失值 96 fangzi['楼层'] = fangzi['楼层'].map(str.strip) 97 fangzi.head() 98 99 #空格处理 100 fangzi['楼层'] = fangzi['楼层'].map(str.strip) 101 fangzi['地址'] = fangzi['地址'].map(str.rstrip) 102 fangzi.head() 103 104 #异常值处理 105 fangzi.describe() 106 107 108 import numpy as np 109 import pandas as pd 110 import matplotlib.pyplot as plt 111 plt.rcParams['font.family'] = ['SimHei']#乱码转中文 112 s=pd.Series([246,134,49],['面积50+㎡','面积80+㎡','面积120+㎡']) #设置柱状图属性 113 s.plot(kind = 'bar', title = '上海房屋面积分布值') #设置柱状图标题 114 plt.show() 115 #柱状图 116 117 df_score = fangzi['规格'].value_counts() #统计评分情况 118 plt.title("房子户型规格占比图") #设置饼图标题 119 plt.figure(figsize=(80, 15))#设置圆饼图比例 120 plt.rcParams['font.sans-serif'] = ['SimHei']#乱码转中文 121 plt.pie(df_score.values,labels = df_score.index,autopct='%1.1f%%') 122 #圆饼图 123 124 sns.regplot(x = '面积',y = '规格',data=fangzi)#设置散点图属性 125 sns.figure(figsize=(10, 5))#设置比例 126 #散点图
总结: 经过数据爬取与数据可视化,我们了解到,除了虹口区以外各区的二手房均价都趋于缓和阶段,规格多数为二室一厅的房屋。初步爬取分析达到预期,但相对数据对比感觉还不够全面地达到效果。通过python这门课我自己完成了网络爬虫和数据可视性,继续丰富了自己的能力。
|





【本文地址】
今日新闻 |
推荐新闻 |